
如何扩展强化学习
作者:Nathan Lambert
在我到达岗位之前,先做两件快速的家务事。
1. 本周我将在旧金山参加 PyTorch 会议(22 日至 23 日)、AI 基础设施峰会(21 日)和其他当地活动。过来打个招呼。
2. 我推出了一个新的 Substack AI 捆绑包,其中包含 8 份我最喜欢的出版物,为 20 人以上的团队打包在一起。了解更多信息,请访问读帆网。上帖子啦!
“扩展强化学习 (RL)”是捕捉改进前沿模型下一步的时代精神方式,每个人都盯着他们计划攀登的同一座山。
这些不同的团体如何解决这个问题一直是一个秘密。这是一个简单的想法,但很难复制:预测学习曲线的轨迹。这对于学术界来说难以复制有两个原因,这将在不同的时间尺度上得到解决:
缺乏稳定的强化学习训练设置。有许多 RL 库正在并行开发,社区共同让它们为夏季的大型 RL 运行做好了更多准备。
缺乏实验计算能力。
这些并不是新故事。在许多方面,它们反映了开放专家混合(MoE)模型的进展,但它们仍然远远落后于顶级人工智能实验室内代码库的实现,因为它涉及在昂贵的实验制度中克服大量的工程难题。强化强化学习的扩展也以同样的方式发展,但事实证明它更容易实现。
