

扩展鲁福斯,一个由亚马逊生成式AI驱动的对话购物助手,配备超过8万颗AWS Inferentia和AWS Trainium芯片,以备战Prime会员日 | 亚马逊云科技
Amazon鲁福斯是一个由生成式人工智能驱动的购物助手体验它利用来自亚马逊和整个网络的相关信息生成答案,以帮助亚马逊客户做出更明智、更有见识的购物决定。借助Rufus,顾客可以与一个精通亚马逊商品选择的生成式AI专家一起购物,并结合来自全网的信息,帮助购物者做出更加明智的购买决策。
为了满足亚马逊大规模客户的需求,Rufus需要一个低成本、高性能且高度可用的基础设施来进行推理。该解决方案需要具备在全球范围内低延迟地为多亿参数的大规模语言模型(LLMs)提供服务的能力,以服务于其庞大的客户群体。低延迟确保用户与Rufus聊天时能够获得积极的体验,并能够在不到一秒钟的时间内开始收到回复。为了实现这一目标,Rufus团队正在使用多个AWS服务和AWS AI芯片。AWS Trainium和AWS Inferentia.
Inferentia和Trainium是亚马逊AWS专门为加速高性能且成本更低的深度学习工作负载而开发的芯片。使用这些芯片,Rufus在保持低延迟的同时,将其成本降低到了其他评估解决方案的四分之一。在这篇文章中,我们将探讨Rufus使用AWS芯片进行推理部署的情况以及这如何使得该公司能够支持一年中最具挑战性的事件——亚马逊Prime会员日。
解决方案概览
Rufus的核心是由一个在亚马逊产品目录和来自整个网络的信息上训练的LLM提供支持。部署LLM可能会具有挑战性,需要平衡模型大小、模型准确性以及推理性能等因素。较大的模型通常具有更好的知识和推理能力,但由于计算需求更高且延迟增加,其成本也相应更高。Rufus需要被部署并扩展以满足像亚马逊会员日这样的高峰期的巨大需求。在考虑这种规模时,包括它需要表现得如何、对环境的影响以及托管解决方案的成本等。为了应对这些挑战,Rufus结合使用了AWS的解决方案:Inferentia2和Trainium。亚马逊弹性容器服务(Amazon ECS),和应用负载均衡器(ALB)。此外,Rufus团队与NVIDIA合作,使用NVIDIA的Triton推理服务器为解决方案提供支持,提供了使用AWS芯片托管模型的能力。
Rufus推理系统是一种检索增强生成(RAG)系统,通过从亚马逊搜索结果中检索额外信息(如产品信息)来增强响应。这些结果基于客户查询,确保LLM生成可靠、高质量和精确的回复。
为了确保Rufus在Prime Day期间处于最佳位置,Rufus团队构建了一个使用多个AWS区域(由Inferentia2和Trainium提供支持)的异构推理系统。跨多个区域建立系统使Rufus能够在两个关键领域获益。首先,它提供了可以在需求高峰时段使用的额外容量;其次,它提高了系统的整体弹性。
鲁夫斯团队也能够使用Inf2和Trn1两种实例类型。因为Inf2和Trn1实例类型使用相同的AWS Neuron通过SDK,Rufus团队能够使用这两种实例来提供相同的Rufus模型。唯一需要调整的配置设置是张量并行度(Inf2为24,Trn1为32)。与Inf2相比,使用Trn1实例还额外带来了20%的延迟降低和吞吐量提升。
下图展示了解决方案架构。

为了支持跨多个区域的实时流量路由,Rufus构建了一个新型的流量调度器。亚马逊云WATCH支持了底层监控,帮助团队在不到15分钟内根据流量模式变化调整不同区域间的流量比例。通过使用这种编排方式,Rufus团队能够在需要时将请求导向其他区域,仅以轻微的延迟作为代价换取第一个令牌。由于Rufus的流式架构以及区域之间的高性能AWS网络,对于最终用户而言感知到的延迟非常小。
这些选择使Rufus能够在全球三个区域扩展超过80,000个Trainium和Inferentia芯片,平均每分钟处理300万个令牌,并且在Prime Day期间保持P99小于1秒的延迟以确保首次响应。此外,通过使用这些专用芯片,Rufus每瓦性能比其他评估解决方案提高了54%,这帮助Rufus团队达到了能源效率目标。
