
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
作者:Zhang, Zhen
Main
Reasoning capability, the cornerstone of human intelligence, enables complex cognitive tasks ranging from mathematical problem-solving to logical deduction and programming. Recent advances in AI have demonstrated that LLMs can exhibit emergent behaviours, including reasoning abilities, when scaled to a sufficient size4,5. However, achieving such capabilities in pre-training typically demands substantial computational resources. In parallel, a complementary line of research has demonstrated that LLMs can be effectively augmented through CoT prompting. This technique, which involves either providing carefully designed few-shot examples or using minimalistic prompts such as “Let’s think step by step”3,6, enables models to produce intermediate reasoning steps, thereby substantially enhancing their performance on complex tasks. Similarly, further performance gains have been observed when models learn high-quality, multistep reasoning trajectories during the post-training phase2,7. Despite their effectiveness, these approaches exhibit notable limitations. Their dependence on human-annotated reasoning traces slows scalability and introduces cognitive biases. Furthermore, by constraining models to replicate human thought processes, their performance is inherently capped by the human-provided exemplars, which prevents the exploration of superior, non-human-like reasoning pathways.
To tackle these issues, we aim to explore the potential of LLMs for developing reasoning abilities through self-evolution in a RL framework, with minimal reliance on human labelling efforts. Specifically, we build on DeepSeek-V3 Base8 and use Group Relative Policy Optimization (GRPO)9 as our RL framework. The reward signal is only based on the correctness of final predictions against ground-truth answers, without imposing constraints on the reasoning process itself. Notably, we bypass the conventional supervised fine-tuning (SFT) phase before RL training. This design choice originates from our hypothesis that human-defined reasoning patterns may limit model exploration, whereas unrestricted RL training can better incentivize the emergence of new reasoning capabilities in LLMs. Through this process, detailed in the next section, our model (referred to as DeepSeek-R1-Zero) naturally developed diverse and sophisticated reasoning behaviours. To solve reasoning problems, the model exhibits a tendency to generate longer responses, incorporating verification, reflection and the exploration of alternative approaches within each response. Although we do not explicitly teach the model how to reason, it successfully learns improved reasoning strategies through RL.
Although DeepSeek-R1-Zero demonstrates excellent reasoning capabilities, it faces challenges such as poor readability and language mixing, occasionally combining English and Chinese in a single CoT response. Furthermore, the rule-based RL training stage of DeepSeek-R1-Zero is narrowly focused on reasoning tasks, resulting in limited performance in broader areas such as writing and open-domain question answering. To address these challenges, we introduce DeepSeek-R1, a model trained through a multistage learning framework that integrates rejection sampling, RL and supervised fine-tuning, detailed in the ‘DeepSeek-R1’ section. This training pipeline enables DeepSeek-R1 to inherit the reasoning capabilities of its predecessor, DeepSeek-R1-Zero, while aligning model behaviour with human preferences through further non-reasoning data.
To enable broader access to powerful AI at a lower energy cost, we have distilled several smaller models and made them publicly available. These distilled models exhibit strong reasoning capabilities, surpassing the performance of their original instruction-tuned counterparts. We believe that these instruction-tuned versions will also greatly contribute to the research community by providing a valuable resource for understanding the mechanisms underlying long CoT reasoning models and for promoting the development of more powerful reasoning models. We release DeepSeek-R1-Zero, DeepSeek-R1, data samples and distilled models to the public as described in the ‘Code availability’ section.
DeepSeek-R1-Zero
To implement large-scale RL of DeepSeek-R1-Zero, we use a highly efficient RL pipeline. Specifically, we use GRPO9 as our RL algorithm, described in Methods section ‘GRPO’. Furthermore, we use a rule-based reward system to compute accuracy and format rewards, with detailed methodologies outlined in Methods section ‘Reward design’. Furthermore, our high-performance RL infrastructure is described in Supplementary Information, section 2.1, ensuring scalable and efficient training.
Specifically, we apply the RL technique on the DeepSeek-V3 Base to train DeepSeek-R1-Zero. During training, we design a straightforward template to require DeepSeek-R1-Zero to first produce a reasoning process, followed by the final answer. The prompt template is written as below.
“A conversation between User and Assistant. The User asks a question and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process and answer are enclosed within <think>...</think> and <answer>...</answer> tags, respectively, that is, <think> reasoning process here </think><answer> answer here </answer>. User: prompt. Assistant:”, in which the prompt is replaced with the specific reasoning question during training. We intentionally limit our constraints to this structural format, avoiding any content-specific biases to ensure that we can accurately observe the natural progression of the model during the RL process.
