

Meta的生成广告模型(GEM):加速广告推荐AI创新的中枢大脑
- 我们正在分享有关 Meta 生成广告推荐模型 (GEM) 的详细信息,这是一种新的基础模型,可通过增强其他广告推荐模型提供相关广告的能力来提高广告效果和广告商投资回报率。
- GEM 的新颖架构使其能够随着参数数量的增加而扩展,同时持续有效地生成更精确的预测。
- GEM 传播其知识,在整个广告模型组中利用一套训练后技术,从而实现 Meta 广告推荐系统的范式转变。
- GEM 利用增强的训练可扩展性,有效利用数千个 GPU 来构建和迭代 LLM 规模的广告基础模型。
- GEM 已经推动 Instagram 和 Facebook 上的广告转化率显着增加。
Meta 一直处于在我们的产品和服务中利用人工智能来为广告商创造商业价值的前沿。利用先进技术为人们提供个性化广告并最大限度地提高每次广告印象的效果是我们开发广告推荐系统的一个组成部分。
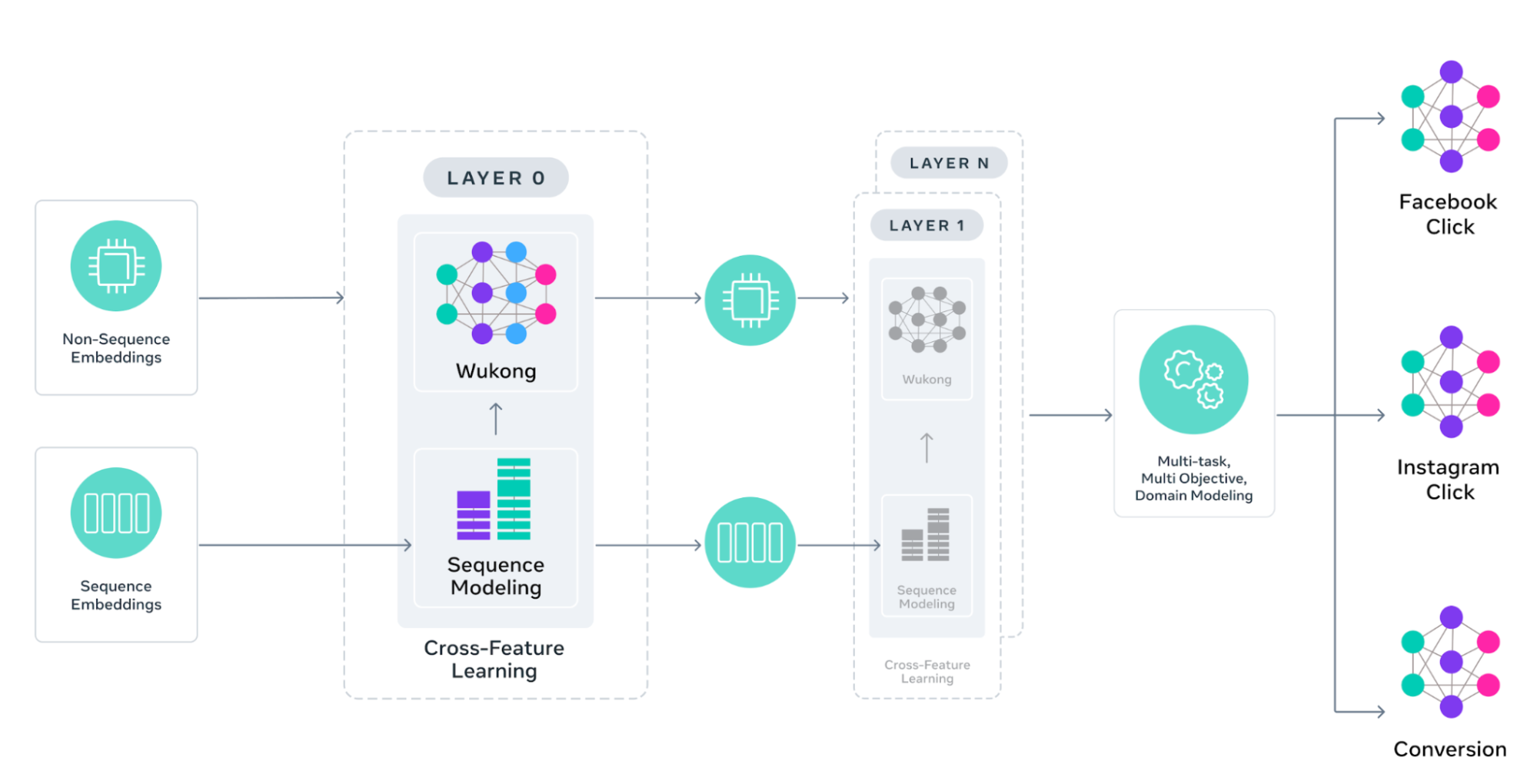
的生成广告推荐模型 (GEM)是 Meta 最先进的广告基础模型,建立在法学硕士启发的范例之上,并在数千个 GPU 上进行训练。它是业内最大的推荐系统 (RecSys) 基础模型,在大型语言模型的规模上进行训练。GEM 引入了架构创新,可解锁有效的扩展法则,通过数据和计算实现经济高效扩展的性能提升。多维并行性、自定义 GPU 内核和内存优化等训练突破使得大规模训练 GEM 成为可能。培训后,GEM 应用先进的知识转移技术来增强整个广告堆栈中下游模型的性能,从而提供更相关和个性化的广告体验人们的喜好。自推出创业板以来今年早些时候第二季度,GEM 在 Facebook 和 Instagram 上的推出使 Instagram 上的广告转化率增加了 5%,Facebook Feed 上的广告转化率增加了 3%。
