
深入增强学习基于学习的机制,以改善EH-WSN的吞吐量
作者:Davoodi, Kasra
介绍
能源收割机无线传感器网络(EH-WSN)由多个传感器组成,其特征在于它们的较小的嵌入式尺寸。这些网络能够从环境来源捕获能源作为补充能源1。这些智能节点积极监视周围环境并收集基本的环境数据。然后,该数据通过智能节点发送到远程基站(BS)。为了实现这一目标,传感器节点必须长时间运行,同时依靠有限的电池电量。尽管这些网络利用能量收集,但整日太阳辐射的变化会导致收获能量的波动,从而导致能量限制。结果,这些节点中的电池逐渐耗尽,最终导致网络隔离。这为EH-WSN造成了一个重要的问题,因为这些网络由许多节点组成,并且偶尔部署在具有挑战性的环境中,例如沙漠或战场上,在沙漠或战场上,维护无法维护并且任务成本高昂。
为了解决与电池能源挑战相关的局限性,在能源管理文献中提出了两类方法。这些方法包括基于聚类的方法2,,,,3,,,,4和基于RL的方法1,,,,5。
在基于聚类的方法中,传感器在簇中不均匀和随机分布6,,,,7,并且每个群集中的一个节点被概率地选择为群集头,以从常规节点收集数据并将其转发到基站。位于基站靠近基站的群集通常会由于其增加的继电器责任而处理更高的数据量8,,,,9。因此,在基站附近的群集的节点较少,而离基站较远的节点包含更多的节点。这将网络分散到单个集群中并改善网络性能。但是,由于能源收集资源的波动性质以及在EH-WSN环境中的多种条件,尽管部分管理能源消耗,但基于聚类的方法缺乏适应能量变化所需的灵活性1。
在基于RL的方法中,将能源收集和数据传输建模为决策过程,可以通过与环境相互作用进行优化。该学习是使用四个基本组成部分进行建模的:代理,州,行动和奖励。每个传感器节点都被认为是与环境相互作用的代理,旨在优化数据传输,同时最大程度地减少不同条件下的能源消耗。每个节点的能级代表其状态。基于此状态,代理商选择一个诉讼,并根据结果取决于结果,以奖励或罚款的形式收到反馈。通过持续的互动和反复学习,代理人逐渐识别哪些行动产生最高的长期奖励。该学习过程允许传感器节点制定有效的策略,以进行节能沟通10。这种建模和构建问题的方式使基于RL的方法比基于聚类的方法具有优势,因为它使它们能够自适应地定义与环境和能源收集资源相关的参数,从而显着提高了数据传输速率。
据我们所知,基于RL方法的文献中的大多数作品都将能量视为离散数量,这意味着将其分为固定的间隔或类别。该方法简化了连续的状态空间,使其对于Q-学习等传统RL算法更容易管理。例如,能量水平可以分别分为[0â0â3.3),[0.3 0.7)和[0.7 1],分别对应于低,中和高的范围。1,,,,5。这种离散化有助于降低复杂性,并使训练模型更容易。但是,它也引入了某些局限性。首先,节点之间的重要区别可能会丢失两个具有不同能量水平的节点。其次,能量状态的粗略表示可以导致较少的响应和次优的性能。结果,选定的动作可能无法准确反映实际的网络条件,可能导致能源消耗不平,较低的数据传输速率以及网络性能的总体下降11。
为了解决这些局限性,本文提出的方法采用了深入的增强学习方法(DRL)方法,该方法将RL与深度神经网络(DNN)相结合,将能量水平视为连续变量,而不是将它们分配为固定间隔。在这种方法中,RL负责通过与环境的相互作用来学习最佳的行动策略,而DNN通过评估众多状态并估算行动值来近似Q功能。尽管DNN通常由许多层组成,但我们仅使用两个隐藏层来降低计算复杂性并最大程度地减少传感器节点处的能耗。该设计使该模型能够将能级视为连续变量,并在各种能量和网络条件上概括。通过处理高维状态空间,DNN增强了动作值估计的准确性,并支持马尔可夫决策过程框架内的最佳决策。首先,通过将能量视为连续变量,该设计可以保留节点之间的重要区别,从而确保两个具有显着不同能量水平的节点未分为同一类别。其次,它在每个节点的能级中捕获了甚至微小的波动,从而使对动态变化的响应更加精确。结果,该方法可以对能量波动的更精确的响应,从而改善能源感知控制,较高的数据传输速率以及跨节点的更平衡的能量使用,最终增强了整体网络吞吐量。
本文的主要方面包括以下部分***:
1。引入一个结合RL方法和DNN的DRL网络,以连续定义网络中的状态。这导致网络的总吞吐量提高了11.79%。
2。鉴于神经网络通常由许多层和神经元组成,因此所提出的方法仅使用两层,简化了计算过程并减少传感器能量消耗。
本文的其余部分如下:第2节提供了先前研究的概述。第3节详细介绍了系统模型,并提出了所提出的方法。第4节中讨论了从提出的方法获得的结果的分析。第5节包含讨论,第6节总结了本文。
相关工作
