

遇见Aria:这款新的开源多模态人工智能正在与大型科技公司竞争 - Decrypt
作者:Decrypt / Jose Antonio Lanz
人工智能迎来了一个新的玩家——而且它是完全开源的。阿丽亚(人名,根据 context 可能没有直接对应的中文标准译法,保持原有形式)由东京的Rhymes AI开发的多模态大语言模型,能够在一个单一架构内处理文本、代码、图像和视频。
不过,值得关注的不仅是它的多功能性,还有其高效性。它不像其多模态同类模型那样庞大,这意味着它更加节能且对硬件要求更低。
Rhymes AI通过运用一个来实现这一目标的专家混合(MoE)框架这种架构类似于拥有一支专门化的迷你专家团队,每个专家都经过训练,在特定领域或任务中表现出色。
当给模型提供新的输入时,只会激活相关的专家(或其子集),而不是使用整个模型。这样,运行模型的特定部分会比运行一个试图处理一切的整体知识型实体更轻量。
这使得Aria更加高效,因为与传统的模型不同,传统的模型在每个任务中激活所有参数,而Aria会选择性地每次只激活其249亿参数中的35亿参数来处理每个令牌,从而减少计算负载并提高特定任务的性能。
它也允许更好的可扩展性,因为可以新增专家来处理专门任务而不会使系统过载。
需要注意的是,Aria是开源Arena中第一个多模态的Moe。目前已经有一些Moe(如Mixtral-8x7B)和一些多模态的大语言模型(如Pixtral),但Aria是唯一能够结合这两种架构的模型。
阿丽亚在合成基准测试中击败了竞争对手
在基准测试中,Aria 的表现优于一些开源重量级选手,如 Pixtral 12B 和 Llama 3.2-11B。
更令人惊讶的是,它正在与像GPT-4、Gemini-1 Pro或Claude 3.5 Sonnet这样的专有模型竞争,并展示了与其母公司OpenAI的杰作相媲美的多模态性能。
Rhymes AI已将Aria在Apache 2.0许可下发布,允许开发人员和研究人员改编和构建该模型。
这也是由Meta和Mistral领导的不断扩大的开源AI模型池中的一个非常强大的补充,这些模型的表现与更受欢迎且被广泛采用的闭源模型类似。