上周我们收到了第一篇关于扩展强化学习的权威论文。它提出了一种清晰的方法来推断计算规模上的 RL 学习曲线,并为获得顶级性能所需的计算顺序设置基线。纸,法学硕士扩展强化学习计算的艺术(Khatri & Madaan 等人,2025 年),称为 ScaleRL,对于任何想要了解 RL 算法和基础设施绝对前沿的人来说都是必读之作。
对于某些个人背景而言,在 2025 年全年,我们在 Ai2 的推理空间中拥有名为“scaling-rl”的主要松弛通道,因为我们知道该领域第一个明确的工作将非常重要。这篇文章涵盖了关键细节以及我接下来看到的内容。
尽管所有较低级别的 RL 数学也让您感到困惑,但您需要了解两件关键的事情。首先是这些直观的工作方式以及它们实际预测的内容。其次是它们与我们所知道和喜爱的预训练缩放法则的比较。
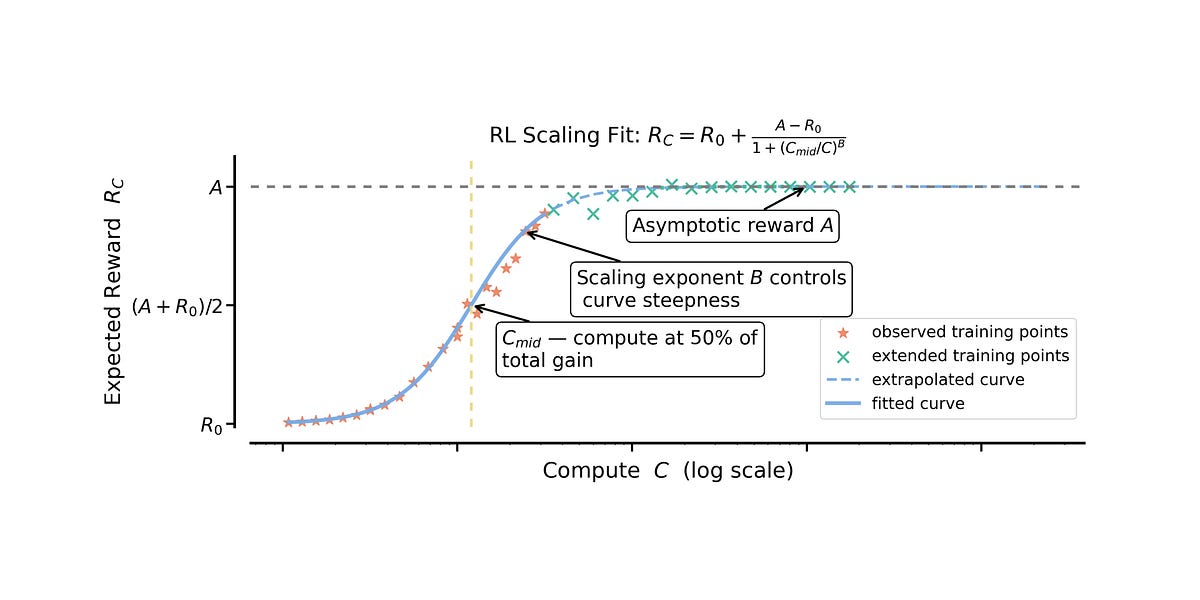
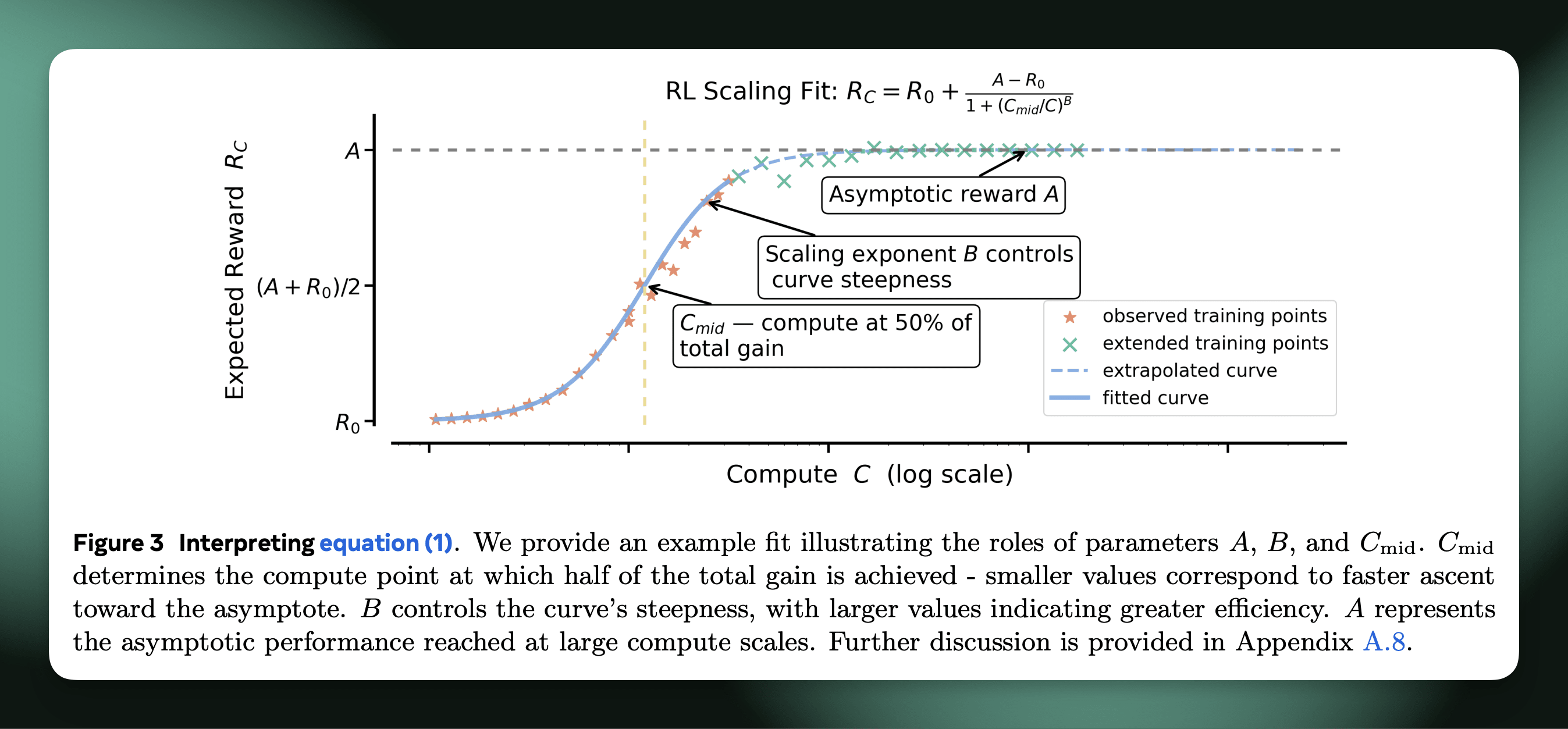
