
An end-to-end multifunctional AI platform for intraoperative diagnosis
作者:Cai, Muyan
Introduction
Intraoperative frozen diagnosis is a critical technique in surgical pathology1, allowing rapid tissue sample analysis to guide surgical decisions in real-time2. However, the accuracy of this diagnosis depends significantly on the quality of the frozen tissue sections, which is often compromised by the time-sensitive nature of surgery3. Tissue degeneration, contraction during freezing, and suboptimal staining frequently lead to artifacts or unclear nuclear and cytoplasmic details, all of which can obscure diagnostic features4,5,. These quality issues make frozen section interpretation challenging for pathologists, affecting diagnostic reliability and confidence6. Therefore, improving the frozen section quality is critical to advancing intraoperative diagnostic accuracy.
Deep learning has emerged as a powerful tool in digital pathology for various tasks, including image quality enhancement7,8. Generative adversarial networks (GANs) have shown particular promise, as they can learn from data distributions and generate synthetic data that closely mirrors real samples9,10. Previous studies have shown that GANs can be effectively applied to image enhancement, producing high-resolution synthetic images that can even deceive experienced pathologists11,12. The ability to generate high-quality synthetic images makes GANs a promising candidate for improving the quality of frozen histologic images. GANs have even been demonstrated to enhance cryosectioned image quality by transforming them to resemble formalin-fixed, paraffin-embedded (FFPE) tissue images, a standard in histopathology13,14. Despite these promising advances, there remains a lack of comprehensive evaluation on the clinical impact, reliability, and utility of these methods within the context of an end-to-end intraoperative diagnostic workflow.
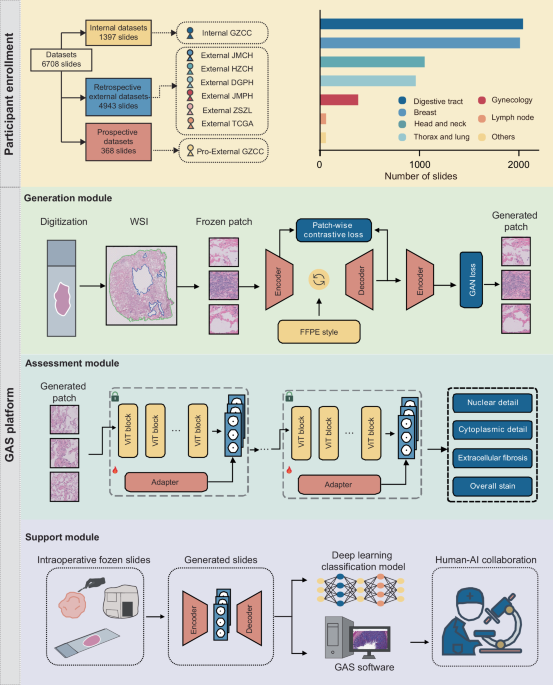
To address these challenges, we introduce GAS, a multifunctional, end-to-end framework tailored for intraoperative frozen diagnosis, which includes three integrated modules: the Generative, Assessment and Support modules. The Generation module, trained using a GAN-based multimodal network, effectively converts frozen section images into high-quality virtual FFPE-style images, guided by descriptive text annotations15. The Assessment module utilizes four quality control models, fine-tuned from foundational pathology models, to objectively assess the quality of these generated images. Substantial improvements in microstructural details are demonstrated over the original frozen sections. Finally, the Support module integrates GAS into routine clinical practice through a human-artificial intelligence (AI) collaboration platform, improving pathologists’ diagnostic confidence within prospective cohorts. Our study highlights the clinical utility of the GAS platform in intraoperative diagnostics, establishing a model for integrating end-to-end AI solutions into standard clinical workflow.
Results
Study participants
In this study, we introduced the GAS platform to provide a comprehensive diagnostic process that optimizes frozen section images, evaluates quality, and supports clinical decision-making through multiple integrated modules. To achieve this, we utilized six cohorts comprising over 6700 whole-slide images (WSIs) for model training and validation, as shown in Fig. 1. The Internal GZCC cohort served as the training and internal validation dataset, consisting of 553 frozen and 844 FFPE slides from 325 patients. External validation included four retrospective cohorts and one prospective cohort. Specifically, the External JMCH cohort comprised 228 frozen slides and 310 FFPE slides from 191 patients, the External HZCH cohort contained 225 frozen and 225 FFPE slides from 225 patients, the External DGPH cohort contained 114 frozen and 115 FFPE slides from 115 patients, the External JMPH cohort had 103 frozen and 86 FFPE slides each from 77 patients, the External ZSZL cohort had 1500 frozen slides from 674 patients, the TCGA cohort contained 1180 frozen and 857 FFPE slides from 815 patients. The prospective cohort, Pro-External GZCC, included 189 frozen and 179 FFPE slides from 188 patients. All slides were initially scanned at ×40 magnification and subsequently downsampled to ×20 for model training, considering both clinical relevance and computational efficiency. Details of participant characteristics are presented in Table 1.

