
机器学习方法克服了不平衡的临床数据,以进行鼻内无瓣监测
作者:Bai, Juho
介绍
自由皮瓣重建是一种常见程序,用于重建肿瘤切除或创伤引起的大缺陷1。在口腔和颌面区域,襟翼在功能和美学上都起着至关重要的作用。因此,皮瓣坏死会导致具有挑战性的医疗情况2,,,,3。为了防止这种情况,术后皮瓣监测是必不可少的,并且已经引入了各种基于设备的监控方法4,,,,5,,,,6。但是,这些监视方法仍然依赖于不断出现在患者床边的人员的多个观察结果,例如居民7,,,,8。此外,最终的数据(通常是定性图像)可能很难解释,并且可能无法为操作外科医生提供结论性的证据。
为了解决这些困难,人工智能(AI)模型已应用于大大区域的襟翼监测9,,,,10,,,,11,,,,12。但是,这些方法通常在解决临床环境中固有的类不平衡的同时努力实现稳健的性能,或者它们需要专门的成像设备。我们的研究利用从已经观察到的患者那里获得的照片,结合了来自各种解剖部位的图像并在不同的条件下,目的是开发一个模型,该模型可以在现实世界中广泛实现。
结果
患者特征
审查了131例患者的病历,包括临床照片。最常见的病例是使用前大腿前(ALT)无瓣重建八一个切除术缺陷。在131名患者中,有8例因血管损害而进行了打捞程序,并在2例患者中观察到导致总皮瓣损失的晚期失败。详细信息显示在表中 1。表1研究患者的临床特征。数据集详细信息
仅将训练集用于模型学习,而测试集则仅用于验证。
数据以8:2的比率分开,导致训练集中有1501个样本,测试集中有376个样本。
根据皮瓣中的血管妥协的存在或不存在,将图像分为两类。1类代表一组具有确认血管损害的图像,通过接受重复打捞程序或通过确认皮瓣坏死的患者进行了验证,这是通过全面的颜色变化和催化性的完全改变所证明的。所有其他保持正常且活跃的皮瓣均被归类为0类。在因发现的血管妥协而重新进入打捞程序的患者中,未收集第二个血管吻合期后拍摄的图像。
每个班级都会随机选择样品,以确保测试和训练集中的类似类别分布。此信息总结在表中 2。
临床应用
在376张图像中,有352张代表了健康的皮瓣,而没有任何血管折衷,部分襟翼损失。其余的24张图像描绘了经历了静脉充血,动脉不足的襟翼。该模型将352个普通皮瓣图像中的351个正确分类为0类,并确定了需要打捞程序的24个不健康的皮瓣图像中的20个。
模型性能
我们以前探索了四个不同的模型配置,如表 3,考虑班级加权的应用和损失功能的选择。所有配置都将视觉变压器(VIT)大型模型作为共同体系结构。在所有实验中,学习率设置为0.0001,其他超参数遵循视觉变压器的默认建议。
使用准确性,F1分数,精度,召回和特定于类的指标对模型进行评估。桌子 4总结每个模型的总体性能指标。
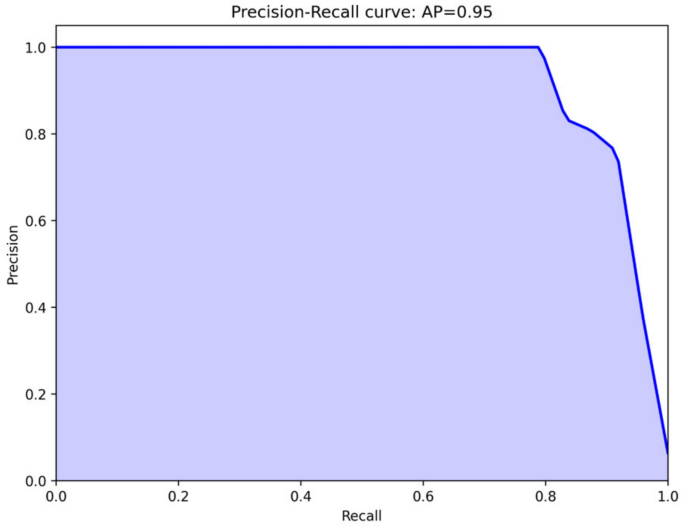
所有类别模型的总体准确性为0.9867,F1得分为0.9863,表明这四个模型之间的性能异常高。相应的精确记录曲线如图所示。 1。图1对于广泛的召回值,Precision-Recall曲线保持较高的精度(接近1.0),仅在非常高的召回水平下急剧下降。

班级加权和焦点损失的结合似乎有效地解决了类不平衡问题。
正如预期的那样,在大多数级别的0个样本上,4个模型中提出的模型表现出色。值得注意的是,对于少数类1样本,它还达到了0.95的精度,这表明与没有加权或使用简单跨侧面(CE)损失的模型相比,表现出色。所有模型的特定班级性能指标均在表中列出 5。表5所有模型的特定于类的性能对表。用于模型验证的患者级交叉验证
为了更严格地验证模型的临床适用性,我们还在患者水平上进行了5倍的交叉验证。
在这种方法中,将131名患者随机分为5组,以确保将同一患者的所有图像专门放置在训练或测试集中。
表格总结了患者级交叉验证的结果 6。加权局灶性损耗模型表现出卓越的性能,平均精度为0.9379±0.0173,精度为0.9421±0.0152。为了进行比较,没有体重模型的CE损耗的精度为0.9339±0.0197,而没有体重和加权CE损耗模型的焦点损失表现出较低的性能,精度分别为0.8956±0.0229和0.8634 - ±0.8634 - ±0.0748。
此外,我们提出的加权局灶性损失模型在所有配置中都达到了最高的F1得分(0.9080±0.0253),这证实了其在处理此临床数据集中存在的不平衡类分布方面的有效性。
讨论
人工智能彻底改变了医学成像,尤其是在诊断和细分方面。许多研究采用人工神经网络来识别疾病并预测各种领域的预后,包括神经外科和整形手术13,,,,14,,,,15,,,,16。随后,开发了卷积神经网络(CNN)模型,以识别异常区域,诊断状况和预测临床照片的结果17,,,,18。
