
一种用于检测死亡调查笔记中自杀情况不一致性的自然语言处理方法
作者:Peng, Yifan
介绍
近年来,美国自杀死亡人数出现了令人担忧的增长,在2000年至2021年间,自杀率上升了36%。1了解自杀的情况对于有效的干预和预防自杀的政策制定是至关重要的。
国家暴力死亡报告系统(NVDRS)是一项全面的监测计划,从美国所有50个州、华盛顿特区和波多黎各收集暴力致死数据。2它详尽地记录了自杀受害者的相关信息,包括人口统计学特征和关键的社会决定因素(SDoH)。数据库还包含了每起事件的死亡调查笔记,描述了可能导致自杀的情境。NVDRS对一系列自杀情境变量进行了编码。3这些是由人工摘要者利用死亡调查记录中的信息手动标注的。4这些自杀情境变量表明了与自杀相关的社会因素的存在状态(例如,家庭关系危机、心理健康危机和身体健康危机)。NVDRS提供了一本标准化的编码手册以维持数据质量,并为注释员(即摘要提取人员)提供了常规编码培训。然而值得注意的是,只有5%的事件注释由两位独立的注释员进行了验证,而剩余的95%的数据则依赖于单一注释员的评估。4这种缺乏同行验证过程增加了在州级甚至州内级别上标注不一致的风险。此外,尽管标注人员遵守编码指南,但由于可能存在的专业知识差距和人为错误,仍存在标注不一致的潜在可能性。5.
在我们之前的研究中,我们开发了自然语言处理(NLP)方法从NVDRS叙述中提取自杀情况3我们的研究突出了各州之间表现的差异,并提出了对NVDRS数据注释不一致性的担忧。若干研究探讨了通过各种方法解决NLP中数据标注错误的问题。6,7,8,9,10,11,12,13例如,利用传统的概率方法14训练机器学习模型(例如支持向量机)15,16,17,18,19,20,21,22并通过主动学习开发生成模型23然而,传统的概率方法无法处理罕见事件或比较概率相似的事件。这主要是因为这些概率难以高置信度地计算和比较。同时,传统的监督训练模式在训练过程中需要高质量的标注数据。这对于应用到NVDRS数据集时是一个限制,因为在该数据集中只有5%的数据由两位标注员进行了验证。然而,之前的努力主要集中在一般领域的NLP任务上,如词性标注(POS)和命名实体识别(NER)。这些方法不能直接应用于识别自由文本死亡调查记录中的错误标签。
本研究介绍了一种基于变压器模型的实证自然语言处理方法,用于检测死亡调查记录中潜在的数据标注不一致。在我们的评估中,我们测量了所有美国州份自杀情况下的注释差异。在这里,我们将被评估的州称为“目标州”,其他所有州称为“其他州”。对于每个自杀情况变量,我们都训练了一个基于变压器的二元分类器。3使用从目标状态和其他状态采样的数据。然后,我们通过在排除目标状态的训练数据后重新训练分类器来评估标注不一致性的变化,以此确定F-1分数的变化情况。我们还设计了一个类似交叉验证的框架以识别导致这些不一致的问题数据实例。这些问题实例经过人工修正之后,我们再次训练了分类器以评估修正的有效性。在这项工作中,我们使用F-1分数作为比较的基础评价指标。F-1分数是精度(真正例预测占所有正例预测的比例)和召回率(真正例预测占所有实际正例的比例)的调和平均值,它将精度和召回率综合为一个单一的数值。较高的F-1分数表明模型性能更好。最后,我们分析了不同人口亚群体(年龄、性别、种族)的比值比(OR),以更好地理解偏见风险。
我们的实验表明,我们的方法在识别NVDRS死亡调查记录中的潜在标注错误方面是有效的。此外,纠正这些错误可使平均F-1得分提高3.85%。总之,我们旨在增强对NVDRS中未结构化死亡调查笔记中存在的注释不一致性的理解。通过解决这些不一致性,我们希望促进使用NVDRS数据来发现自杀情况,从而进行纵向变化分析和趋势分析,并帮助制定国家级、州级和地方层面的针对性自杀预防策略。
方法
数据源
本研究使用了国家暴力死亡报告系统(NVDRS)的数据集,涵盖了从2003年到2020年间在美国所有50个州、波多黎各和哥伦比亚特区记录的267,804起自杀死亡事件。2为了访问NVDRS数据集,研究人员必须满足一定的资格要求,并采取措施确保保密性和数据安全。我们的研究获得了NVDRS受控访问数据库(RAD)提案的批准,该提案授予我们访问数据并开展此处描述的工作所需的权限。我们还获得了威尔康奈尔医学研究院机构审查委员会对研究项目23-12026810-01的批准,该项目名为“使用AI/ML应对自杀危机”。
每个事件实例都附带两份死亡调查记录,一份来自法医(CME)视角,另一份来自执法部门(LE)视角。NVDRS为每个事件包含超过600个独特的数据元素,包括识别自杀危机的要素——即发生在自杀身亡前两周内的导致自杀发生的诱发事件。4自杀危机的例子包括家庭关系、身体健康和心理健康危机。自杀危机是根据CME和LE报告的内容进行标注的。数据标注员(即摘要者)从预定义的危机列表中选择,并且必须为每次事件编码所有已知的相关危机。如果CME报告或LE报告中表明存在某种危机,标注员必须在数据库中确认并记录这一危机。4.