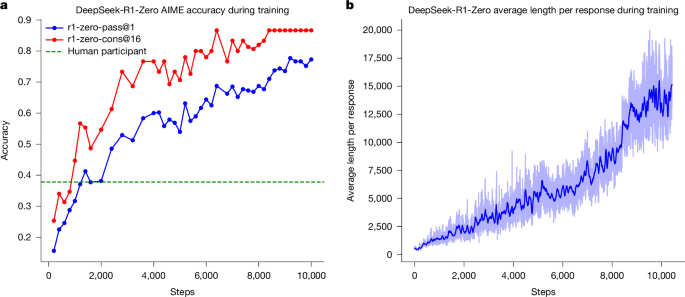
Figure 1a shows the performance trajectory of DeepSeek-R1-Zero on the American Invitational Mathematics Examination (AIME) 2024 benchmark throughout the RL training process, in which the average pass@1 score on AIME 2024 shows a marked increase, jumping from an initial value of 15.6% to 77.9%. Also, by using the self-consistency decoding10, the performance of the model can be further improved, achieving an accuracy of 86.7%. This performance greatly surpasses the average performance across all human competitors of the AIME. Besides the maths competitions, as shown in Supplementary Fig. 8, DeepSeek-R1-Zero also achieves remarkable performance in coding competitions and graduate-level biology, physics and chemistry problems. These results underscore the effectiveness of RL in enhancing the reasoning capabilities of LLMs.

a, AIME accuracy of DeepSeek-R1-Zero during training. AIME takes a mathematical problem as input and a number as output, illustrated in Extended Data Table 1. pass@1 and cons@16 are described in Supplementary Information, section 4.1. The baseline is the average score achieved by human participants in the AIME competition. b, The average response length of DeepSeek-R1-Zero on the training set during the RL process. DeepSeek-R1-Zero naturally learns to solve reasoning tasks with more thinking time. Note that a training step refers to a single policy update operation.
As well as the progressive enhancement of reasoning capabilities during training, DeepSeek-R1-Zero also demonstrates self-evolutionary behaviour with RL training. As shown in Fig. 1b, DeepSeek-R1-Zero exhibits a steady increase in thinking time throughout training, driven only by intrinsic adaptation rather than external modifications. Making use of long CoT, the model progressively refines its reasoning, generating hundreds to thousands of tokens to explore and improve its problem-solving strategies.
The increase in thinking time helps with the autonomous development of sophisticated behaviours. Specifically, DeepSeek-R1-Zero increasingly exhibits advanced reasoning strategies such as reflective reasoning and systematic exploration of alternative solutions provided in Extended Data Fig. 1a, substantially boosting its performance on verifiable tasks such as maths and coding. Notably, during training, DeepSeek-R1-Zero exhibits an ‘aha moment’, shown in Table 1, characterized by a sudden increase in the use of the word ‘wait’ during reflections, provided in Extended Data Fig. 1b. This moment marks a distinct change in reasoning patterns and clearly shows the self-evolution process of DeepSeek-R1-Zero.
The self-evolution of DeepSeek-R1-Zero underscores the power and beauty of RL: rather than explicitly teaching the model how to solve a problem, we simply provide it with the right incentives and it autonomously develops advanced problem-solving strategies. This serves as a reminder of the potential of RL to unlock higher levels of capabilities in LLMs, paving the way for more autonomous and adaptive models in the future.
DeepSeek-R1
Although DeepSeek-R1-Zero exhibits strong reasoning capabilities, it faces several issues. DeepSeek-R1-Zero struggles with challenges such as poor readability and language mixing, as DeepSeek-V3 Base is trained on several languages, especially English and Chinese. To address these issues, we develop DeepSeek-R1, whose pipeline is illustrated in Fig. 2. In the initial stage, we collect thousands of cold-start data that exhibit a conversational, human-aligned thinking process, as detailed in Supplementary Information, section 2.3.2. RL training is then applied with hyperparameters in Methods section ‘Training details of the first RL stage’, data details in Supplementary Information, section 2.3.1, to improve the model performance with the conversational thinking process and language consistency. Subsequently, we apply rejection sampling and SFT once more. This stage incorporates both reasoning and non-reasoning datasets into the SFT process, as detailed in Supplementary Information, section 2.3.3, enabling the model to not only excel in reasoning tasks but also demonstrate advanced writing capabilities. To further align the model with human preferences, we implement a secondary RL stage designed to enhance the helpfulness and harmlessness of the model while simultaneously refining its reasoning capabilities. The reward model is described in Methods section ‘Reward design’ and RL hyperparameters are in Methods section ‘Training details of the second RL stage’. The total training cost is listed in Supplementary Information, section 2.4.4.