优化推理性能和主机利用率
在每个区域中,Rufus 推理系统使用了亚马逊 ECS(Elastic Container Service),该服务管理底层的由 Inferentia 和 Trainium 提供支持的实例。通过管理底层基础设施,Rufus 团队只需要带入他们的容器和配置,通过定义一个ECS任务在每个容器中,使用带有Python后端的NVIDIA Triton推理服务器运行vLLM和Neuron SDK。vLLM是一个内存高效的推理和服务引擎,旨在实现高吞吐量。Neuron SDK使得团队可以轻松采用AWS芯片,并支持许多不同的库和框架,如PyTorch Lightning。
Neuron SDK 提供了一个在 Trainium 和 Inferentia 硬件上运行的基于 transformer 的大型语言模型(LLM)推理解决方案,具有优化的性能以支持广泛的架构。为了减少延迟,Rufus 与 AWS Annapurna 团队合作开发了各种优化措施,例如 INT8(仅权重量化)、使用 vLLM 的连续批处理以及 Neuron 编译器和运行时中的资源、计算和内存带宽优化。这些优化目前已经在 Rufus 生产环境中部署,并且从 Neuron SDK 2.18 版本开始可供使用。
为了减少客户开始收到Rufus响应的总体等待时间,团队还开发了一种推理流式架构。由于LLM推理需要大量的计算和内存负载,完成一个客户查询的完整响应生成可能需要几秒钟的时间。采用流式架构后,Rufus可以在生成令牌后的第一时间返回这些令牌。这种优化使得客户能够在不到1秒的时间内开始接收响应。此外,多个服务通过gRPC连接协同工作,智能地实时聚合和增强流式响应以提供给客户。
如以下图所示,图片和链接嵌入在响应中,允许客户与Rufus互动并继续探索。

扩容
尽管我们必须保持低延迟以提供最佳的客户体验,但通过提高硬件资源利用率来扩展服务吞吐量也至关重要。高硬件利用率可以确保加速器不会闲置,并且不会无谓地增加成本。为了优化推理系统的吞吐量,团队改进了单主机吞吐量以及负载均衡效率。
LLM推理的负载均衡由于以下挑战而变得复杂。首先,单个主机只能处理有限数量的并发请求。其次,完成一个请求的端到端延迟可能会有所不同,根据LLM响应长度可能持续几秒钟。
为了应对挑战,团队通过考虑单个主机的吞吐量和使用负载均衡在多个主机上的吞吐量来优化吞吐量。
该团队使用了ALB的最不显眼请求(LOR)路由算法,与之前的基准测量相比,吞吐量提高了五倍。这使得每个主机都有足够的时间来处理在途请求并通过gRPC连接流回响应,而不会因同时接收到多个请求而超载。Rufus还与AWS和vLLM团队合作,通过将vLLM与Neuron SDK和NVIDIA Triton推理服务器集成来提高单主机并发性。
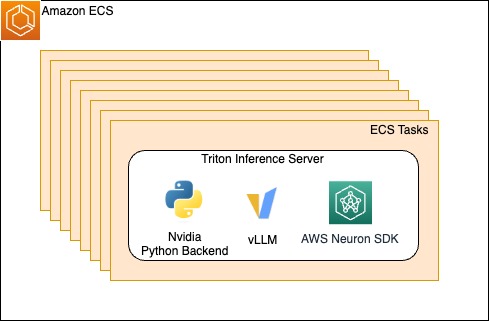
图1. ECS任务横向扩展以托管Triton推理服务器及其依赖项
通过此次集成,Rufus 能够受益于一项关键优化:连续批处理。连续批处理使单个主机能够大幅提高吞吐量。此外,与静态批处理等其他批处理技术相比,连续批处理提供了独特的功能。例如,在使用静态批处理时,第一个标记的响应时间(TTFT)会随着一批中的请求数量线性增加。连续批处理优先考虑大语言模型推理的预填充阶段,即使同时运行更多请求也能保持 TTFT 在可控范围内。这帮助 Rufus 提供了低延迟的第一响应体验,并提高了单主机吞吐量以控制服务成本。
结论
在这篇文章中,我们讨论了Rufus是如何利用Neuron SDK和Inferentia2以及Trainium芯片及AWS服务可靠地部署和运行其多亿参数的大语言模型(LLM)。随着生成式AI的进步和客户反馈,Rufus仍在不断进化和发展,并鼓励大家使用Inferentia和Trainium。
了解更多关于我们如何做到这一点的方式亚马逊全领域使用生成式AI进行创新.