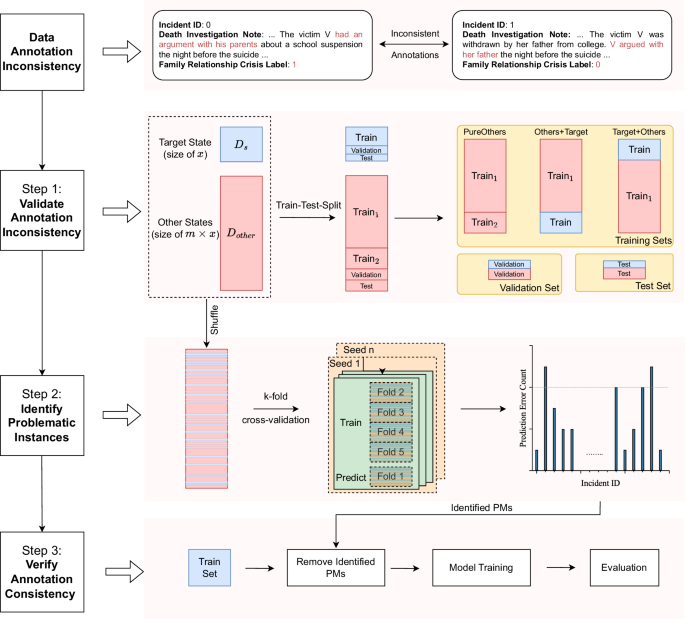
本研究有三个任务:验证跨状态注释不一致,识别导致这些不一致的具体数据实例,并在移除已识别的问题数据实例后验证注释一致性是否有所改善。我们介绍了我们的方法并使用三种危机作为示例进行实验:家庭关系危机、心理健康危机和身体健康危机(按状态统计的详细信息见表)1这些变量因其在NVDRS数据集中正例较多以及先前工作中显示的分类效果较差而被选中。3这些三种危机的定义和例子可以在补充表中找到。1我们也通过数据预处理解决了NVDRS数据集中的正负类不平衡问题。首先,排除了阳性实例少于10个的州,以确保有足够的训练数据。接下来,对于每个危机事件,我们为每个州创建了一个平衡的类别分布,保留所有的阳性实例,并对阴性实例进行下采样,确保两类数量相等。
验证标注不一致性
受曾等人的启发13我们的方法基于这样的假设,即如果两个数据集的标签标注一致,那么分别在这两个数据集上训练出来的模型在应用于对方数据集时应该表现出相同的预测能力。实际操作中,给定一个数据集D如果我们使用它的子集之一来训练模型以预测剩余部分,我们预计两个子集的评估性能将是相当的。
基于这一假设,我们首先探索目标状态下的标签标注是否成立s与所有其他州的一致(图中的步骤1)1具体来说,给定目标状态的标注数据\(D_s \subset D\)(哪里Ds大小为x我们采样m独占子集(每个子集的大小为)x从其他州的标注数据中,表示为D其他值得注意的是\(D_s \cap D_{其他} =\)∅.