在第三季度,我们对 GEM 的模型架构进行了改进,使我们通过添加给定量的数据和计算获得的性能优势翻了一番。这将使我们能够继续扩大 GEM 上使用的培训容量,并获得有吸引力的投资回报率。我
介绍创业板GEM 通过三项关键创新代表了 RecSys 的重大进步:采用先进架构的模型扩展、用于知识转移的训练后技术以及支持可扩展性的增强培训基础设施。
这些创新有效提高了广告效果,实现了整个广告模型群的有效知识共享,并优化了数千个 GPU 的训练使用。GEM 推动了广告 RecSys 的范式转变,通过用户和广告客户目标的联合优化,改变了整个渠道(认知度、参与度和转化)的广告绩效。
为 Meta 广告 RecSys 构建大型基础模型需要解决几个关键挑战:
- 处理所有 Meta 应用程序中的大型动态功能空间:每天,我们的平台上都会发生数十亿次用户与广告互动,但有意义的信号(例如点击和转化)却非常稀少。GEM 必须从这些庞大但不平衡的数据中学习,识别有意义的模式并概括不同的用户和行为。
- 处理各种数据:GEM 必须从各种广告数据中学习,包括广告商目标、创意格式、衡量信号以及跨多个投放渠道的用户行为。这种异构性显着增加了建模的复杂性,要求 GEM 统一多模式、多源输入并捕获细微的交互,为其他广告推荐模型提供支持。
- 高效培训:训练和扩展大型基础模型需要数千个 GPU,并利用先进的并行性和系统级优化来确保高效的硬件利用率。
GEM 通过以下方式克服了这些挑战:
- 现在的可扩展模型架构推动广告效果提升的效率提高了 4 倍对于给定数量的数据和计算,比我们原始的广告推荐排名模型要好。
- 一个新的框架提高知识转移效率,实现 2 倍的效率的 标准知识蒸馏。
- 一个新的训练堆栈,可提供有效训练 FLOPS 提高 23 倍,模型 FLOPS 利用率 (MFU) 提高 1.43 倍使用GPU 数量增加 16 倍. . .
