

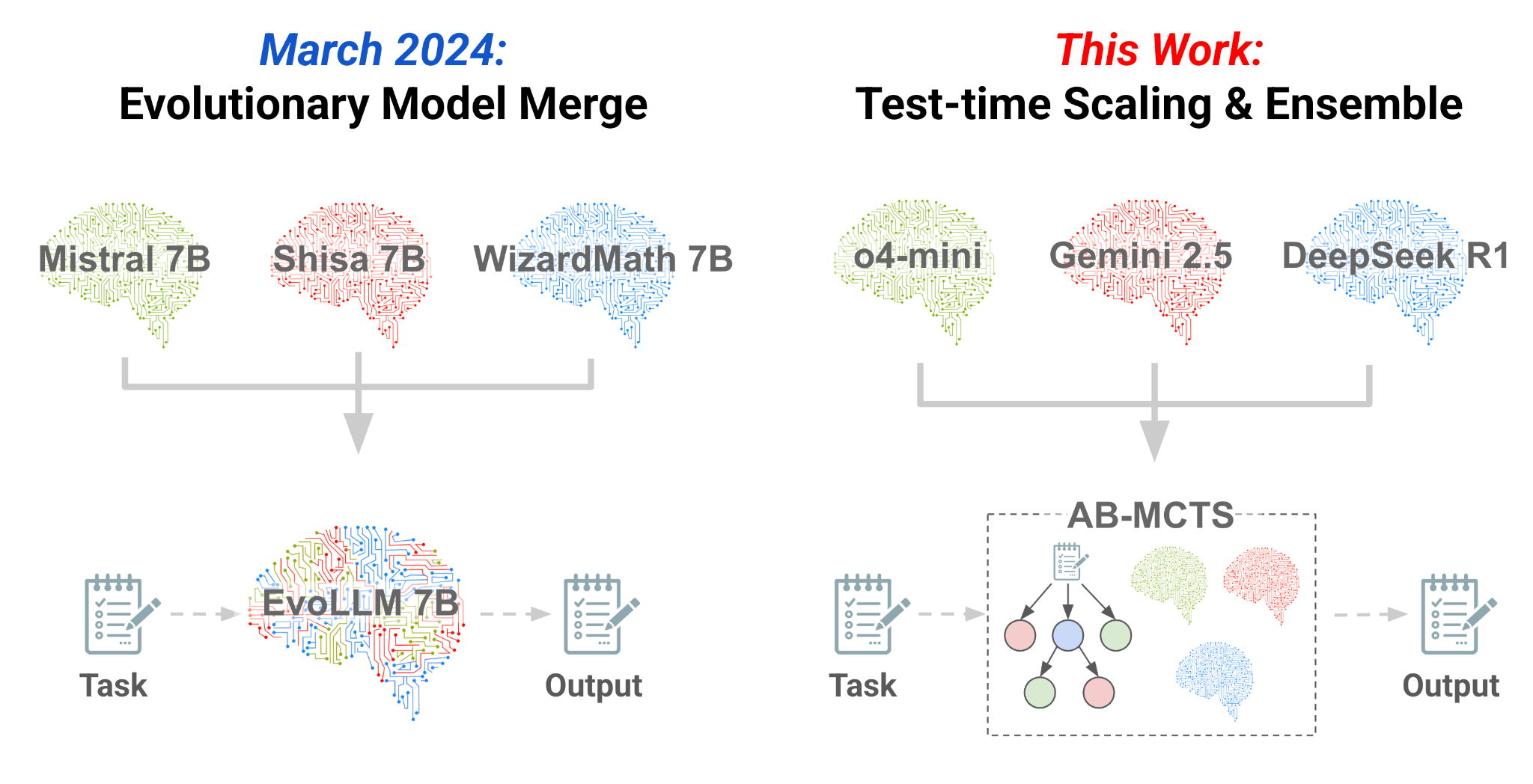
遵循我们2024年的研究进化模型合并这是一种混合技术,可以从现有模型(左)创建更好的模型,我们现在正在应对使用Frontier模型(右)的混合挑战。我们已经开发了AB-MCT,这是一种新的推理时间缩放算法,使多个边境AI模型可以合作,从Arc-Agi-2基准。
概括
在Sakana AI,我们通过应用自然风格的原则(例如进化和集体智能)来开发AI系统。在我们2024年的研究中进化模型合并,我们通过进化计算和模型合并来利用现有开源模型的广泛集体智能。这使我们提出了一个新问题:我们可以不仅在构建新模型,而且还可以在推理过程中使用多种模型吗?我们可以利用Chatgpt,Gemini和DeepSeek等不断提高的边境模型来利用它们作为集体智能的一种形式?
Sakana AI很荣幸能引入一种新的推理时间缩放算法,AB-MCT(自适应分支蒙特卡洛树搜索),这使AI能够有效执行试用并允许多个边境AI模型合作。在此博客文章中,我们将介绍该概念并分享我们有希望的初始结果。特别是我们的AB-MCT组合O4-Mini+双子座2.5-Pro+R1-0528,当前的Frontier AI模型在撰写本文时,在ARC-AGI-2基准测试上取得了强劲的性能,优于单个O4-Mini,Gemini-2.5-Pro和DeepSeek-R1-0528模型,其大幅度较大。
- 纸:https://arxiv.org/abs/2503.04412
- 算法实施:https://github.com/sakanaai/treequest
- ARC-AGI-2实验代码:https://github.com/sakanaai/ab-mcts-arc2

