
使用属性中立框架提升人工智能赋能医疗系统的公平性
作者:Liang, Huiying
介绍
人工智能(AI)技术在近年来取得了巨大进步,并且其在医疗领域的应用日益增多。1,2,3虽然人工智能已经在专业水平上取得了性能成就,但它直接应用的情况却在各种场景中引发了关于产生不公平结果的担忧。4,5,6,7例如吉乔亚等人关于医学成像中AI系统能够以不同准确度检测患者种族的研究8以及Seyyed-Kalantari等人关于不同年龄、性别、种族和经济社会地位的漏诊发现,强调了公平性这一关键问题。9不公平性,表现为根据敏感属性划分的不同群体之间表现不均,通常是由于AI驱动的医疗系统依赖于源自属性偏见的不当关联所导致的。5,10.
之前缓解这些偏见的努力涉及对个别模型进行特定调整11,12Puyol-Antón等人提出了一种用于分割的公平元学习方法,其中训练了一个深度学习分类器来分类种族,并与分割模型联合优化。13Dash等人设计了一种反事实正则化器来减轻预训练机器学习分类器的偏见14尽管有效,但针对特定模型的修改需要大量的资源和专业知识来有效地识别和纠正偏差,这一任务由于领域专家稀缺而变得更加复杂。因此,一个模型无关的解决方案越来越被认可为最有效的策略。
常用的方法来减轻AI模型的不公平性是在特征编码空间上进行去偏处理11或者基于某种图像增强策略12然而,几项研究表明,此类偏见与疾病结果以及医学图像的特征密切相关。在图像层面有效分离并消除偏差属性的同时保留必要的医疗信息仍然是一个重要的挑战,潜在的解决方案仍在探索中。
为了解决这一挑战,我们提出了属性中立框架。该框架旨在从数据层面分离出偏见属性与疾病相关信息,并随后对其进行中和以确保跨不同亚群的平衡表示。通过同时中和多个属性,属性中立框架在根源上解决了偏见属性问题,提供了一种普遍适用的解决方案,超越了模型复杂性和部署场景的限制。在此框架内,我们开发了属性中立器(AttrNzr),用于生成无法被人类或机器学习分类器轻松识别受保护属性的中性化数据。然后,我们将使用这些数据来训练疾病诊断模型(DDM)。与其他不公平缓解算法的比较分析表明,AttrNzr能够有效降低DDM的不公平性,同时保持其整体疾病诊断性能。本文的主要贡献有两点:1)探索了利用中性化数据减轻AI赋能医疗系统的不公平性的有效性,并使用AttrNzr实现了多属性X射线图像的中和;2)提供了一种模型无关的解决方案,直接在图像层面解决不公平问题,从而无需对每个模型进行单独修改。
结果
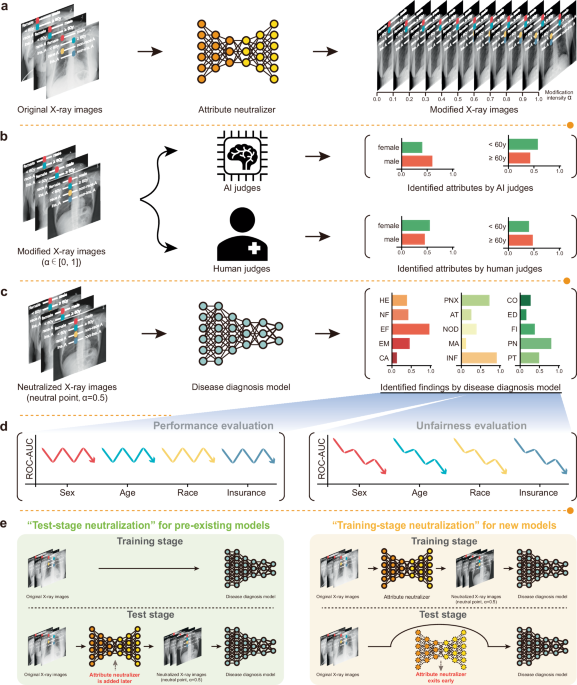
该研究通过使用三个大型公开胸部X光图像数据集(ChestX-ray14)验证了AttrNzr在缓解AI赋能的医疗系统内部不公平性方面的效果。15MIMIC-CXR16以及CheXpert17数据集的元数据包括性别和年龄属性。在MIMIC-CXR数据集中,还提供了种族和保险等额外属性。AttrNzr使用这些数据集进行训练,以修改X光图像中的属性强度。修改强度α控制AttrNzr中属性修改的程度。α范围从0到1,其中0表示没有修改,1表示否定该属性,而0.5表示中性属性。通过AI裁判和人类裁判的属性识别测试来评估AttrNzr生成具有特定属性且难以与真实X光图像区分开来的X光图像的能力。构建了多个差异度量模型(DDMs),包括基于中性化X光图像(修改强度:0.5)、修改后的X光图像(修改强度:0.6和0.7)以及结合其他不公平缓解算法的模型,例如Fairmixup。12公平格rad(注意:"Fairgrad"被假设为专有名词,如地名或公司名,因此保留原形进行音译)11以及平衡采样18,19为了评估DDM中的不公平性,采用了三种不公平度量标准:最差情况性能、性能差距和性能标准偏差。最后,为了缓解现有AI赋能的医疗系统的不公平性,并减少AttrNzr在测试阶段的计算需求,提出了两种AttrNzr的应用范式:测试阶段中和化和训练阶段中和化。我们的综合研究概述见图。1.

a利用AttrNzr生成修改后的X光图像,这些修改后图像的属性可以通过修改强度α进行调节。b将AI裁判和人类裁判纳入属性识别中,以辨别修改后的X光图像的原始属性。c在AttrNzr生成的α值为0.5的中性化X光图像上建立DDM。d根据DDM的预测进行性能和不公平性评估。e研究在测试阶段中立化范式中实施AttrNzrs以减轻现有医学AI模型的不公平性,以及在训练阶段中立化范式中实施AttrNzrs以最小化新医学AI模型的计算需求。
由属性中和器生成的X射线图像
基于原始的X射线图像及其相应的属性标签,训练了单个和多个属性的AttrNzrs。这些AttrNzrs用于以修改强度α调整属性,该参数控制属性修改的程度。α的取值范围从0到1,其中0表示不进行修改,1表示否定该属性,而0.5表示中性属性。平均修改后的X射线图像及一些示例如图所示。2.

a–d修改属性的平均修改X射线图像。修改的属性分别为(男性)到(女性),(女性)到(男性),(男性,≥60岁)到(女性,<60岁),以及(女性,<60岁)到(男性,≥60岁)。其他具有其他修改属性的平均修改X射线图像见补充图。S4. e–h修改后的X射线图像示例。修改的属性与原图相同。a–d其他修改属性的X射线图像示例见补充图。S5每个子图包含四行。第一行显示一个条形图,展示修改后的X光图像与原始X光图像之间的结构相似性指数度量(SSIM)。第二行展示了原始X光图像和修改后的X光图像。第三行显示了修改后的X光图像与原始X光图像之间的差异图像。相较于原始X光图像,在修改后的X光图像中,高亮区域用红色标记,低亮区域用绿色标记。第四行依次展示修改强度α的值从0.0到1.0(0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0)。a, b, e,和f由单一属性AttrNzrs生成,while后面的内容缺失了,我只能翻译到这里。如果您有更多的部分需要翻译,请提供完整文本。根据您的要求,只输出翻译结果,所以原文不足的部分保持不变。c, d, g,和 h由多属性AttrNzrs生成。
结构相似性指数度量(SSIM)被用于定量评估修改后的X射线图像与原始X射线图像之间的相似性。结果显示,随着修改强度的增加,SSIM值逐渐减小。如图所示。2a–d这些平均修改过的X射线图像中,SSIM与修改强度之间存在强烈的负相关关系(皮尔逊相关系数:男性到女性 -0.9097,女性到男性 -0.8917,60岁及以上男性到60岁以下女性 -0.9099,60岁以下女性到60岁及以上男性 -0.9040)。此外,AttrNzr生成的差异图像与原始X射线图像生成的差异图相似(补充图)。S6).
