
负责任的 AI:PowerSchool 如何使用 Amazon SageMaker AI 通过 AI 驱动的内容过滤来保护数百万学生的安全 |亚马逊网络服务
这篇文章是与 PowerSchool 的 Gayathri Rengarajan 和 Harshit Kumar Nyati 共同撰写的。动力学校
是一家领先的 K-12 教育云软件提供商,为 90 多个国家/地区的超过 6000 万名学生和 18,000 多个客户提供服务,其中包括美国学生入学率排名前 100 的地区中的 90 多个地区。当我们推出跨多个教育平台集成的人工智能助手 PowerBuddy™ 时,我们面临着一个严峻的挑战:实施足够复杂的内容过滤,以区分合法的学术讨论和教育环境中的有害内容。
在这篇文章中,我们演示了如何使用构建和部署自定义内容过滤解决方案亚马逊 SageMaker 人工智能在保持较低误报率的同时实现了更高的准确性。我们将详细介绍微调 Llama 3.1 8B 的技术方法、我们的部署架构以及内部验证的性能结果。
PowerSchool 的 PowerBuddy
PowerBuddy 是一款人工智能助手,可提供个性化见解、促进参与并在整个教育过程中提供支持。教育领导者受益于 PowerBuddy 为他们的数据和用户带来的 PowerSchool 生态系统中最常见的工作流程(例如 Schoology Learning、Naviance CCLR、PowerSchool SIS、Performance Matters 等),以确保学生及其支持提供者网络在学校和家里获得一致的体验。
PowerBuddy 套件包括多种人工智能解决方案:PowerBuddy for Learning 功能作为虚拟导师;PowerBuddy for College and Career 为职业探索提供见解;PowerBuddy for Community 简化了对学区和学校信息及其他信息的访问。该解决方案包括内置的辅助功能,例如语音转文本和文本转语音功能。
PowerBuddy 的内容过滤
作为为数百万学生(其中许多是未成年人)提供服务的教育技术提供商,学生安全是我们的首要任务。国家数据显示大约 20% 的 12 至 17 岁学生遭受过欺凌,16% 的高中生曾严重考虑过自杀。随着 PowerBuddy 在 K-12 学校中的广泛采用,我们需要专门针对教育环境进行校准的坚固护栏。
市场上现成的内容过滤和安全护栏解决方案并不能完全满足 PowerBuddy 的要求,主要是因为需要在教育环境中进行特定领域的认知和微调。例如,当一名高中生学习二战或大屠杀等敏感历史话题时,重要的是教育讨论不会被错误地标记为暴力内容。同时,系统必须能够检测潜在危害或威胁的迹象并立即向学校管理人员发出警报。实现这种微妙的平衡需要深入的背景理解,而这只能通过有针对性的微调来实现。
我们需要实施一个复杂的内容过滤系统,能够智能地区分合法的学术查询和真正有害的内容,检测并阻止表明欺凌、自残、仇恨言论、不当性内容、暴力或不适合教育环境的有害材料的提示。我们面临的挑战是找到一种云解决方案来训练和托管自定义模型,该模型可以可靠地保护学生,同时保持 PowerBuddy 的教育功能。