A detailed background on DeepSeek-V3 Base and DeepSeek-V3 is provided in Supplementary Information, section 1.1. The models DeepSeek-R1 Dev1, Dev2 and Dev3 represent intermediate checkpoints in this pipeline.
We evaluate our models on MMLU11, MMLU-Redux12, MMLU-Pro13, DROP14, C-Eval15, IFEval16, FRAMES17, GPQA Diamond18, SimpleQA19, C-SimpleQA20, CLUEWSC21, AlpacaEval 2.0 (ref. 22), Arena-Hard23, SWE-bench Verified24, Aider-Polyglot25, LiveCodeBench26 (2024-08–2025-01), Codeforces27, Chinese National High School Mathematics Olympiad (CNMO 2024)28 and AIME 2024 (ref. 29). The details of these benchmarks are provided in Supplementary Tables 15–29.
Table 2 summarizes the performance of DeepSeek-R1 across several developmental stages, as outlined in Fig. 2. A comparison between DeepSeek-R1-Zero and DeepSeek-R1 Dev1 reveals substantial improvements in instruction-following, as evidenced by higher scores on the IF-Eval and Arena-Hard benchmarks. However, owing to the limited size of the cold-start dataset, Dev1 exhibits a partial degradation in reasoning performance compared with DeepSeek-R1-Zero, most notably on the AIME benchmark. By contrast, DeepSeek-R1 Dev2 demonstrates marked performance enhancements on benchmarks that require advanced reasoning skills, including those focused on code generation, mathematical problem solving and STEM-related tasks. Benchmarks targeting general-purpose tasks, such as AlpacaEval 2.0, show marginal improvement. These results indicate that reasoning-oriented RL considerably enhances reasoning capabilities while exerting limited influence on user-preference-oriented benchmarks.
DeepSeek-R1 Dev3 integrates both reasoning and non-reasoning datasets into the SFT pipeline, thereby enhancing the proficiency of the model in both reasoning and general language-generation tasks. Compared with Dev2, DeepSeek-R1 Dev3 achieves notable performance improvements on AlpacaEval 2.0 and Aider-Polyglot, attributable to the inclusion of large-scale non-reasoning corpora and code-engineering datasets. Finally, comprehensive RL training on DeepSeek-R1 Dev3 using mixed reasoning-focused and general-purpose data produced the final DeepSeek-R1. Marginal improvements occurred in code and mathematics benchmarks, as substantial reasoning-specific RL was done in previous stages. The primary advancements in the final DeepSeek-R1 were in general instruction-following and user-preference benchmarks, with AlpacaEval 2.0 improving by 25% and Arena-Hard by 17%.
We also compare DeepSeek-R1 with other models in Supplementary Information, section 4.2. Model safety evaluations are provided in Supplementary Information, section 4.3. A comprehensive analysis of evaluation is provided in Supplementary Information, section 5, including a comparison with DeepSeek-V3, performance evaluations on both fresh test sets, a breakdown of mathematical capabilities by category and an investigation of test-time scaling behaviour. Supplementary Information, section 6 shows that the strong reasoning capability can be transferred to smaller models.
Ethics and safety statement
With the advancement in the reasoning capabilities of DeepSeek-R1, we deeply recognize the potential ethical risks. For example, R1 can be subject to jailbreak attacks, leading to the generation of dangerous content such as explosive manufacturing plans, whereas the enhanced reasoning capabilities enable the model to provide plans with better operational feasibility and executability. Besides, a public model is also vulnerable to further fine-tuning that could compromise inherent safety protections.
In Supplementary Information, section 4.3, we present a comprehensive safety report from several perspectives, including performance on open-source and in-house safety evaluation benchmarks, and safety levels across several languages and against jailbreak attacks. These comprehensive safety analyses conclude that the inherent safety level of the DeepSeek-R1 model, compared with other state-of-the-art models, is generally at a moderate level (comparable with GPT-4o (2024-05-13)30). Besides, when coupled with the risk control system, the safety level of the model is increased to a superior standard.
Conclusion, limitation and future work
We present DeepSeek-R1-Zero and DeepSeek-R1, which rely on large-scale RL to incentivize model reasoning behaviours. Our results demonstrate that pre-trained checkpoints inherently have substantial potential for complex reasoning tasks. We believe that the key to unlocking this potential lies not in large-scale human annotation but in the provision of hard reasoning questions, a reliable verifier and sufficient computational resources for RL. Sophisticated reasoning behaviours, such as self-verification and reflection, seemed to emerge organically during the RL process.
Even if DeepSeek-R1 achieves frontier results on reasoning benchmarks, it still faces several capability limitations, as outlined below.
