
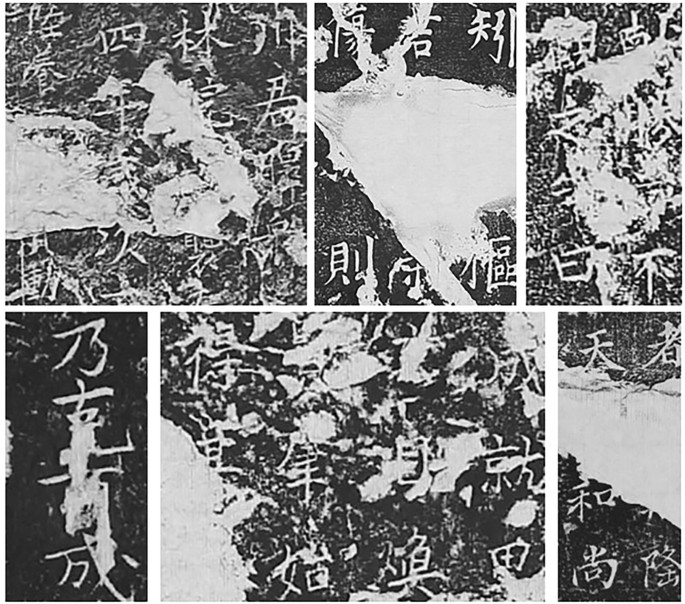
Chinese inscription restoration based on artificial intelligent models
作者:Li, Honglei
Related technologies and practices
Machine learning is a branch of artificial intelligence, whose goal is to make computers have human intelligence9. Deep learning is an important branch of machine learning, with complex structures that construct powerful multi-layer neural network models10.
When faced with a situation where the inscriptions have missing characters, filling in the missing characters becomes a crucial and challenging task in inscription restoration. Currently, the mainstream deep learning models for this task are based on a Transformer, which is a complicated but powerful architecture to process sequential data through self-attention mechanisms and capture long-distance dependencies of the text11. BERT12 and RoBERTa13 are two famous models based on Transformers. In practice, BERT and RoBERTa have shown excellent performance in natural language understanding tasks. Assael et al. proposed a model called Pythia, which combines LSTM14 and an attention mechanism to predict missing ancient Greek inscriptions. On the PHI-ML dataset, Pythia’s prediction error rate reached 30.1%, lower than that of epigraphers15. Afterwards, Assael et al. further proposed Ithaca, which was inspired by BigBird16. Its architecture consists of multiple Transformer decoders that can effectively capture contextual information. It achieved an accuracy of 62% when restoring damaged text. After collaborating with epigraphers, the accuracy was improved to 72%17. Fetaya et al. achieved an accuracy of 88.5% in the testing task of recovering Babylonian script based on recurrent neural networks18. Kang et al. proposed a multi-task learning method based on a Transformer network to effectively restore and transform the historical records of Joseon Dynasty19.
Since Chinese characters are not composed of alphabets but of graphic radicals, NLP models trained for missing or incomplete ancient Chinese texts require context. Yu et al. achieved good results in automatic sentence-breaking and punctuation models for ancient Chinese by training BERT in ancient Chinese20. Dongbo et al. constructed SikuBERT and SikuRoBERTa for the intelligent processing of ancient Chinese texts using a high-quality Chinese text corpus. The result showed that their proposed models outperformed the basic BERT model and other models in ancient Chinese text-processing tasks21. Sheng et al. constructed a high-quality text corpus of ancient books of Chinese traditional medicine, trained and compared several deep learning models, and found that the Roberta model had the best performance, which could help the restoration of ancient books of traditional Chinese medicine22. Zheng J. and Sun J. used ensemble learning methods to integrate Chinese BERT, Chinese RoBERTa, SikuBERT, and SikuRoBERTa for prediction tasks related to ancient Chinese. The grid search method composed of SikuBERT and SikuRoBERTa achieved the best performance in the ensemble model23. Han et al. proposed RAC-BERT, an improved BERT model based on Chinese radical parts. By replacing random Chinese characters with the same radical, the model reduced the computational complexity while maintaining higher performance24.
CV models are also useful in inscription restoration. This kind of task involves the partially damaged characters in inscriptions. At present, the main model architectures used for ancient inscriptions are convolutional neural networks (CNN), generative adversarial networks (GAN), Transformers, and their extended architectures.