The datasets were derived from eight different cohorts, with the Internal GZCC data used for model training and data from the other cohorts utilized to externally test the model’s generalization performance. The number of included slides from different organs was illustrated in the column chart. The GAS platform comprises three modules: the Generation module, the Assessment module, and the Support module. The Generation module was trained using a GAN-based multimodal network guided by text descriptions of the FFPE style. The Assessment module included four microstructural quality control models, which were developed by fine-tuning a pathological foundation model using only a small number of patches. The Support module was conducted on a human-artificial intelligence collaboration software to aid pathologists to make diagnoses. FFPE formalin-fixed, paraffin-embedded, WSI whole-slide image, GAN generative adversarial network.
Development of a generation module for optimizing frozen section images
To generate virtual FFPE-like images from frozen sections, we developed the Generation module of the GAS platform. This module employed a GAN-based multimodal unpaired transfer network, with both image- and patch-level supervision, making it adaptable to various tumor types. The transformation process was further guided and compared using text descriptions representing various histological styles. Among these, the style described as ‘formalin-fixed paraffin-embedded tissues’ consistently yielded the most favorable results within the Internal GZCC cohort (Supplementary Table 1). Consequently, this FFPE style was adopted to guide the transformation, enhancing the visual fidelity of the synthetic images to real FFPE samples (Fig. 2a). Notable quality improvements were observed across multiple organ types (Fig. 2b–d, Supplementary Fig. 1 and Supplementary Data no. 1).

a The architecture of the generative model consisted of three key components: an encoder, a style neck, and a decoder. The style neck was responsible for transferring the style from frozen to FFPE patches. b–d Examples showed that the GAS-generated images improved image quality across various organs. e–g Confusion matrices presented the classification results (generated or real FFPE patches) of three pathologists. FFPE formalin-fixed, paraffin-embedded, GAN generative adversarial network.
To assess the fidelity of the generated images compared to real FFPE images, a reader study was conducted. Three pathologists reviewed 200 image patches and classified them as either generated or real. The pathologists classified 50–72% of synthetic images as real FFPE and 26–47% of real FFPE images as generated (Fig. 2e–g). Low inter-observer agreement indicated that pathologists could not reliably differentiate real FFPE from synthetic images. An additional reader study was conducted to identify whether pathologists can distinguish frozen images from the generated images. Results showed a high classification accuracy ranging from 89.5 to 93.5% (Supplementary Fig. 2), indicating that the generated images were visually distinct from frozen images.
Evaluation of the generation module using Fréchet inception distance (FID)
The Generation module of the GAS platform was assessed for its performance in producing FFPE-like images using FID, a widely accepted metric for assessing image similarity and quality13. The FID values, which quantify the similarity of generated images to real FFPE images—where lower values indicate greater similarity - were evaluated against state-of-the-art generative models across multiple datasets (Fig. 3a). In the independent test cohort of Internal GZCC, GAS achieved a superior FID of 23.021, outperforming other generative models with FID values ranging from 23.717 to 64.977. Similar advantages were observed in external validation cohorts (Fig. 3b–g and Supplementary Table 2). These results collectively demonstrated that GAS consistently produces high-quality FFPE-like images that closely resembled real FFPE images across diverse datasets.

a The workflow for calculating the FID. b–g The FID of different generative model across different cohorts: Internal GZCC, External JMCH, External HZCC, External DGPH, External JMPH, and Pro-External GZCC. Internal GZCC, the test cohort of the retrospective internal cohort; External JMCH, External HZCH, External DGPH, and External JMPH, four retrospective external cohorts; Pro-External GZCC, the prospective study. FFPE formalin-fixed, paraffin-embedded, FID Frechet Inception Distance.
Establishment of an assessment module for quality control
To complement the evaluation of similarity between generated and FFPE images, we established the second component of the GAS platform: the Assessment module. This module comprised four quality control models designed to automatically assess critical pathological features: nuclear detail, cytoplasmic detail, extracellular fibrosis, and overall stain quality (Fig. 4a). A total of 1020 image patches from frozen, generated, and FFPE sections across multiple organs were used for model training and validation (Supplementary Table 3), with 816 patches fine-tuned on a pathological foundation model to train four binary classifiers. High- and low-quality labels were established by consensus between two expert pathologists, following criteria detailed in Supplementary Table 4. Compared to a 4-tier scoring system (excellent to very poor), the binary labeling showed higher inter-rater consistency (Supplementary Figs. 3 and 4). In independent testing, all four binary labeling models achieved strong performance: nuclear detail [Area under the curve (AUC 0.973, accuracy 0.922], cytoplasmic detail (AUC 0.975, accuracy 0.941), extracellular fibrosis (AUC 0.871, accuracy 0.877), and overall stain quality (AUC 0.965, accuracy 0.941) (Fig. 4b, c).