Mantelakis等。从早期的非神经网络模型到当代CNN方法,对整容手术中的人工智能应用进行了全面综述。他们报告说,分析视觉图像进行病变评估和治疗计划的AI系统表现出很高的精度19。
自由皮瓣重建是肿瘤切除或创伤后功能和美学视角的关键治疗方式20。尽管此过程的成功率超过95%,但罕见的血管妥协实例会导致复杂的结果2,,,,3。通常可以通过频繁监测和迅速的打捞程序来避免这种并发症4,,,,5,,,,6。
当前的监测方法包括传统观察,多普勒系统,颜色双工超声检查和近红外光谱。尽管它们很受欢迎,但这些方法中的每一种都有关键的局限性:它们可能会产生毫无意义的信号,这对于缺乏经验的居民人员来解释或涉及过大型观察设备的挑战,这些设备无法频繁使用21,,,,22。此外,现有的监测方法均未提供可量化的襟翼更改的测量6。
针对这些局限性,Hsu等人。开发了一种监督的学习方法,以产生量化结果的量化结果12。但是,迄今为止,尚无此类尝试监视口腔内插入的免费襟翼。与观察位于外部部位的襟翼相比,位于口腔内的监测皮瓣提出了更大的挑战。尽管经常口服清洁程序,但皮瓣通常被与唾液混合的血液覆盖,使完全可视化变得困难。此外,口腔的复杂解剖结构可以使摄影文档本身具有挑战性23,,,,24。此外,上述某些监视设备在口腔内完全不适用。
我们的模型仅利用皮瓣的2D图像,消除了与将大探针插入口腔相关的不适。尽管口腔的洞穴状结构不可避免地会导致图像之间的显着照明变化,但通过模型中的随机调整克服了这一挑战。因此,图像捕获只需要智能手机闪光灯。
鉴于血管吻合的成功率超过95%,在我们的研究中,只有131名患者中只有10例接受了打捞程序或经历了总皮瓣损失。我们通过应用班级加权并在训练过程中纳入焦点损失来解决固有的数据集不平衡。班级加权和焦点损失的结合提出了一种解决机器学习模型中类不平衡的协同方法。班级加权通过分配更高的重要性来减轻少数族裔的代表性,而焦点损失则动态调整学习过程以专注于难以分类的样本。这种集成的方法增强了模型从代表性不足的类和具有挑战性的实例中学习判别特征的能力,从而提高了整体分类性能。这种方法在高度偏斜的数据集中特别有效,在此方法可以显着提高模型的概括能力并提高现实世界应用中遇到的关键少数群体的识别率。
尽管图像中存在复杂的结构,例如牙齿,嘴唇和舌头,通常被血液和唾液所掩盖,但我们的模型还是成功地识别了皮瓣并发现其生存能力的变化。即使这些结构偏离了由于手术干预和术后条件的正常外观,这种能力仍然存在。
与人类观察者相比,模型的量化变化的能力可以更敏感地检测改变。如图所示 2,用3小时的间隔捕获了两个输入图像(a:2 h后拯救过程,b:5 h,初始救助程序)。与第一个相比,第二张图片显示出充血边缘的略有增加,但差异足够微妙,以至于临床医生认为皮瓣相似并推迟了进一步的救助程序。然而,该模型表明发生了重大变化,估计第一个图像中襟翼中血管损害的概率为1.3%,在第二张图像中将近十倍至13%。随后,该患者在最初的患者15小时进行了第二次打捞程序。尽管采取了这些干预措施,但血管损害仍未解决,最终需要清除皮瓣。

输入来自一名58岁男性患者的图像,他们接受了口咽癌的格式切除术和咽切除术,并使用前外侧大腿皮瓣修复了缺陷。初次手术后患者表现出充血症状,促使静脉重新塑料11小时。左侧的图像显示了重新施加后2小时的模型分析,而右侧的图像表示重新构态后5小时的分析。
尽管模型的总体表现良好(F1分数= 0.9863),但第1类观察到的相对较低的召回率(0.83)仍需要改进。这表明该模型可能会以大约17%的概率将实际的血管妥协案件分类为正常的实际病例,这可能会导致实践中的重大临床风险。这些误差主要源于有限的数据集,只有几百个代表血管妥协的图像,以及用于确定血管妥协的置信水平阈值的次优构型。如前所述,当置信度低于50%时,当前模型不会直接打印1类。但是,它确实表明了通过提高置信度的潜在血管疾病。因此,在临床部署之前,似乎有必要根据怀疑血流障碍的图像来重新校准置信度水平阈值。在临床环境中,缺少受损的皮瓣(假阴性)可能导致不可逆转的组织损失,我们建议设定较低的标记潜在损害的阈值,接受较高的假阳性率作为提高患者安全的合理权衡。鉴于缺失血管妥协的严重后果,临床上可接受的召回应接近0.95或更高。
在376张图像的测试集中,该模型仅分类五个。一个健康的皮瓣错误地分类为坏死(假阴性),而四个具有血管折衷的皮瓣被错误分类为健康(假阳性)。假阴性病例涉及用无alt瓣修复的八一个缺陷,对侧舌头似乎是坏死的。该模型错误地将这种黑暗的舌头识别为由于图像中类似比例而引起的皮瓣。所有四个假阳性病例均表现出血管损害。在其中三种情况下,皮瓣仅占据图像的一小部分,大部分照片由正常组织组成,这可能导致模型的错误分类。其余的情况涉及在将前臂皮瓣移植到颊颊后12小时拍摄的图像。在此图像中,襟翼的颜色和边缘与健康皮瓣的颜色和边缘非常相似,这使该模型诊断为没有血管损害。然而,到第四天的术后,皮瓣显示出坏死的迹象,包括部分皮肤脱落。
