

研究人员说,他们可能找到了一个梯子来爬上“数据墙”
作者:Jonathan Kemper
麻省理工学院的研究人员推出了一个名为SEAL的新框架,该框架使大型语言模型(LLMS)生成了自己的合成训练数据,并在没有外部帮助的情况下改善了自己。
密封分为两个阶段。首先,该模型学会使用奖励学习来创建有效的“自我编辑”。这些自我编辑写为自然语言指令,可以定义新的训练数据并设置优化参数。在第二阶段,系统应用这些说明并通过机器学习更新了自己的权重。

密封的关键部分是其休息^em算法,它的作用像是一个过滤器:它只能保持和加强自我编辑,从而真正改善了性能。该算法收集不同的编辑,测试哪些工作起作用,然后仅使用成功的变体来训练模型。SEAL还使用低级适配器(LORA),该技术可以快速,轻巧的更新而无需重新训练整个型号。
研究人员在两种情况下对测试进行了密封。首先,他们在文本理解任务上使用QWEN2.5-7B。该模型从文本产生了逻辑推断,然后以其自身的输出进行了训练。
广告
解码器通讯
您收件箱的最重要的AI新闻。
每周
免费
•随时取消

SEAL的精度为47%,超过了比较方法的33.5%。其自我生成的数据的质量甚至超过了Openai的数据GPT-4.1,尽管基础模型要小得多。
