

苹果公司的AI研究人员质疑OpenAI关于o1推理能力的说法
作者:Matthias Bastian
苹果研究人员的一项新研究,包括著名人工智能科学家Samy Bengio在内,对当今大型语言模型的逻辑能力提出了质疑——甚至是OpenAI的新“推理模型”o1。
由梅赫拉德·法拉贾巴尔领导的团队创建了一个新的评估工具,名为GSM-Symbolic。该工具有基于GSM8K数学推理数据集,并添加了符号模板以更全面地测试AI模型。
研究人员测试了开源模型,如Llama、Phi、Gemma和Mistral,以及包括OpenAI最新产品在内的专有模型。结果,发表在arXiv上建议即使是领先模型,如OpenAI的GPT-4也并不使用真实的逻辑,而只是模仿模式。
添加无关信息会降低性能
结果表明,当前GSM8K的准确率评分不可靠。研究人员发现性能存在很大差异:例如,Llama-8B模型的得分在70%到80%之间波动,而Phi-3则在75%到90%之间变化。Farajtabar表示,对于大多数模型来说,在GSM-Symbolic上的平均表现低于原始GSM8K。
广告
解码者通讯newsletter
最重要的人工智能新闻直接发送到您的邮箱。
✓ 每周
✓ 免费
随时取消
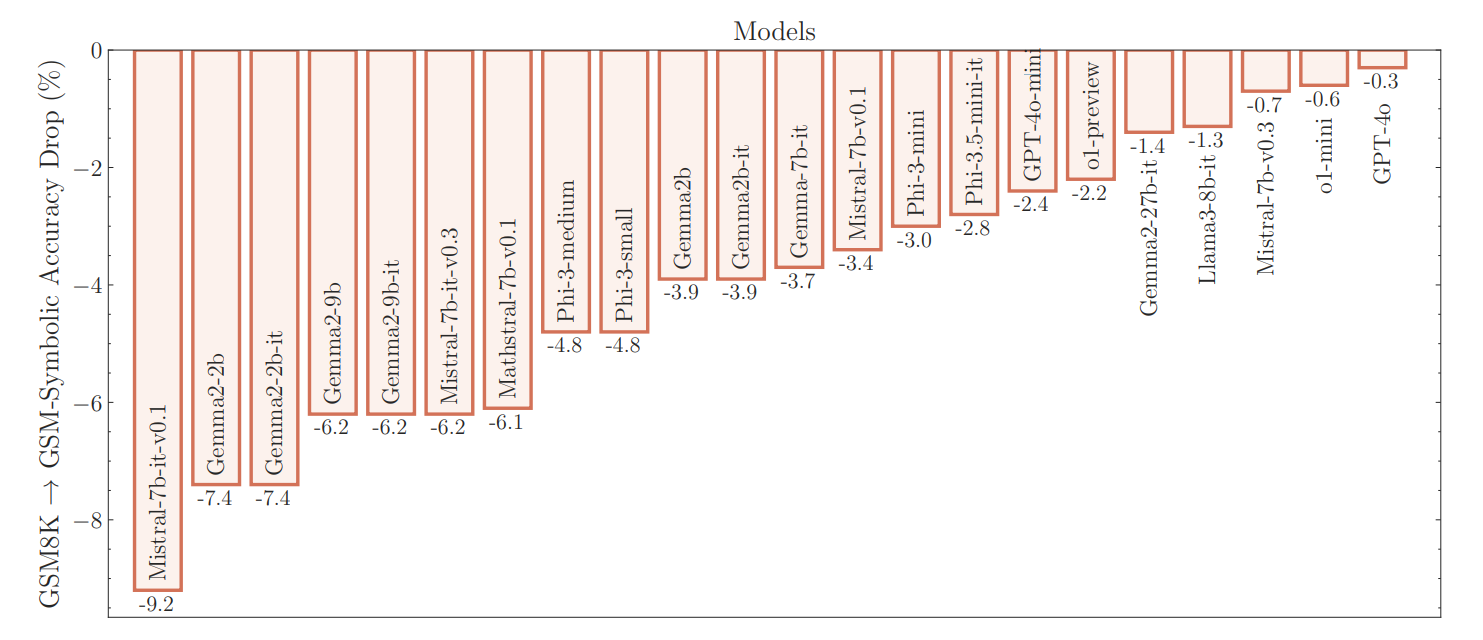
使用GSM-NoOp数据集的实验特别具有启示性。在这里,研究人员向一个看似相关的文本问题中添加了一个但实际上并未对整体论点做出贡献的单个陈述。
结果是所有模型的性能都下降了,包括OpenAI的o1模型。"如果我们只改变名字,一个小学生成绩是否会波动约10%?"法拉杰塔巴尔反问道.

法拉杰塔巴尔强调真正的問題是,隨著任務難度僅略微增加,表現的變異性大幅上升且性能下降。要應對隨著難度增加而產生的變化可能需要“指數級更多的數據”。
扩展只会导致更好的模式匹配器
虽然开放AI o1系列,该模型在许多基准测试中取得最高分数,表现更好,但它仍然存在性能波动并会犯“愚蠢的错误”,显示出同样的根本弱点。这一发现表明由另一项最近发表的研究支持.
总体而言,Farajtabar总结说,在语言模型中没有发现形式推理的证据。“他们的行为更可能是由复杂的模式匹配来解释的。”扩大数据、参数和计算能力将导致更好的模式匹配器,但“不一定能成为更好的推理者。”

该研究还质疑了大型语言模型基准的合理性。根据研究人员的说法,广受欢迎的GSM8K数学基准测试中大幅改进的结果——大约三年前GPT-3得分为35%,而目前的模型得分可高达95%——可能是由于训练数据中包含了测试示例。
这个想法有以下支持证据或依据:最近的一项研究显示,较小的人工智能模型在泛化数学任务方面表现较差。可能是因为他们在训练时看到的数据较少。
超越模式识别
苹果的研究人员强调,理解大型语言模型(LLM)的真实推理能力对于其在现实世界场景中的应用至关重要,特别是在准确性与一致性要求很高的领域——包括人工智能安全、对齐、教育、医疗保健和决策系统。
“我们认为进一步的研究对于开发具备形式推理能力的AI模型是必不可少的,这些模型需要超越模式识别,实现更为稳健和通用的问题解决技能,”该研究结论指出。这是通往拥有类似人类认知能力或通用智能的系统的关键挑战。
AI研究员弗朗索瓦·丘列特将苹果公司的这项研究描述为“堆积如山的证据中又一个证据。”科勒说,LLM缺乏逻辑能力在2023年初还是一个“极其异端的观点”——现在它正变得成为一种“显而易见的常识”。
人工智能研究中的辩论
这项研究有趣的地方在于,两大人工智能研究机构苹果和OpenAI持对立立场。OpenAI认为o1是第一个推理模型(级别2)这为逻辑代理(第三级)奠定了基础,这本应是OpenAI的下一个增长领域.
苹果研究人员的论点被弱化了,例如,由一个新的OpenAI基准测试显示o1可以解决机器学习工程任务OpenAI声称明确排除了测试示例作为训练数据。另一项研究得出结论认为AI模型至少进行某种概率推理.
这些差异的一个原因可能是诸如智能、推理和逻辑之类的术语含糊不清,可以在不同情境中变化或以不同程度出现,或者在机器逻辑的情况下,可以采取新的形式.
最终,如果未来的AI模型能够可靠地解决它们被赋予的任务,这种学术讨论将会退居幕后——而这正是估值超过150亿美元的OpenAI需要证明。