a The workflow of developing quality control models in the Assessment module. The adapter architecture was applied to fine-tune the foundation model to adapt to the quality assessment task. b The area under the curve (AUC) of different items (nuclear detail, cytoplasmic detail, extracellular fibrosis, and overall stain quality) in the validation cohort of quality control models. c Confusion matrices presented the classification results (low or high quality) of the quality control models predicting different items in the validation cohort of quality control models. d The column chart displayed the percentage of high-quality and low-quality images for GAS-generated (G) and frozen (F) images in the test cohort of the Internal GZCC dataset. e Gradient-weighted Class Activation Mapping (Grad-CAM) highlighted the areas of focus for the quality control models.
To verify that the models effectively captured the intended features, Gradient-weighted Class Activation Mapping (Grad-CAM) was applied. Overlaying Grad-CAM heatmaps onto H&E patches, revealed that the nuclear detail, cytoplasmic detail, and extracellular fibrosis models accurately focused on their respective features: nuclei, cytoplasm, and extracellular fibrosis. These visualizations confirmed that the Assessment module successfully evaluated the quality of the specified pathological features (Fig. 4d and Supplementary Fig. 5).
Image quality evaluation by the assessment module
The Assessment module was utilized to assess and compare the quality of frozen images and GAS-generated images. Substantial improvements in the quality of generated patches were observed across all evaluated features in the Internal GZCC cohort. For nuclear detail, the proportion of high-quality patches increased from 38.26% in frozen patches to 61.19% in generated patches, marking a 22.93% improvement. In the cytoplasmic detail item, high-quality patches rosed from 31.19% in frozen patches to 64.78% in generated patches, an improvement of 33.59%. For extracellular fibrosis, the percentage of high-quality patches increased from 87.88% in frozen patches to 97.91% in generated patches, reflecting a 10.03% improvement. Regarding overall stain quality, high-quality patches increased from 70.93% in frozen patches to 92.23% in generated patches, demonstrating a 21.30% improvement (Fig. 4e).
The module was further applied across external validation cohorts, revealing consistent enhancements in image quality across diverse datasets. In the External JMCH cohort, generated images exhibited an increase in high-quality patches, with nuclear detail improving from 77.12 to 78.86%, cytoplasmic detail from 79.93 to 87.18%, extracellular fibrosis from 97.24 to 99.00%, and overall stain from 91.73 to 94.55%. In the External HZCH cohort, improvements were observed in nuclear detail (from 63.98 to 65.22%), cytoplasmic detail (from 69.14 to 78.75%), and overall stain quality (from 90.36 to 91.70%). In the External DGPH cohort, significant increases were seen in nuclear detail (from 56.64 to 69.38%), cytoplasmic detail (from 61.07 to 75.72%), extracellular fibrosis (from 95.74 to 98.31%), and overall stain quality (from 91.20 to 94.82%). The External JPCH cohort exhibited enhancements in nuclear detail (from 84.27 to 85.96%), cytoplasmic detail (from 87.29 to 92.36%), extracellular fibrosis (from 98.76 to 99.44%), and overall stain (from 96.97 to 97.89%). In the prospective Pro-External GZCC cohort, significant quality improvements were also observed in GAS-generated images compared to frozen images: nuclear detail increases from 8.74 to 25.45%, cytoplasmic detail improved from 20.45 to 40.45%, extracellular fibrosis rose from 80.32 to 87.50%, and overall stain improved from 41.57 to 69.27% (Supplementary Fig. 6). To assess its robustness, we applied our model to images with pronounced folds and poor quality. The generated images still demonstrated an increase in high-quality patches (Supplementary Table 5). These results underscore the effectiveness of the GAS platform in enhancing the quality of pathological microstructure, facilitating improved diagnostic evaluation.
Support module for clinical application
To assess the impact of GAS-generated images on diagnostic performance, we conducted several deep-learning classification tasks, comparing the results derived from GAS-generated images with those using original frozen images as inputs. For assessing margin positivity in breast cancer, GAS-generated images achieved a higher AUC of 0.874, compared to 0.862 for frozen images (P = 0.788, t test). Similarly, in distinguishing between benign and malignant breast lesions, the GAS-generated images outperformed frozen images, achieving an AUC of 0.784 compared to 0.765 (P = 0.254, t test). In addition, for differentiating between breast carcinoma in situ and invasive breast cancer, GAS-generated images again demonstrated superior performance, with an AUC of 0.722, compared to 0.696 for frozen images (P = 0.057, t test) (Fig. 5a–c). We also tested three additional tasks, including predicting sentinel lymph node metastasis in breast cancer, classifying lung cancers into adenocarcinoma or squamous cell carcinoma, and benign and malignant thyroid lesions. In these tasks, the generated images demonstrated higher diagnostic performance compared to frozen images (Supplementary Table 6). These consistently higher AUCs for GAS-generated images underscore the platform’s ability to transform frozen images into high-quality virtual FFPE-like images, significantly enhancing diagnostic accuracy in clinical applications.