Convolutional neural network is a common model composed of convolutional layers, activation functions, pooling layers, and fully connected layers. CNN effectively extracts local features from images25. Zhang used CNN to extract features from residual inscriptions. His model adopted the cross-layer idea of ResNet26. By adding residual modules based on VGGNet27, the accuracy of residual inscription text recognition was improved28. Xing and Ren addressed the issue of insufficient character information extraction in existing models by improving the context encoder29 and adding dilated convolutions to learn the structural features of characters, thereby repairing missing stroke inscriptions30. Feng et al. used DenseNet31 from the backbone network to alleviate gradient vanishing and model degradation, while enhancing feature reuse and transfer to improve the recognition performance of ancient handwritten texts32. Zhao et al. proposed the Ga-RFR network, which reduces feature redundancy in the generated feature maps by using gated convolutions instead of regular convolutions, thereby improving the restoration performance of Chinese inscriptions33. Lou Y. also used gated convolution to improve deep networks, reducing the generation of a large amount of redundant feature information, and combining multiple loss functions to enhance the model’s ability to repair inscription images34.
GAN consists of generators and discriminators, which constantly competes during the training process, ultimately enabling the generator to generate samples increasingly difficult to distinguish from real data35. Its approach and functionality make it more suitable for image-based text restoration tasks. GAN provides a new solution to the restoration of inscriptions, especially for large-scale missing inscriptions. This network can fill in the gaps in the image through generative techniques. For example, Li N. and Yang W. used a GAN with global and local consistency preservation (GLC-GAN) to complete handwritten text images, and proposed a two-level completion system consisting of rough and fine completion36. Wenjun et al. imitated human writing behavior and proposed a dual-branch structure character recovery network EA-GAN that integrated GAN and attention. This network has good performance in extracting character features, and even if the damaged area of the text is large, EA-GAN can also accurately recover damaged characters37. Liu et al. used an edge detection module to collect edge information on character strokes and guided GAN to learn the structure and semantics of characters. Their method achieved better repair quality38.
Based on the Transformer architecture, Chen et al. proposed a lightweight Qin Bamboo Slips text recognition model QBSC Transformer, which used a fusion of separable convolution and window self-attention mechanism to extract global features of Qin Bamboo Slips text. It significantly reduced computational complexity while maintaining high accuracy39. Hao and Chen combined Swin Transformer and Mask R-CNN40 to perform text segmentation on Chinese inscriptions41. Swin Transformer effectively processed image data by designing hierarchical feature maps and windowed self-attention mechanisms. It also showed excellent performance in image classification tasks42.
In addition, other models and repair strategies achieved satisfactory results. Lin et al. judged whether Chinese characters were damaged based on Chinese character splitting and embedding, and then used a bipartite graph neural network to predict the possible results of Chinese characters43. Sun C. and Hou M. focused on using edge detection methods to smooth and fill the extracted text contour to restore the fuzzy text44.
For repairing inscriptions, NLP models and CV models have achieved exciting results along with limitations. For NLP models, the performance is greatly limited by the volume of prepared ancient texts since the grammar, syntax, genre, and usage heavily vary in different dynastic periods. For the writing of Chinese characters, it is challenging to recognize a Chinese character in thousands of regular and variant character repositories with over 30 kinds of fonts45. It forces us to try two kinds of models to restore Chinese ancient inscriptions in text and vision dimensions. It is a naturally thoughtful solution. The NLP model is undoubtedly essential to missing or damaged characters prediction. It will output many possible characters in descending order of probabilities. However, expert can still hardly decide the right one due to the hallucination. If there remain partial radicals of the character, we can get characters with the same partial radicals through ancient character CV models. Experts will choose the more likely characters in smaller range from the two groups of predicted characters. However, CV models are not available if the character completely disappears.
Technical roadmap
The architecture proposed in this paper is to predict missing or incomplete characters in Chinese inscriptions through NLP model and CV model. We introduce the pre-trained models to help the model training, as well as provide the joint tactic of two models. The technical roadmap is illustrated by the flowchart in Fig. 2.