解决EH-WSN中能源限制的现有方法主要分为基于聚类的基于聚类和基于RL的方法。
聚类将传感器节点分为组,每个节点由一个集群头管理,该群集从节点收集数据并将其传输到基站12。沿高效路径选择簇头会延长网络寿命和稳定性13,,,,14,,,,15,,,,16,,,,17。聚集在无线传输过程中保留最大的能量。但是,如果没有有效选择最佳簇头的方法,则可能会在数据收集中出现并发症,从而导致传感器节点的能源效率降低2。
Choi等。3提出了一种新的两相聚类(TPC)方案,以最大程度地减少WSN中网络和延迟自适应数据收集的能源消耗。El Alami和Najid4引入了一种称为增强聚类层次结构(ECH)的方法。ECH的主要目标是提高WSN内的能源效率。为此,提出了一种睡眠效果机制,专门针对相邻和重叠的节点量身定制。这也有效地最小化了数据冗余,导致网络寿命的最大化。使用Wang等人中详细介绍的数学表达式确定节点的最佳传输能力。18。此外,开发了一种算法来选择簇头,从而提高了WSN中数据收集效率。Sharmin等。2提出了一种将混合粒子群优化(HPSO)与增强的低能自适应聚类层次结构(HPSO-ILEACH)相结合的解决方案,以选择簇头。目的是提高能源效率并在数据聚合过程中提高WSN的网络稳定性。在其他一些作品中,使用路由方法。El Assari19建议采用不等聚类方法(EMUC)的节能多跳路。这种方法涉及创建不同尺寸的簇,这些簇由基站和传感器节点之间的距离确定。曼达拉等。20为有效的基于群集的数据收集提出了一个均匀的耗散协议(EEDP),其中传感器数据通过群集头的多个序列转发到基站。Mehrabi和Kim21开发了一个混合企业线性编程(MILP)模型,以增强EH-WSN中的网络性能。
除了聚类外,机器学习算法,尤其是增强学习,还可以用于提高网络性能。夏尔马和乔汉5采用Q学习方法来获得每个传感器节点来获取最佳动作。这增强了覆盖范围并确保主动节点之间的联系。Ge等人提出了一种整合Q学习和SARSA的协作方法。1达到能量中立,同时最大化网络数据吞吐量。江等。22与MCTA算法相比,拟议的PPSS在基于模拟的方案中显示了25英寸45%的能源效率,在基于实现的方案中的能力效率增加了约16.9%。Rioual等人。23研究了各种奖励功能,以开发一种确定最合适的奖励功能和相关参数的方法,以最大程度地提高电池的自主权。Prabhu等。24引入了针对WSN的RL驱动路由算法,并根据网络的当前状态设计路线。结果表明,这种方法可以通过选择适当的奖励功能来识别最佳路线,有效地最大程度地减少传输延迟并提高可靠性。
尽管提出的解决方案能够为网络实现更好的性能,但这些处理能量限制的方法表现出两个主要缺点。首先,它们可能通过将具有不同能量水平的人分配给同一预定义的类别来掩盖节点之间的关键差异。其次,这种离散的能量状态建模限制了系统对能量条件的准确响应的能力,从而可能导致效率低下的动作和网络性能退化。
背景
鉴于相关工作中确定的能量限制和局限性,本文提出了一种新颖的方法,将增强学习(RL)与深神经网络(DNN)集成在一起,以应对这些挑战。所提出的方法是专门设计的,目的是克服能源收获无线传感器网络中与能源管理相关的问题。以下各节提供了本文采用的系统模型的简要概述,并详细介绍了深Q-Network(DQN)。
系统模型
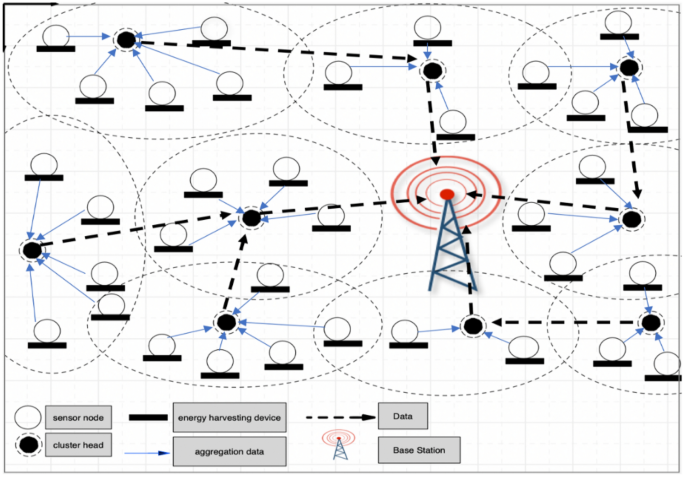
选择用于比较的基线方法包括基于聚类的和基于RL的方法,这些方法通常用于增强WSN中的吞吐量。尽管这些方法被广泛使用,但它们经常通过连续的能量监测面临挑战,这是拟议的DRL方法寻求解决的限制。提出的方法旨在填补这些空白,提供更有效的解决方案,以增强网络性能。下一节提供了对所提出的方法与现有基于RL的方法的详细比较。数字1演示包括必需组件的网络结构:基站,群集头和每个群集中的许多传感器节点。这些组件对于在整个网络中实现有效的通信和数据传输至关重要。基站,集群头和传感器节点之间的合作确保了稳健而可靠的网络性能。鉴于选择适当的聚类协议的重要性,本文采用了Ge等人提出的聚类方法。1。

聚集的EH-WSN网络。
最初,所有传感器都会随机部署在该区域中,其中群集头是根据等式选择的。((1):
$$ \ begin {Aligned} \ text {rand()} \ le \ frac {p} {1- p \ cdot \ cdot \ text {mod} \ left(r,\ text {round {round} \ left(\ frac {1} {1} {p} {p} {p} {p} {p}
(1)
