
状态报告
astro-ph.EP 注:这里的"astro-ph.EP"是arXiv.org上天体物理学分类的一个子类别代码,通常不进行翻译,直接保留原样。其中"astro-ph"代表天体物理学,"EP"代表“地球和行星”(Earth and Planets)。若需要解释,则可以补充说明为“天文地球与行星科学”。但按照指示,只输出内容本身则保持原文不变。
2024年10月11日
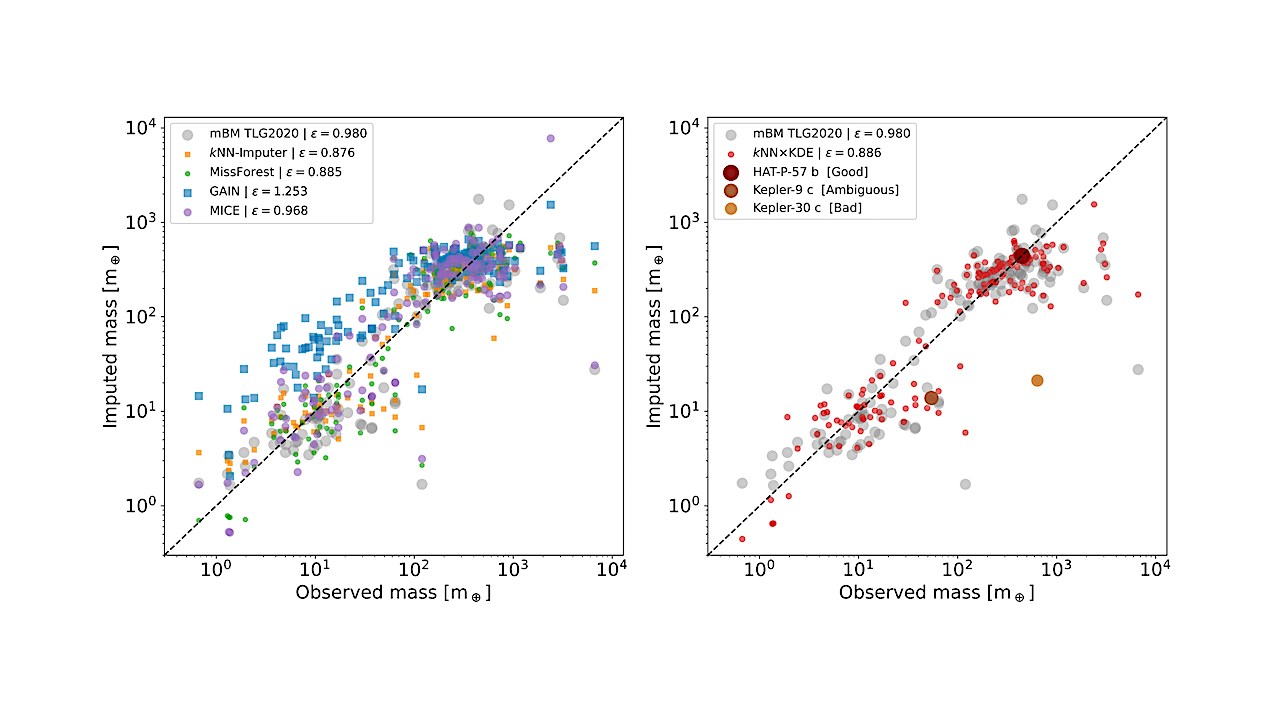
使用完整属性数据集的测试结果,其中将150个测试行星视为凌日观测,并且缺失质量值。左图显示了四个提议的插补算法以及TLG2020中mBM代码的结果。右图展示了mBM代码和kNN×KDE算法之间的观察质量和插补质量的比较。图例显示了所有150个绘制行星的平均误差。对角虚线表示观测值与插补值之间完美的对应关系。右边图例中标记的三颗行星的分布如下所示。 — astro-ph.EP
系外行星档案是一个关于已发现的太阳系外行星性质的信息宝库,但统计分析受到了缺失值数量的限制。最具有信息量的整体属性之一是行星质量,然而由于超过70%的已知行星没有测量其质量值,因此这个参数尤其难以准确测量。
我们比较了五种不同机器学习算法的能力,这些算法可以利用多维不完整数据集来估算缺失的行星质量属性。在使用存档的部分子集(包含六个行星属性)和完全集合(同样包含六个行星属性)的情况下,以及在不完整的六项和八项行星属性集中利用所有行星发现的情况下,对结果进行了比较。
我们发现,即使额外的数据不完整,随着数据的增加,插补结果也会改善,并且可以对任何行星进行大量预测,无论已知哪些属性。我们最青睐的算法是新开发的kNN×KDE算法,它可以为插补属性返回一个概率分布。该分布的形状可以指示算法的信心水平,还可以反映外星系人口的基本特征。
我们通过一系列示例展示了如何用过境法或径向速度法发现系外行星时,这些分布可以被解释。最后,我们测试了kNN×KDE的生成能力,基于档案创建大量的合成行星群,并从多维空间中的属性组识别潜在的行星类别。所有代码都是开源的。
弗洛里安·拉兰德,埃莉扎beth·塔斯克,Kenji Doya
评论:30页,14幅图,1张表。已被《开放天体物理学杂志》接受发表
主题:地球和行星天体物理学(astro-ph.EP);天文仪器与方法(astro-ph.IM);机器学习(cs.LG)
引用格式:arXiv:2410.06922 [astro-ph.EP] (或 arXiv:2410.06922v1 [astro-ph.EP] 为此版本)
https://doi.org/10.48550/arXiv.2410.06922
专注于学习更多
提交历史记录
来自:Florian Lalande
[v1] 2024年10月9日星期三 22:19:33 UTC (4,942 KB)
https://arxiv.org/abs/2410.06922
天体生物学,天文学,

探险者俱乐部会员,前NASA空间站有效载荷经理/太空生物学家,远征队成员,记者,退役登山者,联觉者,纳美人-绝地-弗雷曼人-佛教徒混合体,手语使用者,德文岛和珠穆朗玛峰大本营老将,(他/他) 🖖🏻