a–c The violin plots illustrated the diagnostic performance of deep-learning models in margin assessment, distinguishing between benign and malignant breast lesions, and predicting breast carcinoma in situ and invasive breast cancer, respectively, using either GAS-generated images or frozen images as inputs. Statistical significance was assessed using the t test. d Screenshot of human–AI collaboration software. e The violin plots illustrated the initial diagnostic confidence of the three pathologists as well as their confidence after utilizing GAS assistance. Statistical significance was evaluated using the Wilcoxon signed-rank test. f–h Confusion matrices presented three pathologists’ initial diagnostic confidence and GAS-assisted confidence.
To further explore the clinical utility of GAS in intraoperative diagnostic workflows, we developed a human–AI collaboration software. The software allowed pathologists to review frozen WSIs and identified regions of low-quality requiring closer evaluation. These regions could then be selectively converted into virtual FFPE-like images for enhanced clarity (Supplementary Movie 1). We conducted a prospective assessment using a sub-cohort from the Pro-External GZCC cohort, which included 45 breast lesion samples (34 benign and 11 malignant). Three pathologists initially provided diagnoses and assigned diagnostic confidence levels (on a scale of 1–3, where 1 represents low confidence and 3 high confidence) based on frozen WSIs. After employing the GAS platform to convert unclear regions into virtual FFPE-like regions, the pathologists finalized their diagnoses and confidence levels. The time required for the GAS platform was demonstrated in Supplementary Table 7. While their diagnostic outcomes for distinguishing benign from malignant breast lesions remained unchanged with GAS assistance, their confidence levels significantly improved (all P < 0.001, Wilcoxon signed-rank test; Fig. 5d–h). To further validate this, we conducted two additional reader studies focusing on margin assessment and sentinel lymph node metastasis evaluation, respectively, to assess whether the Support Module could enhance pathologists’ diagnostic confidence. Consistent results were observed, with all three pathologists showing significantly increased confidence when using the Support Module (all P < 0.001, Wilcoxon signed-rank test; Supplementary Fig. 7). These findings highlight the GAS platform’s capability to enhance diagnostic confidence effectively. Moreover, the selective transformation approach enables efficient integration into routine testing workflows, underscoring the platform’s potential for broad clinical adoption.
Discussion
Despite the growing interest in AI for histopathology, few systems have achieved clinical integration, largely due to the absence of end-to-end, multifunctional solutions16. To bridge this gap, we developed GAS—a comprehensive platform for intraoperative diagnosis that integrates three key modules: Generation for virtual FFPE-like image synthesis, Assessment for quality control, and Support for decision assistance via human–AI collaboration. Unlike previous approaches that focus on narrow tasks or specific tumor types13, GAS provides a complete diagnostic pipeline with broad applicability across organs and clinical scenarios. Its consistent performance in prospective settings demonstrates strong potential for real-world deployment, especially in time-sensitive intraoperative workflows.
A critical bottleneck in the development and deployment of AI pathology systems lies in data quality, which directly affects model performance17,18. Manual quality control of large WSI datasets is impractical, and existing AI tools often focus only on technical artifacts such as blur or focus19,20. In this study, we leveraged a pathology foundation model and introduced a lightweight adapter-based fine-tuning strategy to develop four quality control models targeting nuclear detail, cytoplasmic detail, extracellular fibrosis, and stain quality. Compared to full fine-tuning, the adapter framework minimizes annotation burden, reduces computational cost, and mitigates catastrophic forgetting21. This approach aligns with the practical needs of clinical AI systems and offers a scalable path for extending to other pathology tasks.
Although FID is commonly used to quantify image realism, we observed a discrepancy between high FID values and pathologists’ inability to distinguish generated images from real ones. This stems from fundamental differences in evaluation principles: FID captures global statistical differences based on Inception-v3 features22, while pathologists rely on local morphological cues. In addition, FID is sensitive to clinically irrelevant variations and does not directly reflect diagnostic utility. To address this, we introduced a domain-specific Assessment module that evaluates nuclear and cytoplasmic quality, providing a pathology-informed supplement to FID and enabling a more nuanced, task-relevant assessment of image fidelity.
Our study has several limitations. First, the quality control models were developed based on four microstructural features drawn from prior work on virtual staining evaluation23. While aligned with standard pathology criteria, these features may not fully capture all diagnostic subtleties. Future work could explore unsupervised methods for more comprehensive image quality assessment with reduced reliance on manual annotation. Second, the Generation model shows limited robustness on severely degraded slides, highlighting the need to enhance artifact tolerance. Third, despite meeting intraoperative time constraints, system latency remains a concern. Techniques such as model compression, pruning, and mixed-precision inference may help reduce computational load in future clinical deployments. Lastly, the dataset was enriched for some types of cancer, such as breast and lung cancers, potentially limiting generalizability. Expanding to more diverse tumor types will be critical for broader validation.
In conclusion, GAS offers an end-to-end platform that enhances the reliability of intraoperative diagnoses and facilitates the integration of AI into clinical practice, paving the way for more efficient intraoperative decision-making.