这里,\(p \)表示被选为簇头(CH)的节点的概率,而\(r \)表示回合的数量。竞争区域\(r_c \)对于每个候选者,CH由等式表示。((2):
$$ \ begin {Aligned} r_c = r_0 \ cdot \ left(1- c \ cdot \ frac {d _ {\ text {max}}} - d(s_i,\ s_i,\ text {bs})}
(2)
网络最大竞争半径由\(R_0 \)和\(d(s_i \ times bs)\)是距节点的距离\(s_i \)到BS。变量\(d_ {max} \)表示节点可以与基站相距最远的距离,而c是一个系数在0到1之间。对于每个群集,最终簇头是根据当前能量水平和预期能量收获的最高组合选择下一个时间间隔的。根据\(r_c \)等式,可以确保位于基站靠近的群集面临较少的竞争。
为了最终确定每个群集的形成,所有传感器节点都确定其与可用群集头的距离,然后选择最接近的群集作为指定的群集头。此过程可确保网络内的有效通信,因为基于接近度的群集头选择优化了数据聚合和路由。
深Q网络(DQN)
深Q网络(DQN)是一种加强学习算法,将Q学习与深神经网络相结合,以在具有高度或连续状态空间的环境中有效决策。在传统的Q学习中,使用Q-table来估计每个州行动对的预期累积奖励(Q值)。但是,随着状态空间的增长,这种方法变得不切实际。
为了克服这一限制,DQN使用深层神经网络作为函数近似器来估计Q值,以\(q(s,a; \ theta)\)\), 在哪里s是国家,一个是行动,\(\ theta \)代表神经网络参数。对网络进行了训练,以最大程度地减少预测的Q值与从贝尔曼方程计算的目标值之间的损失。
$$ \ begin {aligned} l(\ theta)= \ mathbb {e} _ {(s,a,a,r,s')} \ left [\ left(r + \ gamma \ gamma \ max _ {a'} q(s'}\ end {Aligned} $$
(3)
这里,r是直接的奖励,\(\ gamma \)是折现因子,并且\(\ theta ^ - \)代表目标网络的参数,该参数会定期更新以稳定学习。DQN中的关键增强功能包括经验重播,该重播将过去的过渡存储在缓冲区中,并随机对它们进行样品以降低数据,而目标网络有助于稳定培训。
在本文中,DQN使传感器节点能够通过适应实时能量状态来学习最佳动作,从而改善EH-WSN中的能量感受控制。
提出的方法
能源效率是无线传感器网络(WSN)管理的关键挑战,特别是由于传感器节点的电池容量有限。加强学习(RL)方法(例如Q-学习)通常使用离散模型代表能级和其他系统状态,其中连续变量被分为固定的间隔或类别。尽管离散化简化了实施,但它引入了主要缺点。首先,它导致粒度的丧失,其中能量水平显着不同的节点可能会分为同一类。这可能会导致次优决策,因为学习代理无法区分节点能量的细微但重要的变化。其次,离散化可能导致粗糙和僵化的控制,无法有效适应EH-WSN环境的动态性质。
为了解决这些局限性,已经提出了更高级的方法,例如深钢筋学习(DRL)。DRL模型,尤其是基于深Q-NETWORKS(DQN)的模型,可以将能量视为连续变量,从而在决策中更精细的解决方案和对网络的更适应性实时管理。与基于表的方法不同,DRL利用神经网络近似连续状态空间的动作价值,从而使其能够在看不见或很少遇到的状态中更好地概括。这使网络能够对能源和其他环境条件的微小波动更加精确地响应,最终改善能量利用并增强整体吞吐量。
本文使用深Q-NETWORK(DQN),该Q-Network(DQN)将深度神经网络(DNN)与Q学习集成在一起,以管理无线传感器网络中的传输决策。DNN用于在连续和高维状态的空间(包括传感器节点的实时能级)上近似Q值函数。通过使每个节点能够在复杂条件下评估行动的长期奖励,DNN促进了更准确的政策学习。这导致有关数据传输的决策改善,直接导致网络吞吐量的增强。
本文中使用的DRL利用了一个完全连接的前馈神经网络,其中包括两层:一个带有10个神经元和RELU激活的隐藏层,然后是带有线性激活函数的输出层,与可能的动作数量相对应。选择两层体系结构在计算效率和功能近似能力之间提供了平衡的权衡。虽然更深的网络可以提供更好的表现力,但具有一个隐藏层的浅网络通常足以容纳低维状态空间,并且在训练过程中可以更快地收敛。该模型是使用RMSProp优化器进行培训的,学习率为0.01,批次大小为32,折扣系数训练\(\ gamma = 0.9 \)。根据其固有的性质,对每个传感器的能量进行了分析和研究。提出的方法的仿真结果清楚地表明,与离散能量的情况相比,吞吐量增加了显着的余量。