在第一步中,其他州的大小{{Train}}_{2}设置等于目标状态的大小火车设置,确保三个新的训练集大小相同。在步骤2中,k进行-fold交叉验证程序重复执行n多次使用不同的随机种子。对于每个数据实例,我们记录了其预测错误计数,并最终通过阈值化预测错误计数来识别有问题的实例。PM 潜在错误。
然后我们将其拆分Ds以及D其他分别将数据集划分为训练集、验证集和测试集,比例为8:1:1,并构建三个相同大小的训练集:(1) PureOthers仅包含来自目标州以外的样本;(2) Others+Target结合其他州和目标州的样本;(3) Target+Others同样结合目标州和其他州的样本。对于每个训练集,我们使用基于变压器的二元分类器进行训练,具体采用的是来自Transformer的双向编码表示(BERT)模型。24我们的目标是对比不同训练集组合之间的分类性能。具体来说,我们评估每个州与其他各州在身体健康、家庭关系和心理健康危机注释上的不一致情况。为了量化这种不一致性,我们计算了ΔF在目标状态和其他州的测试集上,不一致性被测量为使用混合训练数据(Others+Target和Target+Others)训练的模型的平均F-1得分与仅使用其他州的数据(PureOthers)训练的模型的F-1得分之间的差异。
$$\triangle F-1=({差异})\left({F-1}_{{混合}}-{F-1}_{{纯其他}}\right)$$
(1)
$${F-1}_{{混合}}=\text{平均值}\left({F-1}_{{其他}+{目标}},{F-1}_{{目标}+{其他}}\right)$$
(2)
当将目标状态的数据纳入训练时,使用更大的正样本ΔF在目标状态的测试集上为-1,伴随一个较小的负数ΔF在其他州的测试集上得分为-1,表示目标州与其他州之间的标注不一致更为明显。
识别有问题的实例
识别目标状态中可能导致标签不一致的问题数据实例Ds以及D其他,我们介绍了一个k五折交叉验证方法(图中步骤2)1参考王等人方法的做法21我们的方法涉及以下步骤:我们将拼接Ds以及D其他将其合并成一个数据集后,我们随机打乱数据以确保其充分混合,然后将打乱后的数据集划分成k折。每个独特的折被当作hold-out集处理,而其余的部分则作为剩余的数据集。k-1折用作训练集。我们为每个折训练独立的自杀情况分类器,以识别其中的问题实例。在整个过程中,每个单独的数据样本都会被分配到一个特定的折中,在交叉验证期间保持不变。这确保了每个数据样本在保留集中只使用一次,并且对模型的训练有所贡献。k-1次。对于hold-out集中的每个数据样本,我们将模型的预测与真实标签进行比较,并统计差异的数量。
为了减少随机性并增强研究结果的可靠性,我们重复了实验k-折交叉验证过程多次(即,n多次重复(根据给定的次数),在每次迭代中使用不同的随机数据分区和独立的随机种子。然后,对于数据集中的每个数据实例,我们得到n估计。我们用符号表示ci (0 ≤ ci≤n) 作为一个数据实例出现的次数xi被标记为可能存在标签错误的n估计。这个数量ci表示置信水平 rằngxi可能包含标注错误。随后,我们对每个数据样本的预测错误计数应用阈值机制来处理这个问题。Ds这一阈值设定使我们能够有效识别并标记那些反复显示不一致性的数据实例。
验证标注一致性
一旦我们识别出有问题的数据实例在Ds我们的下一步是评估这些潜在错误是否对模型的性能产生负面影响。为此,我们将系统地从训练数据集中移除被识别为潜在错误的数据实例。通过移除这些实例并重新训练模型,我们可以评估这些潜在错误对模型性能的影响(图中的步骤3)。1为了衡量这些移除的有效性,我们引入了一个随机基线进行比较,该基线从训练集中随机移除了与那些被识别为有问题的实例相同数量的实例。
在另一个方面,我们的工作扩展到潜在错误的手动校正。在识别出潜在错误后,我们招募了两位标注员来手动识别和纠正实际的误标。实际的误标被定义为两位标注员将原始注释标记为不正确的实例。两名标注员接受了根据NVDRS编码手册进行标签标注的培训,并通过讨论解决了分歧。我们的目标是展示一致性的标注如何提高分类器的表现。我们采用了一种增量训练范式,使用四个训练集来演示这一点(图)。2): 其他州加目标州,包含其他州的数据和目标州的原始数据;其他州加修正后的目标州,包含其他州的数据和修正后的目标州的数据;目标州加其他州,包含目标州的原始数据和其他州的数据,以及修正后的目标州加其他州,包含修正后的目标州的数据和其他州的数据。

四种训练数据的组合被展示。对于每种训练数据的组合,我们将它输入增量训练范式中。T是步长,和N是目标状态下数据实例的总数量s以及其他州。