Structure output and tool use
At present, the structural output capabilities of DeepSeek-R1 remain suboptimal compared with existing models. Moreover, DeepSeek-R1 cannot make use of tools, such as search engines and calculators, to improve the performance of output. However, as it is not hard to build a RL environment for structure output and tool use, we believe that the issue will be addressed in the next version.
Token efficiency
Unlike conventional test-time computation scaling approaches, such as majority voting or Monte Carlo tree search (MCTS), DeepSeek-R1 dynamically allocates computational resources during inference according to the complexity of the problem at hand. Specifically, it uses fewer tokens to solve simple tasks but generating more tokens for complex tasks. Nevertheless, there remains room for further optimization in terms of token efficiency, as instances of excessive reasoning—manifested as overthinking—are still observed in response to simpler questions.
Language mixing
DeepSeek-R1 is at present optimized for Chinese and English, which may result in language-mixing issues when handling queries in other languages. For instance, DeepSeek-R1 might use English for reasoning and responses, even if the query is in a language other than English or Chinese. We aim to address this limitation in future updates. The limitation may be related to the base checkpoint, DeepSeek-V3 Base, which mainly uses Chinese and English, so that it can achieve better results with the two languages in reasoning.
Prompting engineering
When evaluating DeepSeek-R1, we observe that it is sensitive to prompts. Few-shot prompting consistently degrades its performance. Therefore, we recommend that users directly describe the problem and specify the output format using a zero-shot setting for optimal results.
Software-engineering tasks
Owing to the long evaluation times, which affect the efficiency of the RL process, large-scale RL has not been applied extensively in software-engineering tasks. As a result, DeepSeek-R1 has not demonstrated a huge improvement over DeepSeek-V3 on software-engineering benchmarks. Future versions will address this by implementing rejection sampling on software-engineering data or incorporating asynchronous evaluations during the RL process to improve efficiency.
Beyond specific capability limitations, the pure RL methodology itself also presents inherent challenges:
Reward hacking
The success of pure RL depends on reliable reward signals. In this study, we ensure reward reliability through a reasoning-domain rule-based reward model. However, such dependable reward models are difficult to construct for certain tasks, such as writing. If the reward signal is assigned by a model instead of predefined rules, it becomes more susceptible to exploitation as training progresses, which means that the policy model may find shortcuts to hack the reward model. Consequently, for complex tasks that cannot be effectively evaluated by a reliable reward model, scaling up pure RL methods remains an open challenge.
In this work, for tasks that cannot obtain a reliable signal, DeepSeek-R1 uses human annotation to create supervised data and only conducts RL for hundreds of steps. We hope that, in the future, a robust reward model can be obtained to address such issues.
With the advent of pure RL methods such as DeepSeek-R1, the future holds immense potential for solving any task that can be effectively evaluated by a verifier, regardless of its complexity for humans. Machines equipped with such advanced RL techniques are poised to surpass human capabilities in these domains, driven by their ability to optimize performance iteratively through trial and error. However, challenges remain for tasks for which constructing a reliable reward model is inherently difficult. In such cases, the lack of a robust feedback mechanism may slow progress, suggesting that future research should focus on developing innovative approaches to define and refine reward structures for these complex, less verifiable problems.
Furthermore, making use of tools during the reasoning process holds notable promise. Whether it is using tools such as compilers or search engines to retrieve or compute necessary information or using external tools such as biological or chemical reagents to validate final results in the real world, this integration of tool-augmented reasoning could greatly enhance the scope and accuracy of machine-driven solutions.
Methods
GRPO
GRPO9 is the RL algorithm that we use to train DeepSeek-R1-Zero and DeepSeek-R1. It was originally proposed to simplify the training process and reduce the resource consumption of proximal policy optimization (PPO)31, which is widely used in the RL stage of LLMs32. The pipeline of GRPO is shown in Extended Data Fig. 2.