构建和扩展 GEM 的架构
GEM 接受了来自广告和有机互动的广告内容和用户参与数据的培训。从这些数据中,我们得出特征,并将其分为两组:序列特征(例如活动历史记录)和非序列特征(例如用户和广告属性,例如年龄、位置、广告格式和创意表示)。定制的注意力机制独立地应用于每个组,同时还支持跨特征学习。这种设计提高了准确性,并扩展了每个注意力块的深度和广度,使我们上一代模型的效率提高了 4 倍。

非序列特征交互建模
了解用户属性如何与广告特征交互对于准确的推荐至关重要。创业板增强了悟空建筑使用具有跨层注意力连接的可堆叠分解机,使模型能够了解哪些特征组合最重要。每个 Wukong 块都可以垂直扩展(为了更深入的交互)和水平扩展(为了更广泛的功能覆盖),从而能够发现日益复杂的用户广告模式。
离线序列特征建模
用户行为序列 - 跨越广告/内容点击、查看和交互的长序列 - 包含有关偏好和意图的丰富信号,然而传统架构很难有效地处理如此长的序列。GEM 通过金字塔并行结构克服了这一挑战,将多个并行交互模块堆叠在金字塔结构中,以大规模捕获复杂的用户与广告关系。新的可扩展离线功能基础架构以最低的存储成本处理多达数千个事件序列,因此 GEM 可以从更长期的用户有机和广告交互历史中学习。通过对这些扩展的用户行为序列进行建模,GEM 可以更有效地揭示模式和关系,从而更深入、更准确地了解用户的购买历程。
跨特征学习
现有方法将用户行为序列压缩为下游任务的紧凑向量,这有丢失关键参与信号的风险。GEM 采用不同的方法,保留完整的序列信息,同时实现高效的跨特征学习。我们的设计,国际前线,采用并行总结和交替的序列学习之间的交错结构(例如,定制变压器架构)和跨特征交互层。这允许逐步完善其序列理解,同时保持对完整用户旅程的访问。这种设计促进了高效的交互学习,同时保留了用户序列数据的结构完整性,使 GEM 能够扩展到更高的层数,而不会丢失关键的行为信号。
具有特定领域优化的多领域学习
传统的广告推荐系统很难在广泛的产品生态系统中平衡学习——要么孤立地处理表面(从而错过有价值的跨平台见解),要么一视同仁(忽略特定于平台的行为)。Facebook、Instagram 和 Business Messaging 等不同的元界面都有独特的用户行为和交互模式。GEM 通过从跨表面用户交互中学习来解决这个问题,同时确保预测仍然适合每个表面的独特特征。例如,这使得 GEM 能够利用 Instagram 视频广告参与度的洞察来改进 Facebook Feed 广告预测,同时还优化每个域针对其特定目标(例如点击或转化)的预测。
通过后期培训技术最大限度地提高传输效率
只有当 GEM 的知识能够有效地转移到数百个面向用户的垂直模型 (VM) 时,GEM 才会产生影响。为了将 GEM 基础模型 (FM) 的性能转化为面向用户的虚拟机的可衡量的收益,我们采用了直接知识转移策略和分层知识转移策略。
直接传输使 GEM 能够将知识传输到 GEM 接受训练的同一数据空间内的主要虚拟机。分层传输将 GEM 中的知识提炼为特定领域的 FM,然后由 FM 教授 VM,从而推动广告模型的广泛改进。这些方法共同使用了一套技术,包括知识蒸馏、表示学习和参数共享,以最大限度地提高整个广告模型空间的传输效率,从而实现2x的有效性标准知识蒸馏。
知识蒸馏
在 Meta 的广告系统中,VM 经常遭受由于 FM 训练和评估延迟以及 GEM 或 FM 预测与 VM 特定目标之间的领域不匹配而导致的陈旧监督。随着时间的推移,VM(学生)和 GEM(教师)之间的这些过时或不一致的信号可能会降低学生模型的准确性和适应性。
为了解决这个问题,我们使用学生适配器在训练期间,一个轻量级组件可以使用最新的地面实况数据来完善教师的输出。它学习一种转换,可以更好地将教师的预测与观察到的结果结合起来,确保学生模型在整个培训过程中获得更多最新的和领域相关的监督。
表征学习
表示学习是模型自动从原始数据中驱动有意义且紧凑的特征的过程,从而实现更有效的下游任务,例如广告点击预测。表示学习通过生成语义对齐的特征来补充知识蒸馏,这些特征支持从教师模型到学生模型的高效知识转移。通过这种方法,GEM 可以有效提高 FM 到 VM 的传输效率,而无需增加推理开销。
参数共享
参数共享是一种技术,其中多个模型或组件重用同一组参数,以减少冗余、提高效率并促进知识转移。
在我们的上下文中,参数共享允许 VM 有选择地合并来自 FM 的组件,从而实现高效的知识重用。这使得较小的、对延迟敏感的虚拟机可以利用 FM 的丰富表示和预先学习的模式,而不会产生全部计算成本。
GEM 是如何训练的
GEM 的运作规模通常只有现代法学硕士才能看到。培训 GEM 需要对我们的培训方案进行彻底改革。重新设计的培训堆栈提供了使用 16 倍以上的 GPU,有效训练 FLOP 增加 23 倍同时也提高了效率。MFU(衡量硬件效率的关键指标)增加了 1.43 倍,反映出 GPU 资源得到了更好的利用。这种提高吞吐量和效率的能力对于训练这种规模的基础模型非常重要。