对于第一点,该方法需要采取一个(或几个)关键基础模型,对每个模型运行一些强化学习,通过在多次稳定运行中进行一些形状预测来预测终点,然后,对于您的大型运行,您可以根据最终性能来预测终点。RL 运行的形状激发了这一点,您会看到您的模型通常在前几步中获得约 80% 的准确度增益,并且您想知道如果您在整个数据集上进行训练,模型的最终性能会如何。
作者定义了三个适合的常量,A 用于衡量训练数据集子集(也称为验证集)的峰值性能 – 准确度,B 用于 sigmoid 曲线的斜率,C 用于 x 轴上的计算。然后你要做的就是进行一组 RL 训练作业,并拟合一个回归,根据随时间变化的早期准确度测量结果来预测最后一块真实训练点。然后,您可以通过了解 RL 学习曲线的正常形状来比较该起始模型上未来 RL 消融的预测最终性能。
其次是考虑如何将其与预训练缩放法则进行比较。这些与将下游测试损失与预训练计算相关联的深刻见解的幂律相去甚远——强化学习训练数据集的准确性是比下一个令牌预测更有限制的衡量标准。相对于指出模型本质的基本原理,强化学习缩放定律对于消除设计选择最有用。在很多方面,预训练的缩放法则一开始也可以这样看待,所以我们将从这里看到强化学习如何演变。