Methods
Patient cohorts
This multicenter study included retrospective development and validation of the GAS platform, followed by a prospective validation to assess its generalizability. The Generation module was trained using retrospectively collected data from the Internal GZCC. External validation involved six independent cohorts from JMCH, HZCH, DGPH, JMPH, ZSZL, and TCGA. A prospective cohort was enrolled at Pro-External GZCC. All included patients had intraoperative diagnoses and matched post-operative FFPE-confirmed diagnoses. Frozen and FFPE slides were derived from the same surgical specimens, though exact pairing was not required due to the unpaired GAN architecture. Exclusion criteria included patients with incomplete clinical data and slides with extensive tissue folds, large fractures, or severe out-of-focus regions. The study was approved by the ethics committee of Sun Yat-sen University Cancer Center (No. SL-B2023-416-02), with informed consent waived for retrospective data and obtained for the prospective cohort.
Data digitalization
For each case, all available tumor slides were scanned at ×40 magnification (0.25 μm/pixel) for further analysis. Slides from the Internal GZCC, External HZCH, External DGPH, and Pro-External GZCC cohorts were scanned with a PHILIPS Ultra-Fast Scanner (Philips Electronics N.V., Amsterdam, Netherlands) and saved in iSyntax format. Meanwhile, slides from the External JMCH and External JMPH datasets were scanned using the Aperio AT2 scanner (Leica Biosystems, Wetzlar, Germany) and stored in SVS format.
Data preprocessing
For each digitized slide, CLAM’s preprocessing24 method was used to segment the tissue regions in the WSIs. Based on this segmentation mask, the tissue regions were partitioned into non-overlapping 512 × 512 patches at 20× magnification, with coordinates retained for the final reconstruction of the entire slide. Due to imperfections in the segmentation, partial background regions such as text or partial blank areas were often included. It was observed that background patches erroneously included exhibit distinctly different histogram distributions compared to tissue patches (Supplementary Fig. 8). To eliminate these background patches, all patches were converted to grayscale, and the mean and variance of their grayscale images were computed. Background patches were then filtered based on thresholds applied to these statistics. In addition, within the remaining patches, there were areas blurred due to lens defocus during slide scanning, which were identified and removed using the Laplacian method25.
Generation module
Model overview: To synthesize FFPE-like images from frozen sections, we developed the Generation module of the GAS platform, comprising an encoder, a style neck, and a decoder. The encoder downsampled inputs to expand the receptive field and reduce computational burden. The style neck enabled domain translation, and the decoder reconstructed the output, aided by skip connections to retain fine details lost during downsampling. Training optimized a weighted sum of adversarial26 and PatchNCE losses27. The adversarial loss drove global realism, while PatchNCE preserved local structural fidelity by maximizing mutual information between input and output patches.
Style neck: The style neck was composed of stacked residual blocks28. Crucially, the normalization layers within the residual blocks were Adaptive Instance Normalization (AdaIN) layers29, which accomplished the style transformation of the input images. The AdaIN layer altered the style of the input image through adaptive affine transformations (Eq. (1)):
$${AdaIN}\left(x,y\right)=\sigma \left(y\right)\left(\frac{x-\mu \left(x\right)}{\sigma \left(x\right)}\right)+\mu \left(y\right)$$
(1)
where x represented the input image and y represents the target style image. μ(·) and σ(·) denoted the mean and standard deviation, respectively. The original AdaIN layer required multiple computations of the affine parameters (the mean and standard deviation) from the style input. We proposed that the affine parameters could be directly predicted from text descriptions of the FFPE style, without the need for additional input images of the FFPE style and repeated calculations. There, we employed the text encoder of QuiltNet30 to text encoder encode the text representing the FFPE style, which was “formalin-fixed paraffin-embedded tissues”. The encoded text was then fed into a multilayer perceptron (MLP) to predict the affine parameters. Through this design, our generative model efficiently leverages pathology-specific knowledge embedded in the pretrained network to encode FFPE-style representations. These representations guide the image synthesis process, enabling the model to generate high-quality FFPE-like images from frozen section inputs.
Training configurations: Our model was optimized using the Adam31 optimizer with a learning rate set to 0.0002. It underwent training with a batch size of 1 over a maximum of 200 epochs. To ensure a fair comparison, all baseline models were trained under consistent settings. The generative model was trained with flip-equivariance augmentation, where the input image to the generator was horizontally flipped, and the output features were flipped back before computing the PatchNCE loss.
Differences from our method: Unlike prior approaches, our method is tailored for intraoperative scenarios, where rapid inference is essential. To this end, we use a lightweight encoder–decoder architecture with fewer layers and incorporate skip connections to mitigate feature loss during downsampling. Rather than relying on computationally intensive attention modules, we leverage domain knowledge embedded in a pathology-pretrained model to generate textual descriptions of FFPE characteristics. These are integrated into the generator via AdaIN, enabling fast and high-fidelity generation of FFPE-style images.
