

谷歌AI研究人员提出精明的RAG:一种处理大型语言模型不完善检索增强和知识冲突的新颖RAG方法
作者:Asif Razzaq
检索增强生成(RAG)已成为通过将外部知识融入其输出来提升大型语言模型能力的关键技术。RAG方法使LLM能够从外部来源获取额外信息,例如基于网络的数据库、科学文献或特定领域的语料库,从而提高它们在知识密集型任务中的性能。RAG系统可以使用内部模型知识和检索到的外部数据生成更具上下文准确性的响应。尽管具有优势,但RAG系统常常需要帮助来整合检索到的信息与内部知识,这可能导致潜在冲突并降低模型输出的可靠性。
当RAG系统检索外部数据时,总是存在引入无关、过时或恶意信息的风险。与RAG相关的一个重大挑战是不完美的检索问题。这一问题会导致LLM在尝试将其内部知识与有缺陷的外部内容合并时产生不一致和错误输出。例如,研究表明,在实际场景中检索到的段落中有高达70%并不直接包含真实答案,导致通过RAG增强的LLM性能下降。当LLM面临复杂查询或外部来源可靠性不确定的领域时,这一问题会更加严重。为解决这些问题,研究人员专注于创建一个能够有效管理和减轻这些冲突的系统,通过改进整合机制来实现。
传统检索增强生成(RAG)的方法包括了多种策略来提高检索质量和鲁棒性,例如过滤无关数据、使用多代理系统对检索到的段落进行批评或采用查询重写技术。虽然这些方法在改善初始检索方面显示出了一些有效性,但由于它们无法处理检索后阶段内部和外部信息之间的内在冲突,因此存在局限性。结果是,在检索数据的质量可以更好且更一致的情况下,传统方法往往落后于需求,导致错误的响应。研究团队为了填补这一空白,开发了一种能够筛选并选择高质量数据以及整合相互矛盾的知识来源的方法,以确保最终输出的可靠性。
谷歌云AI研究团队和南加州大学的研究人员开发了敏锐的RAG,介绍了一种独特的处理检索增强缺陷的方法。研究人员实现了一个自适应框架,该框架可以动态调整如何利用内部和外部知识。Astute RAG最初从LLM的内部知识中获取信息,这与外部数据是互补的来源。然后通过比较内部知识与检索到的文章进行源感知整合。这个过程通过迭代细化信息来源来识别并解决知识冲突。最终响应基于一致数据的可靠性确定,确保输出不受错误或误导性信息的影响。
实验结果展示了Astute RAG在TriviaQA、BioASQ和PopQA等多样化数据集中的有效性。平均而言,新方法相比传统RAG系统整体准确率提高了6.85%。当研究人员在最坏的情况下测试Astute RAG(即所有检索到的段落都是无用或误导性的)时,该方法仍然显著优于其他系统。例如,在这种情况下,其他RAG方法无法产生准确输出,而Astute RAG达到了接近仅使用内部模型知识的性能水平。这一结果表明,Astute RAG有效地克服了现有基于检索的方法固有的局限性。
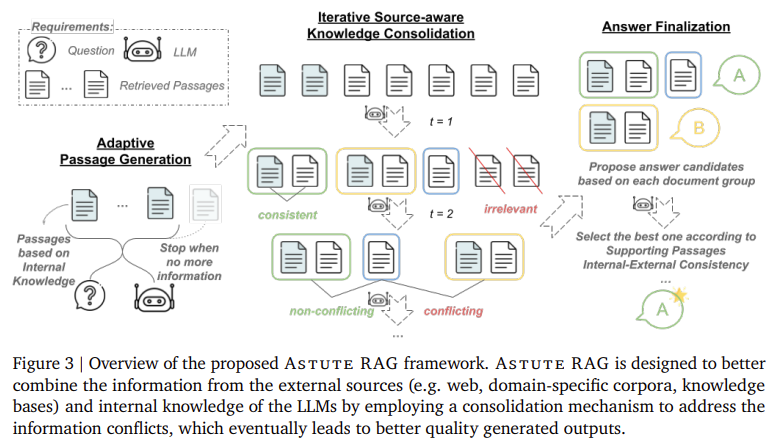
该研究的主要结论可以总结如下:
- 不完美的检索作为瓶颈:该研究将不完美的检索识别为现有RAG系统失败的重要原因。它强调了他们在研究中发现的70%的检索段落并不包含直接答案。
- 知识冲突:研究发现,19.2%的情况下内部和外部来源之间存在知识冲突,其中47.4%的冲突仅通过内部知识得到了正确解决。
- 在各种数据集上的表现:经过三次迭代的整合,Astute RAG 在 TriviaQA 中实现了 84.45% 的准确率,在 BioASQ 中实现了 62.24% 的准确率,超过了表现最佳的基线 RAG 方法。
- 最坏情况下的鲁棒性:该方法即使在所有外部数据都具有误导性的情况下仍能保持高性能,展示了其稳健性和处理知识冲突极端情况的能力。
- 迭代知识巩固:敏锐的RAG通过多次迭代精炼信息,成功过滤掉了不相关或有害的数据,确保LLM生成可靠和准确的响应。


总之,Astute RAG 通过引入一个自适应框架来解决检索增强生成中知识冲突的关键挑战,该框架能够有效整合内部和外部信息。这种方法减轻了不完美检索的负面影响,并增强了大型语言模型在实际应用中的鲁棒性和可靠性。实验结果表明,Astute RAG 是一种解决现有 RAG 系统局限性的解决方案,尤其是在外部来源不可靠的复杂场景中。
查看一下纸张此研究的所有功劳归于该项目的研究人员。也不要忘了关注我们在推特并加入我们电报频道和领英oup. 如果你喜欢我们的作品,你会爱上我们的通讯Newsletter别忘了加入我们50k+ 机器学习子论坛
即将举行活动 - 2022年10月17日 RetrieveX – 生成式AI数据检索大会(推广)

阿西夫·拉扎克是Marktechpost Media Inc.的首席执行官。作为一名具有远见的企业家和工程师,阿西夫致力于利用人工智能为社会带来益处。他最近的一项努力是推出了一个人工智能媒体平台——Marktechpost,该平台以深入报道机器学习和深度学习新闻而著称,这些内容不仅技术上严谨而且易于广大受众理解。该平台每月的浏览量超过200万次,彰显了其在观众中的受欢迎程度。