
Unveiling Arabic named entity recognition using natural language processing with artificial intelligence approach on Moroccan dialect
作者:Alotaibi, Shoayee Dlaim
Introduction
Arabic is one of the authorized languages in the world of Arabs and the strongest natural dialect in terms of morphological derivation and inflexion1. It is considered one of the top 10 common languages in the world by 420 million native talkers and 25 standard dialects. Arabic contains numerous exclusive features which make Arabic text both interesting and challenging. Special appreciation for the growing convenience of social media sites; there is a significant growth in the availability of Arabic texts on the Internet2. Arabic NER (ANER) draws attention to the efficient procedure of these texts. NER is the challenge of classifying indications related to exact kinds, like person name, position, and organization3. Also, general areas in numerous exact fields, namely the field of medicinal and drug processes, are removed by NER. With the help of Arabic NER, removing significant data in dissimilar areas is very useful. Additionally, it supports a range of downstream tasks comprising entity linking, machine translation, coreference resolution, relation extraction, and event extraction4. NER is a task of NLP that categorizes named entities in an assumed text predefined semantic classes like the person’s name, organization name, and position name. In the 1990s, NER was presented as a data extractor challenge in the message understanding conferences (MUC)5. It generally plays a vital part in numerous tasks of NLP, like data retrieval, machine translation, question answering, and text summarization. So, exploring a precise NER method can function as a source of data for diverse NLP uses. As a simple module of NLP, NER is familiar with English but still wants to complete a survey in Arabic. English NER is easier than Arabic NER because most English comments begin with capital letters, unlike Arabic, where this is not standard practice6.
Furthermore, Arabic is a morphologically compound dialectal owing to its very morphological and numerous variants. There is a reasonable quantity of work on NER study in Chinese, English, and other extensively spread dialects7. Previous NER methods were commonly dependent upon three techniques such as machine learning (ML)-based, hybrid-based, and rule-based NER. The Rule-based NER is based on a pair of manual rubrics removed by specialists in morphology. ML-based NER depends on statistical and feature-engineering methods8. Then, the hybrid-based NER unites either ML- or rule-based techniques. At present, through the innovation of multi-layered neural networks (NN), DL-based methods have attained remarkably higher performance in numerous NLP challenges, such as NER. DL is measured as a sub-area of ML that utilizes NN of manifold layers9. A multistage model determines and absorbs the depiction and structure of unstructured and unlabeled data like documents and imageries10. A large number of informal and dialectal Arabic texts are now easily accessible on online platforms due to the rise in -generated content on social media platforms. This growth highlights the requirement for advanced models to detect and classify named entities within these texts precisely. Effectual entity recognition in Arabic dialects like Moroccan can significantly improve data retrieval, sentiment analysis, and machine translation applications. It is crucial for unlocking the full potential of Arabic language processing in real-world scenarios.
This study introduces a novel Northern Goshawk Optimization with Artificial Intelligence for Arabic Named Entity Recognition (NGOAI-ANER) technique in Moroccan Dialect. The NGOAI-ANER technique enhanced the precision and efficiency of NER systems for Arabic text. The NGOAI-ANER technique begins by applying word embedding methods to convert text into dense vector representations, effectively capturing the semantic information essential for NER tasks. Furthermore, the stacked attention long short-term memory (SALSTM) technique is trained on the embedded data, leveraging the strength of DL architectures to identify named entities within Arabic text accurately. The NGOAI-ANER technique utilizes the northern goshawk optimization (NGO) model to fine-tune hyperparameters effectively to optimize the solution of the DL technique. An experimental assessment of the DarNERcorp dataset demonstrates the efficacy and scalability of the NGOAI-ANER model. The key contribution of the NGOAI-ANER model is listed below.
-
The NGOAI-ANER technique employs word embedding to transform textual data into dense vector representations that capture rich semantic relationships. This improves the quality of input features, enabling a better understanding of context and meaning. As a result, it improves the overall accuracy and efficiency of the subsequent sequence modelling.
-
The NGOAI-ANER method integrates the SALSTM network to capture complex dependencies and improve context understanding in text sequences. This enhances the capability to concentrate on relevant data across long-range interactions, thereby improving the accuracy and robustness of NER tasks.
-
The NGOAI-ANER approach implements the NGO technique to tune hyperparameters efficiently, optimizing the training process. This results in faster convergence and improved model accuracy. It ensures a more effective and automated parameter selection for enhanced overall performance.
-
The NGOAI-ANER model presents a novel hybrid framework by uniquely integrating the SALSTM network with NGO for hyperparameter tuning. This incorporated model simultaneously improves understanding of attention-based context and optimizes model parameters. The approach improves accuracy and convergence speed in NER tasks. Its combination of advanced sequence modelling and bio-inspired optimization distinguishes it from existing methods.
Related works
Anam et al.11 introduced a DL model for Urdu NER, which connects Floret and FastText word embeddings by considering the nearby context of words for an enhanced feature extractor. The pre-trained Floret and FastText word embeddings are openly accessible for the Urdu language and are employed for producing the feature vector of 4 benchmark Urdu language datasets. Such features must be implemented as input for training diverse integrations of gated recurrent unit (GRU) LSTM, Bi-LSTM, CRF, and DL methods. Ait Benali et al.12 introduced a multi-headed self-attention mechanism (SAM) employed in the BiLSTM-CRF NN architecture for identifying Arabic-called individuals in social media platforms employing two embeddings. The introduced model unites character and word embedding at the layer of embedding. In13, a technique that links a variety of Word embedding methods, manifold clustering, identification models, and Irace for automated model formation was presented. This technique includes the formation of dissimilar Word embedding techniques, the execution of dissimilar identification and clustering models, and altering these executions by dissimilar parameter mixtures to make an Arabic NER Method by the maximum rate of precision. In14, a significant variation of RNN, such as Bi-LSTM, is particularly employed for series identification issues for the task of NER. Word context features play a vital part in precisely forecasting termed entities. The current work donates to emerging new word embedding, i.e. increased word embedding, which can absorb contextual features well. Alsultani and Aliwy15 project an effective NER method that influences the encoding block of the Transformer, whereas either character- or word-level embedding was implemented. The united character- and word-level embedding served an encoding with Bi-LSTM. The encoding output is assumed to be a layer of Multi-head SAM. This executes the encoding block of the transformer containing a SAM tracked by a feed-forward system. Hatab et al.16 employ Madamira, an exterior knowledge basis, to make extra word features. The technique assesses the value of inserting these features into conventional characters and word embeddings to execute the task of NER on MSA. The NER technique was applied utilizing BiLSTM-CRF. The morphological and syntactical features are also inserted into dissimilar word embeddings to train the method. Goyal et al.17 project a DL-based NER method utilizing hybrid embedding with a mixture of fast text and BiLSTM-based character embedding. These embeddings take the text’s context, semantic, and syntactic assets that increase the intellectual influence of DL techniques. Diverse tests are executed with significant variations of RNN such as LSTM and Bi-LSTM, GRU and Bi-GRU.
Hamad and Abushaala18 developed a NER technique. After pre-processing, the research signified every word with multiple features like Part of Speech (PoS), FastText embedding, non-medical word matching, and TF-IDF. To classify the word, the surrounding words are considered to arrest its context. Therefore, the research has categorized every word into its entity through the SVM technique. Tibi and Messaoud19 developed a DL-based system using multi-scale product analysis and a Hamilton neural network (HNN) technique to detect Arabic dialects from speech signals accurately. Bourahouat, Abourezq, and Daoudi20 presented a model to improve sentiment analysis for Moroccan Arabic using pre-trained Arabic BERT models integrated with DL and ML techniques, addressing data imbalance challenges. Mansour et al.21 proposed a method to analyze Arabic dialect sentiment on social media using several ML, DL, and transformer-based models to detect the most effective approach. Jbel et al.22 created a comprehensive Moroccan dialect sentiment dataset and computed various ML and DL approaches for effectual sentiment analysis across Arabic and Latin scripts. Bahbib et al.23 developed and evaluated an automated system for accurately categorizing Arabic medical questions utilizing integrated feature extraction and DL techniques. Ouza et al.24 developed an accurate Arabic sentiment analysis system using AraBERT incorporated with neural network models to capture the language’s morphological and syntactic variances effectively. Dandash and Asadpour25 presented a technique to analyze the relationship between Arabic Twitter language use, personality traits, and sentiment using ML techniques to enhance understanding of user behaviour. Skiredj et al.26 developed and evaluated DarijaBanking and the BERTouch model to strengthen and improve intent classification in Moroccan Darija for the banking domain. Magdy et al.27 developed and evaluated Jawaher, a benchmark for assessing large language models’ ability to comprehend and interpret Arabic proverbs across dialects. Mohammad, Alkhnbashi, and Hammoudeh28 proposed a model to improve the performance of large language models like ChatGPT for accurate Arabic healthcare query understanding and response generation.
Despite significant advancements, various limitations and research gaps remain in Arabic NLP tasks. Many existing studies depend on pre-trained embeddings without fully capturing complex contextual and dialectal variations, particularly in under-resourced dialects like Moroccan Darija. Integrating diverse embeddings and architectures often lacks comprehensive evaluation across varied datasets, limiting generalizability. Furthermore, the handling of imbalanced datasets and the fusion of multimodal features remain insufficiently explored. While transformer-based models exhibit efficiency, their cultural and linguistic adaptability, specifically in dialect-rich environments, requires additional refinement. Addressing these research gaps is crucial for developing more robust, scalable, and dialect-aware Arabic NLP systems.
Methodology
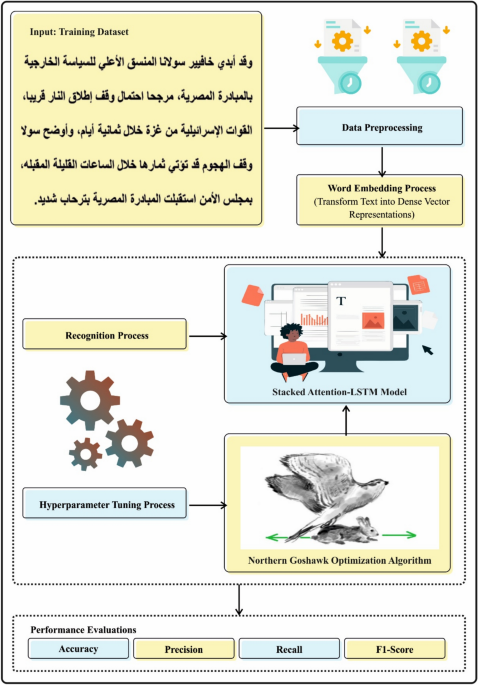
This research introduces a novel NGOAI-ANER methodology for the Moroccan dialect. The methodology aims to enhance the precision and efficiency of NER systems for Arabic text. Various procedures, namely word embedding, SALSTM-based classification, and NGO-based hyperparameter tuning, are used to accomplish that. Figure 1 specifies the workflow of the NGOAI-ANER method.