在评估了多个允许模型定制和微调的人工智能提供商和云服务后,我们选择了亚马逊 SageMaker 人工智能根据这些关键要求作为最合适的平台:
- 平台稳定性:作为每天支持数百万学生的关键任务服务,我们需要具有高可用性和可靠性的企业级基础设施。
- 自动缩放功能:学生在教育领域的使用模式具有很强的周期性,在上课期间流量会出现显着峰值。我们的解决方案需要在不降低性能的情况下处理这些波动。
- 微调后模型权重的控制:我们需要控制我们的微调模型,以不断完善我们的安全护栏,使我们能够快速响应教育环境中可能出现的新型有害内容。
- 增量训练能力:通过有问题的内容的新示例不断改进我们的内容过滤模型的能力至关重要。
- 成本效益:我们需要一种解决方案,既能保护学生,又不会产生过高的成本,从而限制学校使用我们的教育工具。
- 精细控制和透明度:学生的安全需要了解我们的过滤决策是如何做出的,需要一个不只是一个解决方案黑匣子但提供了模型行为和性能的透明度。
- 成熟的托管服务:我们的团队需要专注于教育应用程序而不是基础设施管理,因此具有生产就绪功能的全面托管服务至关重要。
解决方案概述
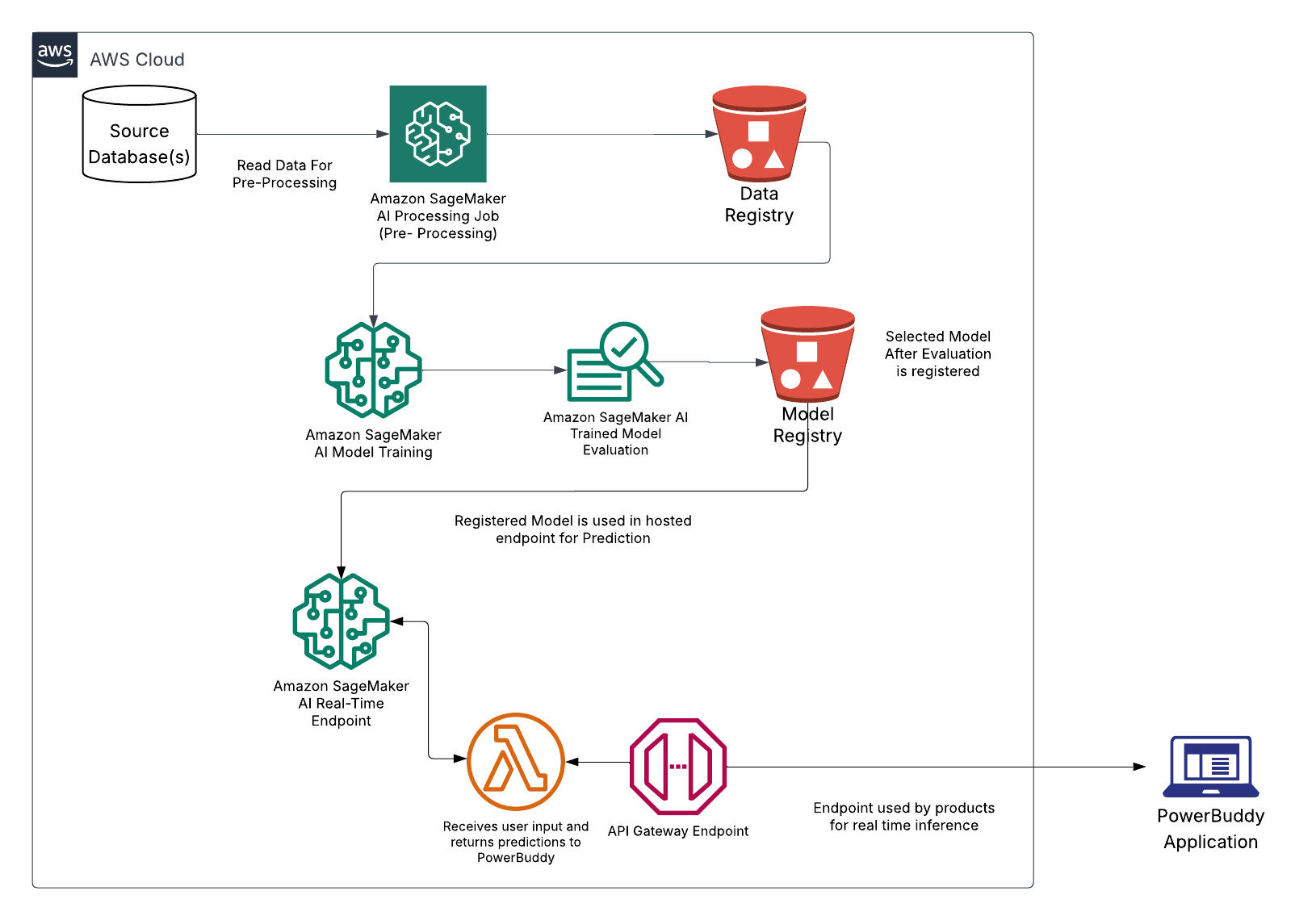
我们的内容过滤系统架构,如上图所示,由几个关键组件组成:
- 数据准备管道:
- 针对教育环境的安全和不安全内容示例的精选数据集
- 数据预处理和增强以确保稳健的模型训练
- 安全存储在亚马逊S3具有适当加密和访问控制的存储桶
注:所有培训数据均完全匿名,不包含学生个人身份信息
- 模型训练基础设施:
- 用于微调 Llama 3.1 8B 的 SageMaker 训练作业
- 推理架构:
- 在配置了自动扩展的 SageMaker 托管端点上部署
- 通过以下方式与 PowerBuddy 集成亚马逊 API 网关用于实时内容过滤
- 监控和记录亚马逊云观察用于持续的质量评估
- 持续改进循环:
- 误报/漏报的反馈收集机制
- 安排再培训周期以纳入新数据并提高性能
- A/B 测试框架,用于在完全部署之前评估模型改进
开发流程
在探索了多种内容过滤方法后,我们决定使用以下方法对 Llama 3.1 8B 进行微调Amazon SageMaker JumpStart。这一决定是在我们最初尝试从头开始开发内容过滤模型之后做出的,事实证明,优化各种类型有害内容的一致性具有挑战性。
SageMaker JumpStart 通过提供预配置的环境和优化的超参数来微调基础模型,显着加快了我们的开发流程。该平台简化的工作流程使我们的团队能够专注于整理针对教育安全问题的高质量培训数据,而不是花时间在基础设施设置和超参数调整上。
我们在 Amazon SageMaker AI 训练作业上使用低秩适应 (LoRA) 技术对 Llama 3.1 8B 模型进行了微调,这使我们能够保持对训练过程的完全控制。
微调完成后,我们将模型部署在 SageMaker AI 托管端点上,并将其作为关键安全组件集成到我们的 PowerBuddy 架构中。