ARC-AGI-2上AB-MCT和多LLM AB-MCT的结果,显示Pass@K作为LLM调用数量的函数。
介绍
有一个众所周知的谚语:•两个头大于一个。尽管人脑是一个非凡的器官,但人类的最大成就并不是个人思想的产物。前所未有的壮举,例如阿波罗计划,互联网的创建和人类基因组项目,不是由一个天才而不是通过不同个人的合作来实现的,而知识的积累,换句话说,集体智慧。通过汇集多样化的专业知识和思想,有时会冲突并融合它们,人类已经克服了无数的技术障碍。
我们认为,同样的原则对于人工智能也是如此。通过汇总他们的智能,AI系统可以解决任何单个模型都无法克服的问题。诸如Chatgpt,Gemini,Grok和Deepseek之类的Frontier AI模型在激烈的竞争中以令人叹为观止的速度发展。但是,无论它们变得多么先进,每个模型都保留了自己的个性,这些个性源于其独特的培训数据和方法。我们认为这些偏见和变化的才能不是局限性,而是创造集体智慧的宝贵资源。就像一个梦dream以求的人类专家解决复杂问题一样,AIS也应通过将其独特的优势列入餐桌来协作。
这AB-MCT(自适应分支蒙特卡洛树搜索)我们今天介绍的算法是实现这一愿景的具体步骤。AB-MCT是一种推理时间缩放的方法,可以使OpenAI和DeepSeek等提供商的边境AIS合作并有效地进行试验和错误。在以下各节中,我们将(1)介绍推理时间缩放的概念,(2)解释单个AI如何执行反复试验,(3)描述了我们通过使多个AIS合作来增强这一点的尝试,(4)(4)在具有挑战性的任务上使用Frontier模型提出我们的初始实验。
什么是推理时间缩放?
面对一个困难的问题时,您可以一目了然地解决,您该怎么办?最有可能的,你会独自思考更长的时间,参与动手反复试验,或者与他人合作。我们可以让AI以相同的方式解决困难问题吗?
目前引起关注的范例是推理时间缩放(或测试时间缩放)。这是发现,对于一个复杂的问题,可以通过在推理时分配更多的计算资源来提高性能。虽然训练期间的性能与计算之间的关系(训练时间缩放)已知已知,但我们现在知道,性能与所使用的计算预算之间也存在正相关关系后模型已经训练。一种方法是使用增强学习来产生更长的思想链,这极大地增强了所谓的能力推理模型例如Openai的O1/O3和DeepSeek s r1。这与人类思维的策略相对应。
除了简单地给出推理模型的思考时间之外,我们还可以重复重新审视问题,完善其答案,甚至在必要时重新开始。想象一下,您正在尝试解决编程挑战。不管您的程序员有多熟练,如果没有试用和错误运行代码,修复错误,有时从头开始,就不可能完成复杂的程序。这个过程不仅限于编程;我们人类不断参与其中。此方法也适用于LLMS。我们新开发的AB-MCT是一种推理时间缩放技术,使AI能够执行此类试用有效,甚至允许不同的AIS集体思考。推理时间缩放的三个方向。