Reader study: To assess the fidelity of the generated images compared to real FFPE images, a reader study was conducted. Three pathologists reviewed 200 image patches (100 generated and 100 real FFPE) and classified them as either generated or real, and reviewed 200 image patches (100 generated and 100 frozen) and classified them as either generated or frozen.These image patches were randomly sampled from all test sets, and the sampling process was unbiased. Regarding tissue region selection, the preprocessing pipeline was consistent across datasets.
Assessment module
With the application of foundation models in computational pathology15,32,33,34, the ability of these models to extract general features from pathological images has significantly improved. We developed the Assessment module using pathological image quality control models derived from the foundation model. Then, the adapter architecture was introduced to enhance the model’s performance on the task of pathological image quality assessment. During training, the parameters of the foundation model were kept frozen, only the adapter and the projector used for prediction were trained. The foundation model consisted of 24 ViT blocks35. The adapter followed an MLP architecture. To retain the original knowledge encoded by the foundation model, a residual structure was introduced. Specifically, the output of the ViT block was fed into the adapter, and the adapter’s output was aggregated with the original features using a fixed parameter γ (Eq. (2)):
$${{\mathcal{F}}}_{l}^{* }=\gamma {A}_{l}{({F}_{l})}^{T}+(1-\gamma ){F}_{l}$$
(2)
Where Al denoted the adapter at layer l, Fl represented the output of the ViT block at layer l, and \({{\mathcal{F}}}_{l}^{* }\) indicated the output feature, which served as the input to the subsequent ViT block, and γ was set to 0.8 in this experiment36,37.
Compared to Low-Rank Adaptation (LoRA)38, a widely used parameter-efficient fine-tuning method that modifies model weights through low-rank matrix updates, the adapter approach adjusts features via external modules36,39,40. It combines original and adapted features using a scaling factor γ, allowing finer control over the degree of adaptation. As the foundation model, UNI21, was pretrained on over 100 million pathology images using the MoCoV341 framework and already captures extensive domain knowledge, the adapter strategy preserves core representations while introducing task-specific features for quality control, thereby improving overall performance.
The quality control models were trained using a batch size of 16, with training lasting up to 50 epochs. Optimization employed the Adam optimizer with an L2 weight decay set at 5e−5, along with a learning rate of 1e−5. Segmentation and patching of WSIs were performed on Intel(R) Xeon(R) Gold 6240 Central Processing Units (CPUs), and the models were trained on 4 NVIDIA GeForce RTX 2080 Ti Graphics Processing Units (GPUs).
To verify whether the quality control model attended to relevant features, we applied Grad-CAM. A forward pass produced the final convolutional feature map and the pre-softmax prediction score. Gradients of the score with respect to the feature map were then computed via backpropagation. Channel-wise importance weights were calculated, aggregated through a weighted sum, and passed through ReLU to generate the final localization map.
Deep-learning classification of support module
To evaluate whether the synthetic FFPE-like images generated by GAS provide greater utility in downstream classification tasks compared to frozen images, we designed a series of deep-learning classification tasks. These included: margin assessment, sentinel lymph node metastasis prediction in breast cancer, classification of benign versus malignant thyroid lesions, lung adenocarcinoma versus lung squamous cell carcinoma, benign versus malignant breast lesions, and breast carcinoma in situ versus invasive breast cancer.
For the task of distinguishing lung adenocarcinoma from lung squamous cell carcinoma, cases from TCGA were used to develop the model. For the classification of benign versus malignant thyroid lesions, benign versus malignant breast lesions, and carcinoma in situ versus invasive breast cancer, FFPE data were used for model development. In contrast, for margin assessment and sentinel lymph node metastasis tasks, diagnostic models were developed using either original frozen images or GAS-generated images only, without incorporating any FFPE data. The classification results obtained using GAS-generated images were compared with those using frozen images as inputs. The prediction process using the generated images was as follows: tissue regions in the frozen images were segmented and divided into 512 × 512 patches. Subsequently, synthetic FFPE-like patches were generated from frozen patches, and their features were extracted. Finally, the patch-level features were aggregated into a slide-level feature for prediction. The feature aggregation follows the attention-based pooling function introduced in CLAM (Eq. (3)):
$${a}_{i,k}=\frac{{e}^{\{{W}_{a,i}(\tan \,{\rm{h}}\,{V}_{a}{{\bf{h}}}_{k})\odot simg({U}_{a}{{\bf{h}}}_{k})\}}}{{\sum }_{j=1}^{K}{e}^{\{{W}_{a,i}(\tan \,{\rm{h}}\,{V}_{a}{{\bf{h}}}_{j})\odot simg({U}_{a}{{\bf{h}}}_{j})\}}}$$
(3)
$${{\boldsymbol{f}}}_{{slide},i}=\mathop{\sum }\limits_{k=1}^{K}{a}_{i,k}{{\boldsymbol{h}}}_{k}$$
Here, fslide,i denotes the aggregated feature representation for class i, ai,k is the attention score for patch k, and hk is the patch-level feature. Va and Ua are learnable fully connected layers, and Wa,i epresents one of N parallel attention branches.
