

这篇AI论文介绍了对大规模模型合并技术的全面研究
作者:Nikhil
模型合并是机器学习中的高级技术,旨在将多个专家模型的优势结合成一个更强大的单一模型。这一过程使得系统能够从各种模型的知识中受益,并减少大规模个体模型训练的需求。合并模型可以降低计算和存储成本,并提高模型在不同任务上的泛化能力。通过合并,开发人员可以利用分散式开发模式,即不同的团队独立构建专家模型,然后将这些模型结合起来以增强整体系统的性能。
一个重要的挑战是模型合并的可扩展性。大多数研究集中在规模较小的模型上,通常只合并少量的专家模型,一般为两到三个。随着模型的增大以及专家模型数量的增加,并集操作的复杂度也随之上升。关键问题是如何高效地合并更大规模的模型而不牺牲性能。另一个关注点是诸如基础模型质量等因素——即基础模型是否经过预训练或针对特定任务进行了微调——如何影响合并后模型的表现。随着社区开发出越来越大规模和复杂的模型,理解这些因素至关重要。
当前的模型合并方法包括简单的技术,如平均专家模型的权重,以及更复杂的方法,如任务算术,其中会调整特定于任务的参数。然而,这些方法仅在小型模型上进行了测试,通常参数数量不超过70亿,并且通常只涉及少数几个模型的合并。尽管这些方法已经取得了一些成功,但它们在大规模模型上的有效性尚未进行系统的评估。此外,这些方法对于未见过的任务泛化能力仍需进一步探索,特别是在处理多个大型模型时。
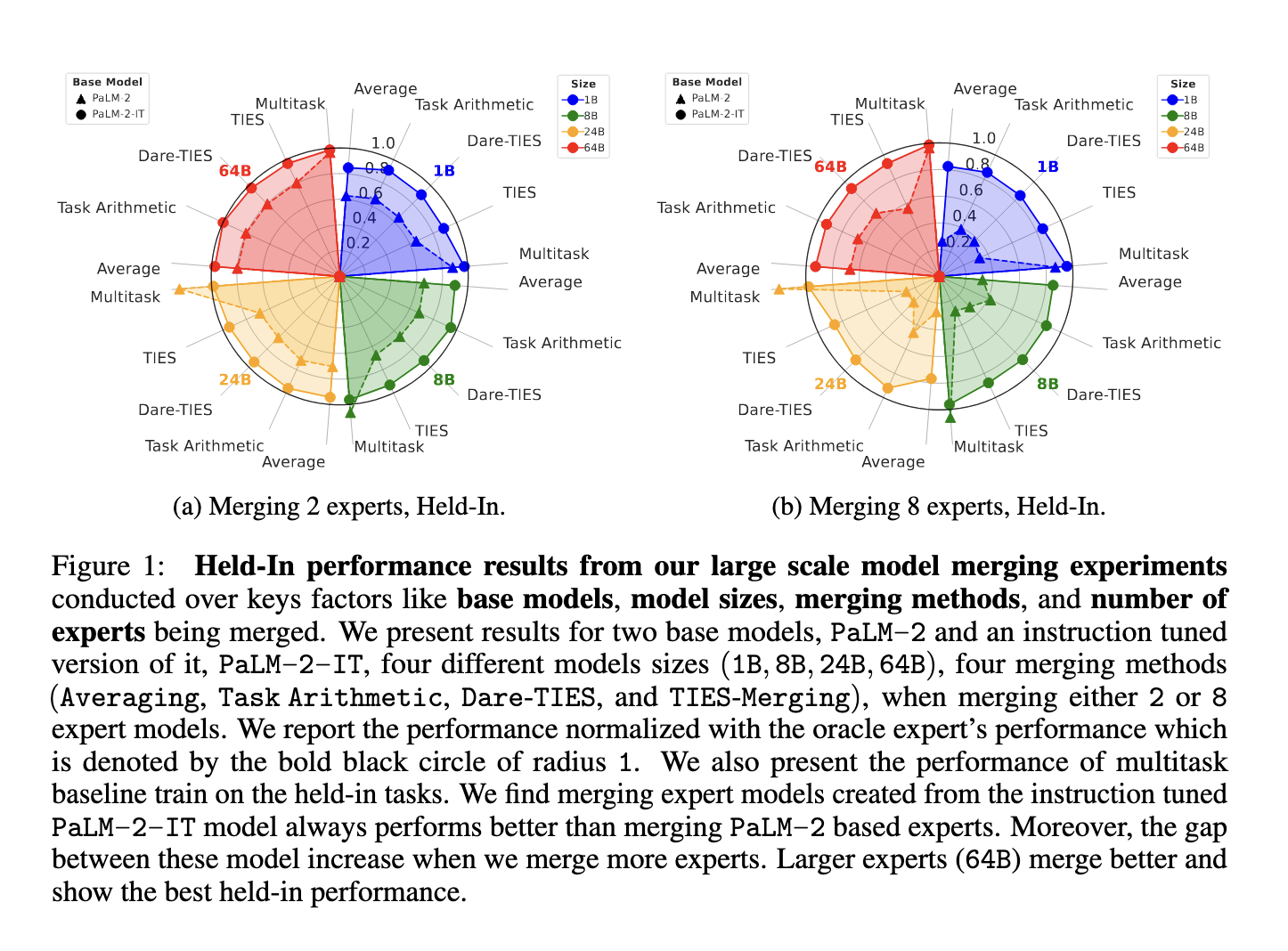
来自北卡罗来纳大学教堂山分校、谷歌和弗吉尼亚理工学院的一个研究团队介绍了一项全面的研究,评估大规模模型合并。研究人员探索了从10亿到640亿参数的模型合并,并使用多达八个专家模型进行各种配置。他们评估了四种合并方法:平均法、任务算术法、Dare-TIES和TIES-合并。此外,他们还试验了两个基础模型,PaLM-2和PaLM-2-IT(PaLM-2的指令调优版本)。他们的目标是研究基础模型质量、模型大小以及被合并专家的数量等因素如何影响合并后模型的整体有效性。这项大规模评估是首次系统地尝试在此规模上评估模型合并的研究之一。
研究人员在其方法中使用了针对特定任务进行了完全微调的专家模型。然后将这些模型合并,以评估它们在保留任务(即训练专家的任务)和未见过的任务(用于零样本泛化的任务)上的表现。合并技术包括修改任务特定参数或使用简单平均来组合模型。作为参考点,使用了基础模型的指令微调变体PaLM-2-IT,以检查指令微调是否提高了在合并后模型的泛化能力。这种方法允许系统地分析模型大小、专家数量和基础模型质量对合并成功的影响。
该研究的结果揭示了几项重要的见解。首先,他们发现较大的模型(如具有640亿参数的模型)更容易合并,而较小的模型则不然。合并显著提高了模型的泛化能力,特别是在使用指令微调的模型(例如PaLM-2-IT)时更为明显。例如,在合并八个大型专家模型后,组合后的模型在未见过的任务上表现优于多任务训练的模型,并且性能更高。具体来说,结果表明从PaLM-2-IT中合并的模型比从预训练的PaLM-2中合并的模型具有更好的零样本泛化能力。此外,随着模型大小的增加,不同合并方法之间的性能差距缩小,这意味着即使简单的技术(如平均)对于大型模型也可能是有效的。研究者还注意到,在不超过八个专家模型的情况下进行更多模型合并可以实现更好的泛化而不会显著降低性能。