推理模型在一次尝试中思考更长的思考来实现绩效的提高。在这项研究中,我们通过为反复试验和多LLM AB-MCT开发AB-MCT来建立在此基础上,以利用多个Frontier LLM的集体智能。
导航搜索的两个维度:平衡深度和宽度
我们的AB-MCT(自适应分支蒙特卡洛树搜索)是一种推理时间缩放方法,使LLMS能够有效地进行反复试验。制作LLM使用试用版的最简单方法是深度搜索方法调用顺序完善。该方法使用LLM来生成答案,然后反复改进它们。另一种方法是重复采样,其中LLM从同一提示多次生成解决方案。这很简单宽度搜索反复查询LLM的搜索,而无需反映以前尝试的结果。它利用LLM的随机性质,这对同一问题产生了不同的答案。虽然看起来效率低下,但据报道,它在许多基准上都优于顺序完善。

因此,两者搜索更深层次(完善现有解决方案)和搜索更宽(生成新解决方案)已被证明可有效使用LLMS更好的答案。但是,没有有效的方法将它们结合在一起。连续精炼会反复完善解决方案,如果最初的尝试被误导,可能会难以达到一个良好的答案。反复提出同样的问题的重复采样从不改善有希望但不完美的解决方案。这意味着对这些简单的单向方法有改进的空间。我们认为,如果我们能够实现更类似人类的试验过程,有时会重复相同的问题以获取更好的初始方向,而其他时候则可以完善有希望的解决方案。”我们可以利用LLM来找到出色的答案。
为了解决这个问题,我们开发了AB-MCT,以灵活地搜索这两个深度和宽度方向,适应问题和上下文。使用AB-MCT,当找到有前途的解决方案时,系统可以反复完整地完善它,同时仍然平衡全新的解决方案。与现有方法相比,这使我们可以通过相同数量的LLM调用获得更好的答案。从本质上讲,AB-MCT是推理时间缩放的一种新的,更有效的方法。

为了实现这一灵活的搜索,AB-MCT扩展了蒙特卡洛树搜索(MCT),该搜索(MCT)在Alphago等系统中著名,并采用Thompson采样来决定要探索哪个方向。具体而言,在每个节点(表示初始提示或先前生成的解决方案)上,AB-MCT使用概率模型来估计两个可能的操作的潜在质量:生成全新的解决方案或完善现有的解决方案。然后,我们从这些模型中采样质量估计,以确定追求方向。一个关键的挑战是评估一种新的尚未生成的解决方案的质量。AB-MCT通过使用混合模型和概率分布来代表此评估来有效地管理此问题,从而实现了真正的灵活搜索。有关AB-MCTS算法和实验结果的更多详细信息,请参考我们纸。
人工智能合作作为第三个搜索维度
近年来,LLM开发爆炸了,边境模型和开源替代方案都以令人难以置信的速度发展。尽管基准表明所有这些模型都具有很高的能力,但有趣的是它们具有不同的特征。一些模型在编码方面表现出色,其他模型在创意写作方面,而另一些模型则在代理,顺序执行中表现出色。
当使用LLMS解决问题时,这些优势和劣势以各种方式表现出来。例如,在同一基准中,LLM的熟练程度因问题而异。在基准上进行总体效果不佳的模型可能会在其中的特定问题上表现出色。此外,只有在LLMS协作和相互利用的优势时,才能解决一些问题。例如,在一个问题中,一个LLM可以更好地定义整体策略,而另一个LLM则更好地编写特定代码。鉴于这些不同的专业知识,可以想象,通过巧妙地结合多个LLM,我们可以解决更广泛的问题。
为了最大化多个LLM作为集体智能的潜力,我们正在原型化多LLLM AB-MCT,这不仅可以适应搜索搜索方向,还可以为给定的问题和情况选择哪个LLM。此外生成新解决方案(更宽)和完善现有解决方案(更深入)AB-MCT中的选择,多LLLM AB-MCT添加了一个新步骤:选择哪个LLM使用。

