

Unlock faster, efficient reasoning with Phi-4-mini-flash-reasoning—optimized for edge, mobile, and real-time applications.
State of the art architecture redefines speed for reasoning models
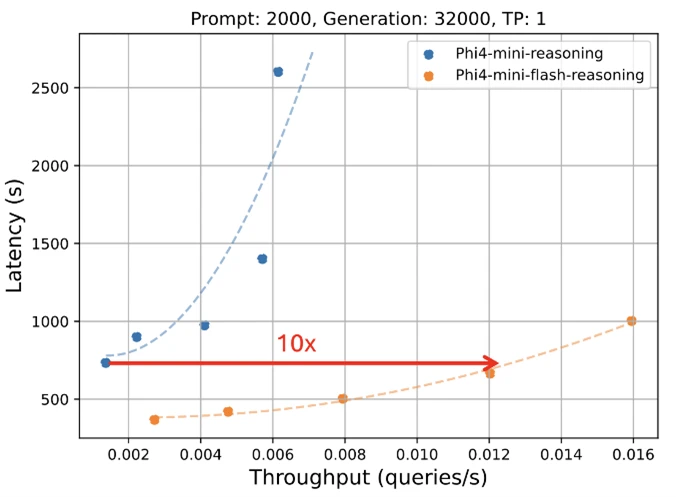
Microsoft is excited to unveil a new edition to the Phi model family: Phi-4-mini-flash-reasoning. Purpose-built for scenarios where compute, memory, and latency are tightly constrained, this new model is engineered to bring advanced reasoning capabilities to edge devices, mobile applications, and other resource-constrained environments. This new model follows Phi-4-mini, but is built on a new hybrid architecture, that achieves up to 10 times higher throughput and a 2 to 3 times average reduction in latency, enabling significantly faster inference without sacrificing reasoning performance. Ready to power real world solutions that demand efficiency and flexibility, Phi-4-mini-flash-reasoning is available on Azure AI Foundry, NVIDIA API Catalog, and Hugging Face today.
Efficiency without compromise
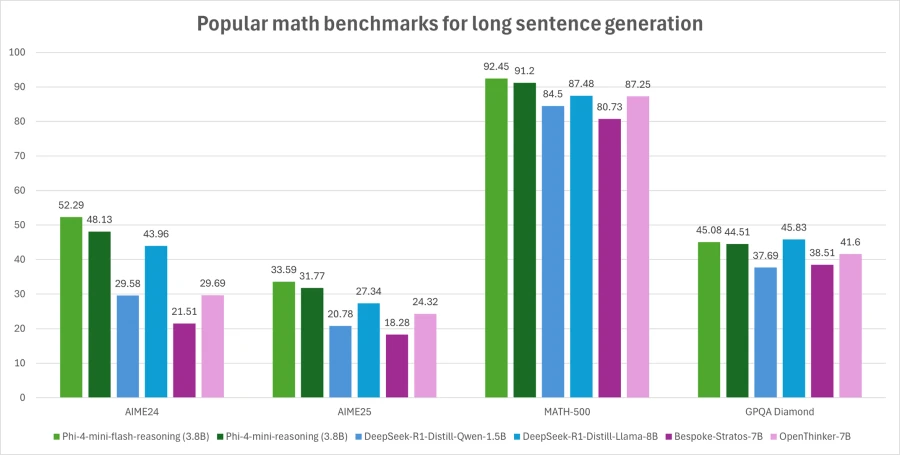
Phi-4-mini-flash-reasoning balances math reasoning ability with efficiency, making it potentially suitable for educational applications, real-time logic-based applications, and more.
Similar to its predecessor, Phi-4-mini-flash-reasoning is a 3.8 billion parameter open model optimized for advanced math reasoning. It supports a 64K token context length and is fine-tuned on high-quality synthetic data to deliver reliable, logic-intensive performance deployment.
What’s new?
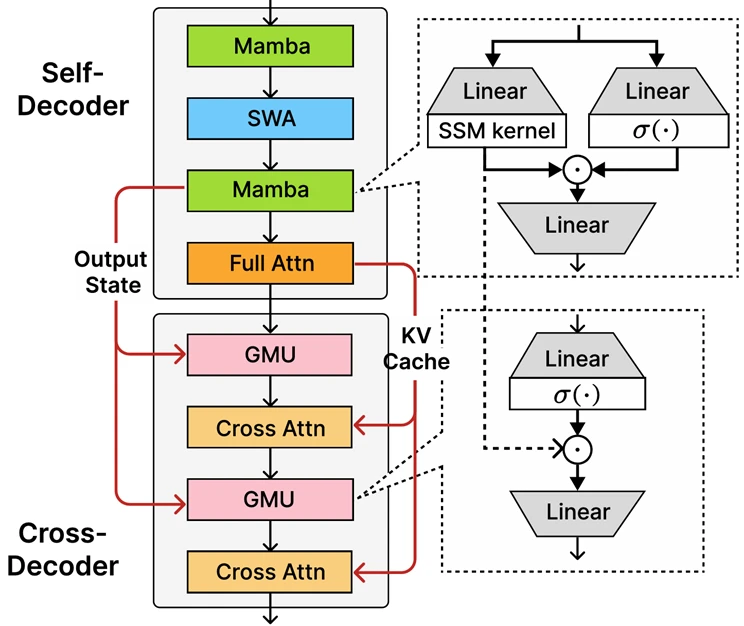
At the core of Phi-4-mini-flash-reasoning is the newly introduced decoder-hybrid-decoder architecture, SambaY, whose central innovation is the Gated Memory Unit (GMU), a simple yet effective mechanism for sharing representations between layers. The architecture includes a self-decoder that combines Mamba (a State Space Model) and Sliding Window Attention (SWA), along with a single layer of full attention. The architecture also involves a cross-decoder that interleaves expensive cross-attention layers with the new, efficient GMUs. This new architecture with GMU modules drastically improves decoding efficiency, boosts long-context retrieval performance and enables the architecture to deliver exceptional performance across a wide range of tasks.