Workflow of NGOAI-ANER technique.
Word Embedding
Initially, the NGOAI-ANER approach begins with the word embedding techniques that transform the text into dense vector representations, capturing semantic information crucial for NER tasks29. Word embedding presents a method of signifying individual words utilizing higher dimension real number vectors, which take the semantic and syntactic relations among words. Word2Vec (W2V) is an instance of a method employed to make word embeddings. This model is used to make AraVec because it is a pre-trained word embedding method for Arabic. Word embedding cannot take every orthographic and morphological data of words because it is crucial for morphological-rich dialects such as Arabic. Therefore, the requirement for additional word representation is dependent upon its characters.
FastText is a word embedding method that complements W2V. It delivers optimum outcomes for rare or hidden words because it pauses a term to character \(n\)‐grams and signifies a term by the amount of the vector representation of its portions.
DL Architecture
At this stage, the SALSTM model is trained on the embedded data, utilizing the power of DL architectures to classify named entities within Arabic text30 accurately. To enhance the learning capability of LSTM, several LSTMs are loaded into layers. The authors discovered the benefits of deep-stacked LSTM. Wang et al. discovered a different manner to integrate multi-single LSTM layers combined and deliberated the benefits and drawbacks of deep LSTM. During this case, 2-LSTMs are set as part of the model’s framework. By loading the LSTM layer, the resultant hidden layer (HL) was spread to the adjacency LSTM cells and, apart from the input, to the subsequent LSTM layer. Additional HLs allow the method to define the spread among network output and input by noticing the mapping connection with multiple dimension spaces and enhancing the model’s capability to manage non-linearity. Every LSTM layer outcome in a vector sequence is employed as input for the next LSTM layer. The \({n}^{th}\) layer is upgraded by Eqs. (1-5).
$${f}_{(t)}^{n}=\sigma \left({W}_{f}^{n}{h}_{\left(t\right)}^{n-1}+{V}_{f}^{n}{h}_{\left(t-1\right)}^{n}+{b}_{f}^{n}\right)$$
(1)
$${i}_{(t)}^{n}=\sigma \left({W}_{i}^{n}{h}_{\left(t\right)}^{n-1}+{V}_{i}^{n}{h}_{\left(t\right)}^{n}+{b}_{i}^{n}\right)$$
(2)
$${o}_{(t)}^{n}=\sigma \left({W}_{o}^{n}{h}_{\left(t\right)}^{n-1}+{V}_{o}^{n}{h}_{\left(t-1\right)}^{n}+{b}_{o}^{n}\right)$$
(3)
$${c}_{(t)}^{n}={f}_{(t)}^{n}\otimes {c}_{\left(t-1\right)}^{n}+{i}_{\left(t\right)}^{n}\otimes \text{tanh}\left({W}_{c}^{n}{h}_{\left(t\right)}^{n-1}+{V}_{c}^{n}{h}_{\left(t-1\right)}^{n}+{b}_{c}^{n}\right)$$
(4)
$${h}_{(t)}^{n}={0}_{(t)}^{n}\otimes tanh\left({c}_{\left(t\right)}^{n}\right)$$
(5)
The first layer input is the mapping features removed by CNN, but the output is assumed to be the hierarchical feature. Stacking multi-LSTM layers allows the method to rebuild the representation acquired from the preceding layer, and a novel representation with a higher level of abstraction was obtained. The parameters are divided in the entire space of the model, which accelerates the trained convergence and executes the optimum non-linear function of the data. However, a solitary LSTM resolves specific issues presented in RNN; managing long and complicated series is still very complex. Employing 2-layer LSTMs as part of the system framework makes the HL more compactly connected, improving the predictive accuracy. Figure 2 portrays the structure of SALSTM.