多LLM AB-MCT中搜索算法的概述。在步骤1中,它决定是选择现有节点(更深入搜索)还是从当前节点(搜索较宽)生成新解决方案。如果更深,它将从下一个级别重复步骤1。如果它更宽或没有现有节点,则需要步骤2选择LLM。在步骤3中,所选的LLM基于父节点生成了改进的解决方案,并评估了结果。然后将此新解决方案添加到树上作为新节点。
为了完成这项工作,我们需要知道哪个LLM对每个问题都是有效的。但是,这在开始时是未知的,因此系统必须随着搜索的进行而进行调整。这意味着在早期阶段使用LLM的平衡组合,然后专注于那些更有希望的人。这可以看作是多臂强盗问题,机器学习中的一个众所周知的问题。但是,与标准的多臂匪徒问题不同,每次都会显示相同的输入,此处的关键是适应基于生成的答案的变化输入。对于LLM选择,我们为每种LLM类型分配了一个单独的概率模型,并以类似于上述AB-MCT方法的方式使用了Thompson采样。这些概率模型是根据搜索过程中每个LLM的性能进行更新的,因此选择更有希望的LLM越来越有可能被选择。有关更详细的算法和实现,请参考我们的纸(附录D)和代码。
实验结果
我们在开发的多llm AB-MCT上介绍了最初的实验结果Arc-Agi-2基准。Arc-Agi(抽象和推理语料库)旨在评估一种人类般的灵活智能,可以有效地推理和解决新的问题,这与测试特定技能或知识的传统指标不同。尽管Arc-Agi-1长期以来一直是人类容易的研究挑战,但对于AI来说很难,但我们将更具挑战性的Arc-Agi-2用于实验。

ARC-AGI-2的一个示例问题。任务是从左侧的三个演示案例中推断出常见的转换规则,并将其应用于右侧的测试案例。这是使用多LLM AB-MCT可以解决的问题之一。
我们研究了多LLLM AB-MCT在此困难基准上的潜在性能。在本实验中,我们将最大数量的搜索迭代(LLM调用)设置为250,并指示模型以Python代码生成转换规则。搜索是由奖励指导的,反映出生成的Python代码正确解决了多少个演示案例。为了主要评估搜索算法的最大潜在性能,我们使用了Pass@K Metric,该量度可以衡量在K尝试中是否至少找到一个正确的解决方案。这与ARC-AGI-2的官方竞赛标准不同,ARC-AGI-2通常使用PASS@2标准(提交两个最终答案,一个是正确的)。通过@2方法,需要从搜索结果中选择有希望的候选人的附加步骤。在这项最初的研究中,我们专注于通过Pass@k评估搜索能力本身。稍后,我们将简要介绍暂定通行证@2评估。在ARC-AGI-2的公共评估集中,对120个任务进行了实验。有关详细的实验设置,请参阅提供的源代码。

ARC-AGI-2上AB-MCT和多LLM AB-MCT的结果,显示了250次成功率。与O4-Mini一起使用AB-MCT的结果超过了O4-Mini(浅灰色条)的重复采样。此外,结合了Gemini-2.5-Pro和DeepSeek-R1-0528的Multi-LLM AB-MCTS在PASS@250时的得分提高了。

ARC-AGI-2上AB-MCT和多LLM AB-MCT的结果,显示Pass@K作为LLM调用数量的函数。虚线使用没有AB-MCT的重复采样表示对照实验的结果。
重复采样被认为是ARC-AGI的非常有效的方法。实际上,在我们的实验中,用O4-Mini重复采样成功地解决了23%的问题(即,生成的Python代码正确地转换了测试案例)。该结果远远超过了单打得分,并证明了重复采样的功能。但是,我们的AB-MCT将得分进一步提高到27.5%。大约50个LLM调用后,这两种方法之间的差异变得更加明显。
通过利用Frontier模型作为具有多LLM AB-MCT的集体智能,我们最终能够找到30%以上问题的正确解决方案。有趣的是,虽然DeepSeek-R1-0528本身并不特别表现出色,但将其结合在多LLM AB-MCT中会有效地增加了可解决的问题的数量。
我们在Multi-LLM AB-MCT中发现的关键特征之一是它可以根据特定问题的熟练程度动态分配LLM的能力。下图清楚地说明了这种行为:对于演示示例(图的左侧)的成功率很高的情况,我们观察到对特定LLM的明显偏好。发生这种偏见是因为该算法在搜索过程中识别了哪些LLM对给定问题最有效,并随后增加了该模型的使用频率。