所提出的方法集中在网络环境中的传感器节点及其状态上。这些传感器节点或代理配备了最初的能级\(E_0 = 0.5 \)并位于距离基站不同距离的位置。Smart Agent旨在提高数据包率和网络吞吐量,并根据其状态精心调整其行为。该状态被认为是连续的,并在等式中表示。((4):
$$ \ begin {aligned} s_t = \ left [e _ {e _ {\ text {harkest}},e _ {\ text {dis}},e _ {\ text {cdis}}}} \ right]
(4)
在等式中。((4),三个与能源相关的关键参数在系统的性能中起关键作用。这里,\(E _ {\ Text {Harvest}} \)代表每个传感器时收获的能量的数量\(t_k \),,,,\(e _ {\ text {dis}} \)\)指示与初始能量相比剩余的能量\(E_0 \), 和\(e _ {\ text {cdis}} \)表示簇头的剩余能量与其初始能级之间的差异。基于这三个能量值,每个传感器节点根据当前状态选择最佳动作。这种战略决策过程可确保有效的资源利用并提高整体网络性能。设计算法的设计使每个代理都探索并利用环境。当代理人遇到状态时\(英石\),它评估两个不同的选项:它要么选择最合乎逻辑的动作,\(\ epsilon \)或以概率进行随机操作\(1- \ epsilon \)。在过程的每次迭代中,每个节点都会选择并执行操作,因此获得奖励。当来自传感器节点的数据包成功传输到群集头时,奖励将分配为正值\(+1 \)。相反,如果数据包未能到达集群头,则奖励将设置为负值\(-1 \)。奖励功能的第三个组成部分施加了强烈的惩罚\(-100 \)如果传感器节点的能量低于零。这劝阻该模型选择会导致节点不活跃的能量耗尽动作,从而促进更多能源感知的决策。每个传感器的随后状态是通过比较其剩余能量以及其簇头与初始能量的确定的(\(E_0 \))和收获的能量。然后将该状态用作操作选择过程的输入。
算法1:具有经验的深度Q学习网络
-
1。
初始化一个具有足够容量(n)的内存缓冲区(调用D)以存储信息。
-
2。
创建一个动作值函数(称为Q),并给它一些初始随机权重(\(\ theta \))。此功能将是主要网络。
-
3。
设置另一个动作值函数(表示为\(\ hat {q} \))具有与Q最初相同的权重(\(\ theta ^{ - } = \ theta \))。此功能将用作目标网络。
-
4。
每个情节的循环
-
5。
初始化状态(表示为s)
-
6。
时间通过t = 0
-
7。
对于每个步骤
-
8。
选择\(a_t = {\ left \ {\ begin {array} {ll} \ text {带有概率} \ varepsilon \ text {select} \ arg arg \ max \ max _a q(s_t,s_t,s_t,a,a,\ theta)
-
9。
t时间计算奖励r的计算
-
10。
商店过渡\((S_T,A_T,R,S_ {NEXT})\)在d
-
11。
样品样品样本随机微型过渡\((S_T,A_T,R,S_ {NEXT})\)从d
-
12。
设置\(y_j = {\ left \ {\ begin {array} {ll} r_j&\ text {for terminal} j + 1 \\ r_j + \ r_j + \ gamma \ left(\ max _ {a'}{否则} \ end {array} \ right。
-
13。
每个C步骤重置每个C\(\ hat {q} = q \)
算法1概述了DQN的不同阶段,从一对深神经网络的形成和初始化开始:主网络和目标网络。目标网络以反映主网络的参数初始化,并且这些参数在每个阶段的主网络定期更新。在下一步中,状态被初始化并认为是连续的,并且算法以循环进行。每个传感器节点遵循Epsilon-Greedy策略并取决于其当前状态,选择了最佳动作,概率\(\ epsilon \)或具有概率的随机动作\(1- \ epsilon \)。选择动作后,在每个步骤中,传感器节点都会从与执行动作相对应的环境中获得奖励。然后,当前状态,行动,奖励和下一个状态存储在缓冲区中。每次之后c时间步骤,将主网络的权重保存并复制到目标网络。最后,重复步骤7至13,直到达到最佳解决方案。
应该注意的是,超参数的选择,例如学习率和epsilon衰减率,通过初步实验仔细调节,以确保最佳性能。这些参数显着影响DRL算法的学习效率和收敛速度。例如,逐渐的epsilon衰减确保了平衡的探索和剥削,这对于适应WSN的动态能量景观至关重要。这种微调过程有助于实现稳定,高效的培训结果。