GAS software of support module
A prospective assessment using a sub-cohort from the Pro-External GZCC cohort was conducted to validate the clinical utility of GAS in intraoperative diagnostic workflows. We developed a human–AI collaboration software to facilitate the process. Once the frozen sections were prepared, they were scanned to create digital slides. After uploading these slides to the GAS software, pathologists can browse the frozen sections online. If any areas appear unclear, the pathologists can click on the corresponding regions, and the software will convert these unclear areas into high-resolution FFPE-like images.
Quantification and statistical analysis
FID was used to measure image similarity for the generative models. Additionally, the quality control model evaluated the generative models using scoring as another metric. For the quality control model, accuracy and AUROC served as the primary evaluation metrics. The external test sets from different centers, allowed for a more comprehensive assessment of the generalization properties of GAS. A P value less than 0.05 was considered statistically significant. Statistical significance was evaluated using t test and Wilcoxon signed-rank test. Data preprocessing and model development were conducted using Python (version 3.8.0) and the deep-learning platform PyTorch (version 2.3.0).
Data availability
The digital whole-slide images (WSIs) from The Cancer Genome Atlas (TCGA) are publicly available at https://portal.gdc.cancer.gov. However, WSIs generated from other included cohorts are not publicly accessible due to data protection regulations and institutional guidelines. Statistical results derived from these WSIs can be provided upon reasonable request to the lead contact, following the completion of a data transfer agreement.
Code availability
The source code for model training is publicly available on GitHub (https://github.com/LexieK7/GAS). The GAS platform is also accessible as an open-source software tool at the same link, accompanied by a detailed tutorial designed for pathologists, developers, and other users interested in utilizing it for intraoperative diagnosis. The pretrained weights and training dataset of QuiltNet are available at https://github.com/wisdomikezogwo/quilt1m, and the pretrained weights of UNI are available at https://github.com/mahmoodlab/UNI. Further information and requests for resources and code should be directed to and will be fulfilled by the corresponding author.
References
Vergara, R. et al. Surgical pathology and sustainable development: international landscape and prospects. J. Clin. Pathol. 78, 233–239 (2025).
Ackerman, L. V. & Ramirez, G. A. The indications for and limitations of frozen section diagnosis; a review of 1269 consecutive frozen section diagnoses. Br. J. Surg. 46, 336–350 (1959).
Jaafar, H. Intra-operative frozen section consultation: concepts, applications and limitations. Malays. J. Med. Sci. 13, 4–12 (2006).
Renne, S. L., Redaelli, S. & Paolini, B. Cryoembedder, automatic processor/stainer, liquid nitrogen freezing, and manual staining for frozen section examination: a comparative study. Acta Histochem. 121, 761–764 (2019).
Chen, Y., Anderson, K. R., Xu, J., Goldsmith, J. D. & Heher, Y. K. Frozen-section checklist implementation improves quality and patient safety. Am. J. Clin. Pathol. 151, 607–612 (2019).
Nakhleh, R., Coffin, C. & Cooper, K. Recommendations for quality assurance and improvement in surgical and autopsy pathology. Hum. Pathol. 37, 985–988 (2006).
Bera, K., Schalper, K. A., Rimm, D. L., Velcheti, V. & Madabhushi, A. Artificial intelligence in digital pathology—new tools for diagnosis and precision oncology. Nat. Rev. Clin. Oncol. 16, 703–715 (2019).
Madabhushi, A. & Lee, G. Image analysis and machine learning in digital pathology: challenges and opportunities. Med. Image Anal. 33, 170–175 (2016).
Iqbal, T. & Ali, H. Generative adversarial network for medical images (MI-GAN). J. Med. Syst. 42, 231 (2018).
Bentaieb, A. & Hamarneh, G. Adversarial stain transfer for histopathology image analysis. IEEE Trans. Med. Imaging 37, 792–802 (2018).
Li, W. et al. High resolution histopathology image generation and segmentation through adversarial training. Med. Image Anal. 75, 102251 (2022).
Ahmad, W., Ali, H., Shah, Z. & Azmat, S. A new generative adversarial network for medical images super resolution. Sci. Rep. 12, 9533 (2022).
Ozyoruk, K. B. et al. A deep-learning model for transforming the style of tissue images from cryosectioned to formalin-fixed and paraffin-embedded. Nat. Biomed. Eng. 6, 1407–1419 (2022).
Siller, M. et al. On the acceptance of “fake” histopathology: a study on frozen sections optimized with deep learning. J. Pathol. Inf. 13, 6 (2022).
Oluchi Ikezogwo, W. et al. Quilt-1M: one million image-text pairs for histopathology. Adv. Neural Inf. Process. Syst. 36, 37995–38017 (2023).
Griffin, J. & Treanor, D. Digital pathology in clinical use: where are we now and what is holding us back?. Histopathology 70, 134–145 (2017).