用多LLM AB-MCTS以PASS@250求解每个ARC-AGI-2任务的LLM的比例。每个任务的结果都按搜索树的奖励值(左更高)的奖励值进行排序。星标表示成功的试验。
此外,我们看到了通过组合多个LLM来解决任何单个LLM无法解决的示例。这不仅仅是简单地将最佳LLM分配给每个问题。在下面的示例中,即使最初由O4-Mini生成的解决方案不正确,DeepSeek-R1-0528和Gemini-2.5-Pro也能够将其用作在下一步中得出正确解决方案的提示。这表明,多LLM AB-MCT可以灵活地结合边界模型来解决以前无法解决的问题,从而将使用LLMS作为集体智能所实现的限制。

用多LLM AB-MCT求解Arc-Agi-2时搜索树的一个示例。节点中的数字表示生成顺序,颜色表示所选的LLM。黄色节点是正确转换测试用例的代码的节点。这是一个示例,没有一个LLM可以找到解决方案,但是LLM的组合成功了。

多LLM AB-MCT可以在不同的LLM之间进行协作。该图显示了一个示例,其中DeepSeek-R1-0528在O4-Mini生成的不正确解决方案(从上图中的问题中)提高了正确的答案。
如前所述,我们的主要重点是评估搜索能力,因此使用Pass@K Metric。作为参考,当我们使用基于简单的基于规则的方法选择两个最终答案(在搜索后期以后生成的高奖励的代码选择)时,Multi-llm AB-MCT达到了19.2%的第2个通行证。虽然这是Pass@2的绝佳结果,但与30%PASS@K相比,差距超过10%。通过开发更好的最终答案选择算法,建立更复杂的奖励模型或合并LLM-AS-A-Gudge以进行更详细的奖励设计是一个重要领域,这是对未来工作的重要领域,从而缩小这一差距。Multi-LLM AB-MCT是一种雄心勃勃的方法,旨在通过合作多个边界模型来通过推理时间缩放来提高性能。在组合多个LLM的方面,其他方法,例如多基因辩论,,,,代理的混合物, 和LE-MCT还提出了。研究我们的方法与这些相关技术之间的关系仍然是未来工作的另一个领域。
结论
在这项工作中,我们引入了多LLM AB-MCT,作为利用多个高性能边界AIS作为集体智能的框架。我们的最初实验表明,多LLLM AB-MCT可以在具有挑战性的ARC-AGI-2基准上实现高性能。我们已经发布了基础算法Treequest,在Apache 2.0许可下,用于推理时间缩放的树搜索软件框架。TreeQuest具有灵活的API,允许用户将AB-MCT和多LLM AB-MCT应用于具有最小代码的各种任务,并自由实现自定义评分和生成逻辑。它的检查点功能可以轻松地从API错误中恢复,从而实现了长期运行的复杂任务。
我们认为这些结果很重要,因为它们建议在推理时间缩放中未开发的潜力。自2024年中期以来,通过增强学习优化推理过程的推理模型已将推理时间缩放时代作为模型缩放后的下一个范式迎来了一个时代。我们的方法表明,通过反复执行这些模型的推理并将多个LLM与独特的个性相结合,可以进一步增强推理性能。这指向推理时间缩放的新方向,例如试用和集体智慧用于推理模型。Sakana AI将继续基于这项研究来推进AI,重点介绍了先驱新型AI系统的进化原理和集体智慧的原则。
有关此研究的更多详细信息,请参阅以下材料:
纸:更宽还是更深?
- 使用自适应分支树搜索缩放LLM推理时间计算https://arxiv.org/abs/2503.04412
- 算法代码:https://github.com/sakanaai/treequest
- ARC-AGI-2实验代码:https://github.com/sakanaai/ab-mcts-arc2

Sakana Ai
有兴趣加入我们吗?请看我们职业机会有关更多信息。