结果
在本节中,提出了仿真结果以评估所提出的基于DRL方法的性能。各种网络配置和节点密度被认为证明了该方法的有效性和可扩展性。研究的Q学习算法在Python中使用连续状态进行建模。环境是一个正方形空间,尺寸为\(200 \ times 200 \,\ text {m}^2 \),在其中心安装了一个基站(\(100 \,\ text {m},100 \,\ text {m} \))。在每个仿真中,传感器节点的分布都不均匀,导致簇的簇数量变化。每个传感器节点以\(0.5 \,\ text {j} \)能量和每个簇头的选择是随机的,概率为0.2。通过测量成功传输数据包的速率来评估网络性能,该数据包可作为吞吐量的主要度量标准。为了评估可伸缩性和鲁棒性,对不同大小的网络进行了模拟,特别是使用100、80、60、40和20传感器节点进行了模拟。假定没有静态能源消耗,该能源消耗在模拟中设置为0,并且电池本身消耗的能量被忽略。为简单起见,假定理想的电池,并且没有建模环境噪声。能源收集基于太阳能输入,使用实际辐照数据来反映现实的能量动力学。吞吐量通过成功传递到基站的数据包数量来衡量。表中使用的通信参数和能量模型值在表中详细介绍1。表1系统参数设置。根据结果,与基于RL的技术相比,提出的基于DRL的方法可显着改善吞吐量。
值得注意的是,DRL方法适应波动水平的能力会导致更有效,有效的数据流,尤其是在具有高传感器节点可变性的情况下。该分析强调了连续状态表示在增强EH-WSN性能方面的重要性。此外,基于DRL的方法通过利用深层神经网络可以直接处理连续的状态空间。它学会了通过神经网络近似Q值(或策略),从而使代理商能够做出决策而无需离散状态空间。这会导致更准确的决策,更快的收敛性以及吞吐量的重大改善。为了检查该算法与不同数量的节点的兼容性,已经考虑了五个具有不同数量的传感器的网络在环境中随机分布。数字2说明与基于RL的方法相比,基于DRL的方法中的网络吞吐量有所增加。该图显示了550集后传感器节点的性能。

WSN网络中吞吐量的比较。
数字3e说明了数据包传输速率的逐步改善,突出了连续能量分析的优势。数字3A显示了所有100个节点的700个迭代的训练过程中的100个传感器的网络吞吐量。基于DRL的方法增加了通过网络发送的数据包总数。因此,使用基于RL的方法中的100个节点中的数据包数量从基于DRL的方法中的330,000增加到370,000。这表明,将370,000个数据包发送到基站,最适合当前网络配置。这些测量值也可以在图2中看到。3b–e for nodes 80, 60, 40, and 20, respectively, which demonstrates a significant increase in each packet transmitted to the base station in the DRL-based method compared to the RL-based method.This value has approximately reached from 210,000 to 310,000 for 80 nodes, 200,000 to 242,000 for 60 nodes, 150,000 to 163,000 for 40 nodes, and from 83,000 to 87,000 for 20 nodes.

The quantity of packets that the base station has received for 100, 80, 60, 40, and 20 nodes.
As shown in Fig.4, the packet loss results for networks with 20, 40, 60, 80, and 100 nodes are presented, respectively.Although a relative increase in packet loss is observed in the DRL-based method, the number of successfully received packets also increases.This indicates that the DRL algorithm, by optimizing decision-making and transmission scheduling, improves overall data transmission efficiency.In other words, while network traffic and, consequently, packet loss rate increase, the overall network performance in data delivery improves, leading to higher throughput.