为了支持海量模型大小和多模式工作负载,我们采用多维并行、自定义 GPU 内核和模型系统协同设计等策略。这些技术可实现近线性扩展,应用于数千个 GPU,从而提高计算吞吐量、内存使用率和整体硬件效率。
分布式训练
训练大型模型(例如 GEM)需要跨密集和稀疏组件精心策划并行策略。对于模型的密集部分,混合分片分布式并行 (HSDP) 等技术可优化内存使用并降低通信成本,从而实现在数千个 GPU 上高效分配密集参数。相比之下,稀疏组件(主要是用于用户和项目特征的大型嵌入表)采用二维的使用方法数据并行性和模型并行性,针对同步效率和内存局部性进行了优化。
GPU 吞吐量的系统级优化
除了并行性之外,我们还实施了一套技术来饱和 GPU 计算吞吐量并减少训练瓶颈:
- 定制的内部 GPU 内核,专为可变长度(锯齿状)用户序列和计算融合而设计,利用最新的 GPU 硬件功能和优化技术。
- PyTorch 2.0 中的图形级编译可自动执行关键优化,包括用于节省内存的激活检查点和用于提高执行效率的运算符融合。
- 内存压缩技术,例如用于激活的 FP8 量化和统一嵌入格式,以减少内存占用。
- 另外,我们开发了无需利用流式多处理器 (SM) 资源即可运行的 GPU 通信集合通过 NCCLX(NVIDIA NCCL 的 Meta 分支)消除通信和计算工作负载之间的争用,从而提高重叠和 GPU 利用率。
减少培训开销和工作启动时间
为了提高训练敏捷性并最大限度地减少 GPU 闲置,我们优化了有效训练时间 (ETT)——处理新数据所用的训练时间比例。我们通过优化训练器初始化、数据读取器设置、检查点和 PyTorch 2.0 编译时间等,将作业启动时间减少了 5 倍。值得注意的是,我们通过缓存策略将 PyTorch 2.0 编译时间减少了 7 倍。
在整个开发生命周期中最大限度地提高 GPU 效率
GPU 效率在模型生命周期的所有阶段都得到了优化——从早期实验到大规模训练和训练后。在探索阶段,我们使用轻量级模型变体加速迭代,与全尺寸模型相比,成本要低得多。这些变体支持一半以上的实验,从而以最小的资源开销实现更快的想法验证。在训练后阶段,模型运行前向传递来为下游模型生成知识,包括标签和嵌入。与大型语言模型不同,我们还进行持续的在线训练来刷新 FM。我们增强了训练和训练后知识生成之间以及基础模型和下游模型之间的流量共享,以减少计算需求。此外,GPU 效率优化已应用于所有阶段,以提高端到端系统吞吐量。
广告推荐基础模型的未来
广告推荐系统的未来将取决于对人们偏好和意图的更深入了解,使每次互动都感觉个性化。对于广告商来说,这可以转化为大规模的一对一联系,从而推动更强的参与度和成果。
展望未来,GEM 将学习 Meta 的整个生态系统,包括跨文本、图像、音频和视频等方式的有机内容和广告内容的用户交互。 GEM 的这些经验将扩展到涵盖 Facebook 和 Instagram 的所有主要界面。这种更强大的多模式基础有助于 GEM 捕捉点击、转化和长期价值背后的细微差别,为统一的参与模型铺平道路,该模型可以对有机内容和广告进行智能排名,从而为人们和广告商提供最大价值。
我们将继续扩大创业板规模并在更大的集群上进行训练通过改进其架构并改进最新人工智能硬件上的训练方法,使其能够以不同的方式从更多数据中高效学习,从而提供精确的预测。我们还将发展 GEM,通过推理时间扩展进行推理,以优化计算分配,为以意图为中心的用户旅程提供支持,并实现代理、洞察驱动的广告商自动化,从而提高 ROAS。
致谢
我们要感谢 Yasmine Badr、John Bocharov、Shuo Chang、Laming Chen、Wenlin Chen、Wentao Duan、Xiaorui Gan、Shuo Gu、Mengyue Hang、Yuxi Hu、Yuzhen Huang、Shali Jiang、Santanu Kolay、Zhijing Li、Boyang Liu、Rocky Liu、Xi Liu、Liang Luo、GP Musumeci、Sandeep Pandey、Richard Qiu、Jason Rudy、Vibha Sinha、Matt Steiner、Musharaf Sultan、Chonglin Sun、Viral Vimawala、Ernest Wang、Xiaozhen Xia、Jackie (Jiaqi) Xu、Fan Yang、Xin Zhang、Buyun 张、Zhengyu 张、Qinghai Zhou、Song Zhou、Zhehui Zhou、Rich Zhu 以及 Meta 广告推荐系统中最大基础模型的开发和生产背后的整个团队。