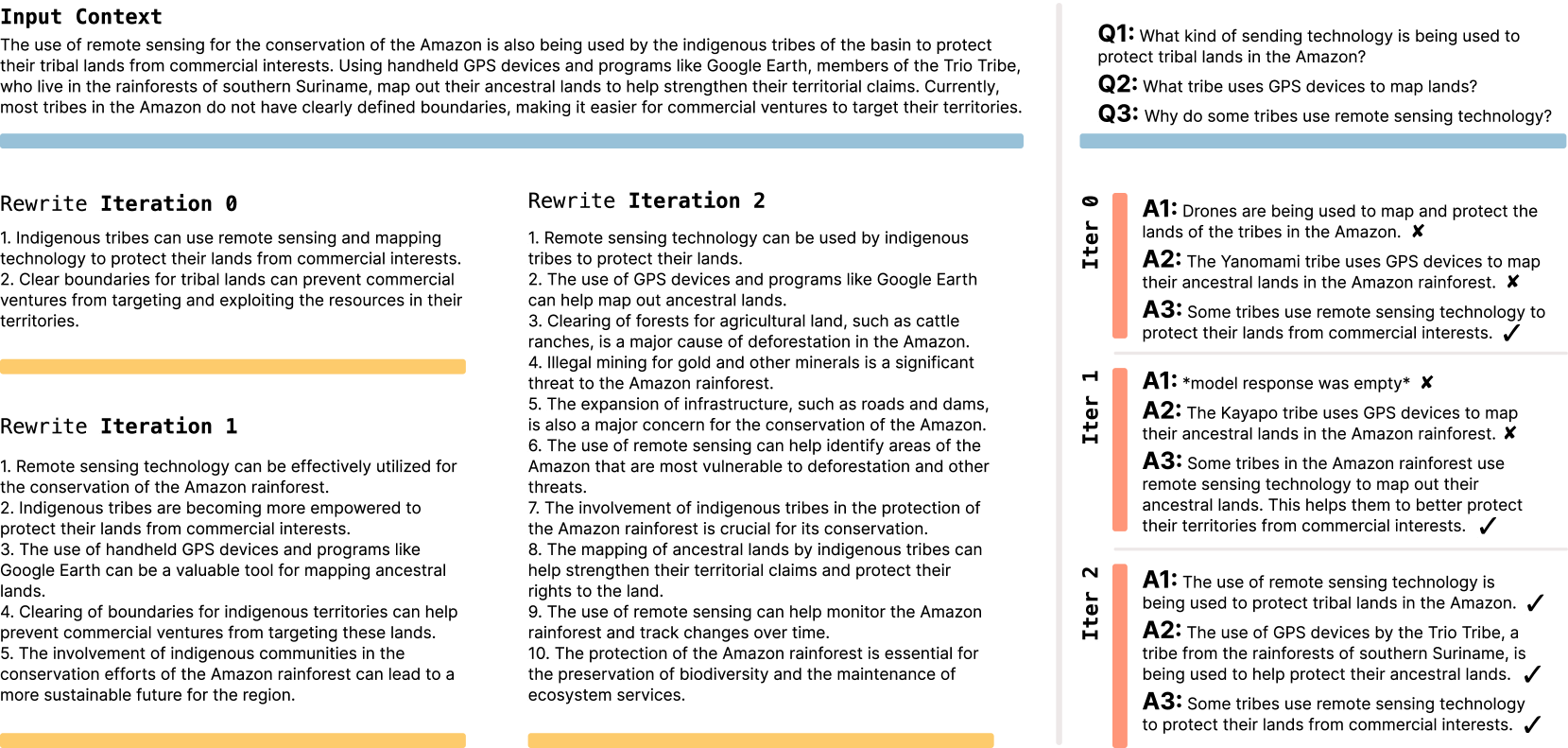
在第二次测试中,团队在推理任务上使用Llama 3.2-1B查看了几次提示。在这里,该模型从预设工具包中选择了不同的数据处理技术和培训参数。借助SEAL,该模型获得了72.5%的成功率,而没有任何以前的培训,只有20%。
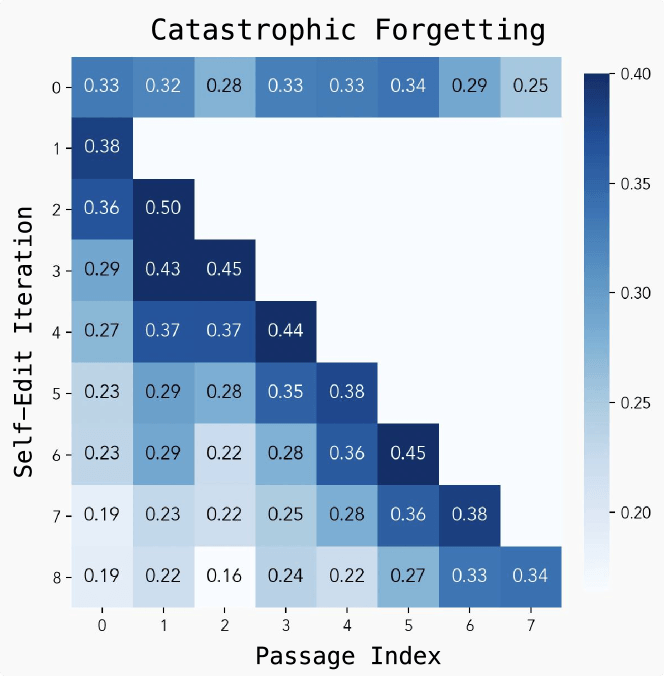
“灾难性遗忘”仍然是一个挑战
尽管取得了良好的结果,但研究人员发现了几个局限性。主要问题是“灾难性遗忘”:当模型承担新任务时,它开始失去以前的绩效。培训也是资源密集的,因为对自我编辑的每次评估都需要30到45秒。
解决数据墙
麻省理工学院团队将密封视为克服所谓的一步“数据墙”。另外,研究人员还警告说“模型崩溃”的风险,在经过过多的训练时,模型质量的降低了低质量AI生成的数据。SEAL可以实现正在进行的学习和自动AI系统,以不断适应新的目标和信息。
如果模型可以通过吸收新材料(例如科学论文)并产生自己的解释和推论来教授自己,那么他们可以不断改善稀有或代表性不足的话题。这种自我驱动的学习循环可能有助于将语言模型推高当前限制。
密封的源代码可在github。