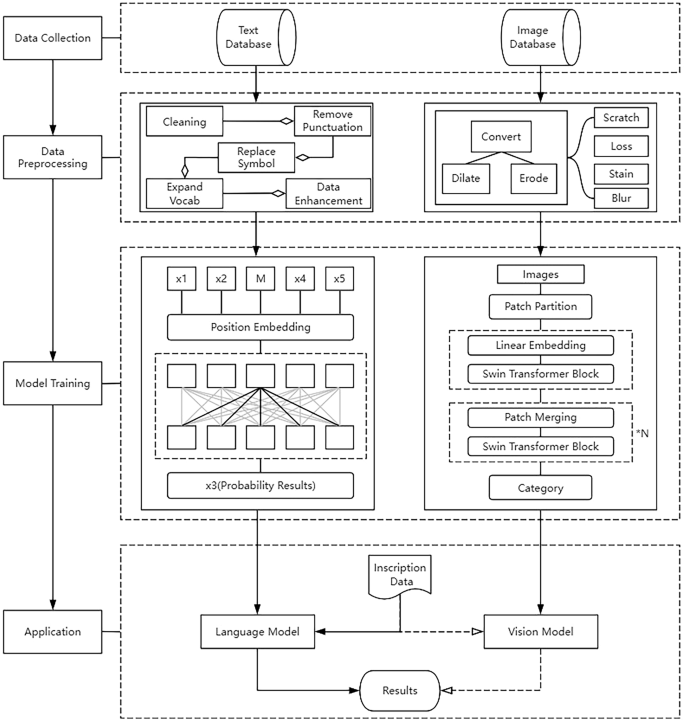
Technology Roadmap of inscription restoration.
In the model training step, texts and images of inscriptions are pre-processed for higher quality. Then, the NLP model and CV model are trained based on selected pre-trained models. When models are validated and deployed, missing or incomplete characters are fed into the models for restoration. Top n predicted characters with higher possibilities are introduced to experts for the final decision. If characters are incomplete, that means characters are partially damaged, and the CV model outputs complete characters based on incomplete images. In these most common cases, characters with the biggest f1_score are preferred recommendations. f1_score is introduced here to leverage two possibility values of NLP model and CV model, whose original definition involves precision and recall. In this research, f1_score is redefined with two possibility values in Eq. 1.
$${\rm{f}}1\_{\text{score}}=\frac{2* {{\rm{P}}}_{n}* {{\rm{P}}}_{v}}{{{\rm{P}}}_{n}+{{\rm{P}}}_{v}}$$
(1)
Where pn is the possibility of character output by NLP model and pv is the possibility of character output by CV model.
Predictions resulting from two different models contribute more to selecting the right character than any individual model. Figure 3 shows a prediction example.

The restoration example.
Data preparation
For the inscription textual data, the types of collected data include but are not limited to:
-
a.
Metal and stone vessels: bronzes, coins, etc.
-
b.
Rocks: cliff, stone carving, tablet, etc.
-
c.
Stele: tombstone, merit stele, chronicle stele, inscription stele, religious stele, etc.
-
d.
Others: seals, oracle bones, epitaphs, statue tablets, stone scriptures, tower inscriptions, architectural inscriptions, etc.
We firstly removed punctuation marks, because there are no punctuation marks in ancient Chinese inscriptions. Then, we marked the missing or incomplete characters with unweighted special symbols to keep them from the computation during model training.
Since the writing fonts of inscriptions are firmly sparse, we were confronted with the challenges of recognition of characters in inscriptions from different historical periods or stylistic variations. We conducted dataset augment with the help of multiple localized experts few-shot font generation network (MX-Font). As a few-shot font generation (FFG) model, MX-Font can extract multiple style features not explicitly conditioned on component labels, but automatically by multiple experts to represent different local concepts. With the multiple experts, MX-Font can capture diverse local concepts and show the generalization ability to unseen languages46.
We collected 22,000 calligraphy images of traditional Chinese characters from public calligraphy repositories and inscription databases. Only the stele text data from Zhejiang University stele inscription database (Fig. 4)47 and other inscription databases were up to 11,588 pieces of inscriptions.

Zhejiang University stele inscription database.
We classified calligraphy images into different stylistic groups such as Kaishu, Xingshu, Caoshu, Weibei, Xiaozhuan, Lishu and etc. Then OpenCV was used to convert calligraphy images into SVG images, and FontForge48 was used to convert the Chinese character SVG images into TTF files. These TTF files were merged with the same font style files of MX-Font. Finally, we used MX-Font to get images of over 19000 traditional Chinese characters in different calligraphy styles. Examples are shown in Fig. 5.

Traditional Chinese character font styles.