Architecture of SALSTM.
The AM in NN is a resource allocation method to allocate resources to the most crucial challenges and resolve excess data problems with restricted calculation resources. In NNs, with extra parameters, a model takes better feature expression capability it will get, and additional data saved by the model. However, this can generate a data overload problem. By establishing the AM, the system could concentrate on the critical data to the existing tasks amongst several input data, decreasing the attention to other ineffective data. The AM resolves the data overload issue and enhances the model’s effectiveness and precision.
However, the optimum method of AM is attained by integrating the basics with attention distribution co-efficient. The AM maintains the in-between solutions of the trained method, acquires these in-between solutions, and connects the resultant series with them by allocating weights. Moreover, related to the typical RNN, the AM can be calculated in parallel, but the computational of all the steps is no longer dependent upon the computation solutions of the preceding stage. So, the AM has some parameters and more effective computation.
The computation is separated into two stages: (i) compute attention distribution between every input data; (ii) calculate the weighted average of input data dependent upon attention distributions.
The Eqs. (6–9) illustrate the computational rules of the AM. The input \(x\) and the preceding HL variable \({h}_{t-1}\text{ attained HL variable ht}.\) \({c}_{i}\) implies the weighted average of the subsequent HL unit and each HL of the RNN layer. \(\alpha\) defines the equal-weighted ratio among 2 HL units. \(\overline{{h}_{s}}\) represents the value of the target. \(s\) signifies the weighted computation process.
$${h}_{t}=RNN\left({x}_{t}, {h}_{t-1}\right)$$
(6)
$${c}_{i}={\sum }_{j=1}^{n}{\alpha }_{ij}{h}_{j}$$
(7)
$${\alpha }_{ij}=\frac{\text{exp}\left(s\left({h}_{t},\overline{{h}_{s}}\right)\right)}{{\sum }_{k=1}^{n}\text{exp}\left(s\left({h}_{t}, \overline{{h}_{s}}\right)\right)}$$
(8)
$$s\left({h}_{t}, \overline{{h}_{s}}\right)={h}_{t}\overline{{h}_{s}}$$
(9)
Hyperparameter selection
Finally, the NGOAI-ANER technique utilizes the NGO approach to fine-tune hyperparameters effectively to optimize the DL model performance31. This approach is chosen for its efficiency in optimization by replicating the natural hunting strategies of the Northern Goshawk, enabling compelling exploration and exploitation of the search space. This method provides faster convergence and avoids getting trapped in local optima, enhancing model performance. Its adaptability and capability in balancing exploration–exploitation make it particularly appropriate for intrinsic DL models with several parameters. Additionally, NGO requires less computational resources and tuning effort, making it an ideal choice over other metaheuristic algorithms. This efficiency and robustness justify its selection for improving model accuracy and convergence speed. Figure 3 specifies the working flow of the NGO methodology.