对于每个训练集,我们逐步以增量的方式并采用一定的步长加入更多的训练样本。T为了更细致地观察修正后的数据对模型性能的影响。我们训练分类模型并在测试集上分析其表现。这一过程有助于验证标签的一致性和修正数据的有效性。我们将所有实验重复进行n=5次使用不同的随机种子。
偏倚风险分析
为了更好地理解数据标注中的偏见风险,我们采用了逻辑回归模型来考察在剔除已识别错误后,自杀情况与人口统计变量(即种族、年龄和性别)之间的关系是否发生了变化。NVDRS根据死亡证明(DC)记录受害者事件发生时的性别。NVDRS遵循美国卫生与公众服务部(HHS)和管理与预算办公室(OBM)关于种族/族裔分类的标准,这些标准定义了联邦报告中收集和呈现有关种族和族裔数据的标准。在这项工作中,我们遵循HHS标准,并使用两个类别来划分族裔(西班牙裔或拉丁裔、非西班牙裔或拉丁裔),并根据OMB和HHS的标准使用五个类别来划分种族数据(美洲原住民或阿拉斯加土著人、亚洲人、黑人或非洲美国人、夏威夷原住民或其他太平洋岛民、白人)。为每种自杀情况开发了一个独立的逻辑回归模型。
具体来说,预测变量代表了特定的比较组(即黑人、年轻人(年龄在24岁以下)、女性),并被编码为1。然后将该比较组与参考组(即白人、成年人、男性)进行对比,后者被编码为0。我们使用从相应的逻辑回归模型中获得的预测变量系数估计值来计算每个比较组的比值比(OR)。OR量化了特定情况在比较组相对于参考组发生的可能性。OR的计算方法如下:\(OR=e^{比较组系数估计}\)OR大于1表示对照组的情况发生率高于参考组。我们进一步基于系数估计的标准误差和Z分数计算了每个OR的95%置信区间(CI)。
$${下限置信区间}={e}^{系数估计}-Z\times{标准误差},$$
$${较高CI界值}={e}^{系数估计}+Z\times {标准误差}$$
对于两个说明州(俄亥俄州和科罗拉多州),我们在三组标注中计算了每个情境变量的比值比:来自NVDRS的原始标注,去除我们方法识别出的错误后的标注,以及随机删除相同数量实例后的标注。通过比较不同标注集合中同一子组的比值比,我们可以检查自杀情境与人口统计学变量之间的关系是否发生了变化。
统计与可重复性
在这项研究中,我们使用了BioBERT25作为我们的骨干模型,以其业界领先的表现而著称,如我们先前的研究所示。3BioBERT 可以处理最多包含 512 个令牌的序列,并生成 768 维的表示。大约有 5.1% 的 NVDRS 数据输入长度超过了 512 个令牌,在输入 BioBERT 前被截断了。我们将自杀危机检测视为一个文本分类问题,通过将 CME 和 LE 注释连接起来并馈送到 BioBERT 中进行训练,以判断文本中是否提到了感兴趣的自杀危机。我们在 BioBERT 上添加了一个完全连接的层用于分类。
对于每个危机,排除了阳性病例少于10例的州,以确保有足够的训练数据来验证标注的一致性。在实验中,我们进行了抽样m =从其他州的标注数据中抽取了4个独占子集。我们进行了五次实验(n= 5) 来在实现可靠评估和保持合理运行时间之间取得平衡。这也确保了训练集和测试集中包含足够的变化。每次迭代使用不同的随机种子,并报告微平均F-1分数的范围以及平均值。对于问题实例发现,我们选择了k= 5 для (此处上下文不全,不确定"for"后的具体含义,故保留原词)k-折交叉验证,遵循常见的机器学习实践。预测结果与真实标签之间的差异频率越高,错误的真实标签概率越大。我们将阈值设置为5,有效地将潜在错误的数量最小化。
在我们之前的研究中,我们将基于BERT的模型应用于NVDRS叙述中的危机分类。3我们在本研究中选择了身体健康、家庭关系和心理健康危机,因为与其他危机相比,这些危机的正面案例频率更高,且ROC曲线下的面积(AUC)评分较差(表)2和图。2在王等人的研究中3类似地,我们选择了俄亥俄州和科罗拉多州作为示例州,因为它们的阳性实例频率较高,并且在各州分类F-1分数方面优于其他州(表)A2并且A3在王等人的工作中3).
二元交叉熵损失和Adam优化器在模型训练中被使用。我们对所有模型进行了30个周期的训练,并根据它们在验证集上的表现来选择模型。框架是用PyTorch实现的。我们在Intel Xeon 6226 R 16核处理器和Nvidia RTX A6000 GPU上进行了实验。
报告摘要
有关研究设计的进一步信息可在以下位置获取:自然科研报道摘要与此文章相关联。
结果
验证标注不一致性
图3(补充数据)1)显示△F在目标状态(↑)和其他状态(↓)的测试集上的表现。见图。3(a)物理健康危机的结果显示,当目标州的数据添加到训练集中时,大约有83.7%(43个州中有36个)的州在预测目标州测试集的表现上有所提升(通过正值表示)△F‒1),而大约69.8%(43中的30个州)在其他州的测试集上表现下降(由负值表示)△F‒1).

