使用四个NVIDIA RTX 6000 Pro Blackwell Max-Q GPU构建A16Z的个人AI工作站|安德烈·霍洛维茨(Andreessen Horowitz)
作者:Marco Mascorro

在基础模型,多模式AI,LLM和越来越多的数据集时代,对RAW Compute的访问仍然是研究人员,创始人,开发人员和工程师的最大瓶颈之一。虽然云提供可伸缩性,但个人AI工作站提供对环境,减少延迟,自定义配置和设置的完整控制,以及在本地运行所有工作负载的隐私。
这篇文章涵盖了我们的版本四-GPU工作站由新的NVIDIA提供支持RTX 6000 Pro Blackwell Max-Q GPU。此构建可以推动使用桌面AI计算的限制384GBvram(96GB每个gpu),全部都在桌子下面的外壳中。

为什么要建立这个工作站?
训练,微调和对现代AI模型的推断需要大量的VRAM带宽,高CPU吞吐量和超快速存储。在云中运行这些工作负载可以引入延迟,设置开销,较慢的数据传输速度和隐私权折衷。
通过建立工作站完整PCIE 5.0 x16连接的企业级GPU,我们得到:
- 最大GPU到CPU带宽:PCIE开关或共享车道没有瓶颈。
- 企业级VRAM:每个RTX 6000 Pro Blackwell Max-Q提供96GB的VRAM,实现密集的训练运行和大型模型推断而无需量化。每张卡在峰值(Max-Q版本)时仅消耗300W的功率。