关于作者
 詹姆斯·帕克是亚马逊网络服务(AWS)的解决方案架构师。他与Amazon.com合作,利用AWS设计、构建和部署技术解决方案,并特别关注人工智能和机器学习领域。在业余时间,他喜欢探索新的文化、体验新事物,并紧跟最新的科技趋势。
詹姆斯·帕克是亚马逊网络服务(AWS)的解决方案架构师。他与Amazon.com合作,利用AWS设计、构建和部署技术解决方案,并特别关注人工智能和机器学习领域。在业余时间,他喜欢探索新的文化、体验新事物,并紧跟最新的科技趋势。
 RJ是一名亚马逊的工程师。他构建和优化用于训练的分布式系统,并致力于优化采用系统以减少机器学习推理的延迟。业余时间,他正在探索使用生成式AI来创建食谱。
RJ是一名亚马逊的工程师。他构建和优化用于训练的分布式系统,并致力于优化采用系统以减少机器学习推理的延迟。业余时间,他正在探索使用生成式AI来创建食谱。
 杨州他是一名软件工程师,致力于构建和优化机器学习系统。近期他的工作重点是提升生成式人工智能推理的性能和成本效益。在工作之外,他喜欢旅行,并且最近发现了对长跑的热情。
杨州他是一名软件工程师,致力于构建和优化机器学习系统。近期他的工作重点是提升生成式人工智能推理的性能和成本效益。在工作之外,他喜欢旅行,并且最近发现了对长跑的热情。
 赵宏申亚当是亚马逊商店基础人工智能的软件开发经理。在他的当前角色中,亚当带领Rufus推理团队构建GenAI推理优化解决方案和大规模推理系统,以实现低成本高速推理。业余时间,他喜欢与妻子一起旅行和创作艺术。
赵宏申亚当是亚马逊商店基础人工智能的软件开发经理。在他的当前角色中,亚当带领Rufus推理团队构建GenAI推理优化解决方案和大规模推理系统,以实现低成本高速推理。业余时间,他喜欢与妻子一起旅行和创作艺术。
 钟发勤FaQin是亚马逊商店基础人工智能的一名软件工程师,负责大型语言模型(LLM)推理基础设施和优化工作。她对生成式人工智能技术充满热情,并与领先团队合作推动创新,使LLM更加易于访问并具有更大的影响力,最终在各种应用场景中提升客户体验。业余时间她喜欢有氧运动和与儿子一起烘焙。
钟发勤FaQin是亚马逊商店基础人工智能的一名软件工程师,负责大型语言模型(LLM)推理基础设施和优化工作。她对生成式人工智能技术充满热情,并与领先团队合作推动创新,使LLM更加易于访问并具有更大的影响力,最终在各种应用场景中提升客户体验。业余时间她喜欢有氧运动和与儿子一起烘焙。
 尼古拉斯·特罗恩他在亚马逊商店基础AI部门担任工程师。他最近的重点是利用自己在Rufus系统的专业知识,帮助Rufus推理团队,并提高Rufus体验中的系统利用率。业余时间他喜欢与妻子共度时光,以及前往附近海岸、纳帕和索诺玛地区进行短途旅行。
尼古拉斯·特罗恩他在亚马逊商店基础AI部门担任工程师。他最近的重点是利用自己在Rufus系统的专业知识,帮助Rufus推理团队,并提高Rufus体验中的系统利用率。业余时间他喜欢与妻子共度时光,以及前往附近海岸、纳帕和索诺玛地区进行短途旅行。
 Bing银亚马逊商店基础人工智能的科学总监。他负责构建专门用于购物场景并针对亚马逊规模进行优化的大型语言模型。业余时间,他喜欢参加马拉松比赛。
Bing银亚马逊商店基础人工智能的科学总监。他负责构建专门用于购物场景并针对亚马逊规模进行优化的大型语言模型。业余时间,他喜欢参加马拉松比赛。