上述观察在平均X射线图像中也存在于修改后的X射线示例中。图2e–h展示修改后的X射线图像的示例。从视觉上看,随着修改强度的增加,修改后的X射线图像会逐渐发生细微的变化(补充视频)1差异图像说明了更高的修改强度会导致原始X射线图像与修改后的图像之间的差异增大。此外,观察到的差异区域与不同亚组之间解剖学上的差异相对应,例如男性和女性乳腺之间的差异以及老年(≥60岁)和年轻(<60岁)年龄组骨骼大小的差异。
修改后的X射线图像属性识别
在这项研究中,属性识别被用来评估AttrNzr生成具有特定属性的X射线图像的能力,这些图像与具有相同属性的真实X射线图像无法区分。在第一次属性识别测试中,AI裁判接受完整训练后使用原始X射线图像,并要求他们识别修改后的X射线图像中的性别(女性/男性)和年龄(<60岁/≥60岁)。
如图所示(fig.)3a–d对于修改强度低于0.5的情况下,AI裁判在准确识别修改后的X光图像的原始属性方面表现出色,预测属性与实际属性之间有合理的吻合度。相反,对于修改强度高于0.5的情况,AI裁判很难正确识别修改后X光片的原始属性。由于性别和年龄是二元属性,AI裁判预测的属性几乎与其真实属性相反。因此,0.5的修改强度是AI裁判识别性能的关键转折点。如图所示。3g, h当修改强度设置为0.5时,属性组之间的距离达到最小。随着修改强度进一步偏离0.5,属性组之间的距离逐渐扩大。这一观察结果也通过属性组的UMAP可视化得到了证实,如补充图所示。S7以及S8图3i–l进一步描绘了具备特定属性的修改后的X射线图像更有可能激活相应的属性梯度。此外,与修改强度大于0.5相关的激活区域和低于0.5的激活区域之间出现了显著差异,突显了0.5作为激活热图变化转折点的重要性。

性别属性识别中AI裁判的接收者操作特性(ROC)曲线a)和年龄(b人工智能裁判被要求识别修改后的X光图像的属性。修改强度α设置为0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9和1.0。在性别属性识别中,人工智能裁判的曲线下面积(AUC)、准确率、灵敏度、特异性和F1分数c)和年龄(d在不同修改强度下。人类裁判在性别属性识别中的准确性(e)和年龄(f人类裁判被要求识别五组X射线图像的属性,这些图像是以0.0、0.3、0.5、0.7和1.0的不同强度修改过的。性别(g)和年龄(h) 使用UMAP降维从AI法官的768维度最终层特征得到的二维特征计算组间距离。距离是通过非参数自助法(1000次迭代)得出的95%置信区间来度量两组中心之间的欧氏距离。经过UMAP降维后的X射线图像可视化如补充图所示。S7(性别)和补充图 fig.S8(年龄)。i, j两个性别属性识别中AI裁判的激活热图示例。热图的激活类别为女性。示例的实际性别为女性。i)和男性(j). k, l两个年龄属性识别中AI裁判的激活热图示例。热图的激活类别是<60岁。示例的实际年龄组也是<60岁。k)和≥60岁(l). 数据源以数据源文件的形式提供。
在第二次属性识别中,人类裁判被要求识别由我们的AttrNzr生成的X射线图像的属性。图 3e, f展示了人类评判员识别属性的准确性与修改强度之间存在强烈的负相关关系(年龄的Pearson系数r:−0.9919,性别的Pearson系数r:−0.8896)。值得注意的是,在X光图像中,人类评判员在识别性别方面表现出比识别年龄更高的熟练度。此外,人类评判员的识别表现变化比AI评判员更加平滑。
AI裁判和人类裁判的识别结果显示,AttrNzr生成的X光图像具有很高的真实性。此外,修改强度能够巧妙地调节各种子组属性的强度。值得注意的是,当面对修改强度为0.5时,无论是AI裁判还是人类裁判都表现出最大的不确定性。这一观察结果强调了,与极端端点的二元属性不同,经过调整(α = 0.5)的X光图像代表了一种中立且无偏的数据形式。
疾病诊断性能
疾病相关的信息在使用AttrNzr进行属性修改过程中是否被保留?为了回答这个问题,分别对原始和经过修改的X光图像训练了四个数据偏见缓解模型(DDMs)。这些修改针对年龄这一属性,修改强度(α)设置为0.5、0.6和0.7。重要的是,在α=0.5时,AttrNzr生成的X光图像显示出属性中立化的迹象,因此被称为“中性化X光图像”。此外,还采用了替代不公平缓解算法,即Fairmixup12公平混洗流形12公平格rangle.Angle似乎多余或输入不完整,我只会处理明确给出需要翻译的部分。如果"Fairgrad"是指某个特定的地名或者概念,请提供更多信息以便准确翻译。根据现有内容,“the Fairgrad”可译为“公平格”,但请确认这是否是你想表达的意思。若需翻译的文本确实只有这些字符且没有具体含义,则输出原文:"the Fairgrad"。11以及平衡抽样18也被用于训练另外四个DDM模型。
图4a–d以及补充图 fig.S9描绘7种不同的不公平缓解算法在疾病诊断中的7个关键差异(CD)图。这7个图表对应于7个指标:宏-(ROC-AUC,准确率,灵敏度,特异度,精确度,F1分数和PR-AUC)。很明显,这7种DDMs在6种{数据集,属性}组合中的整体表现存在显著差异(弗里德曼检验)P值:在所有7个指标上均小于0.05)。原始基础DDM在7个指标上的排名分别为1.5、3.3、2.8、3.3、2.2、2.7和1.3。相反,中立化基础DDM在7个指标上的排名分别为3.2、1.0、6.5、1.0、1.0、1.0和2.5。值得注意的是,中立化基础DDM的宏观敏感性显著低于原始基础DDM,在其他6个指标上没有观察到显着差异。关于其他的公平缓解算法,基于Fairgrad的DDM在Macro-(ROC-AUC、精度、F1得分和PR-AUC)方面的表现明显低于原始基础DDM。基于Fairmixup以及基于Fairmixup流形的DDMs在Macro-(ROC-AUC、精度和PR-AUC)方面相对于原始基础DDM的表现显著较低。然而,基于Modi(α = 0.6)和基于平衡采样的DDMs与原始基础DDM相比,在所有7个指标上均没有显着差异。有关更详细的宏观性能信息,请参见补充表。S9–11.

Macro-ROC-AUC的批判性差异(CD)图示a), 宏准确率 (b宏观敏感性(c),以及宏观特指性(d). 在每个图表中,对6种{数据集,属性}组合进行了弗里德曼检验和Nemenyi事后检验:{ChestX-ray14, age},{ChestX-ray14, sex},{MIMIC-CXR, age},{MIMIC-CXR, sex},{CheXpert, age} 和 {CheXpert, sex}。CD值为3.68。ChestX-ray14中各种DDMs的ROC-AUC的小提琴图(e, f),MIMIC-CXR (g–j),以及CheXpert (k, l小提琴图展示了所有发现的ROC-AUC分布情况(ChestX-ray14中有15个发现,MIMIC-CXR中有14个发现,CheXpert中有14个发现)。与不公平缓解相关的属性包括年龄(e, g, k),性别(f, h, l),保险(i),和种族(j在小提琴图中,中央的白色点代表中位数,而小提琴内部的粗线表示四分位距。须状图表示排除异常值后的数据范围。源数据以源数据文件形式提供。
在DDMs的比较分析中,使用ROC曲线和PR曲线来评估特定发现。总共有43个发现被考虑,分布如下:ChestX-ray14数据集中有15个,MIMIC-CXR数据集中有14个,CheXpert数据集中有14个。分别采用Delong检验和Bootstrap方法来评估ROC曲线和PR曲线差异的统计显著性。对于ROC曲线(补充图)。S10例如),与基于原始数据的DDM(补充表相比)S12–14),无显著差异的发现数量如下:15(中和),13(Modi (α = 0.6)),11(Modi (α = 0.7)),1(Fairgrad),28(平衡采样),0(Fairmixup)以及0(Fairmixup 流形)。此外,在基于中和的DDM中,所有发现的ROC-AUC值显示出均匀分布(图。)4e–l关于PR曲线(补充图 Fig.)S11例如),与基于原始数据的DDM(补充表相比)S15–17),无显著差异的发现数量分别为23(中和),17(Modi (α = 0.6)),13(Modi (α = 0.7)),0(Fairgrad),20(平衡采样),0(Fairmixup)以及0(Fairmixup 流形)。此外,在基于中和的DDM中,所有发现的PR-AUC值呈现均匀分布(补充图。)S12).
图5展示了四个由AI裁判、人类裁判和DDMs(基于数据的检测模型)评估的例子。可以观察到,经过中立处理的X光图像相比原始X光图像增加了AI裁判和人类裁判在识别属性方面的不确定性。然而,基于中立化方法的DDM仍然可以从这些中立化的X光图像中识别出相应的发现,并且其检测结果与基于原始图像的DDM的结果一致。

每个示例的属性如下:a女性,<60岁;b女性,≥60岁;c男性,<60岁;和d男性,≥60岁。这些例子中的发现如下:a渗透;b肺气肿;c结节;和 d肺不张,积液。每个子图包含一张原始X光图像及其对应的中性化X光图像。中和的属性是性别和年龄,修改强度α为0.5。X光图像的属性由AI裁判和人类裁判识别,而X光图像的结果则由DDM识别。AI裁判和DDMs报告输出概率。人类裁判基于五名人类裁判的评价报告投票比例。AT肺不张,CA心脏增大,CO实质变性,ED水肿,EF积液(EF),EM肺气肿,FI纤维化,HE隔疝,INF浸润,MA肿块,NOD结节,PT胸膜增厚,PN肺炎,PNX气胸,NF无发现。
疾病诊断模型的不公平性
本节旨在通过三种类型的不公平性指标来评估各种DDM的不公平性:子群体中的最差表现20,21性能差距最大的子组和最差的子组之间的表现差距20以及所有子组中的性能标准差13,22不公平性评估中介绍了该方法。在不公平性评估中,性能基于ROC-AUC进行评价20准确性19,23,24敏感度23,特异性和准确性20.
图6a–d以及补充图 fig.S13展示各种缓解不公平算法的CD图。很明显,7种DDM在6种{数据集,属性}组合中的总体不公平性存在显著差异(弗里德曼检验P值:在11个指标中均小于0.05(最坏情况敏感性除外)。基于中立化的DDM在12个不公平度量中的排名分别为1.3、1.8、2.2、1.8、1.0、1.0、2.7、1.0、1.0、1.8、2.2、1.8,在性能-SD和最坏情况下的性能中排名第一。基于Fairgrad的DDM在12个不公平度量中的排名分别为3.8、1.2、1.0、1.2、7.0、6.5、5.0、6.3、7.0、1.2、1.0、1.2,并且在准确性、敏感性和特异性差距方面排名第一。此外,在多个指标上,如ROC-AUC SD和最坏情况下的ROC-AUC,平衡采样法和中立化方法之间的不公平性没有显著差异(图)。6e-l然而,基于Fairmixup和基于Fairmixup流形的DDM在所有12个不公平性指标上通常表现较差,甚至在某些不公平性指标上比原始的DDM表现更差。对于更为全面的不公平性评估,请参见补充表。S18–20.

关键差异(CD)图用于ROC-AUC标准差(a准确性标准差(b敏感度SD (c),以及特异性SD (d). 在每个图中, Friedman 检验和 Nemenyi 多重比较检验在以下六个数据集属性组合上进行:{ChestX-ray14, 年龄}、{ChestX-ray14, 性别}、{MIMIC-CXR, 年龄}、{MIMIC-CXR, 性别}、{CheXpert, 年龄} 和 {CheXpert, 性别}。CD 值为 3.68。ChestX-ray14 中各种 DDMs 的 ROC-AUC 标准差的小提琴图e, f),MIMIC-CXR (g–j),以及CheXpert (k, l小提琴图展示了所有发现的ROC-AUC标准差分布(ChestX-ray14中有15个发现,MIMIC-CXR中有14个发现,CheXpert中有14个发现)。与不公平缓解相关的属性包括年龄(e, g, k), 性别 (f, h, l),保险(i),和种族(j在小提琴图中,中央的白色点代表中位数,而小提琴内部的粗线表示四分位距。须状线代表排除离群值后的数据范围。源数据以源数据文件形式提供。
皮尔逊相关系数用于量化两个不公平度量之间的关联,皮尔逊的r值见补充表。S21如补充表所示S21观察到最坏情况指标与其他两种不公平性指标之间存在负相关关系,强度不同。相反,在所有四个指标(ROC-AUC、准确率、灵敏度和特异度)中,性能差距与标准差(SD)之间存在很强的正相关关系:ROC-AUC (Pearson’s r: 0.7195)、准确率 (Pearson’s r: 0.8794)、灵敏度 (Pearson’s r: 0.9437) 和特异度 (Pearson’s r: 0.7219)。
多属性中立化中的不公平性
人口具有多种属性,导致了多方面的不公平。本节旨在探讨多属性中立化器(AttrNzrs)对DDMs性能和不公平性的影响。使用AttrNzr生成了四种类型的中立化X光图像,其中被中立化的属性分别为(性别)、(性别,年龄)、(性别,年龄,种族)以及(性别,年龄,种族,保险)。随后,基于原始的X光图像及这四种类型中立化的X光图像分别训练五个DDMs。图7展示了这五个DDMs在三个数据集上的ROC-AUC值和敏感性标准差。需要注意的是,用于中立化的属性和评估不公平性的属性可能不同。例如,在图Fig. 中7k评估不公平性的属性是保险,但只有在性别、年龄、种族和保险都在X光图像中被匿名化的情况下,保险才被视为已被匿名化。

小提琴图展示了ROC-AUC或灵敏度标准差在所有发现中的分布情况(ChestX-ray14中有15个发现,MIMIC-CXR和CheXpert中各有14个发现)。ChestX-ray14中ROC-AUC的分布情况a),MIMIC-CXR (b),以及CheXpert (c胸部X光14数据集中敏感度标准差的分布情况(d, e),MIMIC-CXR (h, i, j, k),以及CheXpert (f, g评估不公平性的属性如下:性别(d, f, h),年龄(e, g, i种族(j),和保险(k). 使用原始X光图像或去偏的X光图像训练了多个DDM。去偏的属性包括(性别)、(性别和年龄)、(性别、年龄和种族),以及(性别、年龄、种族和保险)。在小提琴图中,中间的白色点表示中位数,而小提琴内部的粗线表示四分位距。须状图表示数据范围,不包括异常值。注意:模型训练数据中的去偏属性与评估不公平性的属性可能不同。例如,在子图中k评估的属性是保险,但只有一个模型是在中和了保险数据后训练的。每个发现的ROC-AUC值和敏感性标准差如补充图所示。S14以及S15源数据以源数据文件的形式提供。
如图所示Fig.7a-c随着被中和的属性数量的增加,DDM的Macro-ROC-AUC存在微小的降低。例如,在MIMIC-CXR(图 Fig. 的背景下,7b),五个DDM的Macro-ROC-AUC值分别为:79.41%(原始),78.26%(性别中立化),78.21%(性别和年龄中立化),77.44%(性别、年龄和种族中立化),以及77.76%(性别、年龄、种族和保险中立化)。这一观察结果强调了,如同单一属性的AttrNzr一样,多属性AttrNzr生成的X射线图像仍能保留足够的与疾病相关的信息。
如图所示在图中。7天-k当X射线图像的中立属性包含要评估的属性时,与所评估属性相关的不公平减少变得明显。在图Fig. 中7e,年龄的敏感性SD从0.0507(原始值)下降到0.0249(性别和年龄中立化后)。然而,如果评估属性不在X射线图像的中立化属性之中,相应的敏感性SD显示极小的变化。在图。7j,种族的敏感性SD从0.1360(原始)变为0.1184(中和性别和年龄);在图中。7千保险的敏感性SD从0.0350(原始值)变为0.0370(性别和年龄中立化后)。这一观察结果突显了多属性AttrNzr在消除DDMs众多属性不公平方面的有效性。同时,这种缓解具有高度针对性,对未进行中立化的属性的不公平性影响很小。
测试阶段和训练阶段的中和范式
本节旨在探讨两个问题:1) AttrNzrs 是否能够为原本未设计用于缓解不公平性的现有模型提供事后公平性保护?2) AttrNzr 的参数大约是 DDM 参数的十倍。为了在应用过程中最小化计算成本,AttrNzr 只在应用阶段引入。在这种情况下,AttrNzr 提前退出是否仍能有效减轻模型的不公平性?
为了说明起见,定义了AttrNzr的四种应用范式:不进行中和(不使用AttrNzr)、测试阶段中和(仅在现有模型的测试阶段添加AttrNzr)、训练阶段中和(仅在新模型的训练阶段使用AttrNzr)、全程中和(在训练和测试阶段都使用AttrNzr)(图。)8a在图中展示了这四个应用范式下DDMs的宏平均ROC-AUC值和平均灵敏度标准差。8b–q.

a示意图说明了AttrNzr的四个应用场景。这四个场景分别是:不进行去敏感化(未使用AttrNzr)、测试阶段去敏感化(仅在测试阶段使用AttrNzr)、训练阶段去敏感化(仅在训练阶段使用AttrNzr)以及全程去敏感化(在训练和测试两个阶段都使用AttrNzr)。ChestX-ray14数据集上的宏平均ROC-AUC值:b, c), ChestX-ray Pert (注意:CheXpert 数据集通常用于医学影像分析领域,这里的“ChestX-ray Pert”可能是对“CheXpert”的音译或简化形式,在标准文献中应使用“CheXpert”。) 由于要求只输出翻译结果且没有实际需要翻译的内容,按照指示保持原样: ), CheXpert (d, e),以及MIMIC-CXR (f–i). d–k胸部X光14中的敏感度标准差(_SDs_)j, k),CheXpert (l, m),以及MIMIC-CXR (n–q每个子图的中性属性如下:性别(b, d, f, j, l, n), 年龄 (c, e, g, k, m, o种族(h, p),和保险(i, q). r子图的详细布局模板b–q.
如图所示 fig. 注意:“Illustrated in Fig.”通常直接翻译或表达为“如图所示”,由于原文中没有具体的图号或其他补充信息,“Fig.”保留未译。如果需要进一步解释或者有具体图号,请提供更多信息以便更准确地翻译。在此情况下,按照指示只输出可以确认的内容。8b–i,DDM在四个范式下的三个数据集上的平均Macro-ROC-AUC值分别为:79.49%(无中和),77.22%(测试阶段中和),77.46%(训练阶段中和),以及78.34%(全程中和)。在测试阶段中和和训练阶段中和范式下,DDM的平均Macro-ROC-AUC值下降可能归因于训练数据(训练阶段)与测试数据(测试阶段)之间的异质性。然而,这种下降相对较小,表明在AttrNzr的测试阶段中和和训练阶段中和范式下,DDM的表现并未受到实质性影响。
如图所示_fig.8j–q在四个范式中,DDM在三个数据集上的敏感性标准差分别为0.0488(无去激活)、0.0405(测试阶段去激活)、0.0397(训练阶段去激活)和0.0266(全程去激活)。可以看出,在训练阶段去激活的范式中,AttrNzr仍然可以提供一定的公平保护效果。这些结果强调了引入训练阶段去激活范式如何扩展了AttrNzr的应用潜力。
讨论
在本研究中,我们提出了一种用于缓解医疗场景不公平性的属性中立框架。在此框架内,我们利用AttrNzr生成去偏数据。通过使用去偏数据训练DDMs(诊断决策模型),可以有效破坏疾病信息和敏感属性之间的不适当关联,从而减少模型的不公平性。在三个大型公共X光图像数据集中,AttrNzr展示了出色的X光图像重建能力和准确调整属性信息强度的能力。与其他缓解不公平性的算法进行比较分析显示,AttrNzr在多个公平性评估指标上表现更优。此外,AttrNzr不会显著降低整个群体中DDM的诊断性能。即使修改了多个属性,AttrNzr也能有效缓解模型的不公平性并保持其诊断性能。最后,AttrNzr证明了在训练阶段去偏范式中保护模型公平性的有效性。
在各种DDM中,基于Fairgrad的DDM在性能差距和性能标准差(图。)方面表现出显著的性能。6以及补充图 fig.S13然而,它在整个群体中的疾病诊断性能相对较差(图。)4以及补充图fig.S9这种现象被称为向下趋同,在许多实际场景中偏离了理想的公平标准。21,25,26许多处理中的公平性缓解算法在训练过程中向损失函数引入了额外的学习目标。11,12,14在一定程度上,这一额外约束与模型的主要目标相冲突,从而导致了普遍存在的向下拉平效应。
如果有一种技术能够有效减轻人工智能赋能的医疗系统中的不公平现象,在实际临床场景中证明有效的,那么已经部署的人工智能赋能的医疗系统可能需要被废弃,并基于该技术重新开发新的系统。在这种情况下,系统开发的设计、开发、执行、测试和部署都需要重新进行。这不仅会消耗额外的人力和资金,还会占用更多的医疗资源。而在欠发达地区,这些问题将更加严重。在这项研究中,AttrNzr在测试阶段的中立化范式可能是解决这一问题的一个选项。它可以在保留原有的人工智能赋能的医疗系统的同时,为系统的公平性提供一定的保护。
在欠发达地区,医疗资源匮乏且缺乏经验丰富的医生。因此,欠发达地区是利用人工智能赋能的医疗系统的优点的最佳场所。然而,欠发达地区的患者往往在人工智能训练数据集中代表性不足。在英国生物银行数据集中,研究人员发现了“健康志愿者”选择偏差的证据。27在23andMe基因型数据集中,共有2399人,其中2098人(87%)是欧洲人,只有58人(2%)是亚洲人,50人(2%)是非洲人。28因此,在欠发达地区部署的AI医疗系统可能面临更为严重的不公平问题。另一方面,欠发达地区的计算资源稀缺,因此需要大量计算资源的不公平缓解技术难以有效应用。在这项研究中,AttrNzr 的训练阶段中立化范式不需要大量的计算资源。由于欠发达地区大多数患者属于代表性不足的人群,部署 AttrNzrs 不仅可以提高系统的公平性,还可能提升整体诊断性能。
我们的实验结果表明,某些不公平性评估指标之间不存在显著的相关性。例如,最差情况准确率与准确性差距(皮尔逊相关系数:−0.1767)以及最差情况ROC-AUC与ROC-AUC标准差(皮尔逊相关系数:−0.20172)之间的关联较弱。这强调了各种公平性定义的不兼容性。29在实验层面。虽然性能差距、性能标准差和最差性能有效衡量了不同群体之间的性能差异,但它们可能无法直接捕捉到整体水平下降的效果。鉴于性能与公平性之间的一致性问题、个体属性的复杂性以及跨属性群体的存在,采用全面多样的评估系统对于开发有效的不公平缓解算法至关重要。
该研究有几个局限性。首先,当前版本的AttrNzr只能修改离散属性。然而,许多属性,如年龄、收入等,是连续变量。为了将AttrNzr应用于连续属性,需要对其进行离散化处理。离散化会在属性组之间引入方差。例如,一个59岁364天的患者和另一个60岁1天的患者会被分别归类为“<60 y”和“≥60 y”,尽管他们的实际年龄差异微乎其微。这种被迫的数据分布扭曲可能会阻碍AttrNzr学习连续属性的真实变化趋势。其次,应验证AttrNzr在其他类型的成像模型和其他属性上的有效性。第三,与最差情况性能和性能差距相比,不公平性指标(性能SD)的解释性较差。因此,在使用性能SD时,未来的研究应该考虑这一限制。尽管当前研究在DDMs(决策树模型)和特定属性上取得了令人鼓舞的结果,但探索其在不同医学成像应用和各种属性领域的表现仍然是至关重要的。
方法
数据集
在这项研究中,我们纳入了三个大规模公开的胸部X光数据集,即ChestX-ray1415MIMIC-CXR16以及CheXpert17ChestX-ray14数据集包含从1992年到2015年间收集的30,805名不同患者提供的112,120张胸部正位X光片图像。(补充表)S1数据集包括使用自然语言处理从相关放射学报告中提取的14项发现(补充表)S2X射线图像的原始大小为1024×1024像素。元数据包括每位患者的年龄和性别信息。
MIMIC-CXR 数据集包含从马萨诸塞州波士顿的 Beth Israel Deaconess 医疗中心收集的 356,120 张胸部 X 光片,涉及 62,115 名患者。该数据集中获取的 X 光片有三种视角之一:后前位、前后位或侧位。为了确保数据集的一致性,仅包括后前位和前后位的 X 光图像,最终剩余 239,716 张来自 61,941 名患者的胸部 X 光片(补充表)。S1). MIMIC-CXR数据集中的每一张X光图像都使用自然语言处理工具从半结构化的放射科报告中提取了13个发现进行标注(补充表)S2元数据包括每位患者年龄、性别、种族和保险类型的的信息。
CheXpert数据集包含来自斯坦福医疗中心的65,240名患者在2002年10月至2017年7月期间进行的放射学检查中的224,316张胸部X光图像,这些患者分别是在住院和门诊中心接受检查。该数据集仅包括正位X光图像,侧位图像被移除以确保数据集的一致性。这导致剩下64,734名患者的191,229张正位X光图像(补充表)。S1). CheXpert 数据集中的每一张 X 光图像都标注了 13 种发现(补充表)S2每个患者的年龄和性别可在元数据中获取。
在所有三个数据集中,X光图像均为灰度图,格式为“.jpg”或“.png”。为了便于深度学习模型的学习,所有的X光图像都被调整为256×256像素的大小,并通过最小-最大缩放归一化到[-1, 1]范围内。在MIMIC-CXR和CheXpert数据集中,每个发现可以有四种选项之一:“阳性”,“阴性”,“未提及”或“不确定”。为了简化起见,后三种选项合并为否定标签。三个数据集中的所有X光图像都可以用一个或多个发现进行标注。如果没有检测到任何发现,则将该X光图像标记为“无发现”。
关于患者属性,年龄组被分类为“小于60岁”或“大于等于60岁”30性别属性包括两个组:“男性”或“女性”。在MIMIC-CXR数据集中,移除了种族的“未知”类别,使得患者被归类为“白人”、“西班牙裔”、“黑人”、“亚洲人”、“美洲原住民”或“其他”。同样地,移除了保险类型的“未知”类别,并将患者分为“医疗补助”、“医疗保险”或“其他”三组。三个数据集在属性和交叉属性下的X光图像数量和比例见补充表。S1, S3–S5.
所有三个大规模的公共胸部X光数据集都按照8:1:1的比例被划分为训练数据集、验证数据集和测试数据集(补充表)S6为了防止标签泄漏,同一患者的X光图像不会分配到不同的子集。
属性中和器
AttrNzr是基于AttGAN构建的31,允许在保持其他图像信息的同时连续调整属性强度。它由两个主要部分组成:生成器和判别器。生成器采用U-net结构将原始X射线图像编码为潜在表示,并将潜在表示与属性向量的拼接解码为修改后的X射线图像。判别器作为多任务图像分类器,区分原始和修改后的X射线图像并识别X射线属性。AttrNzr的参数通过结合属性分类约束、重构损失和对抗性损失的损失函数进行优化(补充图)。S1).
\(G_{enc}\)和\(G_{dec}\)指示生成器的编码器和解码器。(C)和\(D\)指示属性分类器和判别器。记作\(a\)原始属性向量,\(b\)修改后的属性向量,\(\hat{b}\)识别的属性向量通过(C), \(Z\)潜在表示\(x^a\)原始X光图像与\(a\), \(x^{\hat{a}}\)修改后的X射线图像 với <|im_start|>user the modified X-ray image with <|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|><|im_start|>\(a\),和 \(x^{\hat{b}}\)修改后的X射线图像_with_(注:原文末尾有“with”但没有进一步的内容,此处保留“with”以保持一致性,但由于中文习惯一般不直接翻译该词,除非后面跟具体内容。如果需要完整句子请提供完整内容以便准确翻译)\(b\). \(a\), \(b\),和 \(\hat{b}\)包含\(n\)二元属性,可以表示为\(a=(a_{1},\cdots,a_{n})\), \(b=(b_{1},\cdots,b_{n})\),和\(\hat{b} = (\hat{b}_1, \cdots, \hat{b}_n)\)分别。
在AttrNzr中,生成器(编码器和解码器)生成的图像应满足三个目标:1)\(x^{\hat{a}}\)与……相同\(x^a\);2) 属性为\(x^{\hat{b}}\)由…识别或标识(C)作为\(b\);和3)\(x^{\hat{b}}\)被识别为\(D\)作为真实的X射线图像。因此,生成器的损失函数\(L_{gen}\)表述如下:
$${L}_{{gen}}={\lambda }_{1}{L}_{{rec}}+{\lambda }_{2}{L}_{{{cls}}_{g}}+{L}_{{{adv}}_{g}},$$
(1)
哪里\(L_{\text{rec}}\), \(L_{cls_{g}}\),和\(L_{g_{adv}}\)分别表示重建损失、属性分类约束和对抗损失。\(\lambda_1\)以及\(\lambda_2\)是用于平衡不同损失的超参数。\(L_{\text{rec}}\)通过所有绝对差异之和来衡量\(x^a\)以及\(x^{\hat{a}}\)如下表述:
$${L}_{{\text {rec}}}=\left\| x^{a}-x^{\hat{a}} \right\|_{1}.$$
(2)
\(L_{cls_{g}}\)通过交叉熵来衡量\(b\)以及\(\hat{b}\)如下表述:
$${L}_{{{cls}}_{g}}={\sum }_{i=1}^{n}-{b}_{i}\log {C}_{i}\left({x}^{\hat{b}}\right)-\left(1-{b}_{i}\right)\log \left(1-{C}_{i}\left({x}^{\hat{b}}\right)\right),$$
(3)
哪里\(C_i(x^{\hat{b}})\)表示预测的第i个属性。\(L_{g_{\text{adv}}}\)表述如下:
$${L}_{\textit{adv}_g}=-D(x^{\hat{b}}),$$
(4)
在AttrNzr中,判别器/属性分类器应达到三个目标:1)识别属性的\(x^a\)作为\(a\)识别\(x^a\)作为真实的X射线图像;和3)识别\(x^{\hat{b}}\)作为假的X光图像。因此,判别器/属性分类器的损失函数\(L_{\text{dis}/\text{cls}}\)表述如下:
$${L}_{{\text{dis}/\text{cls}}}=\lambda_3 {L}_{{\text{cls}}_c} + {L}_{{\text{adv}}_d},$$
(5)
哪里\(L_{cls_{c}}\)以及\(L_{d_{adv}}\)表示属性分类约束和对抗损失。\(\lambda_3\)是用于平衡不同损失的超参数。\(L_{cls_{c}}\)通过交叉熵来衡量\(a\)以及由...生成的属性向量(C),表述如下:
$${L}_{{{cls}}_{c}}={\sum }_{i=1}^{n}-{a}_{i}\log {C}_{i}\left({x}^{a}\right)-\left(1-{a}_{i}\right)\log \left(1-{C}_{i}\left({x}^{a}\right)\right).$$
(6)
\(L_{d_{\text {adv }}}\)表述如下:
$${L}_{\text{{adv}}_{g}}=-D\left(x^{a}\right)+D\left(x^{\hat{b}}\right).$$
(7)
属性向量包含属性的二进制表示。对于年龄和性别,“<60岁”/“≥60岁” 和 “女性”/“男性” 用0/1 表示。对于多类属性如种族和保险类型,每个子组使用独热编码(补充图)。S2a例如,白色编码为((1,0,0,0,0,0)), Hispanics被编码为((0,1,0,0,0,0))在AttrNzr中,通过修改属性向量来调整X射线属性。修改强度α控制了属性修改的程度。α的取值范围从0到1,其中0表示不进行修改,1表示否定该属性,而0.5表示中性属性(补充图)。S2b).
属性向量的高可扩展性使得AttrNzr不仅可以修改单个属性,还可以同时修改多个属性。对于三个胸部X光数据集,分别训练了单个属性的AttrNzr和多个属性的AttrNzr(补充表 )S7).
为了增强AttrNzr的基本稳定性,实施了以下建议:1)在将X射线图像输入鉴别器之前,添加平均值为0.1的高斯噪声;2)在训练鉴别器时,将5%的假/真标签翻转;3)对属性向量应用标签平滑处理;4)使用随机水平翻转来增强X射线图像数据集;5)利用尺寸为6 × 6的大卷积核;6)属性分类约束损失、重构损失、对抗损失和梯度惩罚的损失权重分别设置为10、100、1和10。其他训练超参数包括学习率为0.0001,批次大小为64,训练周期为300。AttrNzr在Tesla V100 32GB GPU上进行训练。
AI裁判用于属性识别
在这项研究中,裁判识别了由我们的AttrNzr生成的X光图像的属性。第一个裁判是经过原始X光图像完全训练的AI模型,用于分类属性类型。该AI裁判用于识别被不同强度修改过的X光图像的属性。修改强度α设置为0.0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9和1.0。为了便于评估AI裁判的表现,本研究中仅对二元属性(年龄和性别)的AI裁判进行了训练。
在考虑了各种深度学习模型在疾病诊断中的表现(将在疾病诊断模型部分提及)之后,卷积神经网络(ConvNet)32被选中来构建AI法官。该AI法官设计有2个输出节点,对应于“<60岁”/“≥60岁”或“女性”/“男性”。AI法官的所有参数都使用ConvNet在ImageNet数据集上的预训练进行初始化。数据增强技术33包括随机水平翻转、随机旋转、高斯模糊和随机仿射变换等数据增强方法被应用于扩充数据集。其他超参数包括学习率为0.0005,批大小为120,训练周期为100个epoch。AI裁判也在一块Tesla V100 32GB GPU上进行训练。在AI裁判完全训练完成后,会使用梯度加权类激活图来找到修改后的X光图像中的激活区域。
人类裁判员进行属性识别
第二个属性识别由人类裁判来确定我们AttrNzr生成的X光图像的属性。广东省人民医院胸外科邀请了五名初级医生作为人类裁判进行属性识别。由于大规模公共胸部X光数据集获取地与这5名人裁判工作地区的种族和保险情况存在差异,因此属性识别仅关注年龄和性别两个属性。
对于每个属性,从ChestX-ray14数据集中随机选择5组X光图像。每组包含40张使用AttrNzr以不同修改强度处理的X光图像。为了减少人工评判的工作量,将修改强度α限制为五个值:0.0、0.3、0.5、0.7和1.0。
即使修改强度不同,同一组X射线图像仍然表现出相对相似性。为了防止人类裁判的识别决定受到同一组但修改强度不同的X射线图像的影响,每个裁判不允许重复识别同一组图像,无论其修改强度如何。五名人类裁判的任务分配安排见补充图 。S3.
疾病诊断模型
在三种大规模公开胸部X光数据集上比较各种深度学习网络的疾病诊断性能(补充表)S8), 在本研究中选择使用ConvNet作为DDM。在这些数据集中,“无发现”标签与其他发现标签是互斥的,但其他发现标签之间并不互斥。为了简化疾病诊断任务,将其视为一个多标签识别任务。在DDM中,输出节点的数量等于发现标签的数量,包括“无发现”标签。最后一层的激活函数为sigmoid函数,损失函数为二元交叉熵损失函数,用于计算目标与输出概率之间的损失。考虑到数据集中发现的不平衡性,我们根据每个发现相关的X光图像数量对损失进行加权。初始化、数据增强和超参数设置与AI Judge保持一致。
深度学习的不稳定给DDM的评估带来了不确定性。为了确保可靠的评估结果,我们在DDM在验证数据集上收敛之后进行额外的20轮训练。每完成一轮训练后,我们保存DDM的输出。最后,根据这20轮训练得到的输出对DDM进行评估。
替代不公平缓解算法
本研究介绍了三种用于减轻AI赋能医疗系统不公平性的替代算法:Fairmixup12公平格rad(注意:"Fairgrad"被假设为一个专有名词,如地名或项目名称,因此保持原样)11以及平衡抽样18前两个算法需要集成到DDM中,而第三个算法仅应用于数据集。
在Fairmixup中,使用mixup来生成不同群体之间的插值样本12这些插值样本引入了平滑正则化约束,该约束被纳入AI模型的损失函数中以减轻不公平性。Mixup可以在图像和特征层面实现,分别称为Fairmixup和Fairmixup流形。插值样本是从混合两个样本得出的,因此Fairmixup在解决与二元属性(如年龄和性别)相关的不公平问题上非常有效。Fairmixup的实现基于官方算法源代码https://github.com/chingyaoc/fair-mixup),并将损失函数中的正则化约束权重设置为0.05。
Fairgrad通过将优势群体样本的权重分配得低于劣势群体样本来确保公平性。11此方法仅适用于二分类任务。因此,在我们的研究中,多标签识别任务被分割为多个二分类任务(ChestX-ray14、MIMIC-CXR和CheXpert数据集分别包含15个、14个和14个二分类任务)。Fairgrad的实现基于官方的PyPI包。https://pypi.org/project/fairgrad/损失函数中的不公平性通过平等机会进行评估。
平衡抽样通过构建组均衡的数据来对抗不公平,其中多数群体的样本数量被随机缩减以匹配少数群体的数量,同时保持各种发现之间的比例分布。关于少数群体样本数量的详细信息请参见补充表 S1.
对于每种替代的不公平缓解算法,模型框架、数据增强、学习率、训练轮数及其他配置与基线DDM保持一致。
性能评估指标
结构相似性指数(SSIM)34用于评估两张X射线图像之间的相似性。SSIM在图像的各个窗口上进行计算。两个窗口之间的度量\(x\)以及\(y\),大小为\(N\times N\)由公式给出:
$${SSIM}(x,y)=\frac{(2\mu_x\mu_y+c_1)(2\sigma_{xy}+c_2)}{(\mu_x^2+\mu_y^2+c_1)(\sigma_x^2+\sigma_y^2+c_2)}.$$
(8)
这里,\(μ_x\)和\(\mu_y\)表示平均像素值\(x\)以及\(y\)分别。\(σ_x^2\)以及\(\sigma_y^2\)表示方差为\(x\)和\(y\),而σ_{xy}表示交叉相关性之间的东西未完整,但根据上下文可以理解为:“代表交叉相关性”或“表示两个信号之间的交叉相关性”。如果必须严格按照给定的句子结构翻译,则输出:"表示交叉相关性之间"。由于原文不完整,建议补充完整后再尝试翻译。\(x\)以及\(y\)变量\(c_{1}\)以及\(c_{2}\)用于在分母较弱时稳定除法。窗口大小设置为\(100\times 100\)在我们的研究中。
在属性识别中,使用准确率、敏感性、特异性和F1分数来评估AI裁判识别修改后的X光图像原始属性的性能。此外,计算接收者操作特征曲线下的面积(AUC-ROC)以进一步评价AI裁判的表现。对于人类裁判,仅使用准确率来评估他们识别修改后X光图像原始属性的能力。
为了应对DDM的不稳定性,取收敛后的20个epoch的输出平均值以获得稳定的结果。在评估每个发现中DDM的表现时,生成ROC曲线和精确度-召回率(PR)曲线,并计算相应的AUC值。此外,为了评价目的还计算了准确率、灵敏度、特异度、精确度和F1分数。通过对所有发现进行这些指标的宏平均来评估DDM的整体性能。
不公平评估指标
不公平性通过评估各个子群体的表现来衡量20在我们的研究中,ROC-AUC被用作评估模型性能的主要指标。为了评估与非二元属性相关的不公平性,我们采用两个评价指标:(1)群体公平性,它测量具有最高和最低AUC值的子组之间的ROC-AUC差距。20(2)最大最小公平性,该指标评估性能最差的子群体的AUC值20,21此外,我们还报告了其他性能指标的值,例如准确率、灵敏度和特异度。
neither the Worst-case ROC-AUC nor the ROC-AUC Gap can reflect the performance differences among all subgroups. The standard deviation (SD) can measure the mutual difference among multiple variables. Therefore, we introduce the standard deviation of performance13,22作为第三个不公平性评估指标,性能标准差可以通过以下公式计算:
$${UI}=\sqrt{\frac{\sum_{i=1}^{M}\left({met}_{i}-\overline{{met}}\right)^{2}}{M}}.$$
(9)
这里,\(M\)表示属性中的组数。\(m_{i}\)或多译为\({{met}}_{i}\)的具体含义不明确,保持原样输出:\({{met}}_{i}\)表示性能度量值的(\(i+1\)th) 如果原始文本就是 \({ith}\) 而没有其他具体含义或上下文,则直接翻译为中文格式可以写作:第 \(i\) 个。根据需要选择合适的表达方式,此处给出两种可能的转换结果,请确认需求。若无特殊含义,输出原文: \({ith}\)群组,和 \(\overline{{met}}\)表示所有组的平均性能。
性能标准差量化了属性内不同群体之间绩效的变异或离散程度。较低的性能标准差表明每个群体的绩效更接近所有群体平均绩效,这表示不公平程度更低。相反,较高的性能标准差则意味着各个群体的绩效分布范围更大,显示出更高的不公平性。在我们的研究中,性能标准差的计算也基于DDM(差异偏差度量)的稳定输出。
统计分析
SSIM用于评估修改后的X射线图像与原始X射线图像之间的相似性。随后,使用皮尔逊相关系数来衡量相似性和修改强度之间的相关性。此外,还使用皮尔逊相关系数来评估裁判识别性能与修改强度之间的相关性。DDM的评价指标在95%置信区间内通过非参数自助法(1000次迭代)计算得出。Delong检验用于检验两个ROC曲线之间差异的统计显著性。PR曲线下面积差值的置信区间使用偏差校正和加速自助法进行计算。如果95%的置信区间不包含0,则表示这两个区域存在显著差异。PROC曲线和PR曲线的比较使用MedCalc软件进行(显著性水平为p<0.05)。
为了全面比较不同算法之间的相对性能和缓解不公平性,我们采用弗里德曼检验。35Nemenyi事后检验随后进行20最初,每个算法在每个数据集和属性内部独立计算相对排名。随后,如果Friedman检验显示统计显著性,则使用平均排名进行Nemenyi检验。显著性阈值为PP值小于0.05被采用。这些测试的结果通过关键差异(CD)图展示。36在这些图表中,由水平线连接的方法属于同一组,表示基于p值的差异不显著,而位于不同组(未由同一条线连接)的方法表现出统计上的显著差异。Fairmixup和Fairmixup流形技术不适合用于非二元属性。因此,在以下6种{数据集,属性}组合中执行Friedman检验和Nemenyi事后检验:{ChestX-ray14, age}、{ChestX-ray14, sex}、{MIMIC-CXR, age}、{MIMIC-CXR, sex}、{CheXpert, age} 和 {CheXpert, sex}。
报告摘要
有关研究设计的进一步信息可在以下位置获取:自然科研报道摘要与本文相关的内容。
数据可用性
在这项研究中,我们整合了三个广泛的公共胸部X光数据集:ChestX-ray14、MIMIC-CXR和CheXpert。ChestX-ray14数据集由美国国立卫生研究院临床中心的院内研究计划支持,并可通过以下网址访问:https://nihcc.app.box.com/v/ChestXray-NIHCC/folder/36938765345MIMIC-CXR数据集可在此访问:https://physionet.org/content/mimic-cxr-jpg/2.0.0/要访问MIMIC-CXR数据集的数据文件,必须首先成为PhysioNet的认证用户。随后,需要完成强制性培训,例如CITI Data或仅限于研究中的标本等课程。最后,应签署该项目的数据使用协议。值得注意的是,MIMIC-CXR数据集中的心脏X光图像已经预处理为压缩的JPG格式。最初的DICOM格式胸部X光片可以从以下位置获取:https://physionet.org/content/mimic-cxr/2.0.0/CheXpert数据集可以通过以下方式访问:https://stanfordmlgroup.github.io/competitions/chexpert/. 源数据本文提供了这些内容。
代码可用性
AttrNzr、AI裁判和DDM的代码可以通过以下链接访问:https://zenodo.org/records/1325409937提供了全面的说明以方便我们的工作被复制。为了代码测试目的,我们提供了一些缩减规模的数据文件。此外,所有模型的超参数都包含在各自的脚本中。值得一提的是,AttrNzr代码的一部分借鉴了Elvis Yu-Jing Lin的工作。https://github.com/elvisyjlin/AttGAN-PyTorch); Fairmixup的实现来源于官方算法源代码(https://github.com/chingyaoc/fair-mixup); 而Fairgrad的实现基于官方的PyPI包(https://pypi.org/project/fairgrad/).
参考文献
卡曼尼,D. S. 等人。通过基于图像的深度学习识别医学诊断和可治疗疾病。细胞 172, 1122–1131.e9 (2018).
汉努恩 A. Y. 等人。使用深度神经网络在动态心电图中进行心脏科医生级别的心律失常检测与分类。自然医学杂志 25, 65–69 (2019).
李等人。等。利用算法不确定性解决应用挑战的人工智能工作流程的提议。iScience 25, 103961 (2022).
陈 RJ 等人. 医疗和保健领域人工智能的算法公平性。自然医学与生物工程杂志 7, 719–742 (2023).
布朗,A. 等。使用捷径测试检测公平医疗AI中的捷径学习。自然通讯 14, 4314 (2023).
Char, D. S., Shah, N. H. & Magnus, D. 在医疗保健中实施机器学习——应对伦理挑战。新英氏医学杂志 378, 981–983 (2018).
陈伊扬,乔西,苏米特及 Ghassemi,玛扎娅斯·玛机亚。用人工智能解决健康差异问题。自然医学 26, 16–17 (2020).
吉乔亚,J. W. 等人。医学影像中AI识别患者种族的建模研究。柳叶刀数字健康 4, 406–414 (2022).
赛亚德-卡尔安塔里,L.,张,H.,麦德莫特,M. B. A.,陈,I. Y. & 噶斯塞米,M. 在服务不足的患者群体中应用胸部X光片的人工智能算法误诊偏倚。自然医学 27, 2176–2182 (2021).
帕加诺,T. P. 等人. 机器学习模型中的偏见和不公平:数据集、工具、公平性指标以及识别和缓解方法的系统回顾。大数据认知计算 7, 15 (2023).
马赫什瓦里,G. & 培罗,M.公平梯度下降:意识到公平性的梯度下降算法(arXiv预印本,2022年)
创,C.-Y. & 穆鲁,Y.公平混合:通过插值实现公平性(arXiv预印本,2021年)
Pu伊奥-安东尼,E. 等。心脏MRI图像分析中的公平性:基于深度学习的分割中由于数据不平衡导致的偏差调查。在计算机科学讲座笔记(包括人工智能讲座笔记和生物信息学讲座笔记的子系列)12903 (LNCS, 2021).
Dash, S., Balasubramanian, V. N. & Sharma, A. 评估和缓解图像分类器中的偏差:使用反事实的因果视角。在会议录 — 2022 IEEE/CVF冬季计算机视觉应用大会,WACV 2022(IEEE, 2022).https://doi.org/10.1109/WACV51458.2022.00393.
王,X.等.ChestX-ray8:大规模胸部X光数据库及常见胸部疾病弱监督分类与定位基准.在会议记录 − 2017年IEEE计算机视觉和模式识别大会(CVPR 2017)卷2017-一月(IEEE, 2017)
Johnson, A. E. W. 等人。MIMIC-CXR,一个脱敏的公开可用的胸部X光片数据库,包含自由文本报告。科学数据 6, 317 (2019).
Irvin, J. 等人。CheXpert:一个带有不确定性标签和专家对比的大规模胸部 X 光片数据集。发表于第33届美国人工智能协会人工智能大会(AAAI 2019),第31届创新性人工智能应用会议(IAAI 2019)和第九届美国人工智能协会教育领域人工智能进展研讨会(EAAI, 2019)https://doi.org/10.1609/aaai.v33i01.3301590.
拉腊扎巴尔,A. J.,尼托,N.,彼得森,V.,米勒内,D. H.及费兰特,E. 医学影像数据集中的性别不平衡会产生偏见的计算机辅助诊断分类器。 Proc. Natl Acad. Sci. 117, 12592–12594 (2020).
张, H. 等. 提高胸部X光分类器的公平性. 在机器学习研究会议论文集 174, 204–233 (2022).
宗, Y., 杨, Y. & Hospedales, T.医学影像公平性基准测试(MEDFAIR)(arXiv预印本,2022年)
Martinez, N., Bertran, M. & Sapiro, G. 极小极大帕累托公平性:一个多目标视角。在第37届国际机器学习大会,ICML 2020附件PartF168147-9 (ICLM, 2020).
王明和邓伟。利用倾斜度感知强化学习减轻面部识别中的偏见。在IEEE计算机学会计算机视觉和模式识别会议 proceedings(IEEE, 2020).https://doi.org/10.1109/CVPR42600.2020.00934.
Das, A., Anjum, S. & Gurari, D. 数据集偏差:视觉问答的案例研究。信息科学与技术协会 proceedings 56, 58–67 (2019).
Reddy, C. 等人。通过公平性指标在表征学习中评估偏差缓解算法(NeurIPS,2021)。
马赫什瓦里, G., 贝尔, A., 迪尼斯, P. & 凯勒, M.无等级化公平:一种新的交叉公平性定义 (2023).
里奇·拉拉,M.A.,埃切韦斯特,R.及费南特,E. 医学影像人工智能中的公平性问题研究。自然通讯 13, https://doi.org/10.1038/s41467-022-32186-3 (2022).
弗莱,A. 等人。英国生物银行参与者与普通人群的社会人口学和健康相关特征的比较。美国流行病学杂志 186, 1026–1034 (2017).
Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K. & Galstyan, A. 机器学习中的偏见与公平性调查ACM计算调查期刊 54, https://doi.org/10.1145/3457607 (2021).
克雷因伯格,J.,穆莱纳桑,S.及拉加万,M. 在风险评分的公平确定中固有的权衡。在莱布尼茨国际 информатик斯 proceedings(LIPIcs,2017)
chaudhari, s. j. 性别识别、人类年龄分类和识别的方法学。国际计算机应用杂志. NCAC2015, 5–10 (2015).
何哲,左巍,阚梅,shan shijie,陈xiaoj ie。AttGAN:仅更改所需的面部属性编辑。 注意:“shan shijie”和“陈xiaoj ie”可能不是正确的拼音翻译,请根据实际姓名进行校正。原文中的人名拼写可能为Shan, S. 和 Chen, X., 请确认具体姓名。因此,更准确的翻译应该是: 何哲,左巍,阚梅,shan(S.),陈X(X.)。AttGAN:仅更改所需的面部属性编辑。IEEE Transactions on Image Processing 28, 5464–5478 (2019).
刘,Z等. 二十时代的卷积神经网络。在IEEE计算机学会计算机视觉和模式识别会议 proceedings(IEEE, 2022).
胡,L., 梁,H. & 陆,L. 拼接学习:一种新型的少量样本学习方法。信息科学 552, 17–28 (2021).
王志勇,Simoncelli E. P. & Bovik A. C. 多尺度结构相似性在图像质量评估中的应用。在第三十七届阿西洛马信号、系统与计算机会议,1398–1402 (IEEE, 2003).https://doi.org/10.1109/ACSSC.2003.1292216.
弗里德曼,M. 使用秩次避免方差分析中隐含的正态性假设。美国统计协会杂志 32, 675–701 (1937).
Demšar, J. 多个数据集上分类器的统计比较。机器学习研究期刊(J. Mach. Learn. Res.) 7, 1–30 (2006).
胡,L.等,利用属性中立框架增强AI驱动医疗系统的公平性,Attribute-Neutralizer-for-medical-AI-system。Zenodo, https://doi.org/10.5281/zenodo.13254099 (2024).
致谢
作者对AttGAN的创造者之一何振亮先生表示感谢,感谢他富有洞察力的讨论。作者还感谢广东省人民医院胸外科医生在属性识别方面的支持。此外,作者还要感谢广东省人民医院高性能计算集群(HPC)以及新桥医院生物医学信息研究中心在数值计算中的宝贵支持。本研究的资金来自多个来源,包括中国国家重点研发计划(2019YFB1404803,资助梁慧英),国家自然科学基金一般项目(62076076,资助梁慧英),优秀青年科学基金(82122036,资助梁慧英),数学天元基金(12326612,资助梁慧英),青年科学基金(81903331,资助熊超),武汉市科技局知识创新专项项目(2023020201010198,资助熊超),广东省人工智能医学影像分析与应用重点实验室(2022B1212010011,资助梁慧英),广东省基础与应用基础研究基金(2022A1515110722和2024A1515011750,资助胡连婷),以及广东省医学科学技术研究基金项目(A2023011,资助胡连婷)。
伦理声明
利益冲突
作者声明没有利益冲突。
同行评审
同行评审信息
自然通讯感谢匿名审稿人对此工作的评审所作的贡献。审稿文件可用。
附加信息
出版者附记施普林格·自然对于出版地图和机构隶属关系中的管辖权声明保持中立。
补充信息
权利与许可
开放访问本文根据知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议发布,该协议允许任何形式和格式的任何非商业用途、分享、分发和复制,只要您向原作者和来源提供适当的引用,并在材料中注明是否对其进行了修改。除非另有说明,本文中的图片或其他第三方材料已包含在文章的知识共享许可证内。如果某一材料未包含在此文章的知识共享许可协议之内且您的使用意图不受法律规定允许或超出被允许的范围,则需要直接从版权所有者处获取许可。欲查看此许可证副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/.
关于这篇文章

引用这篇文章
胡,L., 李,D., 刘,H.等式中的其他人或作品中的其他作者等人(通常用在多作者情况下)利用属性中立框架增强人工智能赋能的医疗系统的公平性。自然通讯 15,8767 (2024). https://doi.org/10.1038/s41467-024-52930-1
收到:
接受:
发表:
DOI: https://doi.org/10.1038/s41467-024-52930-1