For each question q, GRPO samples a group of outputs {o1, o2,…, oG} from the old policy \({\pi }_{{\theta }_{{\rm{old}}}}\) and then optimizes the policy model πθ by maximizing the following objective:
$$\begin{array}{ll} & {{\mathcal{J}}}_{{\rm{GRPO}}}(\theta )={\mathbb{E}}[q \sim P(Q),{\{{o}_{i}\}}_{i=1}^{G} \sim {\pi }_{{\theta }_{{\rm{old}}}}(O| q)]\\ & \frac{1}{G}\mathop{\sum }\limits_{i=1}^{G}\left(\min \left(\frac{{\pi }_{\theta }({o}_{i}| q)}{{\pi }_{{\theta }_{{\rm{old}}}}({o}_{i}| q)}{A}_{i},\,\text{clip}\left(\frac{{\pi }_{\theta }({o}_{i}| q)}{{\pi }_{{\theta }_{{\rm{old}}}}({o}_{i}| q)},1-{\epsilon },1+{\epsilon }\right){A}_{i}\right)-\beta {{\mathbb{D}}}_{KL}({\pi }_{\theta }| | {\pi }_{{\rm{ref}}})\right),\end{array}$$
(1)
$${{\mathbb{D}}}_{{\rm{KL}}}({\pi }_{\theta }| | {\pi }_{{\rm{ref}}})=\frac{{\pi }_{{\rm{ref}}}({o}_{i}| q)}{{\pi }_{\theta }({o}_{i}| q)}-\log \frac{{\pi }_{{\rm{ref}}}({o}_{i}| q)}{{\pi }_{\theta }({o}_{i}| q)}-1,$$
(2)
in which πref is a reference policy, ϵ and β are hyperparameters and Ai is the advantage, computed using a group of rewards {r1, r2,…, rG} corresponding to the outputs in each group:
$${A}_{i}=\frac{{r}_{i}-{\rm{mean}}(\{{r}_{1},{r}_{2},\cdots \,,{r}_{G}\})}{{\rm{std}}(\{{r}_{1},{r}_{2},\cdots \,,{r}_{G}\})}.$$
(3)
We give a comparison of GRPO and PPO in Supplementary Information, section 1.3.
Reward design
The reward is the source of the training signal, which decides the direction of RL optimization. For DeepSeek-R1-Zero, we use rule-based rewards to deliver precise feedback for data in mathematical, coding and logical reasoning domains. For DeepSeek-R1, we extend this approach by incorporating both rule-based rewards for reasoning-oriented data and model-based rewards for general data, thereby enhancing the adaptability of the learning process across diverse domains.
Rule-based rewards
Our rule-based reward system mainly consists of two types of reward: accuracy rewards and format rewards.
Accuracy rewards evaluate whether the response is correct. For example, in the case of maths problems with deterministic results, the model is required to provide the final answer in a specified format (for example, within a box), enabling reliable rule-based verification of correctness. Similarly, for code competition prompts, a compiler can be used to evaluate the responses of the model against a suite of predefined test cases, thereby generating objective feedback on correctness.
Format rewards complement the accuracy reward model by enforcing specific formatting requirements. In particular, the model is incentivized to encapsulate its reasoning process within designated tags, specifically <think> and </think>. This ensures that the thought process of the model is explicitly delineated, enhancing interpretability and facilitating subsequent analysis.
$${{\rm{Reward}}}_{{\rm{rule}}}={{\rm{Reward}}}_{{\rm{acc}}}+{{\rm{Reward}}}_{{\rm{format}}}$$
(4)
The accuracy, reward and format reward are combined with the same weight. Notably, we abstain from applying neural reward models—whether outcome-based or process-based-to reasoning tasks. This decision is predicated on our observation that neural reward models are susceptible to reward hacking during large-scale RL. Moreover, retraining such models necessitates substantial computational resources and introduces further complexity into the training pipeline, thereby complicating the overall optimization process.
Model-based rewards
For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios. We build on the DeepSeek-V3 pipeline and use a similar distribution of preference pairs and training prompts. For helpfulness, we focus exclusively on the final summary, ensuring that the assessment emphasizes the use and relevance of the response to the user while minimizing interference with the underlying reasoning process. For harmlessness, we evaluate the entire response of the model, including both the reasoning process and the summary, to identify and mitigate any potential risks, biases or harmful content that may arise during the generation process.
Helpful reward model
For helpful reward model training, we first generate preference pairs by prompting DeepSeek-V3 using the Arena-Hard prompt format, listed in Supplementary Information, section 2.2, for which each pair consists of a user query along with two candidate responses. For each preference pair, we query DeepSeek-V3 four times, randomly assigning the responses as either Response A or Response B to mitigate positional bias. The final preference score is determined by averaging the four independent judgments, retaining only those pairs for which the score difference (Δ) exceeds 1 to ensure meaningful distinctions. Furthermore, to minimize length-related biases, we ensure that the chosen and rejected responses of the whole dataset have comparable lengths. In total, we curated 66,000 data pairs for training the reward model. The prompts used in this dataset are all non-reasoning questions and are sourced either from publicly available open-source datasets or from users who have explicitly consented to share their data for the purpose of model improvement. The architecture of our reward model is consistent with that of DeepSeek-R1, with the addition of a reward head designed to predict scalar preference scores.
$${{\rm{Reward}}}_{{\rm{helpful}}}={{\rm{RM}}}_{{\rm{helpful}}}({{\rm{Response}}}_{{\rm{A}}},{{\rm{Response}}}_{{\rm{B}}})$$
(5)
The helpful reward models were trained with a batch size of 256, a learning rate of 6 × 10−6 and for a single epoch over the training dataset. The maximum sequence length during training is set to 8,192 tokens, whereas no explicit limit is imposed during reward model inference.