Haghighat, M. et al. Automated quality assessment of large digitised histology cohorts by artificial intelligence. Sci. Rep. 12, 5002 (2022).
Nakhleh, R. E. Quality in surgical pathology communication and reporting. Arch. Pathol. Lab. Med. 135, 1394–1397 (2011).
Schömig-Markiefka, B. et al. Quality control stress test for deep learning-based diagnostic model in digital pathology. Mod. Pathol. 34, 2098–2108 (2021).
Chen, Y. et al. Assessment of a computerized quantitative quality control tool for whole slide images of kidney biopsies. J. Pathol. 253, 268–278 (2021).
Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. Nat. Med. 30, 850–862 (2024).
Wu, Y. et al. A pragmatic note on evaluating generative models with Fréchet inception distance for retinal image synthesis. Preprint at https://arxiv.org/abs/2502.17160 (2025).
Rivenson, Y. et al. Virtual histological staining of unlabelled tissue-autofluorescence images via deep learning. Nat. Biomed. Eng. 3, 466–477 (2019).
Lu, M. Y. et al. Data-efficient and weakly supervised computational pathology on whole-slide images. Nat. Biomed. Eng. 5, 555–570 (2021).
Pech-Pacheco, J.L., Cristóbal, G., Chamorro-Martinez, J. & Fernández-Valdivia, J. Diatom autofocusing in brightfield microscopy: a comparative study. In Proceedings 15th International Conference on Pattern Recognition. ICPR-2000, Vol. 3, 314–317 (IEEE, 2000).
Goodfellow, I. J. et al. Generative adversarial nets. In Neural Information Processing Systems 27 (eds Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N. D. & Weinberger, K. Q.) 2672–2680 (Curran Associates, Inc., 2014).
Park, T., Efros, et al. In Computer Vision – ECCV 2020. (eds Andrea Vedaldi, Horst Bischof, Thomas Brox, & Jan-Michael Frahm) 319-345 (Springer International Publishing).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 770–778 (IEEE, 2016).
Huang, X. & Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In 2017 IEEE International Conference on Computer Vision (ICCV) 1510–1519 (IEEE, 2017).
Ikezogwo, W. O. et al. Quilt-1M: one million image-text pairs for histopathology. Adv. Neural Inf. Process Syst. 36, 37995–38017 (2023).
Kingma, D. P. & Ba, J. J. Adam: a method for stochastic optimization. Preprint at https://arxiv.org/abs/1412.6980 (2014).
Kang, M., Song, H., Park, S., Yoo, D. & Pereira, S. Benchmarking self-supervised learning on diverse pathology datasets. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 3344–3354 (IEEE, 2023).
Lu, M. Y. et al. A visual-language foundation model for computational pathology. Nat. Med. 30, 863–874 (2024).
Xu, H. et al. A whole-slide foundation model for digital pathology from real-world data. Nature 630, 181–188 (2024).
Dosovitskiy, A. et al. An image is worth 16x16 words: transformers for image recognition at scale. Preprint at https://arxiv.org/abs/2010.11929 (2020).
Zhang, J. O. et al. In Computer Vision – ECCV 2020. (eds Andrea Vedaldi, Horst Bischof, Thomas Brox, & Jan-Michael Frahm) 698-714 (Springer International Publishing).
Sung, Y.-L., Cho, J. & Bansal, M. LST: ladder side-tuning for parameter and memory efficient transfer learning. Preprint at https://arxiv.org/abs/2206.06522 (2022).
Hu, J. E. et al. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the International Conference on Learning Representations (ICLR, 2021).
Han, Z., Gao, C., Liu, J., Zhang, J. & Zhang, S. Q. J. A. Parameter-efficient fine-tuning for large models: a comprehensive survey. Preprint at https://arxiv.org/abs/2403.14608 (2024).
Sung, Y.-L., Cho, J. & Bansal, M. J. A. LST: ladder side-tuning for parameter and memory efficient transfer learning. Adv. Neural Inf. Process. Syst. 35, 12991–13005 (2022).
Chen, X. et al. An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision 9620–9629 (IEEE, 2021).
Acknowledgements
This work was supported by grants from the National Natural Science Foundation of China (Nos. 82172646 and 82403737), Guangdong Basic and Applied Basic Research Foundation (Nos. 2024A1515012448 and 2024A1515012828), China Postdoctoral Science Foundation (No. 2024M753786), Science and Technology Program of Guangzhou (No. SL2024A04J00711), Chih Kuang Scholarship for Outstanding Young Physician-Scientists of Sun Yat-sen University Cancer Center (No. CKS-SYSUCC-2023005), and Young Talents Program of Sun Yat-sen University Cancer Center (No. YTP-SYSUCC-0025).
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zheng, X., Zheng, K., Wen, Y. et al. An end-to-end multifunctional AI platform for intraoperative diagnosis. npj Digit. Med. 8, 460 (2025). https://doi.org/10.1038/s41746-025-01808-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-025-01808-7