a ΔF在物理健康情况下测试集的结果为-1,b) ΔF在家庭关系情境下的测试集上,(-1)'sc) ΔF在心理健康情况下测试集上的结果为-1。
在图中 fig. (注意:“fig.”在这里通常用于标明图表,可以保留原样或根据上下文理解替换为“图”)3b家庭关系危机的结果显示,在训练中包含目标州的数据时,40个州中有13个州(占32.5%)在目标州的测试集上提高了预测性能。相比之下,40个州中有16个州(占40%)在其他州的测试集上的表现下降。
在图中(fig.)3C精神健康危机的发现表明,在将目标州的数据纳入训练后,大约有33.3%(39个州中的13个)的州在其目标州的测试集上预测性能得到了提升。相比之下,约43.6%(39个州中的17个)的州在其他州的测试集上的表现有所下降。
发现有问题的实例
图 (如果这是全部内容,有时“Figure”确实只是一个表示“图”的标签,在没有具体描述的情况下,“图”已经足够传达其含义。)4(补充表)2)展示了两个示例状态俄亥俄州和科罗拉多州的预测误差计数分布(对数尺度,以提高可读性)。表2提供了一个关于这些有问题的数据实例的详细统计摘要。在俄亥俄州,我们的问题实例发现方法在1077个家庭关系危机标注中发现了159个潜在错误(占比14.8%),在2328个身体健康危机标注中发现了324个潜在错误(占比13.9%),以及在9654个心理健康危机标注中发现了143个潜在错误(占比1.5%)。对于科罗拉多州,我们的方法则在3315个家庭关系危机标注中检测到了254个潜在错误(占比7.7%),在6019个身体健康危机标注中找到了294个潜在错误(占比4.9%),以及在8534个心理健康危机标注中发现了168个潜在错误(占比2.0%)。

a物理健康状况下的预测误差计数分布(对数尺度):b家族关系情境下的预测误差计数分布(对数尺度)c精神健康状况下的预测误差计数分布(对数刻度)。预测误差计数等于5的数据实例将被识别为潜在错误。
验证标注一致性
图5详细的F-1评分见表3) 视觉上展示了我们的标注一致性验证结果。在从俄亥俄州的数据中移除潜在错误后,我们在其他各州的测试集上观察到了每个危机平均微F-1分数的显著提升。相比之下,随机基线对于三种危机的表现改进较小。具体来说,在家庭关系危机中,移除潜在错误后的评分由0.695提高到0.713,而采用随机删除后的评分则从0.695增加到了0.701。在身体健康危机中,移除潜在错误后评分由0.645提升至0.664,相比之下,随机删除后的评分则从0.645增加到0.654。对于心理健康危机,移除潜在错误之后的评分为0.571提高到了0.600,而采用随机删除后,则是从0.571增加至0.585。

a使用“原版”(在移除识别出的潜在错误之前)和“去除潜在错误”(在移除识别出的潜在错误之后)训练的模型在身体状况下的F-1分数比较,(b在家庭关系情境下,使用“原版”(在移除识别出的潜在错误之前)和“删除潜在错误”(在移除识别出的潜在错误之后)训练模型之间的F-1分数比较,(cF-1分数的比较:使用“Original”(在移除识别出的潜在错误之前)和“PMs Removed”(在移除识别出的潜在错误之后)训练模型在心理健康情境下的表现。PMs表示潜在错误。星号表示统计显著性。共进行了5次独立实验以得出统计数据。
在科罗拉多州也观察到了类似的趋势。在去除潜在错误后,其他州测试集上“家庭关系危机”的平均微F-1分数从0.705增加到0.726,而随机删除后的增幅为0.705至0.714。对于“身体健康危机”,其分数从0.684增加到0.694,相比之下随机删除后的增幅为0.684至0.690。对于“心理健康危机”,其分数从0.574上升到了0.607,而随机删除后的增幅仅为0.574至0.587。
纠正有问题的数据
两名标注员达到了高达0.893(Kappa值)的高互标者一致性(IAA)。在159个潜在错误中,有89个被确认为实际的误标。其中包括87个实例,在这些实例中,家庭关系危机标签在基础真值注释中标错为“0”,以及2个实例中的标签在基础真值注释中标错为“1”。
图6(补充数据)2)显示了增量训练过程中平均微F-1分数的变化。在图中。6a模型在其他州测试集上的性能在训练过程开始时(黑色虚线左侧)和结束时(红色虚线右侧)输入校正数据后表现出显著提升。标签校正将其他州测试集上最终的平均微F1分数从0.691提高到了0.733。图中也可以观察到俄亥俄州测试集上的大幅改进。6b标签修正将俄亥俄州测试集上的最终平均微F1分数从0.679提升到了0.714。这一结果表明,经过修正后,修正后的数据实例对其他州和目标州的测试集上模型的表现都有益处,无论这些数据是在训练过程的开始还是结束时输入到模型中的。