Workflow of the NGO method.
The developed NGO is a population-based method where the north goshawks are explorer members in this system. In an NGO, every member of a population requires a presented solution to the issue, which defines the values of variables. From an opinion of mathematics, every member of the population is a vector, and they are organized from the population as a matrix. Initially, population members were arbitrarily set in the space of searching. The matrix of population was defined utilizing Eq. (10).
$$X={\left[\begin{array}{c}{X}_{1}\\ \vdots \\ {X}_{i}\\ \vdots \\ {X}_{N}\end{array}\right]}_{N\times m}={\left[\begin{array}{ccccc}{x}_{\text{1,1}}& \cdots & {x}_{1,j}& \cdots & {x}_{1,m}\\ \vdots & \ddots & \vdots & \ddots & \vdots \\ {x}_{i,1}& \cdots & {x}_{i,j}& \cdots & {x}_{i,m}\\ \vdots & \ddots & \vdots & \ddots & \vdots \\ {x}_{N,1}& \cdots & {x}_{N,j}& \cdots & {x}_{N,m}\end{array}\right]}_{N\times m},$$
(10)
Here, \({X}_{i}\) represents the \(ith\) presented solution, \(X\) denotes the northern Goshawks population, \(N\) specifies the number of population members, \(m\) refers to the problem variables amount and \({x}_{i,j}\) refers to the value of \(the jth\) variable definite by the \(ith\) developed result.
As indicated above, every member of a population is a projected performance to the issue. So, the objective function (OF) is assessed and depends on every population member. These values acquired for the OF are signified as a vector utilizing Eq. (11).
$$F\left(X\right)={\left[\begin{array}{c}{F}_{1}=F\left({X}_{1}\right)\\ \vdots \\ {F}_{i}=F\left({X}_{i}\right)\\ \vdots \\ {F}_{N}=F\left({X}_{N}\right)\end{array}\right]}_{N\times 1}$$
(11)
whereas, \({F}_{i}\) signifies the OF value attained by \(ith\) projected solution and \(F\) represents the vector of acquired OF value.
The principle for determining which solution is finest is the OF value. In minimized issues, the OF value is lesser; in maximized issues, the OF value is greater, enhancing the projected solution. Let every iteration novel value be acquired for the objective function, and the finest developed solution must be upgraded in every iteration.
In creating the developed NGO model to upgrade the population members, the imitation of the northern goshawk tactic throughout searching was used. The dual foremost northern goshawk behaviours are given below.
-
Identification of prey and attack
-
Chase and escape process
Stage 1: identification of prey (exploration)
In the hunting method, the northern goshawk arbitrarily picks a target and rapidly assaults it. This stage will upsurge the NGO search authority owing to the collection of arbitrary prey from the search space. It chiefs to a global space search to classify the optimum region. The models conveyed are exactly demonstrated utilizing Eqs. (12) to (14).
$${P}_{i}={X}_{k}, i=\text{1,2},\dots ,N, k=\text{1,2},\dots ,i-1, i+1,\dots , N,$$
(12)
$${x}_{i,j}^{new,P1}=\left\{\begin{array}{ll}{x}_{i,j}+r({p}_{i,j}-I{x}_{i,j}),& {F}_{{P}_{i}}<{F}_{i},\\ {x}_{i,j}+r({x}_{i,j}-{p}_{i,j}),& {F}_{{P}_{i}}\ge {F}_{i},\end{array}\right.$$
(13)
$${X}_{i}=\left\{\begin{array}{ll}{X}_{i}^{new,P1},& {F}_{i}^{new,P1}<{F}_{i},\\ {X}_{i},& {F}_{i}^{new,P1}\ge {F}_{i},\end{array}\right.$$
(14)
Here, \({P}_{i}\) denotes the location of prey for the \(ith\) northern goshawk, \({F}_{{P}_{i}}\) refers to the value of an OF, \(k\) represents a randomly generated natural number in the range \([1 {\text{ and}} N],\) \({X}_{i}^{new, P1}\) represents the novel location for the \(ith\) developed solution, \({x}_{ij}^{new, P1}\) signifies its \(jth\) dimension, \({F}_{i}^{new, P1}\) denotes the value of OF dependent upon the initial stage of NGO, \(r\) refers to the arbitrarily formed number in the interval of \(zero and one\), and \(I\) specifies randomly generated number within 1 or 2. \(r\), and \(I\) refers to the randomly produced values employed to make arbitrary NGO performance in the hunt and upgrade.
Stage 2: chase and escape process (exploitation)
Once the northern goshawk assaults the target, the prey attempts to escape. So, in a chase and escape procedure, the northern goshawk endures to hunt prey. Owing to the higher velocity, they can hunt their target in any condition and finally chase. The imitation of this conduct upsurges the exploitation influence of the model in searching for locals. In the projected NGO model, it is highly expected that this search was secure to an attack location with a radius \(R\). The models stated are exactly demonstrated utilizing Eqs. (15–17).
$${x}_{i,j}^{new,P2}={x}_{i,j}+R\left(2r-1\right){x}_{i,j},$$
(15)
$$R=0.02\left(1-\frac{t}{T}\right),$$
(16)
$${X}_{i}=\left\{\begin{array}{ll}{X}_{i}^{new,P2},& {F}_{i}^{new,P2}<{F}_{i},\\ {X}_{i},& {F}_{i}^{new,P2}\ge {F}_{i}.\end{array}\right.$$
(17)
wherein \(T\) denotes the highest iteration count, \(t\) states the iterations count, \({X}_{i}^{new, P2}\) represents the novel position for \(ith\) developed solution, \({x}_{i,j}^{new, P2}\) specifies the \(jth\) dimension, \({F}_{i}^{nex, P2}\) indicates the value of an OF.
Once every population follower is upgraded, dependent upon the 1st and 2nd stages of the NGO model, an iteration is finished, and the novel population member’s values, a function of objective, and the finest solution are defined. Then, the model arrives at the subsequent iteration, and the population member’s upgrade depends on Eqs. (12) to (17) till the preceding iteration of the model was achieved. Afterwards, the execution of NGO, the finest projected solution acquired throughout the iteration, is presented as a quasi‐optimum solution for the assumed optimizer issue. Algorithm 1 demonstrates the NGO method.