Packet loss for 100, 80, 60, 40, and 20 nodes.
Considering Fig.3, which illustrates the number of packets received at the base station, despite the higher packet loss rate in the DRL method compared to the RL method, the network throughput is increased.This suggests that the DRL algorithm utilizes network resources more effectively, transmitting a greater number of packets.Although some packets are lost due to increased traffic or network congestion, the total number of successfully delivered packets to the destination exceeds that of the RL method.Therefore, the increased packet loss rate does not necessarily imply reduced performance but rather reflects the DRL method’s maximized exploitation of the network capacity.
Furthermore, Fig.5a–i show the remaining energy (in Joules) of the sensor nodes in the 550th training iteration for networks of 100, 80, 60, 40, and 20 nodes, respectively.From rounds 170 to 240, the energy of the sensor is reduced because it is placed at night, during which the amount of energy that can be collected is also reduced.数字5b demonstrates the transmission rate (packets/round) of the sensor node in the 550th episode of rounds 1–240.Up to the 50th round, the sensors try to increase the transmission rate to the base station.However, with the decrease in energy, the transmission rate of the sensor node also decreases.As the energy levels of the sensor node progressively rise, the transmission rate also increases.The sensor node tries to set the count of packets transmitted in each round to 24. The quantity of sent packets per round is finally set to 27 for networks with 60, 40, and 20 sensors, respectively, as shown in Fig.5d,f,h,j.图5

讨论
The results of this paper demonstrate the potential of Deep Reinforcement Learning (DRL) in EH-WSNs.