Safety reward model
To assess and improve model safety, we curated a dataset of 106,000 prompts with model-generated responses annotated as ‘safe’ or ‘unsafe’ according to predefined safety guidelines. Unlike the pairwise loss used in the helpfulness reward model, the safety reward model was trained using a pointwise methodology to distinguish between safe and unsafe responses. The training hyperparameters are the same as the helpful reward model.
$${{\rm{Reward}}}_{\text{safety}}={{\rm{RM}}}_{\text{safety}}({\rm{Response}})$$
(6)
For general queries, each instance is categorized as belonging to either the safety dataset or the helpfulness dataset. The general reward, Rewardgeneral, assigned to each query corresponds to the respective reward defined in the associated dataset.
Training details
Training details of DeepSeek-R1-Zero
To train DeepSeek-R1-Zero, we set the learning rate to 3 × 10−6, the Kullback–Leibler (KL) coefficient to 0.001 and the sampling temperature to 1 for rollout. For each question, we sample 16 outputs with a maximum length of 32,768 tokens before the 8.2k step and 65,536 tokens afterward. As a result, both the performance and response length of DeepSeek-R1-Zero exhibit a substantial jump at the 8.2k step, with training continuing for a total of 10,400 steps, corresponding to 1.6 training epochs. Each training step consists of 32 unique questions, resulting in a training batch size of 512 per step. Every 400 steps, we replace the reference model with the latest policy model. To accelerate training, each rollout generates 8,192 outputs, which are randomly split into 16 minibatches and trained for only a single inner epoch.
Training details of the first RL stage
In the first stage of RL, we set the learning rate to 3 × 10−6, the KL coefficient to 0.001, the GRPO clip ratio ϵ to 10 and the sampling temperature to 1 for rollout. For each question, we sample 16 outputs with a maximum length of 32,768. Each training step consists of 32 unique questions, resulting in a training batch size of 512 per step. Every 400 steps, we replace the reference model with the latest policy model. To accelerate training, each rollout generates 8,192 outputs, which are randomly split into 16 minibatches and trained for only a single inner epoch. However, to mitigate the issue of language mixing, we introduce a language consistency reward during RL training, which is calculated as the proportion of target language words in the CoT.
$${{\rm{Reward}}}_{{\rm{language}}}=\frac{{\rm{Num}}({{\rm{Words}}}_{{\rm{target}}})}{{\rm{Num}}({\rm{Words}})}$$
(7)
Although ablation experiments in Supplementary Information, sction 2.6 show that such alignment results in a slight degradation in the performance of the model, this reward aligns with human preferences, making it more readable. We apply the language consistency reward to both reasoning and non-reasoning data by directly adding it to the final reward.
Note that the clip ratio plays a crucial role in training. A lower value can lead to the truncation of gradients for a large number of tokens, thereby degrading the performance of the model, whereas a higher value may cause instability during training. Details of RL data used in this stage are provided in Supplementary Information, section 2.3.
Training details of the second RL stage
Specifically, we train the model using a combination of reward signals and diverse prompt distributions. For reasoning data, we follow the methodology outlined in DeepSeek-R1-Zero, which uses rule-based rewards to guide learning in mathematical, coding and logical reasoning domains. During the training process, we observe that CoT often exhibits language mixing, particularly when RL prompts involve several languages. For general data, we use reward models to guide training. Ultimately, the integration of reward signals with diverse data distributions enables us to develop a model that not only excels in reasoning but also assigns priority to helpfulness and harmlessness. Given a batch of data, the reward can be formulated as
$${\rm{Reward}}={{\rm{Reward}}}_{{\rm{reasoning}}}+{{\rm{Reward}}}_{{\rm{general}}}+{{\rm{Reward}}}_{{\rm{language}}}$$
(8)
in which
$${{\rm{Reward}}}_{{\rm{reasoning}}}={{\rm{Reward}}}_{{\rm{rule}}}$$
(9)
$${{\rm{Reward}}}_{{\rm{general}}}={{\rm{Reward}}}_{\text{reward\_model}}+{{\rm{Reward}}}_{\text{format}}$$
(10)
The second stage of RL retains most of the parameters from the first stage, with the key difference being a reduced temperature of 0.7, as we find that higher temperatures in this stage lead to incoherent generation. The stage comprises a total of 1,700 training steps, during which general instruction data and preference-based rewards are incorporated exclusively in the final 400 steps. We find that more training steps with the model-based preference reward signal may lead to reward hacking, which is documented in Supplementary Information, section 2.5.