NGO model
The NGO method originates from a fitness function (FF) to boost classification performance. It designates a positive number to indicate the higher execution of the candidate outcomes. During this work, the minimizer of the classification error rate is determined as FF is given in Eq. (18).
$$\begin{aligned} fitness\left( {x_{i} } \right) = & Classifier\,Error\,Rate\left( {x_{i} } \right) \\ = & \frac{No. \,of\, misclassified\, intances}{{Total \,no. \,of\, instances}} \times 100 \\ \end{aligned}$$
(18)
Experimental validation
Gold standard corpus
In this part, the experimental validation of the NGOAI-ANER approach is examined under the DarNERcorp dataset 32. The dataset contains 9130 records under four classes, as exposed in Table 1.
DL NER results on 80:20 of training/testing dataset
Figure 4 defines the classification results of the NGOAI-ANER technique on 80%:20% of TRAS/TESS. Figures 4 a, b illustrates the confusion matrices produced by the NGOAI-ANER technique. The results demonstrate that the NGOAI-ANER method accurately detects and precisely distinguishes all four classes. Afterwards, Fig. 4c establishes the PR curve of the NGOAI-ANER methodology. The figure shows that the NGOAI-ANER method enlarged the highest PR performance in every class. However, Fig. 4d determines the ROC of the NGOAI-ANER method. The figure displays that the NGOAI-ANER method has produced accomplished solutions with the most significant value of ROC at different class labels.

80%:20% of TRAS/TESS (a–b) confusion matrices and (c–d) PR and ROC curves.
The NER results of the NGOAI-ANER method are portrayed under 80%:20% of TRAS/TESS, which is assumed in Table 2 and Fig. 5. The experimentation results portrayed that the NGOAI-ANER method properly identified several types of classes. With 80%TRAS, the NGOAI-ANER method attained an average \(acc{u}_{y}\) of 96.91%, \(pre{c}_{n}\) of 93.25%, \(rec{a}_{l}\) of 92.76%, and \({F1}_{score}\) of 93.00%. In addition, with 20%TESS, the NGOAI-ANER model gets average \(acc{u}_{y}\) of 97.59%, \(pre{c}_{n}\) of 94.57%, \(rec{a}_{l}\) of 94.54%, and \({F1}_{score}\) of 94.56%

Average of NGOAI-ANER method at 80%:20% of TRAS/TESS.
The performance of the NGOAI-ANER technique is provided in Fig. 6 in the training \(acc{u}_{y}\)(TRAAC) and validation \(acc{u}_{y}\)(VALAC) outcomes of 80%:20% of TRAS/TESS. The results illustrate useful clarification into the behaviour of the NGOAI-ANER technique across numerous epochs, representing its learning method and generalization data. The outcome substantially improved from the TRAAC and VALAC, with epoch growth. It safeguards the NGOAI-ANER technique in the pattern identification process on both data. The increasing trend in VALAC reviews the skill of the NGOAI-ANER model in explaining the TRA data and shining in presenting an accurate classifier of unseen data.

\(Acc{u}_{y}\) curve of NGOAI-ANER model at 80%TRAS:20%TESS.
Figure 7 reveals a comprehensive analysis of the training loss (TRALS) and validation loss (VALLS) curves of the NGOAI-ANER methodology at dissimilar epochs 80:20 of TRAS/TESS. The gradual decrease in TRALS highlights the NGOAI-ANER methodology, improving the weights and reducing the identification error on both data. The result specifies a strong knowledge of the NGOAI-ANER approach linked with the TRA data, underlining its proficiency in seizing patterns in both data. Noticeably, the NGOAI-ANER approach frequently improves its parameters in decreasing the alterations among the prediction and real TRA classes.

Loss curve of NGOAI-ANER model at 80%TRAS:20%TESS.
DL NER results on 70:30 of training/testing dataset
Figure 8 exhibits the classification results of the NGOAI-ANER method at 70%:30% of TRAS/TESS. Figures 8a, b portrays the confusion matrix presented by the NGOAI-ANER method. The figure shows that the NGOAI-ANER method is familiar and considers every four classes exactly. Similarly, Fig. 8c exposes the PR research of the NGOAI-ANER method. The result defined that the NGOAI-ANER method has the maximum PR solution under four classes. However, Fig. 8d exemplifies the ROC curve of the NGOAI-ANER model. The figure shows that the NGOAI-ANER model has achieved adept results with peak values of ROC in separate classes.