In addition, due to the long history, surfaces of many inscriptions have become illegible, so we oversampled the image data to simulate the defacement of inscriptions. We used the following operations to simulate the damage state of inscription text: scratch, loss, stain and blur. We first performed the following operations several times respectively, then merged the processed images with the original data, and expanded the dataset.
The scratch operation: randomly drawing line segments on the image.
The loss operation: randomly cropping the image in random size.
The stain operation: randomly covering areas with irregular shapes.
The blur operation: adding 8 different levels of noise to the image. Gaussian noise and salt-pepper noise were respectively used. In addition, we also used all these operations in a image.
Take the Chinese character “锕” as an example, the augmented images are shown in Fig. 6.

augmented images of Chinese character.
NLP model preparation
The Mask Language Model (MLM) is suitable for the pre-processed task of inscriptions. Meanwhile, since Chinese ancient inscriptions are all traditional characters, the writing formats and word styles are much more diverse like those in ancient books, and there have been no pre-trained models of inscriptions as yet. We chose SikuRoBERTa as the pre-trained model according to Zheng and Sun’s research. Siku series models pay more attention to the current and contextual tokens than present Bert-based models49. We have also expanded the vocabulary of SikuRoBERTa by adding 757 new Chinese characters found in collected inscriptions.
As an improved version of Bert, Roberta removes the next sentence prediction task and deepens the mask language task suitable for predicting missing or incomplete characters in inscriptions. It is praised for dynamic masks, larger batches, and more training data to obtain better performance13, in which the dynamic mask can increase the diversity of datasets and enable the model to learn different modes of data better. Taking 唐秘書監知章之後也 as an example, the role of dynamic mask results are shown in Table 1:
The pre-processed dataset was fed into the model. In order that the model can learn features of small inscriptions dataset compared with the pre-trained NLP model, we oversampled the dataset to 10 times the original volume to increase the weight of fine-tuning data and reduce the learning rate. As a result, the model well learned the context information contained in inscriptions. By the way, the mask scale was set to 0.15 proposed by MLM.
CV model preparation
Character recognition is also regarded as a kind of image classification task. We chose the Swin Transformer as the pre-trained model for incomplete character restoration. Compared with vision Transformers directly applying the standard Transformer structure to images50, the Swin Transformer introduces the hierarchical construction method commonly used in CNN to build a hierarchical Transformer42, which effectively extracts strokes, structures, and other textual features in images of texts at different levels.
For example, at a lower level, the model may focus on strokes. At a higher level, the model may focus on the overall layout of the text. In addition, the shifted window of Swin Transformer allows the model to capture the relative position and layout information between strokes.
Evaluation metrics
Perplexity defined in Eq. 2 is used to evaluate the NLP model after training.
$${\rm{P}}{\rm{e}}{\rm{r}}{\rm{p}}{\rm{l}}{\rm{e}}{\rm{x}}{\rm{i}}{\rm{t}}{\rm{y}}={{\rm{e}}}^{-\frac{1}{N}\displaystyle \mathop{\sum }\limits_{i=0}^{N}log\,p(x|{x}_{ < i})}$$
(2)
Where N is the total number of tokens, x is the character in the text, and p is the probability of x predicted by the model. Perplexity indicates the performance of the model to predict the text. The lower the value is, the better the performance is.
We used accuracy to evaluate the trained CV model. It is defined in Eq. 3.
$${Accuracy}=\frac{{TP}+{TN}}{{TP}+{TN}+{FP}+{FN}}$$
(3)
Where TP (True Positive) is the number of positive predictions whose actual values are positive.
TN (True Negative) is the number of negative predictions whose actual values are negative.
FP (False Positive) is the number of positive predictions of whose actual values are negative.
FN (False Negative) is the number of negative predictions whose actual values are positive.
关于《Chinese inscription restoration based on artificial intelligent models》的评论
发表评论
摘要
相关讨论
- 大早上打扰了,请教审核问题 3.1: Apps or metadata that mentions the name of any other mobile platform will be rejected
- 刷Leetcode (01) Remove Duplicates from Sorted Array
- 分享一个消息:新加坡奇缺数据科学方面人才
- [上海] Wiredcraft 招聘Javascript CSS前端开发;Node.js Golang Python后端开发程序猿!还有QA Tester;DevOps;项目经理等职位等你来投!!
- Google Code shutting down