a在我们以增量方式逐渐向模型提供更多的训练数据时,对于家庭关系情境下其他州测试集的平均微F-1分数的比较,(b俄亥俄州测试集在家庭关系情景下,当我们逐步以增量方式向模型提供更多的训练数据时的平均微F-1分数比较。在每个子图中,左侧的黑色虚线表示当俄亥俄州的数据已全部用于训练数据“俄亥俄州+其他”和“修正后的俄亥俄州+其他”时的时间点,而右侧的红色虚线则表示开始向模型提供俄亥俄州数据进行“其他+俄亥俄州”和“其他+修正后的俄亥俄州”训练的时间点。
偏倚风险分析
表格4展示了青年与成人、黑人与白人以及女性与男性的比值比(OR)比较。值得注意的是,相对于科罗拉多州的精神健康危机,在原始NVDRS注释中青年的OR值为0.89(95%CI=0.59–1.33),这与随机删除后的注释中的OR值(OR=0.88, 95% CI=0.58–1.34)相似。然而,它不同于在移除我们方法识别的错误后注释中的OR值(OR=0.65, 95% CI=0.31–1.36)。类似地,在原始NVDRS注释中黑人的OR值为0.68(95% CI=0.49–0.93),这与随机删除后的注释中的OR值(OR=0.67, 95% CI=0.48–0.93)相似,但不同于移除我们方法识别的错误后注释中的OR值(OR=0.51, 95% CI=0.07–3.7)。
讨论
本研究探讨了此前未被探索的领域,即发现无结构化死亡调查记录中的标注不一致,并解决可能错误归因的自杀情况。为填补这一空白,我们提出了一种实证的自然语言处理方法。据我们所知,此前没有其他工作将类似的方法应用于任何大规模医疗或死亡数据集。
我们对不同州之间数据标注不一致性的分析表明,将目标州的数据加入训练集后,在针对目标州的测试集进行测试时,有49.8%的目标州的表现得到了提升。然而,在其他州的测试集上进行测试时,则在51.1%的目标州中观察到了平均性能下降的情况。这种表现差异取决于训练数据组合,强调了NVDRS数据集中标注不一致性的存在。这些发现突显了修正死亡调查记录中的标签不一致性以提高数据质量的必要性。
通过采用类似交叉验证的范式并识别出可能不一致的实例,我们展示了从训练集中移除这些实例可以显著提升模型性能和泛化能力。在两个州和地区三种不同的危机情景中观察到的一致性改进表明,移除潜在错误有助于使目标地区的标签注释与其他地区对齐,突显了我们在识别注释错误方面的有效性。我们进一步纠正了这些数据,并在自杀情况检测中观察到了性能提升。
最后但同样重要的是,我们的OR分析衡量了自杀情境(例如,心理健康危机)与特定自杀死者群体(例如,年轻人)相比参考群体(例如,成年人)的相关强度。这有助于识别某些亚人群是否比其对应群体更可能经历过特定的自杀情境。我们发现,在纠正不一致数据实例后,OR结果与未进行数据修正前的结果不同。这一观察表明在开展基于数据的自杀分析时,数据准确性的重要性。
虽然我们的研究提供了有希望的见解,但它确实存在一定的局限性。首先,我们的问题实例发现方法使用了一种类似交叉验证的方法,随着数据集规模的增加,这可能会变得计算成本高昂。其次,尽管我们提出的框架可以与各种模型一起工作,但我们仅展示了利用基于BERT的模型的结果。最近有一些自然语言处理任务展示出了大型语言模型(LLMs)的有效性。26,27这可能是一个未来研究的潜在领域。此外,对于每个事件,我们将验尸官报告和执法部门报告进行了拼接,而NVDRS承认来自两个数据源的信息偶尔会出现冲突。同时,由于基于BERT模型的输入令牌限制,5.1%的记录在被送入BERT模型之前被截断了。如果某些情况下的信息出现在这些记录的末尾,它们将不会被送入NLP模型。参数的选择,如折叠次数和错误识别阈值,可以通过网格搜索进一步调整以获得更好的结果。未来的研究可以旨在识别并减轻亚群体中的潜在偏差。这些偏见可能源自事件报告的方式、数据整理的过程以及结论得出的方法,可能会导致不合理的或有偏向的结果。解决这些偏见将增强研究发现的可靠性和公平性及其在自杀预防中的后续应用。最后,虽然我们展示了手动标签校正的有效性,但仍应探索自动方法以实现可扩展性。这种标注一致性检测框架也可能应用于其他基于州的报告系统,如致命事故分析报告系统(FARS)。28这样的方法会提供一种改善大规模数据集和多样化来源之间标注一致性的实际手段。
NVDRS死亡调查记录中数据标注不一致的存在不仅妨碍了我们对自杀情况的理解,也阻碍了旨在预防自杀的有效策略、项目和政策的发展、实施和评估。在这项工作中,我们提出了一种经验性的自然语言处理方法来检测NVDRS中的数据标注不一致性,并验证识别和纠正可能存在问题的实例的有效性。实验结果展示了我们的方法的能力及其泛化能力,并指出了这项工作的局限性。我们打算完善并扩展我们的方法以解决不同数据源中数据标注不一致的问题。此外,我们倡导建立更严格的注释指南和质量控制措施,以确保数据集的一致性和可靠性。通过提高这些数据集中注释的准确性和一致性,我们可以提升自然语言处理模型的性能和可靠性。这进而为科学家和政策制定者提供了改进NVDRS数据标注准确性的手段,并从根本上支持发现真正的自杀情况,最终有助于预防自杀。
代码可用性
我们已经将代码公开发布了29.