Data availability
We provide the data samples used in our rejection sampling and RL prompts at https://github.com/deepseek-ai/DeepSeek-R1 (https://doi.org/10.5281/zenodo.15753193)33. Comprehensive statistics and details of our complete data-generation methodology are presented in Supplementary Information, section 2.3.
Code availability
Trained weights of DeepSeek-R1-Zero and DeepSeek-R1 are available under an MIT license at https://github.com/deepseek-ai/DeepSeek-R1 (https://doi.org/10.5281/zenodo.15753193)33. The inference script is released at https://github.com/deepseek-ai/DeepSeek-V3 (https://doi.org/10.5281/zenodo.15753347)34. Neural networks were developed with PyTorch35 and the distributed framework is based on our internal framework HAI-LLM (https://www.high-flyer.cn/en/blog/hai-llm). The inference framework is based on vLLM36. Data analysis used Python v.3.8 (https://www.python.org/), NumPy v.1.23.1 (https://github.com/numpy/numpy), Matplotlib v.3.5.2 (https://github.com/matplotlib/matplotlib) and TensorBoard v.2.9.1 (https://github.com/tensorflow/tensorboard).
References
Brown, T. B. et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33 (eds Larochelle, H. et al.) (ACM, 2020).
OpenAI et al. GPT4 technical report. Preprint at https://doi.org/10.48550/arXiv.2303.08774 (2024).
Wei, J. et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35 (eds Koyejo, S. et al.) 24824–24837 (ACM, 2022).
Wei, J. et al. Emergent abilities of large language models. In Transactions on Machine Learning Research (eds Kamath, G. et al.) (2022).
Kaplan, J. et al. Scaling laws for neural language models. Preprint at https://doi.org/10.48550/arXiv.2001.08361 (2020).
Kojima, T., Gu, S. S., Reid, M., Matsuo, Y. & Iwasawa, Y. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems 35 (eds Oh, A. H. et al.) 22199–22213 (ACM, 2022).
Chung, H. W. et al. Scaling instruction-finetuned language models. J. Mach. Learn. Res. 25, 1–53 (2024).
DeepSeek-AI et al. DeepSeek-V3 technical report. Preprint at https://doi.org/10.48550/arXiv.2412.19437 (2025).
Shao, Z. et al. DeepSeekMath: pushing the limits of mathematical reasoning in open language models. Preprint at https://doi.org/10.48550/arXiv.2402.03300 (2024).
Wang, X. et al. Self-consistency improves chain of thought reasoning in language models. In 11th International Conference on Learning Representations (ICLR, 2023).
Hendrycks, D. et al. Measuring massive multitask language understanding. In 9th International Conference on Learning Representations (ICLR, 2021).
Gema, A. P. et al. Are we done with MMLU? In Proc. 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (eds Chiruzzo, L. et al.) Vol. 1 (Long Papers), 5069–5096 (ACL, 2025).
Wang, Y. et al. MMLU-Pro: a more robust and challenging multi-task language understanding benchmark. In Advances in Neural Information Processing Systems 37 (eds Globersons, A. et al.) 95266–95290 (ACM, 2024).
Dua, D. et al. DROP: a reading comprehension benchmark requiring discrete reasoning over paragraphs. In Proc. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Vol. 1 (Long and Short Papers) (eds Burstein, J. et al.) 2368–2378 (ACL, 2019).
Huang, Y. et al. C-EVAL: a multi-level multi-discipline Chinese evaluation suite for foundation models. In Advances in Neural Information Processing Systems 36 (eds Oh, A. et al.) 62991–63010 (ACM, 2023).
Zhou, J. et al. Instruction-following evaluation for large language models. Preprint at https://doi.org/10.48550/arXiv.2311.07911 (2023).
Krishna, S. et al. Fact, fetch, and reason: a unified evaluation of retrieval-augmented generation. In Proc. 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies Vol. 1 (Long Papers) 4745–4759 (ACL, 2025).
Rein, D. et al. GPQA: a graduate-level Google-proof Q&A benchmark. Preprint at https://doi.org/10.48550/arXiv.2311.12022 (2023).
OpenAI. Introducing SimpleQA; https://openai.com/index/introducing-simpleqa/ (2024).
He, Y. et al. Chinese SimpleQA: a Chinese factuality evaluation for large language models. In Proc. 63rd Annual Meeting of the Association for Computational Linguistics Vol. 1 (Long Papers), 19182–19208 (ACL, 2025).
Xu, L. et al. CLUE: a Chinese Language Understanding Evaluation benchmark. In Proc. 28th International Conference on Computational Linguistics (eds Scott, D. et al.) 4762–4772 (International Committee on Computational Linguistics, 2020).