70%:30% of TRAS/TESS (a–b) confusion matrices and (c–d) PR and ROC curves.
The NER outcomes of the NGOAI-ANER methodology are represented below: 70%TRAS and 30%TESS, as specified in Table 3 and Fig. 9. The experimentation outcomes described that the NGOAI-ANER methodology correctly knows various classes. With 70%TRAS, the NGOAI-ANER practice obtains an average \(acc{u}_{y}\) of 97.51%, \(pre{c}_{n}\) of 94.69%, \(rec{a}_{l}\) of 94.53%, and \({F1}_{score}\) of 94.61%. Additionally, with 30%TESS, the NGOAI-ANER approach obtains average \(acc{u}_{y}\) of 97.86%, \(pre{c}_{n}\) of 95.52%, \(rec{a}_{l}\) of 95.51%, and \({F1}_{score}\) of 95.52%

Average of NGOAI-ANER approach under 70%TRAS and 30%TESS.
The performance of the NGOAI-ANER is presented in Fig. 10 under the technique of TRAAC and VALAC outcomes 70:30 of TRAS/TESS. The outcome exhibits valuable clarification into the behaviour of the NGOAI-ANER model over various epochs, representing its learning method and generalization data. Unusually, the outcome achieves a solid development in the TRAAC and VALAC with progress in epoch counts. It verifies the NGOAI-ANER technique from the pattern recognition procedure on both data. The growing tendency in VALAC summarizes the NGOAI-ANER model’s capability to explain the TRA data and precisely identify unnoticed data.

\(Acc{u}_{y}\) curve of NGOAI-ANER approach at 70%:30% of TRAS/TESS.
Figure 11 establishes a comprehensive investigation of the TRALS and VALLS results of the NGOAI-ANER model over discrete epochs of 70%:30% of TRAS/TESS. The advanced decrease in TRALS highlights the NGOAI-ANER methodology, enhancing the weights and decreasing the identification error on both data. The outcome directs an explicit consideration into the NGOAI-ANER approach suggestion with the TRAS, emphasizing its capability to take patterns within both data. Significantly, the NGOAI-ANER model frequently recovers its parameters in decreasing the variances among the real and forecast TRA classes.

Loss curve of NGOAI-ANER approach at 70%:30% of TRAS/TESS.
Performance of NGOAI-ANER model and baselines
In Table 4 and Fig. 12, the final comparison outcome of the NGOAI-ANER method is illustrated33,34. The NGOAI-ANER model attained an \(acc{u}_{y}\) of 97.86%, \(pre{c}_{n}\) of 95.52%, \(rec{a}_{l}\) of 95.51%, and an \({F}_{score}\) of 95.52%, significantly outperforming the other models. The BERT-BGRU model exhibited an \(acc{u}_{y}\) of 90.46%, \(pre{c}_{n}\) of 90.40%, \(rec{a}_{l}\) of 90.66%, and an \({F}_{score}\) of 90.51%. The BRNN-ANER model achieved an \(acc{u}_{y}\) of 94.94%, \(pre{c}_{n}\) of 87.73%, \(rec{a}_{l}\) of 86.51%, and an \({F}_{score}\) of 87.12%. Meanwhile, the AraBERT model illustrated an \(acc{u}_{y}\) of 92.76%, \(pre{c}_{n}\) of 86.99%, \(rec{a}_{l}\) of 87.37%, and an \({F}_{score}\) of 84.20%. The CNN model achieved an \(acc{u}_{y}\) of 93.29%, \(pre{c}_{n}\) of 85.28%, \(rec{a}_{l}\) of 85.62%, and an \({F}_{score}\) of 85.10%, and the GRU model attained an \(acc{u}_{y}\) of 91.05%, \(pre{c}_{n}\) of 85.09%, \(rec{a}_{l}\) of 85.36%, and an \({F}_{score}\) of 85.16%. These results highlight the superiority of the NGOAI-ANER model in presenting higher \(acc{u}_{y}\), \(pre{c}_{n}\), \(rec{a}_{l}\), and \({F}_{score}\) for improved NER performance.

Comparative analysis of NGOAI-ANER technique with existing models.
Ablation study and error analysis of the NGOAI-ANER model and baseline techniques
Table 5 and Fig. 13 demonstrate the ablation study of the NGOAI-ANER method with existing techniques. The NGOAI-ANER method exhibits superior performance across all evaluation metrics with an \(acc{u}_{y}\) of 97.86%, \(pre{c}_{n}\) of 95.52%, \(rec{a}_{l}\) of 95.51%, and \({F}_{score}\) of 95.52%, indicating its robust capability in handling the classification task effectively. The SALSTM model also exhibits competitive results with an \(acc{u}_{y}\) of 97.35%, \(pre{c}_{n}\) of 94.80%, \(rec{a}_{l}\) of 94.88%, and \({F}_{score}\) of 94.85%, exhibiting its strength in capturing sequential dependencies. Meanwhile, the NGO-based method depicts robust performance with an \(acc{u}_{y}\) of 96.65%, \(pre{c}_{n}\) of 94.17%, \(rec{a}_{l}\) of 94.30%, and \({F}_{score}\) of 94.17%, highlighting the value of its optimization strategy. Overall, the NGOAI-ANER model outperforms both SALSTM and NGO techniques.