数据可用性
本研究分析的数据集NVDRS RAD在符合特定资格标准并采取措施确保保密性和数据安全的研究人员请求下可获得。我们的研究得到了NVDRS受控访问数据库(RAD)提案的批准,该提案授予我们访问数据和进行此处描述工作的所需权限。由于NVDRS数据具有保密性,包含可能无意中泄露受害者身份的敏感信息,因此设置了这种受限访问。为了保护这些数据,CDC要求用户满足某些资格要求并实施必要的措施以确保数据安全、保持机密性和防止未经授权的访问。有兴趣访问NVDRS数据的研究人员可以按照提供的说明申请。https://www.cdc.gov/nvdrs图. 的源数据为3见补充数据1图中的源数据5在表中3图的数据来源6见补充数据2.
参考文献
CDC. 预防自杀。https://www.cdc.gov/suicide/.
CDC. 全国暴力死亡报告系统。https://www.cdc.gov/nvdrs.
王,S. 等人。一种用于从死亡调查叙述中识别与社会决定因素相关的环境和自杀危机的自然语言处理方法。美国医学信息协会杂志 30, 1408–1417 (2023).
刘 GS 等人。暴力死亡监控——全国暴力死亡报告系统,48个州、哥伦比亚特区和波多黎各,2020年。MMWR监测总结 72, 1–38 (2023).
霍伦斯坦,N.,施奈德,N.及韦伯,B.语义标注中的不一致性检测。第十届国际语言资源和评估大会(LREC'16) proceedings(第3986-3990页。欧洲语言资源协会(ELRA),斯洛文尼亚波托雷兹,2016年)
克维托宁,P. & 奥利瓦,K. (半)自动检测词性标注语料库中的错误。在计算语言学第19届国际会议(COLING 2002) proceedings (2002).
马庆,吕彬林,村田明,市川明,石原英史。使用模块化神经网络进行标注语料库的在线错误检测。国际人工神经网络会议 proceedings 1185–1192(Springer-Verlag, 柏林, 海德堡, 2001).
乌勒,T. & 席莫夫,K. 不可预期的产出可能是错误。第四届国际语言资源与评估大会(LREC'04) proceedings(欧洲语言资源协会(ELRA),葡萄牙里斯本,2004年)。
洛夫松,H. 使用三种互补方法校正词性标注语料库。第十二届欧洲计算语言学协会会议 proceedings(第523-531页。美国计算语言学协会,2009年)。
卡托,Y.及松原,S. 基于同步树替换语法的句法树库错误修正。ACL 2010年大会短论文集(第74-79页。美国计算语言学协会,2010年)
曼宁,C. D. 词性标注从97%到100%:是否到了加入一些语言学知识的时候了?在计算语言学与智能文本处理171-189 ( Springer, 2011 ).
阮,P.-T.,黎,A.-C.,何,T.-B.及阮,V.-H. 越南语依存树库构建与基于熵的错误检测。语言资源评估 49, 487–519 (2015).
曾庆,余明,余伟,江涛及江敏。NER数据标注中标签一致性的验证。第2届自然语言处理系统评估与比较 workshop 论文集(第11-15页。计算语言学协会,多米尼加共和国蓬塔卡纳,2021年)。
宗,D.,洪,J. & 曼宁,C. D. 使用预训练语言模型检测标签错误。arXiv [计算机科学-计算语言学] (2022).
埃斯金,E. 使用异常检测在语料库中检测错误。在计算语言学协会北美洲分会第1次会议 proceedings (2000).
中川T. & 松本Y. 使用支持向量机检测语料库中的错误。在计算语言学第19届国际会议(COLING 2002) proceedings (2002).