Dubois, Y., Galambosi, B., Liang, P. & Hashimoto, T. B. Length-controlled AlpacaEval: a simple way to debias automatic evaluators. Preprint at https://doi.org/10.48550/arXiv.2404.04475 (2025).
Li, T. et al. From crowdsourced data to high-quality benchmarks: Arena-Hard and BenchBuilder pipeline. Preprint at https://doi.org/10.48550/arXiv.2406.11939 (2024).
OpenAI. Introducing SWE-bench verified; https://openai.com/index/introducing-swe-bench-verified/ (2024).
Aider. Aider LLM leaderboards; https://aider.chat/docs/leaderboards/ (2024).
Jain, N. et al. LiveCodeBench: holistic and contamination free evaluation of large language models for code. In 13th International Conference on Learning Representations (ICLR, 2024).
Mirzayanov, M. Codeforces; https://codeforces.com/ (2025).
Chinese Mathematical Society (CMS). Chinese National High School Mathematics Olympiad; https://www.cms.org.cn/Home/comp/comp/cid/12.html (2024).
Mathematical Association of America. American Invitational Mathematics Examination; https://maa.org/maa-invitational-competitions (2024).
OpenAI. Hello GPT-4o; https://openai.com/index/hello-gpt-4o/ (2024).
Schulman, J., Wolski, F., Dhariwal, P., Radford, A. & Klimov, O. Proximal policy optimization algorithms. Preprint at https://doi.org/10.48550/arXiv.1707.06347 (2017).
Ouyang, L. et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35 (eds Koyejo, S. et al.) 27730–27744 (ACM, 2022).
Nano et al. deepseek-ai/DeepSeek-R1: v1.0.0. Zenodo https://doi.org/10.5281/zenodo.15753192 (2025).
Yu, X. et al. deepseek-ai/DeepSeek-V3: v1.0.0. Zenodo https://doi.org/10.5281/zenodo.15753346 (2025).
Paszke, A. et al. PyTorch: an imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32 (eds Wallach, H. M. et al.) 8026–8037 (ACM, 2019).
Kwon, W. et al. Efficient memory management for large language model serving with PagedAttention. In Proc. ACM SIGOPS 29th Symposium on Operating Systems Principles 611–626 (ACM, 2023).
Acknowledgements
The research is supported by DeepSeek-AI.
Ethics declarations
Competing interests
The authors declare no competing interests and will not file patents related to the content of this manuscript.
Peer review
Peer review information
Nature thanks Edward Beeching, Yarin Gal, José Hernández-Orallo, Daphne Ippolito, Subbarao Kambhampati, Lewis Tunstall, Yiming Zhang and Lexin Zhou for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Evolution of reasoning-related linguistic features in model outputs across training steps.
a, Frequency of representative reflective terms in model-generated outputs throughout the training process. Reflective terms—including ‘wait’, ‘mistake’, ‘however’, ‘but’, ‘retry’, ‘error’, ‘verify’, ‘wrong’, ‘evaluate’ and ‘check’—were identified and curated by a panel of three human experts. Each expert independently proposed a set of words indicative of reflective reasoning, which were subsequently consolidated through consensus into a final vocabulary list. b, Frequency of the term ‘wait’ in model outputs over the course of training. This term was virtually absent during the initial training stages, appeared sporadically between steps 4,000 and 7,000 and exhibited a marked increase in frequency after step 8,000. These trends suggest the emergence of temporal reasoning or self-monitoring behaviour as training progresses.
Extended Data Fig. 2 Illustration of the proposed GRPO for RL-based training.
In the proposed framework, a LLM is used as a policy model to generate responses {o1, o2,…, oG} conditioned on a given query q. Each response within the group is evaluated by a reward model—either learned (model-based) or manually specified (rule-based)—to assign a scalar reward signal. Subsequently, GRPO computes the relative advantages of each group member based on their assigned rewards. Rather than relying on an explicit value function, as in PPO, GRPO directly estimates advantages from the intra-group reward distribution. The policy parameters are then updated to maximize the expected reward while simultaneously minimizing divergence from a reference policy, typically quantified through the KL divergence. By eliminating the need for a separate value network, GRPO offers a simplified yet effective alternative to traditional actor-critic methods such as PPO.
Supplementary information
Supplementary Information
Supplementary Sections 1–11, including Supplementary Tables 1–29 and Supplementary Figs. 1–16 – see Contents for details.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Guo, D., Yang, D., Zhang, H. et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature 645, 633–638 (2025). https://doi.org/10.1038/s41586-025-09422-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-025-09422-z