对于我们的生产部署,我们选择了通过 ml.g5.12xlarge 实例提供的 NVIDIA A10G GPU,这为我们的模型大小提供了性能和成本效益的理想平衡。AWS 团队为我们的用例选择最佳模型服务配置提供了重要指导。该建议确保我们不会过度配置资源,从而帮助我们优化性能和成本。
技术实施
下面是在预处理数据集上微调模型的代码片段。指令调整数据集首先转换为域适应数据集格式,脚本利用完全分片数据并行(FSDP)以及低秩适应(LoRA)方法来微调模型。
我们首先定义一个估计器对象。默认情况下,这些模型通过域适应进行训练,因此您必须通过设置指令调整超参数到真的。
估计器 = JumpStartEstimator(model_id=model_id,环境={"accept_eula": "true"},disable_output_compression=真,超参数={"instruction_tuned": "正确",“时代”:“5”,“最大输入长度”:“1024”,"chat_dataset": "假"},sagemaker_session=会话,基本作业名称 = "CF-M-0219251")定义估计器后,我们就可以开始训练了:
estimator.fit({"training": train_data_location})
训练后,我们使用存储在 S3 中的工件创建了一个模型,并将该模型部署到实时端点进行评估。我们使用测试数据集测试了模型,该数据集涵盖了验证性能和行为的关键场景。我们计算了召回率、F1、混淆矩阵并检查了错误分类。如果需要,调整超参数/提示模板并重新训练;否则继续生产部署。
您还可以在 SageMaker JumpStart 中查看用于微调 Llama 3 模型的示例笔记本SageMaker 示例。
我们使用了Amazon SageMaker 实时终端节点上的自动扩展速度更快用于在 SageMaker AI 端点上设置自动缩放的笔记本。
解决方案的验证
为了验证我们的内容过滤解决方案,我们在多个维度进行了广泛的测试:
- 准确度测试:在我们的内部验证测试中,该模型在代表各种形式的不当材料的不同测试集中识别有害内容的准确率约为 93%。
- 误报分析:我们努力最大程度地减少合法教育内容被错误标记为有害的情况,在测试环境中实现误报率低于 3.75%;结果可能因学校情况而异。
- 性能测试:我们的解决方案保持平均响应时间为 1.5 秒。即使在模拟真实教室环境的高峰使用期间,该系统也始终如一地提供无缝的用户体验,没有失败的交易。
- 可扩展性和可靠性验证:
- 全面的负载测试实现了 100% 的事务成功率和一致的性能分布,验证了系统在持续教育工作负载条件下的可靠性。
- 事务成功完成,且性能或准确性没有下降,这证明了系统能够针对教室规模的并发使用场景进行有效扩展。
- 生产部署:最初向选定的一组学校进行的推广在现实教育环境中表现出一致的表现。
- 学生安全成果:与其他没有专门内容过滤的人工智能系统相比,学校报告的人工智能欺凌或不当内容生成事件显着减少。
与开箱即用的内容过滤解决方案相比,经过微调的模型指标