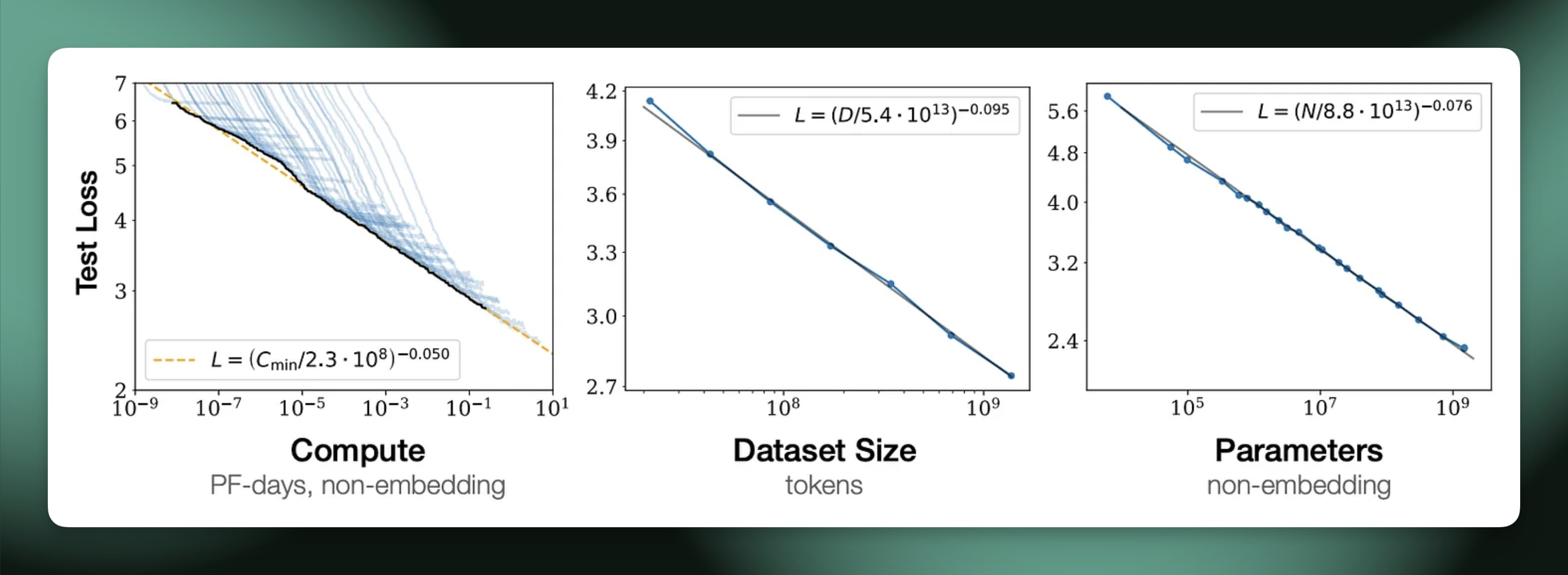
由于这种差异,强化学习的缩放法则在训练领先模型时将发挥与我们今天的预训练缩放法则截然不同的作用。预训练法则是为您的大型预训练运行选择准确的配置(您根本无法真正运行有意义的块来调试),而强化学习更多的是关于消除您将让其运行更长时间的算法。
在预训练中,许多决定取决于您的预算,而缩放法则可以给出答案。您的训练计算、通信瓶颈、最大运行时间、数据可用性等都定义了特定的模型窗口。强化学习的缩放定律可能很快就会告诉我们这一点,但目前最好将缩放定律视为从给定基础模型中提取最大性能的一种方法。
出于所有这些原因,正如作者所说,缩放 RL 更像是一门艺术,因为它是为了找到当运行额外数量级(或两个)样本时将获得性能最后几个百分点的运行。这是一种推断 RL 曲线的细粒度方法,该曲线具有快速上升然后缓慢饱和的标准形状。