该模型最初是出于诊断目的而开发的,该模型表现出了作为外科医生助手的襟翼敏感探测器的潜力。凭借分析在各种条件和照明下拍摄的图像的能力,它可以提供全天候的,与位置无关的结果,从而为术后外科医师提供支持的决策过程。
但是,人们普遍承认,AI应该扩大而不是更换外科医生的决策过程20。由于该模型量化了血管损害的可能性而不是决定治疗时机,因此临床判断对于确定启动救助程序的阈值仍然至关重要。
这项研究提出了一些潜在改进的领域。尽管该模型目前根据血管妥协的可能性提供了二进制分类,但未来的迭代可能会纳入专家注释,以为flap的明显状况提供更多细微的解释,从而为临床医生提供其他治疗决策的见解。此外,这项研究是在一个单个机构的单个机构进行的,该机构将患者队列限制为亚洲种族。为了扩大模型的适用性,需要对更多样化的皮肤肤色进行进一步的培训。
客观上,我们的模型在识别襟翼和评估其生存能力方面表现出了高性能。值得注意的是,这代表了为口内瓣监测开发的第一个深度学习模型。
方法
道德声明
这项回顾性研究被放弃了,要求伊森大学牙科医院的机构审查委员会(IRB),牙科学院的机构审查委员会(IRB)的所有受试者的知情同意,这项研究的实验方案得到了尤斯大学牙科医院IRB牙科学院的IRB批准(批准编号:2-2024- 0008)。所有方法均根据牙科学院Yonsei大学牙科医院的相关指南和法规进行。
研究人群
从2021年6月到2024年3月,有207例连续的患者接受了手术,以使用各种自由皮瓣重建术后缺陷。其中,只有131例患者提供了足够数量和适当的顺序临床照片质量,总共产生了1877张图像进行分析。遵循建立的方案,临床观察重点是皮瓣颜色,温度,毛细血管补充和毛茸茸。在怀疑动脉不足的情况下,进行了针刺测试。与先前的观察结果相比,打捞程序的适应症包括皮瓣颜色的明显变化,充血边缘扩大,销钉测试中缺乏血液流量或皮瓣毛茸茸的变化。
所有照片均由使用各种捕获设备(iPhone 13 Mini(Apple Inc.),iPhone 13 Pro(Apple Inc.),iPhone 15(Apple Inc.),Galaxy S21(Samsung Group)和Galaxy Z Flip4(Samsung Group)拍摄的居住人员立即进行皮瓣监控。在最初的48小时内,当成功打捞程序的可能性更高时,以2小时或3小时的间隔捕获图像6。手术后的第三天,每6小时观察一次皮瓣,从手术后的第四天开始,每天拍摄一张照片。这些照片按案例,日期和捕获时间分类。
数据准备
由于用来拍摄照片的各种设备,实施了标准化的预处理管道:调整大小,随机水平翻转,随机旋转,颜色抖动和归一化。这些过程有助于克服颜色音调的局限性,这些限制可能是将数据集限制为单个人群的,以及当襟翼位于更深层次的区域时,口腔的照明不一致的特征。下面提供了每种方法的详细说明。
-
1。
调整大小:所有图像均保持在224 − 224像素,同时保持纵横比25。
-
2。
随机水平翻转:图像以0.5的概率水平翻转,以引入反射不变性26。
-
3。
随机旋转:图像在±10度内以随机角度旋转,以增强旋转不变性27。
-
4。
颜色抖动:对亮度,对比度,饱和度和色调进行随机调整以提高对照明条件和颜色分布变化的模型弹性28。
-
5。
归一化:最近,Huang等人。在2023年的研究中指出,即使在捕获皮瓣的单个图像中,皮瓣组织和原始皮肤之间的RGB值也可能存在差异。因此,研究团队在预处理过程中进行了正常化的过程,利用来自Imagenet数据集的图像,这可以增强皮肤肤色的多样性,否则仅通过仅包括一个种族而受到限制29,,,,30。
模型开发
我们采用了AMD 7500F CPU和RTX 4090,带有24GB RAM进行培训。所使用的预训练模型是具有默认参数值的VIT_L_16模型。
为了解决我们准备好的数据集中的班级不平衡,我们实施了样本加权策略31。我们定义体重\(w_i \)使用样本总数(n),类(c)的数量以及I类样本数量的每个类别\(n_i \)如下32。
$$ \ begin {aligned} \ begin {aligned} w_i = n/(c*n_i)\\ \ end {aligned} \ end} \ end {aligned} $$
(1)
使用此,我们定义了调整的重量\(w'_1 \)对于少数族裔。在我们的实施中,\(\ beta = 2 \)。
$$ \ begin {Aligned} \ begin {Aligned} w'_1 = \ beta \ cdot w_1 \\\ end {aligned} \ end eend {aligned} $$