经过微调的内容过滤模型在关键安全指标方面表现出比通用的开箱即用过滤解决方案更高的性能。它实现了更高的准确度(0.93 与 0.89 相比),以及更好的 F1 分数安全的(0.95 与 0.91 相比)和不安全(0.90 与 0.87 相比)类。经过微调的模型还展示了精确度和召回率之间更平衡的权衡,表明跨类别的性能更加一致。重要的是,与 160 个测试集中的 19 个原始响应相比,它仅将 6 个安全案例错误分类为不安全,从而减少了误报,这在安全敏感应用程序中具有显着优势。总的来说,我们微调的内容过滤模型被证明更加可靠和有效。
未来计划
随着 PowerBuddy 套件的发展并集成到其他 PowerSchool 产品和代理流程中,内容过滤器模型将不断适应和改进,并针对具有特定需求的其他产品进行微调。
我们计划使用 SageMaker AI 实施其他专用适配器多适配器推理在考虑可行性和合规性的情况下,与我们的内容过滤模型一起使用。这个想法是在大型语言模型 (LLM) 庞大且通用且无法满足较窄问题领域的需求的情况下,部署微调的小语言模型 (SLM) 来解决特定问题。例如:
- 特定于教育领域的决策代理
- 文本到 SQL 查询时的数据域识别
这种方法将消除单独模型部署的需要,同时保持每个适配器的专业性能,从而显着节省成本。
我们的目标是在我们的全球实施中创建一个不仅安全、而且具有包容性并能够满足不同学生需求的人工智能学习环境,最终使学生能够有效学习,同时免受有害内容的侵害。
结论
我们在 Amazon SageMaker AI 上实施专门的内容过滤系统,为 PowerSchool 在教育环境中提供安全 AI 体验的能力带来了变革。通过建立坚固的护栏,我们解决了教育工作者和家长将人工智能引入课堂的主要担忧之一,帮助确保学生的安全。
正如我们的首席产品官 Shivani Stumpf 所解释的:– 我们现在正在跟踪大约 500 个已购买 PowerBuddy 或激活包含功能的学区,覆盖大约超过 420 万学生。我们的内容过滤技术可确保学生能够从人工智能驱动的学习支持中受益,而无需接触有害内容,从而为学术成长和探索创造安全的空间。
其影响不仅仅是阻止有害内容。通过建立对我们的人工智能系统的信任,我们使学校能够将 PowerBuddy 作为一种有价值的教育工具。教师们表示,他们花在监控学生与技术的互动上的时间更少,而花在个性化教学上的时间更多。学生可以受益于 24/7 的学习支持,而无需承担人工智能访问可能带来的风险。
对于需要特定领域安全护栏的组织,请考虑如何调整 SageMaker AI 的微调功能和托管端点以适应您的使用案例。
随着我们继续通过 SageMaker 的多适配器推理扩展 PowerBuddy 的功能,我们仍然致力于保持教育创新和学生安全之间的完美平衡,帮助确保 AI 成为家长、教师和学生可以信任的教育领域的积极力量。
关于作者
![]() 加亚斯里·伦加拉詹是 PowerSchool 数据科学副总监,领导 PowerBuddy 计划。Gayathri 因将深厚的技术专业知识与战略业务需求联系起来而闻名,在提供从概念到生产的企业级生成式人工智能解决方案方面拥有良好的记录。
加亚斯里·伦加拉詹是 PowerSchool 数据科学副总监,领导 PowerBuddy 计划。Gayathri 因将深厚的技术专业知识与战略业务需求联系起来而闻名,在提供从概念到生产的企业级生成式人工智能解决方案方面拥有良好的记录。