Key benefits of the SambaY architecture include:
- Enhanced decoding efficiency.
- Preserves linear prefiling time complexity.
- Increased scalability and enhanced long context performance.
- Up to 10 times higher throughput.
Phi-4-mini-flash-reasoning benchmarks
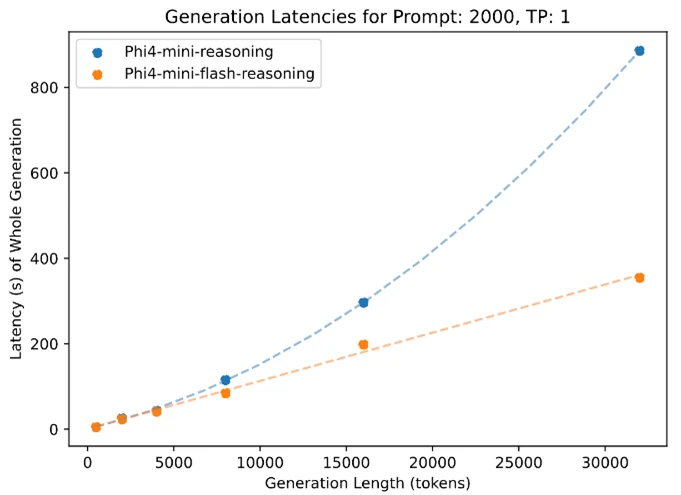
Like all models in the Phi family, Phi-4-mini-flash-reasoning is deployable on a single GPU, making it accessible for a broad range of use cases. However, what sets it apart is its architectural advantage. This new model achieves significantly lower latency and higher throughput compared to Phi-4-mini-reasoning, particularly in long-context generation and latency-sensitive reasoning tasks.
This makes Phi-4-mini-flash-reasoning a compelling option for developers and enterprises looking to deploy intelligent systems that require fast, scalable, and efficient reasoning—whether on premises or on-device.
What are the potential use cases?
Thanks to its reduced latency, improved throughput, and focus on math reasoning, the model is ideal for:
- Adaptive learning platforms, where real-time feedback loops are essential.
- On-device reasoning assistants, such as mobile study aids or edge-based logic agents.
- Interactive tutoring systems that dynamically adjust content difficulty based on a learner’s performance.
Its strength in math and structured reasoning makes it especially valuable for education technology, lightweight simulations, and automated assessment tools that require reliable logic inference with fast response times.
Developers are encouraged to connect with peers and Microsoft engineers through the Microsoft Developer Discord community to ask questions, share feedback, and explore real-world use cases together.
Microsoft’s commitment to trustworthy AI
Organizations across industries are leveraging Azure AI and Microsoft 365 Copilot capabilities to drive growth, increase productivity, and create value-added experiences.
We’re committed to helping organizations use and build AI that is trustworthy, meaning it is secure, private, and safe. We bring best practices and learnings from decades of researching and building AI products at scale to provide industry-leading commitments and capabilities that span our three pillars of security, privacy, and safety. Trustworthy AI is only possible when you combine our commitments, such as our Secure Future Initiative and our responsible AI principles, with our product capabilities to unlock AI transformation with confidence.
Phi models are developed in accordance with Microsoft AI principles: accountability, transparency, fairness, reliability and safety, privacy and security, and inclusiveness.
The Phi model family, including Phi-4-mini-flash-reasoning, employs a robust safety post-training strategy that integrates Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning from Human Feedback (RLHF). These techniques are applied using a combination of open-source and proprietary datasets, with a strong emphasis on ensuring helpfulness, minimizing harmful outputs, and addressing a broad range of safety categories. Developers are encouraged to apply responsible AI best practices tailored to their specific use cases and cultural contexts.
Read the model card to learn more about any risk and mitigation strategies.
Learn more about the new model
- Try out the new model on Azure AI Foundry.
- Find code samples and more in the Phi Cookbook.
- Read the Phi-4-mini-flash-reasoning technical paper on Arxiv.
- If you have questions, sign up for the Microsoft Developer “Ask Me Anything”.
Create with Azure AI Foundry
- Get started with Azure AI Foundry, and jump directly into Visual Studio Code.
- Download the Azure AI Foundry SDK .
- Take the Azure AI Foundry learn courses.
- Review the Azure AI Foundry documentation.
- Keep the conversation going in GitHub and Discord.