在实践中,作者在 1/4 的训练计算中拟合曲线,以预测剩余 3/4 GPU 时间后的结果。未来缩放法则的限制可能会进一步扩大(对于用于建立预训练缩放法则的计算百分比与最终运行中部署的计算百分比,我没有一个很好的启发式方法,如果有的话请发表评论!)。
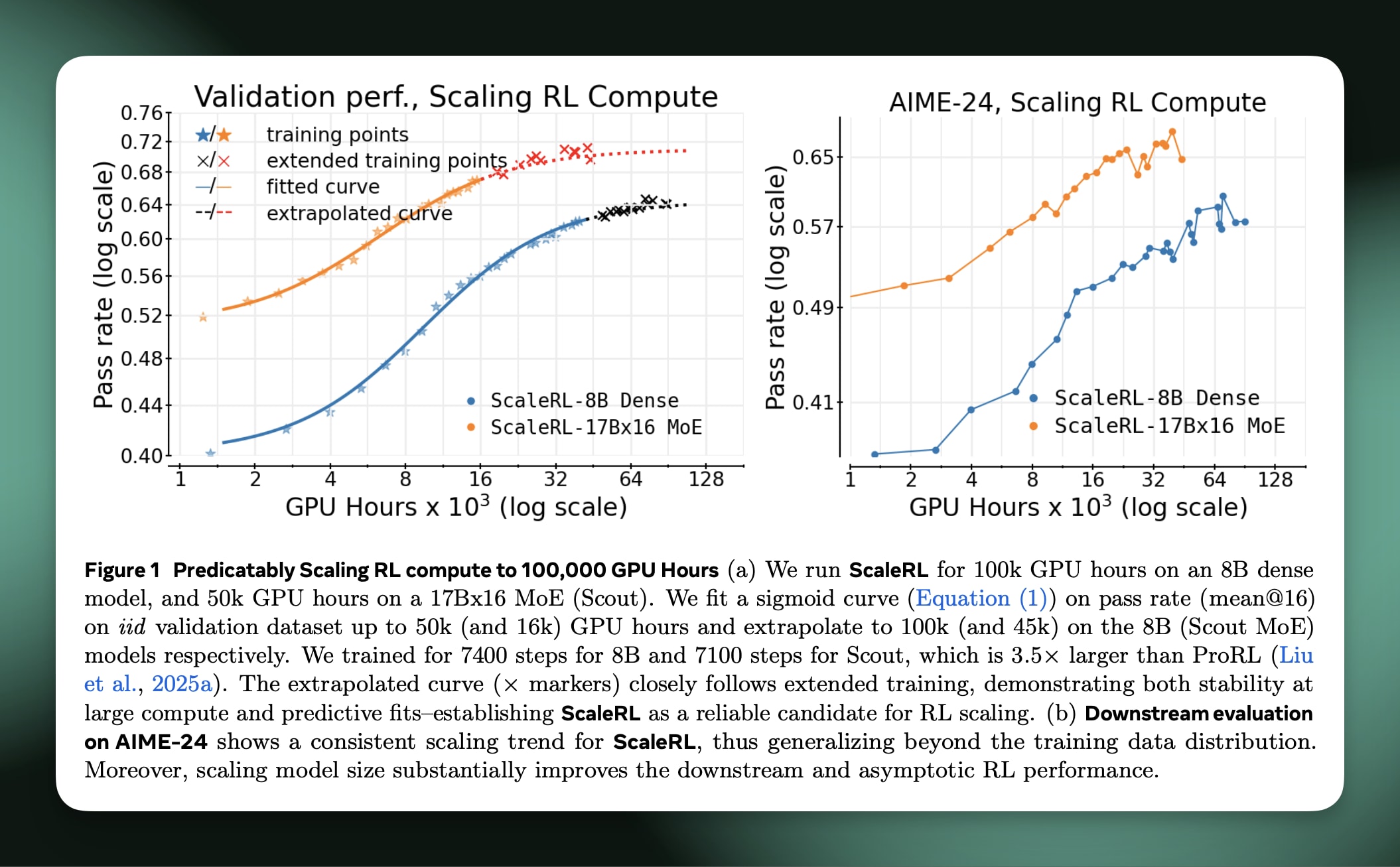
从这里开始,论文很快就进入了技术层面,作为对过去 6 个月主导 RL 研究生态系统的主要想法的检查。在扩大 RL 训练方面,本文对那些重要或不重要的因素表示祝福。这符合过去几年语言建模中反复出现的趋势:大多数关键想法都已经存在,但开放实验室往往没有资源将它们以正确的配置组合在一起。这种缓慢的知识积累需要组织强度、清晰度和能力,这是小型研究小组难以匹敌的。
在我看来,有一些关键想法值得了解并押注于本文:
算法进步:这篇论文非常支持一些最新的算法或进步,可以说将它们描绘成必不可少的。这些包括截断重要性抽样(TIS),组序列策略优化 (GSPO),以及通过以下方法剪裁 IS 权重策略优化 (CISPO)MiniMax M1 纸。稍后将详细介绍这些内容。