(2)
这种额外的提升强调了训练期间少数族类样本的重要性33。
为了进一步解决训练期间的不平衡,我们在损失函数水平上采用了焦点损失技术。使用平衡系数\(\ alpha _i \)上课我和聚焦参数\(\ gamma \),我们将焦点损失(FL)定义为:
$$ \ begin {Aligned} \ begin {aligned} fl(y,\ hat {y})= - \ alpha _i(1- \ hat {y})^\ gamma y \ log(\ hat {\ hat {y})(1- \ hat {y})\\ \ end {对齐} \ end {aligned} $$
(3)
\(\ alpha _i \)是0.25和\(\ gamma \)在我们的实施中是234。
这种方法有助于减少简单示例(y接近Å·)的损失贡献,并增加纠正错误分类示例的重要性。整体培训结构在图中进行了简要说明。 3。

使用类加权和焦点损失来克服阶级失衡的模型的示意图。MLP =多层感知器。
临床应用
用于测试的376张图像输入了模型,该模型输出了代表血管损害概率的置信度(图。 4)。当此概率低于0.5时,图像被归类为1类(可能存在血管妥协)。

((一个)模型接口。当将术后图像提交到模型中时,它会识别图像中结构之间的瓣,并输出血管折衷的概率。((b)一张64岁女性患者的术后3小时照片,该患者在左下牙龈中切除了鳞状细胞癌,上面覆盖有前大腿前外侧的瓣。考虑到皮瓣的颜色和毛茸茸,它看起来非常健康,并且该模型的血管折衷概率小于1%。迄今为止,此皮瓣一直保持健康。((c)一张43岁男性患者的48小时术后照片,他在左下颌骨中切除了蛋白母细胞瘤,并使用日期in-a-a-a-nay Technique重建。尽管前缘显得略有黑,但瓣的整体外观被认为是健康的,并且该模型计算出低血管损害的可能性。迄今为止,此皮瓣也一直保持健康。
基于VIT-LARGE模型配置,可以在使用少于8 GB的GPU内存的硬件上执行我们提出的方法的推理过程,该方法利用了视觉变压器(VIT)体系结构。量化后,提出的方法可以在移动环境中有效使用,例如配备神经处理单元(NPU)的智能手机。该优化使我们的方法作为智能手机应用程序实现,从而促进了设备推理功能。
数据可用性
当前研究期间和/或分析期间生成的数据集可从相应的作者根据合理的要求获得。
参考
Wong,C.-H。&Wei,F.-C。头颈部重建中的显微外科瓣。头脖子 32,1236年1245年(2010年)。
文章一个 PubMed一个 Google Scholar一个
Lutz,B。S.&Wei,F.-C。头部和颈部重建中的显微外科手术襟翼。临床塑料。外科。 32,421â430(2005)。
文章一个 PubMed一个 Google Scholar一个
Pohlenz,P。等。头部和颈部手术中的微血管无菌襟翼:1000瓣的并发症和结局。int。J.口服Maxillofac。外科。 41,739 - 743(2012)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Kohlert,S.,Quimby,A.A.在整形外科研讨会,第33卷,013年(Thieme Medical Publishers,2019年)。
Chae,M。P.等。术后监测微血管无血管襟翼的当前证据:系统评价。安。塑料。外科。 74,621 - 632(2015)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Shen,A。Y.等。免费的皮瓣监控,打捞和故障时机:系统审查。J. Reconstr。Microsurg。 37,300 308(2021)。
文章一个 PubMed一个 Google Scholar一个
杰克逊(R. S.),沃克(R. J.耳鼻喉科。头颈外侧。 141,621 - 625(2009)。
文章一个 PubMed一个 Google Scholar一个
Patel,U。A。等。在受限制的居民工作时间的时代,自由皮瓣重建监测技术和频率。JAMA耳鼻喉科。头颈外侧。 143,803(2017)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Kiranantawat,K。等。第一个用于显微外科监测的智能手机应用程序:silparamanitor。塑料。重新构成。外科。 134,130 A39(2014)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Jarvis,T.,Thornburg,D.,Rebecca,A。M.和Teven,C。M.整形外科中的人工智能:当前的应用,未来方向和道德意义。塑料。重新构成。外科。地球。打开 8,E3200(2020)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Pettit,R。W.,Fullem,R.,Cheng,C。和Amos,C。I.人工智能,机器学习和深度学习临床结果预测。出现。顶部。生命科学。 5,729 - 745(2021)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