- 8TB NVME 5.0存储:NVME PCIE的4x 2TB 5.0 x4模块。
- 256 GBECC DDR5 RAM总数
- 令人惊讶的效率:尽管有规模,但工作站仍在拉动1650W在峰值,足够低,可以在标准的15安培 / 120V家用电路上运行。
- 下一代数据GDS流:当我们仍在测试此支持的过程中,此设置应与NVIDIA GPUDIRECT存储(GDS),这允许数据集或模型直接从PCIE 5.0 NVME SSD传输到GPU VRAM,绕过CPU内存,以减少延迟和最大化吞吐量。
我们计划测试并制作有限数量的这些自定义A16Z创始人版AI工作站。

核心规格
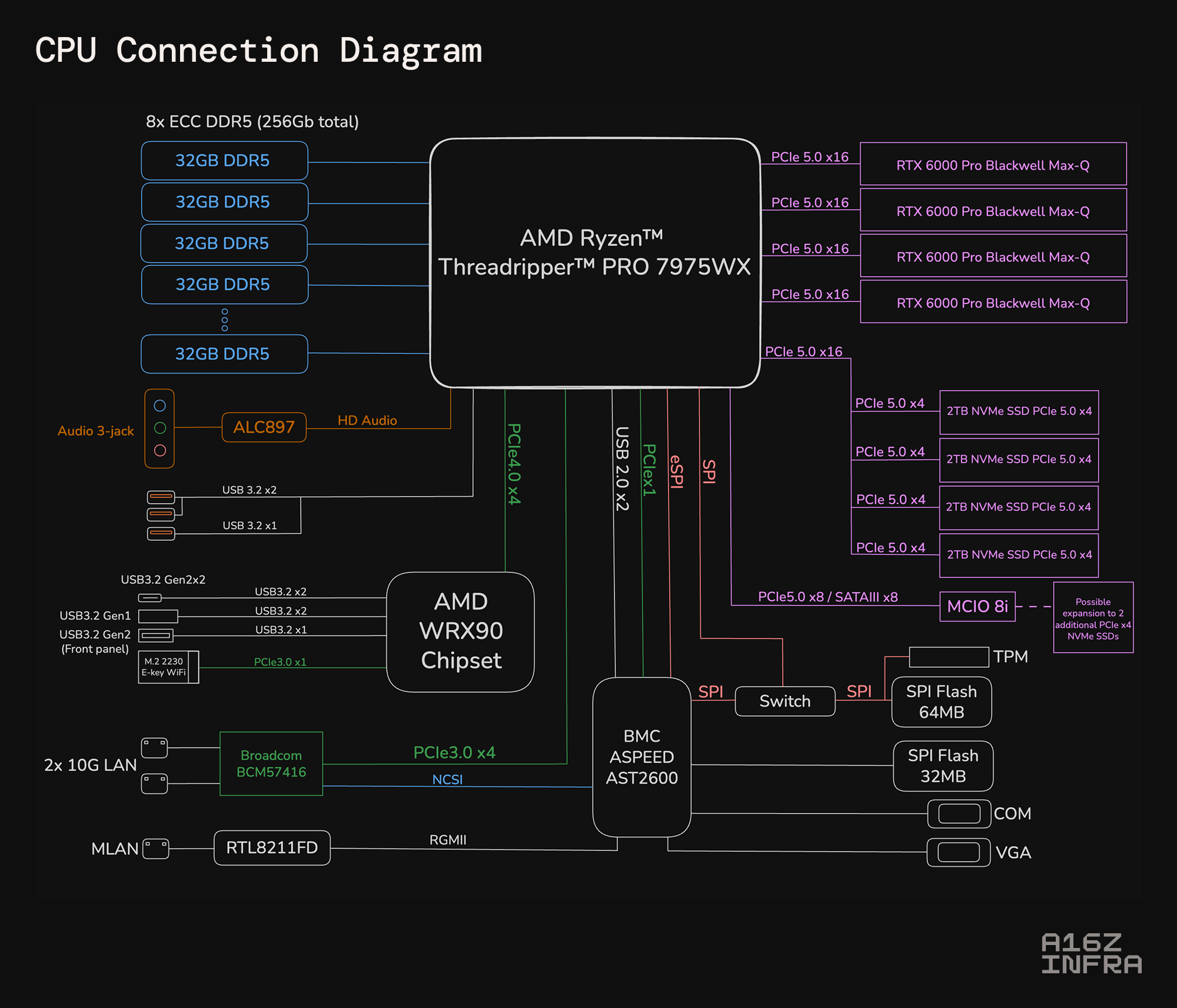
让我们分解硬件:
- GPU:
- 4 N nvidia RTX 6000 Pro Blackwell Max-Q
- 96GB VRAM Per GPU(384GB总VRAM)
- 专用PCIE 5.0 x16车道上的每张卡
- 每GPU 300W
- 中央处理器:
- AMD Ryzen Threadripper Pro 7975WX(用银石XE360-TR5冷却液体)
- 32核 / 64个线程
- 基础时钟:4.0 GHz,提高到5.3 GHz
- 8通道DDR5内存控制器
- 记忆:
- 256GBECC DDR5 RAM