系统改进:作者重点介绍了 PipeLine RL(纸或者存储库)作为结合动态更新(即在很长的一代内改变模型权重)和连续批处理(即随着时间的推移填充 RL 批次,直到您有足够的学习步骤提示)组合的规范参考,这意味着在吞吐量方面比 LLM 上的标准 RL 实现提高了 4 倍以上。下面是来自 ServiceNow 论文的闲置 GPU 的情况。
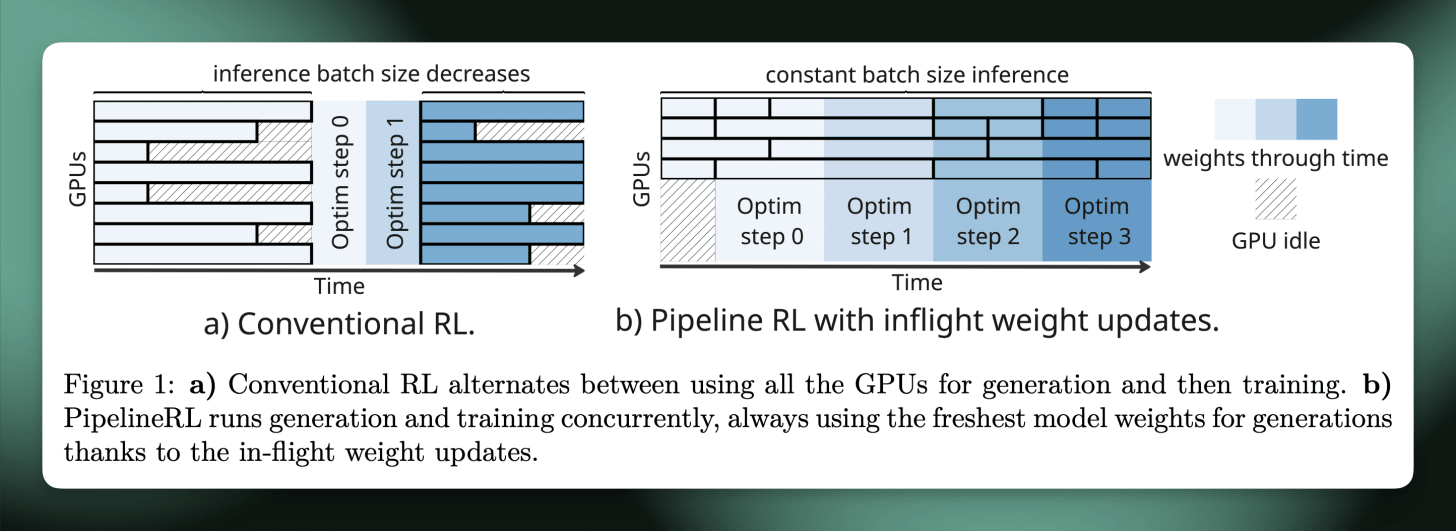
直观地想一下,如果您同时向法学硕士提出 8 个不同的问题会发生什么。其中有些会提前完成,有些则需要很长时间。如果您分配 GPU,使其必须完成全部 8 个问题,然后才能进入下一组问题,那么当您等待最后一个答案时,不可避免地会有 GPU 空闲。
相反,当 GPU 有周期进行更多处理时,连续批处理会不断引入新问题。不过,这在 RL 设置中更为复杂,因为每 8 个(或您的批量大小)问题之后,您需要更新您的 RL 权重。你还能这样做并一直向 GPU 填写新问题吗?那一个永远需要解决的问题会怎样呢?