While previous research has used reinforcement learning to improve EH-WSN throughput, this paper combines reinforcement learning and deep learning methods.This combined method allows the network to select and implement the best strategies for data transmission.By considering the real-time energy levels of each sensor node, the network can make more informed, dynamic decisions, leading to better resource utilization and improved network performance.Continuous monitoring of energy levels is crucial in this optimization process.It helps the network adjust its transmission strategies to maximize resource efficiency, ultimately enhancing overall performance.This paper highlights the importance of continuous energy tracking for improving packet transmission rates.Specifically, the DRL-based method outperforms traditional methods by transmitting more data from each sensor node based on its current energy level, resulting in higher network throughput.In this method, two neural networks are employed: the main and target networks.The target network’s parameters are periodically updated by copying from the main network.Using both networks reduces complexity and energy consumption.However, despite these promising results, it is recognized that the challenges and constraints faced by real-world EH-WSN deployments are not fully addressed by the implementation.
结论
The integration of reinforcement learning (RL) methods with deep neural networks has demonstrated remarkable performance in increasing network throughput.The findings of this paper show that while the DRL method leads to a relative increase in the packet loss rate—likely due to higher network traffic—it simultaneously achieves a greater number of successfully received packets, resulting in improved overall throughput.This indicates that the DRL method effectively maximizes network capacity exploitation by optimizing resource allocation.By continuously considering the amount of energy, this fine-grained adjustment, based on the exact amount of energy, results in a substantial increase in overall network throughput.The proposed DRL method incorporates two neural networks, referred to as the main and target networks.The target network is identical to the main network, with its parameters being periodically duplicated from the main network at each stage.Given that neural networks typically involve a large number of layers and neurons, they can lead to complex calculations and high energy consumption by sensor nodes.To address this, two layers are defined for the neural networks in this paper, which reduces both calculation complexity and energy consumption by sensors.The simulation results of the presented DRL method indicate that the DRL method significantly improves throughput, with an enhancement of 11.79%.It’s important to note that while the proposed DRL method shows significant improvements in throughput, certain challenges remain, such as the computational complexity associated with training deep networks and the sensitivity to hyperparameter settings.Future work could explore optimizing the network architecture further or integrating additional learning strategies, such as meta-learning or transfer learning, to improve adaptability and reduce training times.Additionally, real-world testing in diverse environmental conditions would provide further validation of the method’s robustness.
数据可用性
The dataset used during the current study is available from the corresponding author on reasonable request.
参考
Ge, Y., Nan, Y. & Guo, X. Maximizing network throughput by cooperative reinforcement learning in clustered solar-powered wireless sensor networks.int。J. Distributed Sensor Netw. 17(4), 15501477211007412 (2021).
Sharmin, S., Ahmedy, I. & Md Noor, R. An energy-efficient data aggregation clustering algorithm for wireless sensor networks using hybrid pso.Energies 16(5), 2487 (2023).
Choi, W., Shah, P. & Das, S. K. A framework for energy-saving data gathering using two-phase clustering in wireless sensor networks.在The First Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services, 2004. MOBIQUITOUS 2004., pp. 203–212.IEEE (2004).
El Alami, H. & Najid, A. Ech: An enhanced clustering hierarchy approach to maximize lifetime of wireless sensor networks.IEEE Access 7, 107142–107153 (2019).
Sharma, A. & Chauhan, S. A distributed reinforcement learning based sensor node scheduling algorithm for coverage and connectivity maintenance in wireless sensor network.Wireless Netw. 26(6), 4411–4429 (2020).
Mamalis, B., Gavalas, D., Konstantopoulos, C. & Pantziou, G. Clustering in wireless sensor networks.在RFID and Sensor Networks, pp. 343–374.(CRC Press, 2009).
Younis, O., Krunz, M. & Ramasubramanian, S. Node clustering in wireless sensor networks: Recent developments and deployment challenges.IEEE Netw. 20(3), 20–25 (2006).
Chen, G., Li, C., Ye, M. & Wu, J. An unequal cluster-based routing protocol in wireless sensor networks.Wireless Netw. 15, 193–207 (2009).
Peng, S. & Low, C. P. Energy neutral routing for energy harvesting wireless sensor networks.在2013 IEEE Wireless Communications and Networking Conference (WCNC), pp. 2063–2067.IEEE (2013).