HSU,S.-Y。等。通过深度学习智能手机的深度学习iOS应用程序的静脉充血量量化静脉充血的量化:诊断研究。int。J. Surg。 109,1584年1593年(2023年)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Yeong,E.-K.,Hsiao,T.-C.,Chiang,H。K.&Lin,C.-W。使用人工神经网络和反射率光谱仪预测燃烧时间。烧伤 31,415â420(2005)。
文章一个 PubMed一个 Google Scholar一个
Shi,H.-Y.,Hwang,S.-L.,Lee,K.-T。&Lin,C.-L。创伤性脑损伤手术后的院内死亡率:在人工神经网络和逻辑回归模型中使用的全国人群死亡率预测因素的比较。J. Neurosurg。 118,746 - 752(2013)。
文章一个 PubMed一个 Google Scholar一个
Azimi,P。&Mohammadi,H。R.预测儿童脑积水中的内窥镜第三个心室造口术成功:人工神经网络分析。J. Neurosurg。小儿科 13,426 - 432(2014)。
文章一个 PubMed一个 Google Scholar一个
Azimi,P.,Benzel,E。C.,Shahzadi,S.,Azhari,S。&Mohammadi,H。R.使用人工神经网络预测腰椎脊柱狭窄患者的手术满意度。J. Neurosurg。脊柱 20,300 A305(2014)。
文章一个 PubMed一个 Google Scholar一个
Hallac,R。R.,Lee,J.,Pressler,M.,Seaward,J.R。&Kane,A。A.使用卷积神经网络从2D照片中识别耳朵异常。科学。代表。 9,18198(2019)。
文章一个 广告一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Ohura,N。等。卷积神经网络用于伤口检测:人工智能在伤口护理中的作用。J.伤口护理 28,S13âS24(2019)。
文章一个 PubMed一个 Google Scholar一个
曼特拉基斯(A.塑料。重新构成。外科。地球。打开 9,E3638(2021)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
美国食品和药物管理局。软件中的人工智能和机器学习作为医疗设备。https://www.fda.gov/medical-devices/software-medical-device-samd/arterncover-intelligence-and-machine-machine-learning-software-software-medical-device(2020)。访问:2025-02-19。
Wong,C.-H.,Wei,F.-C.,Fu,B.,Chen,Y.-A。&Lin,J.-Y.前外侧大腿瓣的替代血管椎弓根:外侧环绕股动脉的倾斜分支。塑料。重新构成。外科。 123,571 - 577(2009)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Smit,J。M.,Zeebregts,C.J.,Acosta,R。&Werker,P。M.在过去十年中自由皮瓣监测的进步:一项关键审查。塑料。重新构成。外科。 125,177 - 185(2010)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Lovätãnskã,V.,Sukop,A.,Klein,L。&Brandejsova,A。自由膜监控:审查和临床方法。Acta Chir。塑料。 61,16 23(2020)。
PubMed一个 Google Scholar一个
Felicio-Briegel,A。等。高光谱成像,用于监测口腔自由襟翼:一项可行性研究。激光外科手术。医学 56,165â174(2024)。