动态更新是解决这个问题的方法。实际上发生的是模型在一代中期更新。模型和强化学习系统可以无缝地处理这个问题,并且在将推理权重与强化学习算法的新更新相匹配时消除了大量的空闲时间。
如果没有像这样的一些关键细节,大型强化学习的运行不仅会在 GPU 上变得更加昂贵,而且更重要的是在时间上会更加昂贵。1 天的反馈周期与 4 天的反馈周期形成了截然不同的研究设置。我们有这两个功能开放指导,我们在 Ai2 的训练后存储库,就像许多其他 RL 库一样。
其中很大一部分是修复数字,这对于专家混合 (MoE) 模型来说要困难得多,而且大多数开放的强化学习研究都没有触及这一点。这种对数值稳定性的追求是一个常见的谣言,解释了为什么 Thinking Machines 推出了确定性 VLLM 博客文章在释放他们之前修补程序API– 确定性 VLLM 可能是他们的前向传播。
回到算法。
罗斯·泰勒总结社区在 2025 年经历了 RL 算法的各个时代。首先是从普通 GRPO 到 DAPO 之类的过渡(请参阅我之前关于GRPO技巧或我的Youtube 视频他们也注意到了),它注意到了 GRPO 优势计算中的裁剪公式和偏差问题。下一类算法是 ScaleRL 论文中引用的算法、CISPO 和一般类截断重要性采样1(TIS) 方法,专为序列级优化(通常更接近普通策略梯度)而设计,它考虑了参与者(为 RL 生成补全的 GPU,通常像 VLLM 等快速的东西)和学习者(在不同库中执行梯度更新的 GPU)之间的概率增量。
这个重要性采样项似乎对于正确使用现代强化学习基础设施至关重要,因为如果没有它,扩展到更复杂的系统就很难获得数值稳定性。人工智能社区中有很多关于“重要性抽样”的讨论。实际上,所发生的情况是,优势或奖励通过重要性采样对数比重新加权,该重要性采样对数比对应于两组模型实现(例如 VLLM 与 Transformers)的概率差异。
在所有细节中,论文很好地总结了事态——大规模 yolo RL 运行得很好:
虽然法学硕士的强化学习计算已经大规模扩展,但我们对如何扩展强化学习的理解并没有跟上步伐;该方法论更多的是艺术而不是科学。强化学习领域最近的突破很大程度上是由对新颖算法的独立研究(例如 Yu 等人(DAPO,2025))和特定于模型的训练报告(例如 MiniMax 等人)推动的。(2025)和 Magistral(Rastogi 等人,2025)。重要的是,这些研究提供了针对特定环境的临时解决方案,但没有提供如何开发可随计算扩展的强化学习方法。缺乏扩展方法会扼杀研究进展:由于没有可靠的方法来先验地识别有前途的 RL 候选者,进展与大规模实验联系在一起,而大多数学术界都被边缘化了。
未来重要的是,因为在强化学习时代之后的法学硕士未来时代,这种情况将再次发生,这就是我们在这里的原因。发生这种情况是因为部署强化学习的潜力巨大,需要很长时间才能建立明确的科学最佳实践(即使大多数最优秀的研究人员都公开发表论文,但今天的情况并非如此)。领先的人工智能实验室可以迅速建立相当大的差距,但信息往往会流出并被复制。重要的是,公共选择不断实现——我认为他们会的。
这篇论文是朝着扩展 RL 科学方向迈出的第一步,但仍有许多问题没有得到解答:
没有关于不同数据影响的信息。北极星53K论文中使用的是开放数学 RL 数据集的可靠选项,但我们发现大多数这样的 RL 数据都可以通过 8B 模型上的一组简单的 SFT 推理轨迹来解决。随着人们将强化学习实验扩展到更强大的基础模型,更难的数据可能很快就会成为开放方法的限制。一篇在不同数据体系上重现这些扩展趋势的论文至关重要。
没有有关选择正确基本型号的信息。人们普遍认为,较大的基础模型在 RL 方面表现更好,作者在论文中承认这一点:“较大的 17B×16 MoE 表现出比 8B 密集模型更高的渐近 RL 性能,仅使用 1/6 的 RL 训练计算就优于 8B 的性能。”因此,我们需要进行扩展 RL 研究,以显示下游的最佳基础模型RL,就总体计算预算而言。
作者明确承认这些局限性。他们并不是想隐藏它!2
为了总结这一点,让我们回顾一下,有一个大骚动几周前,在人工智能圈子里,一些前沿实验室的员工表示,GRPO 远远落后于前沿实验室的 RL 堆栈。对我来说更准确的是香草GRPO 远远落后,找出适用于您的模型和数据的一组单独技巧的过程是一个严格保密的秘密。这篇新的 ScaleRL 论文是向人们展示如何弥合这一差距的重要一步。从这里开始,我们必须公开构建工具。