- 跨8个通道(每个32GB)运行
- 可扩展到2TB
- 贮存:
- 8TB总计:4x 2TB PCIE 5.0 NVME SSDS X4车道(每个NVME模块的理论读取速度高达14,900 mb/s)
- 可在RAID 0中配置0〜59.6GB/S汇总理论读取吞吐量(我们正在测试实际吞吐量)。
- 电源供应:
- Thermaltake Toughpower GF3 1650W 80 Plus Gold
- 系统范围的最大抽奖:1650W,可在标准,专用15A 120V插座
- 母板:
- gigabyte MH53-G40(AMD WRX90芯片组)
- 案件:
- 在架子上扩展ATX外壳,并进行一些自定义修改。

设计亮点
完整PCIE 5.0带宽
每个GPU都是通过自己的专用PCIE 5.0 x16,确保CPU和GPU之间的最大数据传输速率。与依靠分叉车道,多路复用器或外部桥梁的多GPU设置不同,此构建保证在较低的PCIE版本中没有妥协的车道分配或违约。
高速数据集的存储
四个PCIE 5.0 NVME SSD提供读取速度的最高每个(理论)〜14.9 GB/s,扩展到〜59 GB/S突袭0中的理论0。当我们仍在全面测试过程中NVIDIA GPUDIRECT存储(GDS)兼容性,它可以允许GPU直接从NVME驱动器获取数据,从而启用直接内存访问(DMA)。
功率效率与实用性