 哈西特·库马尔·尼亚提是 PowerSchool 的首席软件工程师,在软件工程和分析方面拥有 10 多年的经验。他专门使用 Amazon SageMaker AI、Amazon Bedrock 和其他云服务构建企业级生成式 AI 应用程序。他的专业知识包括微调 LLM、训练 ML 模型、在生产中托管它们以及设计 MLOps 管道以支持 AI 应用程序的整个生命周期。
哈西特·库马尔·尼亚提是 PowerSchool 的首席软件工程师,在软件工程和分析方面拥有 10 多年的经验。他专门使用 Amazon SageMaker AI、Amazon Bedrock 和其他云服务构建企业级生成式 AI 应用程序。他的专业知识包括微调 LLM、训练 ML 模型、在生产中托管它们以及设计 MLOps 管道以支持 AI 应用程序的整个生命周期。
 安贾利·维贾亚古玛是 AWS 的高级解决方案架构师,拥有超过 9 年帮助客户构建可靠且可扩展的云解决方案的经验。她居住在西雅图,专门从事教育科技解决方案的架构指导,与教育技术公司密切合作,通过云创新改变学习体验。工作之余,Anjali 喜欢通过徒步旅行探索太平洋西北地区。
安贾利·维贾亚古玛是 AWS 的高级解决方案架构师,拥有超过 9 年帮助客户构建可靠且可扩展的云解决方案的经验。她居住在西雅图,专门从事教育科技解决方案的架构指导,与教育技术公司密切合作,通过云创新改变学习体验。工作之余,Anjali 喜欢通过徒步旅行探索太平洋西北地区。
 德米特里·索尔达金是 Amazon Web Services (AWS) 的高级 AI/ML 解决方案架构师,帮助客户设计和构建 AI/ML 解决方案。Dmitry 的工作涵盖了广泛的 ML 用例,主要关注生成式 AI、深度学习以及在整个企业中扩展 ML。他为许多行业的公司提供过帮助,包括保险、金融服务、公用事业和电信。您可以在 LinkedIn 上与 Dmitry 联系。
德米特里·索尔达金是 Amazon Web Services (AWS) 的高级 AI/ML 解决方案架构师,帮助客户设计和构建 AI/ML 解决方案。Dmitry 的工作涵盖了广泛的 ML 用例,主要关注生成式 AI、深度学习以及在整个企业中扩展 ML。他为许多行业的公司提供过帮助,包括保险、金融服务、公用事业和电信。您可以在 LinkedIn 上与 Dmitry 联系。
 卡兰·杰恩是 AWS 的高级机器学习专家,负责领导 Amazon SageMaker Inference 的全球上市策略。他通过提供部署、成本优化和 GTM 策略方面的指导,帮助客户加快 AWS 上的生成式 AI 和 ML 之旅。他领导跨行业的产品、营销和业务开发工作已有 10 多年,热衷于将复杂的服务功能映射到客户解决方案。
卡兰·杰恩是 AWS 的高级机器学习专家,负责领导 Amazon SageMaker Inference 的全球上市策略。他通过提供部署、成本优化和 GTM 策略方面的指导,帮助客户加快 AWS 上的生成式 AI 和 ML 之旅。他领导跨行业的产品、营销和业务开发工作已有 10 多年,热衷于将复杂的服务功能映射到客户解决方案。