Result analysis of the ablation study of the NGOAI-ANER method.
Table 6 and Fig. 14 depict the error analysis of the NGOAI-ANER approach with existing models. The error analysis reveals that the NGOAI-ANER approach exhibits the lowest error rates across all metrics, with an \(acc{u}_{y}\) error of 2.14%, \(pre{c}_{n}\) error of 4.48%, \(rec{a}_{l}\) error of 4.49%, and \({F}_{score}\) error of 4.48%, indicating its robustness and reliability. The BERT-BGRU model exhibits higher error margins with 9.54% \(acc{u}_{y}\) error, 9.60% \(pre{c}_{n}\) error, 9.34% \(rec{a}_{l}\) error, and 9.49% \({F}_{score}\) error. The BRNN-ANER model attains 5.06% in \(acc{u}_{y}\) error, 12.27% in \(pre{c}_{n}\), 13.49% in \(rec{a}_{l}\), and 12.88% in \({F}_{score}\), illustrating greater inconsistencies. AraBERT exhibits a 7.24% \(acc{u}_{y}\) error, 13.01% in \(pre{c}_{n}\), 12.63% in \(rec{a}_{l}\), and a notably high 15.80% \({F}_{score}\) error. The CNN model has a 6.71% error in \(acc{u}_{y}\), 14.72% in \(pre{c}_{n}\), 14.38% in \(rec{a}_{l}\), and 14.90% in \({F}_{score}\). Meanwhile, the GRU model depicts 8.95% \(acc{u}_{y}\) error, 14.91% \(pre{c}_{n}\), 14.64% \(rec{a}_{l}\), and 14.84% \({F}_{score}\). These figures emphasize the consistent and minimal error of the NGOAI-ANER model compared to existing techniques.