整体系统消耗1650W峰并舒适地适合家庭或办公室环境,而无需专用电路或220V接线。借助内置轮子,它设计用于在位置之间轻松运输。
踢脚线管理控制器(BMC)
集成了AST2600,这是一种底板管理控制器(BMC),可作为远程带外服务器管理的专用处理器,独立于主机CPU和OS操作,以处理关键的监视和控制任务。
用例
- 培训和微调LLM最多数百亿个参数完全精确。
- 运行密集的多模式推理跨图像,文本,音频和视频模型。
- 实验模型并行性(张量,管道或基于专家的碎片)遍布四个GPU。
- 流高通量数据集直接从SSD突袭到GPU内存,以进行增强学习或基于扩散的工作负载。
借助VLLM,DeepSpeed,Sglang等图书馆,该机器是培训和服务自定义LLM,RL培训管道,多模式模型,自动型代理等的基础,没有云依赖性以及自定义设置和环境。
此RTX 6000 Pro Blackwell Workstation代表数据中心功率和桌面可访问性之间的最佳位置;一直呆在桌子下方的高端AI工作站的足迹和力量中。
无论您是一个研究人员探索新体系结构,创业的原型私人LLM部署,还是仅仅是发烧友,此构建都在您的办公桌下展示了一个高效的AI工作站。
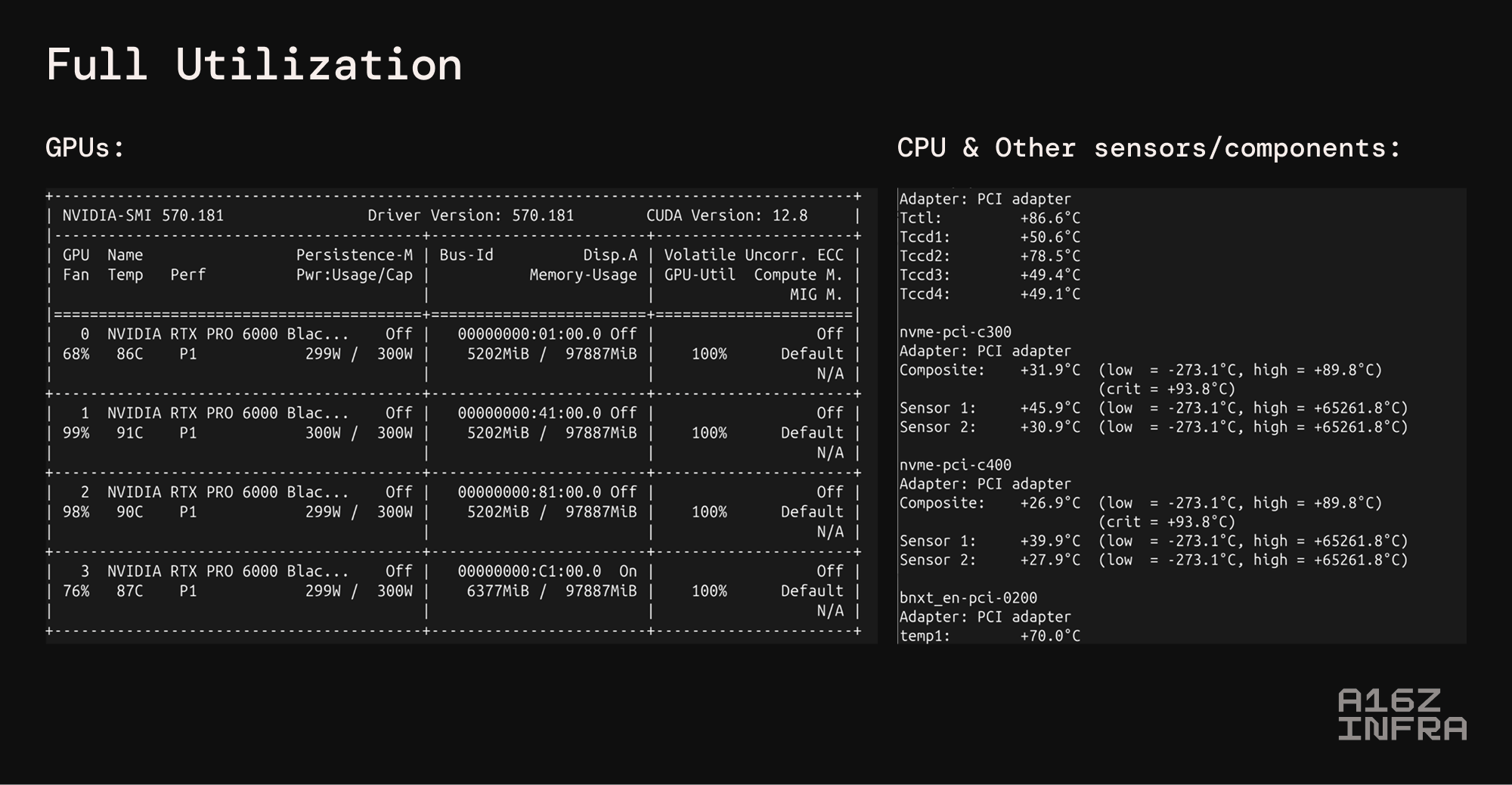
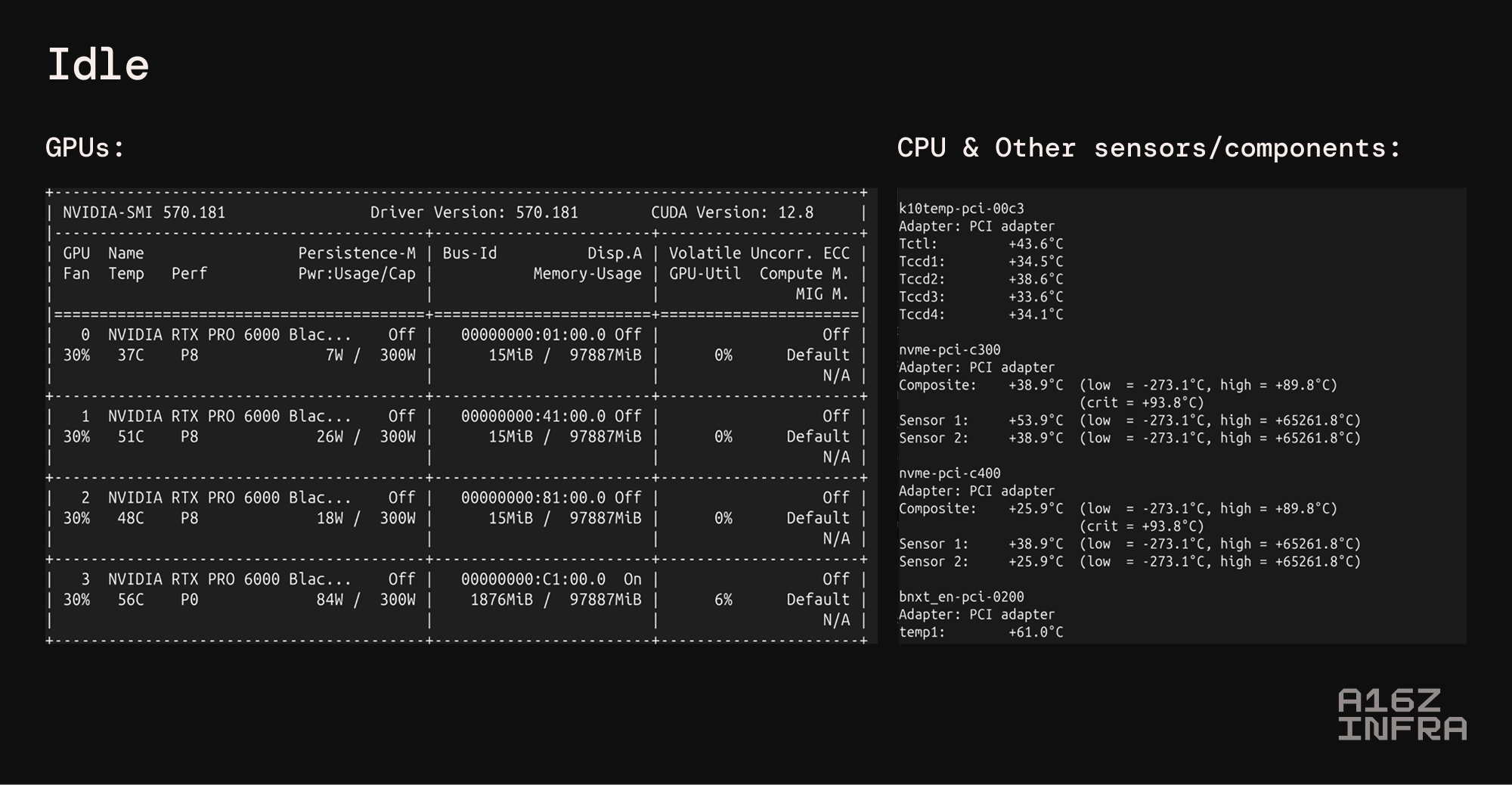
一些温度测试: