

谷歌AI推出Tx-LLM:一个从PaLM-2微调而来的大规模语言模型(LLM),用于预测与药物开发相关的许多实体的属性
作者:Sana Hassan
开发治疗药物既耗时又昂贵,通常需要10到15年的时间,并且成本高达20亿美元,而大多数候选药物在临床试验中失败。成功的治疗药物必须满足各种标准,例如靶点相互作用、无毒性以及合适的药代动力学特性。目前的人工智能模型专注于该流程中的特定任务,但其有限的范围可能会影响性能。治疗数据 commons (TDC) 提供了用于帮助人工智能模型预测药物属性的数据集,然而这些模型是独立工作的。擅长多任务处理的大规模语言模型(LLMs)可以通过统一的方法跨多种任务学习,从而在改善治疗药物开发方面展现出潜力。
大型语言模型(LLM),特别是基于变压器的模型,在自然语言处理方面取得了进展,通过在大规模数据集上的自监督学习在各种任务中表现出色。最近的研究表明,LLM可以处理包括回归在内的多种任务,使用参数的文字表示形式。在治疗学领域,专门化的模型如图神经网络(GNN)将分子表示为图形以进行药物发现等功能。蛋白质和核酸序列也被编码以预测结合和结构等属性。随着生物学和化学领域的应用越来越多,像LlaSMol这样的模型以及特定于蛋白质的模型,在药物合成和蛋白质工程任务中取得了令人鼓舞的结果。
谷歌研究和谷歌深度思维的研究人员介绍了Tx-LLM,这是一个从PaLM-2微调而来的通才大型语言模型,设计用于处理多样化的治疗任务。Tx-LLM在涵盖药物发现流程中66个功能的709个数据集上进行训练,使用单一的权重集合来处理各种化学和生物实体,如小分子、蛋白质和核酸。它在43项任务中表现出具有竞争力的成绩,并在22项任务中超过了现有最佳水平。Tx-LLM在结合分子表示与文本的任务中表现尤为出色,并且在不同药物类型之间显示出积极的迁移效果。这个模型是端到端药物开发的重要工具。
研究人员编制了一个名为TxT的数据集集合,包含来自TDC仓库的709个药物发现数据集,重点关注66项任务。每个数据集都经过了指令微调格式化处理,包括四个组成部分:指令、上下文、问题和答案。这些任务包括二元分类、回归和生成任务,并且分子用SMILES字符串表示,蛋白质用氨基酸序列表示。Tx-LLM模型是从PaLM-2通过该数据进行微调的。他们使用AUROC和Spearman相关性以及设置准确度等指标来评估模型性能,并进行了统计检验和数据污染分析以确保结果的稳健性。
Tx-LLM模型在TDC数据集上表现出色,在66个任务中的43个任务中超越或达到了最先进的(SOTA)结果。它在22个数据集中超过了SOTA,并在另外21个数据集中接近了SOTA表现。值得注意的是,当涉及到将SMILES分子字符串与疾病或细胞系描述等文本特征相结合的数据集时,Tx-LLM表现出色,这可能归功于其预训练的文本知识。然而,在仅依赖于SMILES字符串的数据集中,它的表现不佳,此时基于图的模型更为有效。总体而言,这些结果突显了针对涉及药物和基于文本特征的任务进行微调的语言模型的优势。
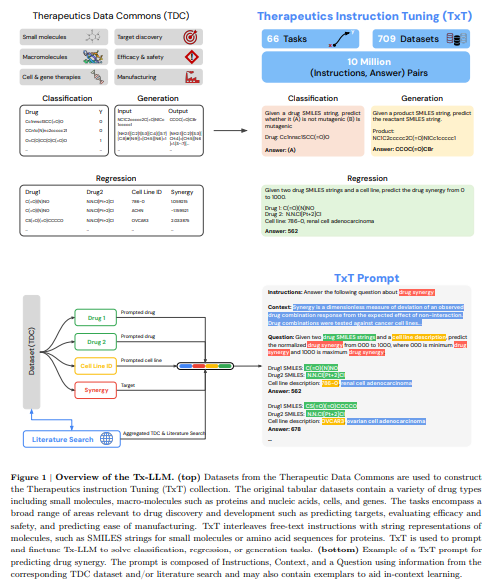
Tx-LLM是首个在多样化的TDC数据集上训练的大型语言模型,这些数据集包括分子、蛋白质、细胞和疾病。有趣的是,在非小分子数据集(如蛋白质)上的训练提高了对小分子任务的表现。尽管通用的大规模语言模型在专门的化学任务方面遇到了困难,但Tx-LLM在回归任务中表现出色,在某些情况下超过了当前最佳模型。该模型显示出从基因识别到临床试验的端到端药物开发的潜力。然而,Tx-LLM仍处于研究阶段,在自然语言指令和预测准确性上存在局限性,需要进一步改进和验证以实现更广泛的应用。
查看一下纸张以及详情此研究的所有荣誉归于该项目的研究人员。也不要忘了关注我们在推特并加入我们电报频道和领英 Group. 如果你喜欢我们的作品,你会爱上我们的新闻通讯..不要忘记加入我们的5万+ 机器学习子论坛
即将举行的活动 - 2022年10月17日 RetrieveX – 生成式AI数据检索大会(推广)

桑娜·哈桑是Marktechpost的咨询实习生,同时也是印度理工学院马德拉斯分校的双学位学生,她热衷于将技术和人工智能应用于解决现实世界中的挑战。怀着解决实际问题的热情,她为人工智能与现实生活解决方案的交汇点带来了全新的视角。