文章一个 PubMed一个 Google Scholar一个
Krizhevsky,A.,Sutskever,I。&Hinton,G.— E. Imagenet分类,具有深卷积神经网络。ADV。神经信息。过程。系统。25(2012年)。
Simonyan,K。&Zisserman,A。大型图像识别的非常深的卷积网络。ARXIV预印本 ARXIV:1409.1556(2014)。
Cubuk,E。D.,Zoph,B.,Mane,D.,Vasudevan,V。&Le,Q.Autoaughment:从数据中学习增强策略。在IEEE/CVF计算机视觉和模式识别会议论文集,113 - 123(2019)。
伯格格伦(A.塑料。重新构成。外科。 69,290 298(1982)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Ioffe,S。批量归一化:通过减少内部协变量转移来加速深层网络训练。ARXIV预印本 ARXIV:1502.03167(2015)。
黄,R.-W。等。Reliability of postoperative free flap monitoring with a novel prediction model based on supervised machine learning.塑料。重新构成。外科。 152, 943e–952e (2023).
文章一个 CAS一个 PubMed一个 Google Scholar一个
Cui, Y., Jia, M., Lin, T.-Y., Song, Y. & Belongie, S. Class-balanced loss based on effective number of samples.在Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9268–9277 (2019).
Shen, L., Lin, Z. & Huang, Q. Relay backpropagation for effective learning of deep convolutional neural networks.在Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part VII 14, 467–482 (Springer, 2016).
Zhou, Z.-H.& Liu, X.-Y.Training cost-sensitive neural networks with methods addressing the class imbalance problem.IEEE Trans。知识。Data Eng. 18, 63–77 (2005).
文章一个 Google Scholar一个
Ross, T.-Y.& Dollár, G. Focal loss for dense object detection.在Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2980–2988 (2017).
致谢
Financial support and sponsorship: This work was supported by Hankuk University of Foreign Studies Research Fund of 2025.
道德声明
竞争利益
作者没有宣称没有竞争利益。
附加信息
Publisher’s note
关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
权利和权限
开放访问This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material.您没有根据本许可证的许可来共享本文或部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。Reprints and permissions
引用本文

Kim, H., Kim, D. & Bai, J. Machine learning approaches overcome imbalanced clinical data for intraoral free flap monitoring.
Sci代表15 , 34849 (2025).https://doi.org/10.1038/s41598-025-15300-5
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41598-025-15300-5