Error analysis of the NGOAI-ANER methodology with existing techniques.
Conclusion
This work introduces a novel NGOAI-ANER technique in the Moroccan dialect. The NGOAI-ANER technique aims to enhance the precision and efficiency of NER models for Arabic text. To achieve that, the NGOAI-ANER technique contains various procedures, namely word embedding, SALSTM-based classification, and hyperparameter tuning. Initially, the NGOAI-ANER technique begins with word embedding techniques to transform the text into dense vector representations, capturing semantic information crucial for NER tasks. Moreover, the SALSTM model is trained on the embedded data, utilizing the merits of DL architectures to identify named entities within Arabic text accurately. The NGOAI-ANER approach utilizes the NGO model to fine-tune hyperparameters effectively to optimize the solution of the DL method. An experimental assessment of the DarNERcorp dataset demonstrates the efficacy and scalability of the NGOAI-ANER model. The experimentation of the NGOAI-ANER model demonstrated a superior accuracy value of 97.86% over existing approaches.
Data availability
The data supporting this study’s findings are openly available at https://data.mendeley.com/datasets/286sss4k9v/4, reference number 32.
References
Dekhili, G., Le, N. & Sadat, F. Improving named entity recognition with commonsense knowledge pre-training. Knowl. Manag. Acquis. Intel. Syst. 11669, 10–20 (2019).
Jin, G. & Yu, Z. A Korean named entity recognition method using Bi-LSTM-CRF and masked self-attention. Comput. Speech Lang. 65, 101134 (2021).
Wang, C., Chen, W. & Xu, B. Named entity recognition with gated convolutional neural networks. In Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data 110–121 (Springer, 2017).
Zhao, T. et al. BiGCNN: Bidirectional gated convolutional neural network for Chinese named entity recognition. In Dataset Systems for Advanced Applications 502–518 (Springer, 2010).
Sumithra, M., Buvaneswari, B., Sangeetha, S. & Sundareswari, V. P. P. Artificial intelligence based accident detection and alert system. J. Cogn. Human-Comput. Interact. 2(1), 29–33 (2022).
Xiaofeng, M., Wei, W. & Aiping, X. Incorporating token-level dictionary feature into a neural model for named entity recognition. Neurocomputing 375(6), 43–50 (2020).
Wintaka, D. C., Bijaksana, M. A. & Asror, I. Named-entity recognition on Indonesian tweets using bidirectional LSTM-CRF. Proc. Compu. Sci. 157, 221–228 (2019).
Huggard, H., Zhang, A., Zhang, E. & Koh, Y. Feature importance for biomedical named entity recognition. In AI 2019: Advances in Artificial Intelligence 406–417 (Springer, 2019).
Dadas, S. Combining neural and knowledge-based approaches to named entity recognition in Polish. In Artificial Intelligence and Soft Computing 39–50 (Springer, 2019).
Konoplich, G., Putin, E., Filchenkov, A. & Rybka, R. Named entity recognition in Russian with word representation learned by a bidirectional language model. In Artificial Intelligence and Natural Language 48–58 (Springer, 2018).
Anam, R. et al. A deep learning approach for Named Entity Recognition in Urdu language. PLoS ONE 19(3), e0300725 (2024).
Ait Benali, B., Mihi, S., Ait Mlouk, A., El Bazi, I. & Laachfoubi, N. Arabic named entity recognition in social media based on BiLSTM-CRF using an attention mechanism. J. Intell. Fuzzy Syst. 42(6), 5427–5436 (2022).
Chaimae, A., Ibtihal, M., Yacine, E. Y. & Hassan, B. Automatic configuration of deep learning algorithms for an Arabic named entity recognition system. Int. J. Adv. Comput. Sci. Appl. https://doi.org/10.14569/IJACSA.2023.0141012 (2023).
Goyal, A., Gupta, V. & Kumar, M. A deep neural framework for named entity recognition with boosted word embeddings. Multimed. Tools Appl. 83(6), 15533–15546 (2024).
Alsultani, H.S.M. and Aliwy, A.H., 2023, December. Arabic named entity recognition based on a sequence-2-sequence model with multi-head attention of transformer encoder. In AIP Conference Proceedings (Vol. 2977, No. 1). AIP Publishing.
Hatab, A.L., Sabty, C. and Abdennadher, S., 2022, June. Enhancing deep learning with embedded features for Arabic named entity recognition. In Proceedings of the Thirteenth Language Resources and Evaluation Conference (pp. 4904–4912).
Goyal, A., Gupta, V. & Kumar, M. Deep learning-based named entity recognition system using hybrid embedding. Cybern. Syst. 55(2), 279–301 (2024).
Hamad, R.M. and Abushaala, A.M., Medical Named Entity Recognition in Arabic Text using SVM. In 2023 IEEE 3rd International Maghreb Meeting of the Conference on Sciences and Techniques of Automatic Control and Computer Engineering (MI-STA) (pp. 200–205). IEEE (2023, May).
Tibi, N. & Messaoud, M. A. B. Arabic dialect classification using an adaptive deep learning model. Bull. Electric. Eng. Inf. 14(2), 1108–1116 (2025).
Bourahouat, G., Abourezq, M. & Daoudi, N. Improvement of Moroccan dialect sentiment analysis using Arabic BERT-based models. J. Comput. Sci 20(2), 157–167 (2024).
Mansour, O., Aboelela, E., Talaat, R. & Bustami, M. Transformer-based ensemble model for dialectal Arabic sentiment classification. PeerJ Comput. Sci. 11, e2644 (2025).
Jbel, M., Jabrane, M., Hafidi, I. & Metrane, A. Sentiment analysis dataset in Moroccan dialect: Bridging the gap between Arabic and Latin scripted dialect. Lang. Resour. Eval. 59, 1401–1430 (2024).
Bahbib, M., Ben Yakhlef, M. & Tamym, L. CNN-BILSTM based-hybrid automated model for arabic medical question categorization. Oper. Res. Forum 6(2), 41 (2025).
Ouza, A., Ouacha, A., Rachidi, A., El Ghmary, M. & Choukri, A. Enhancing Arabic Sentiment Analysis Using AraBERT and Deep Learning Models. In Modern Artificial Intelligence and Data Science 2024: Tools, Techniques and Systems 189–200 (Springer Nature Switzerland, 2024).
Dandash, M. & Asadpour, M. Personality analysis for social media users using Arabic language and its effect on sentiment analysis. Soc. Netw. Anal. Min. 15(1), 6 (2025).
Skiredj, A., Azhari, F., Berrada, I. & Ezzini, S. DarijaBanking: A new resource for overcoming language barriers in banking intent detection for Moroccan Arabic speakers. Natural Lang. Process. https://doi.org/10.1017/nlp.2024.55 (2024).
Magdy, S.M., Kwon, S.Y., Alwajih, F., Abdelfadil, S., Shehata, S. and Abdul-Mageed, M., 2025. Jawaher: A Multidialectal Dataset of Arabic Proverbs for LLM Benchmarking. arXiv preprint arXiv:2503.00231.
Mohammad, R., Alkhnbashi, O. S. & Hammoudeh, M. Optimizing large language models for arabic healthcare communication: A focus on patient-centered NLP applications. Big Data Cogn. Comput. 8(11), 157 (2024).
Youssef, A., Elattar, M. and El-Beltagy, S.R., 2020, October. A multi-embeddings approach coupled with deep learning for Arabic named entity recognition. In 2020 2nd Novel Intelligent and Leading Emerging Sciences Conference (NILES) (pp. 456–460). IEEE.
Zhang, H., Zhang, Q., Shao, S., Niu, T. & Yang, X. Attention-based LSTM network for rotatory machine remaining useful life prediction. Ieee Access 8, 132188–132199 (2020).
Dehghani, M., Hubálovský, Š & Trojovský, P. Northern goshawk optimization: a new swarm-based algorithm for solving optimization problems. Ieee Access 9, 162059–162080 (2021).
Moussa, H. N. & Mourhir, A. DarNERcorp: An annotated named entity recognition dataset in the Moroccan dialect. Data Brief 48, 109234 (2023).
Alsaaran, N. & Alrabiah, M. Arabic named entity recognition: A BERT-BGRU approach. Comput. Mater. Contin. 68(1), 471–485 (2021).
Acknowledgements
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Research Project under grant number RGP2/231/46. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R708), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. Ongoing Research Funding program, (ORF-2025-714), King Saud University, Riyadh, Saudi Arabia. The authors extend their appreciation to the Deanship of Scientific Research at Northern Border University, Arar, KSA for funding this research work through the project number “NBU-FFR-2025-2913-02. The authors are thankful to the Deanship of Graduate Studies and Scientific Research at University of Bisha for supporting this work through the Fast-Track Research Support Program.
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Subait, W.B., Ahmad, N., Alzaidi, M.S.A. et al. Unveiling Arabic named entity recognition using natural language processing with artificial intelligence approach on Moroccan dialect. Sci Rep 15, 30882 (2025). https://doi.org/10.1038/s41598-025-05940-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-05940-y
Keywords
关于《Unveiling Arabic named entity recognition using natural language processing with artificial intelligence approach on Moroccan dialect》的评论
发表评论
摘要
相关讨论
- 在新加坡做面试官的经历 (Interviewer Experience for UI/UX Designer in Singapore)
- Global Neck Cream and Mask Sales Market Surges with Demand for Targeted Skincare Solutions and Anti-Aging Innovations
- 刷Leetcode (01) Remove Duplicates from Sorted Array
- 分享一个消息:新加坡奇缺数据科学方面人才
- 大早上打扰了,请教审核问题 3.1: Apps or metadata that mentions the name of any other mobile platform will be rejected