性能指标显示,规模更大且经过指令调整的模型具有明显优势。例如,将来自640亿参数PaLM-2-IT模型的八个专家模型合并后,其效果超过了用于提升泛化的传统多任务训练基准线。研究指出,在所有评估中,指令调整后的模型表现更佳,并在零样本迁移学习上对未见过的任务表现出更好的结果。合并后的模型比单独微调的专家模型更能适应新任务。
总之,研究团队的研究表明,模型合并,特别是在大规模的情况下,是创建高度通用的语言模型的一种有前景的方法。研究结果表明,指令微调的模型显著地促进了合并过程,尤其是在提高零样本性能方面。随着模型的增长,像本研究中评估的那种合并方法对于开发可扩展和高效的系统以应对各种任务将变得至关重要。该研究为从业者提供了实用见解,并为进一步研究大规模模型合并技术开辟了新的途径。
查看一下纸张此研究的所有功劳都归于该项目的研究人员。也不要忘了关注我们的社交媒体平台推特并加入我们电报频道并且领英 Group. 如果你喜欢我们的工作,你会爱上我们的通讯newsletter..(注意:"newsletter"保留英文原词,因为可能在中文语境中直接使用其英文形式)不要忘了加入我们5万+ 机器学习子论坛
即将举行的活动 - 2022年10月17日 RetrieveX – 生成式人工智能数据检索大会(推广)

尼基尔是Marktechpost的一名实习顾问。他在印度理工学院卡拉格普尔分校攻读材料科学的综合双学位。尼基尔是一名人工智能/机器学习爱好者,总是致力于在生物材料和生物医学等领域研究应用。凭借强大的材料科学背景,他正在探索新的进展并创造机会作出贡献。