德利加奇,D.及帕尔默,M.减少双重标注的需求。第五届语言标注 workshop 记录集(第65-73页。计算语言学协会,美国俄勒冈州波特兰,2011年)
阿米里,H.,米勒,T.及萨沃瓦,G. 使用神经网络识别虚假数据。2018年计算语言学北美协会人类语言技术大会 proceedings,卷一(长论文)(第2006-2016页。计算语言学协会,路易斯安那州新奥尔良,2018年)。
Swayamdipta, S.等. 数据集测绘:用训练动态映射和诊断数据集。arXiv [计算机科学-计算语言学] (2020).
雅戈布扎德法尔,M.-A.,本塔拉赫,B.,蔡巴拉库克,M.及扎马尼拉德,S. 关于众包用户表述中的不正确改写的研究。2019年计算语言学协会北美洲分会人类语言技术会议 proceedings,卷一(长篇和短篇论文)(第295-306页。计算语言学协会,明尼苏达州明尼阿波利斯,2019年)。
王,Z等. CrossWeigh:从不完美的标注训练命名实体标记器。在2019年经验方法自然语言处理会议和第九届国际联合自然语言处理大会(EMNLP-IJCNLP) proceedings(计算语言学协会,2019).https://doi.org/10.18653/v1/d19-1519.
Northcutt, C., 江, L. & Chuang, I. 自信学习:估计数据集标签中的不确定性。人工智能研究杂志 70, 1373–1411 (2021).
莱宾, I. & 鲁彭霍夫, J. 自动标注数据中噪声检测。第55届计算语言学协会年会 proceedings(卷一:长论文)(第1160-1170页。计算语言学协会,加拿大温哥华,2017年)。
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT:深度双向变压器的语言理解预训练。arXiv [计算机科学-计算语言学] (2018).
李俊等。BioBERT:一种用于生物医学文本挖掘的预训练生物医学语言表示模型。生物信息学 36, 1234–1240 (2020).
盖乌瓦拉,M. 等人。利用大型语言模型识别电子健康记录中的健康社会决定因素。NPJ数字医学. 7, 6 (2024).
Keloth, V. K. 等人. 大规模语言模型在从临床记录中提取健康社会决定因素信息方面的应用——一种跨机构可推广的方法。medRxiv https://doi.org/10.1101/2024.05.21.24307726 (2024).
致命事故报告系统(FARS)。美国国家公路交通安全管理局 https://www.nhtsa.gov/研究数据/致命事故报告系统(FARS).
bionlplab/2024_一致性检测: v1.0.0. https://doi.org/10.5281/zenodo.13047596.
致谢
本研究得到了美国国立卫生研究院(NIH)AIM-AHEAD联盟发展计划的资助,资助编号为OT2OD032581;美国国家老龄问题研究所(NIA)的资助,资助编号为RF1AG072799;美国国立过敏与传染病研究所(NIAID)的资助,资助编号为1R01AI130460;国家科学基金会的资助,资助编号为2145640;用于物质使用障碍、HCV和HIV治疗干预的卫生经济学研究中心(NIDA P30DA040500)以及健康护理管理研究与教育基金会的支持。文中内容完全由作者负责,并不一定代表NIH和NSF的官方立场。
伦理声明
利益冲突
作者声明没有利益冲突。
同行评审
同行评审信息
通讯医学感谢Amir Eliassaf及其他匿名审稿人对该工作的同行评审的贡献。同行评审报告可用。
附加信息
出版者注施普林格·自然对于出版地图中的管辖权声明和机构联系保持中立态度。
补充信息
权利与许可
开放访问本文根据创用CC 姓名标示-非商业性-禁止改作 4.0 国际许可协议发布,该协议允许任何非商业用途、分享、分发和复制任何形式或媒介的内容,条件是您必须向原始作者及来源提供适当的署名,并提供链接至创用CC许可协议,同时表明如果对许可材料进行了修改。在未得到本许可的情况下,您没有权利在此文章或其他部分的衍生作品上与他人共享改编后的材料。本文中的图片或第三方材料(除非另有标明)均包含于本文的创用CC许可协议内;如果您想要使用不属于该许可协议范围内的内容,并且您的预期用途超出法律规定或超出了允许使用的范围,您必须直接从版权持有人处获得使用许可。要查看此许可证,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/.
关于这篇文章

引用这篇文章
王思,周宇,韩昭等著ollectors一种用于检测死亡调查记录中自杀情况不一致性的自然语言处理方法。社区医学 4,199 (2024). https://doi.org/10.1038/s43856-024-00631-7
收到:
接受:
发布:
DOI: https://doi.org/10.1038/s43856-024-00631-7