Khan, M. I. & Rinner, B. Energy-aware task scheduling in wireless sensor networks based on cooperative reinforcement learning.在2014 IEEE International Conference on Communications Workshops (ICC), pp. 871–877.IEEE (2014).
Ge, Y., Nan, Y. & Chen, Y. Maximizing information transmission for energy harvesting sensor networks by an uneven clustering protocol and energy management.KSII Trans.Internet Inform.系统。(TIIS) 14(4), 1419–1436 (2020).
Karunanithy, K. & Velusamy, B. Cluster-tree based energy efficient data gathering protocol for industrial automation using wsns and iot.J. Ind. Inform.Integr. 19, 100156 (2020).
Latiff, N. A., Tsimenidis, C. C. & Sharif, B. S. Performance comparison of optimization algorithms for clustering in wireless sensor networks.在2007 IEEE International Conference on Mobile Adhoc and Sensor Systems, pp. 1–4.IEEE (2007).
Morsy, N. A., AbdelHay, E. H. & Kishk, S. S. Proposed energy efficient algorithm for clustering and routing in WSN.Wireless Personal Commun. 103, 2575–2598 (2018).
Khadem, M., Toloie Eshlaghy, A. & Fathi, K. Nature-inspired metaheuristic algorithms: Literature review and presenting a novel classification.J. Appl。res。Ind. Eng. 10(2), 286–339 (2023).
Voronova, L. I., Voronov, V. I. & Mohammad, N. Modeling the clustering of wireless sensor networks using the k-means method.在2021 International Conference on Quality Management, Transport and Information Security, Information Technologies (IT &QM &IS), pp. 740–745.IEEE (2021).
Yarinezhad, R. & Hashemi, S. N. Increasing the lifetime of sensor networks by a data dissemination model based on a new approximation algorithm.Ad Hoc Netw. 100, 102084 (2020).
Wang, T., Heinzelman, W. & Seyedi, A. Maximization of data gathering in clustered wireless sensor networks.在2010 IEEE Global Telecommunications Conference GLOBECOM 2010, pp. 1–5.IEEE (2010).
El Assari, Y. Energy-efficient multi-hop routing with unequal clustering approach for wireless sensor networks.int。J. Computer Netw.社区。(IJCNC)。12(2020)。Mandala, D., Du, X., Dai, F. & You, C. Load balance and energy efficient data gathering in wireless sensor networks.
无线通讯。Mobile Comput. 8(5), 645–659 (2008).
Mehrabi, A. & Kim, K. General framework for network throughput maximization in sink-based energy harvesting wireless sensor networks.IEEE Trans。Mobile Comput. 16(7), 1881–1896 (2016).
Jiang, B., Ravindran, B. & Cho, H. Probability-based prediction and sleep scheduling for energy-efficient target tracking in sensor networks.IEEE Trans。Mobile Comput. 12(4), 735–747 (2012).
Rioual, Y., Le Moullec, Y., Laurent, J., Khan, M. I. & Diguet, J.-P.Reward function evaluation in a reinforcement learning approach for energy management.在2018 16th Biennial Baltic Electronics Conference (BEC), pp. 1–4.IEEE (2018).
Prabhu, D., Alageswaran, R. & Miruna Joe Amali, S. Multiple agent based reinforcement learning for energy efficient routing in wsn.Wireless Netw. 29(4), 1787–1797 (2023).
道德声明
竞争利益
作者没有宣称没有竞争利益。
Declaration of using Generative AI for the writing process
The authors declare the usage of ChatGPT4 only to improve the readability and fluency of the paper.All the text is completely reviewed, and writers take full responsibility for all the content presented in this study.
附加信息
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
开放访问This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material.您没有根据本许可证的许可来共享本文或部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.To view a copy of this licence, visithttp://creativecommons.org/licenses/by-nc-nd/4.0/。重印和权限
引用本文

Hasani, Z., Mahdavimoghadam, M., Mohammadi, R.
等。Deep reinforcement learning-based mechanism to improve the throughput of EH-WSNs.Sci代表15 , 28321 (2025).https://doi.org/10.1038/s41598-025-14111-y
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41598-025-14111-y