阿丽亚的多才多艺也在各种任务中展现出来。
在研究论文中,团队解释了他们如何用整个财务报告来训练模型,该模型能够进行准确的分析,可以从报告中提取数据,计算利润率,并提供详细的分解说明。
当被要求进行天气数据可视化时,Aria不仅提取了相关信息,而且还生成了Python代码来创建图表,并包含了格式细节。
该模型的视频处理能力也看起来很有前景。在一次评估中,Aria 分解了一个关于米开朗基罗《大卫》雕像的一小时视频,识别出 19 个不同的场景,并给出了每个场景的开始和结束时间、标题和描述。这不仅仅是简单的关键词匹配,而是上下文驱动的理解的展示。
编码是Aria擅长的另一个领域。它能够观看视频教程,提取代码片段,并且甚至可以调试它们。有一次,Aria发现并修正了一个涉及嵌套循环的代码片段中的逻辑错误,展示了它对编程概念的深刻理解。
测试模型
Aria是一个拥有253亿参数的大型模型,运行推理至少需要一个配备80GB内存的A100 GPU,并且需要使用半精度计算,因此你无法在笔记本电脑上运行和微调它。然而,我们在以下环境中对其进行了测试:Rhyme AI的演示页面,提供一个简化版本。
文本分析与处理
首先,我们测试了它分析文档的能力,给它提供了一篇研究论文,并要求它简单地解释这篇论文的内容。
该模型非常简洁但准确。它没有产生幻觉,并能保持对话,展示了良好的检索能力。
它以一段连续的长段落显示回复,这可能会让喜欢短段落的用户感到疲劳。
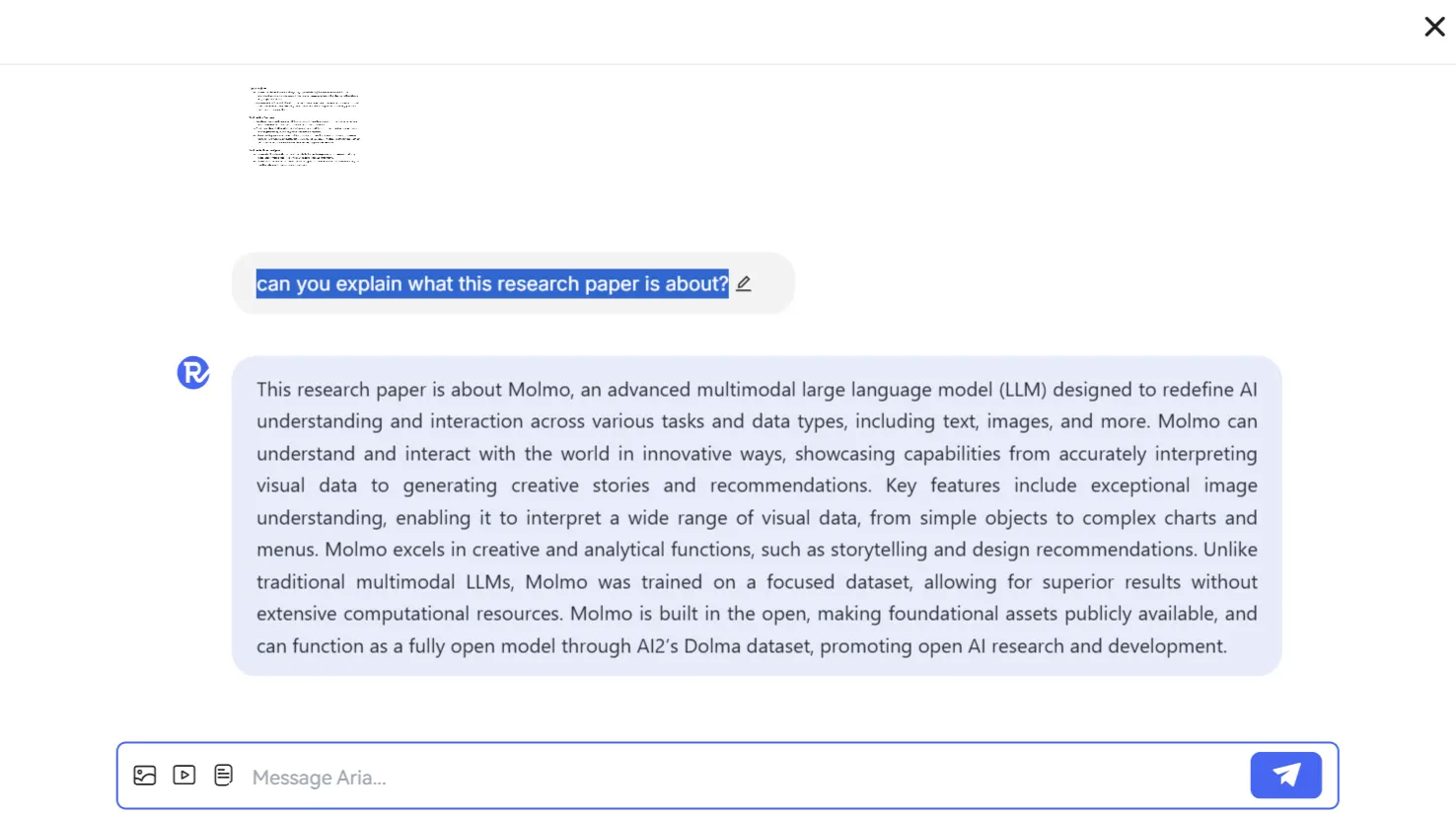
与ChatGPT相比,OpenAI的模型在提供的信息方面显示了类似的答案,但在格式上更加结构化,使其更容易阅读。
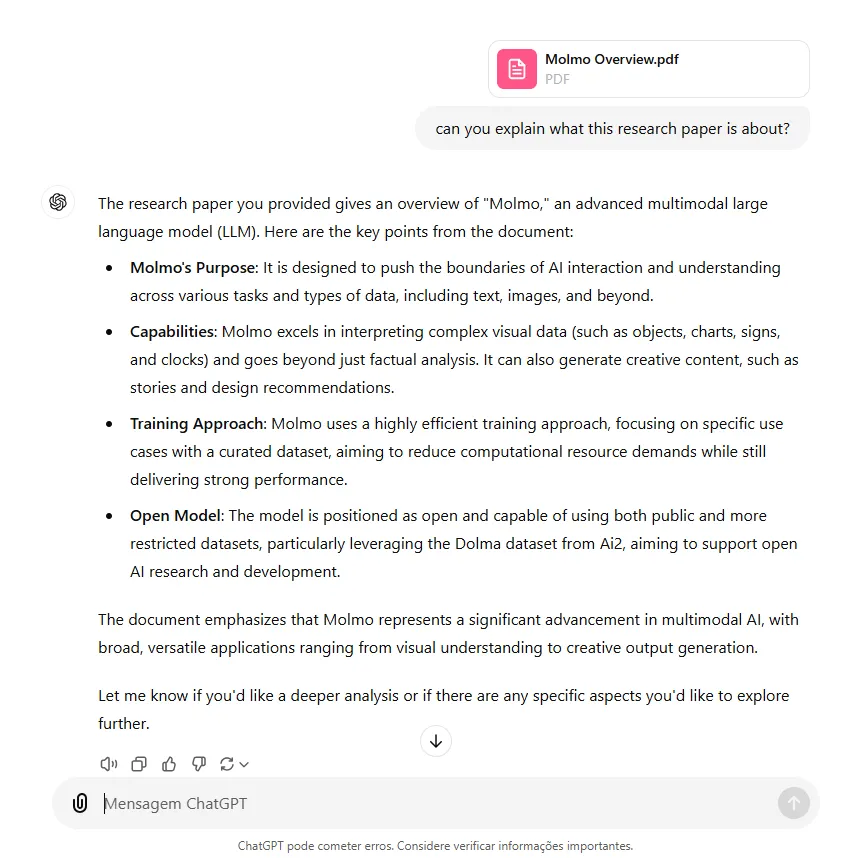
除此之外,Rhyme的演示站点限制只上传最多五页的PDF文件。而ChatGPT能够处理超过200页文档的能力要强得多。
作为对比,Claude 3.5 Sonnet允许上传小于30MB的文档,只要它们不超过其token限制。
编码与图像理解
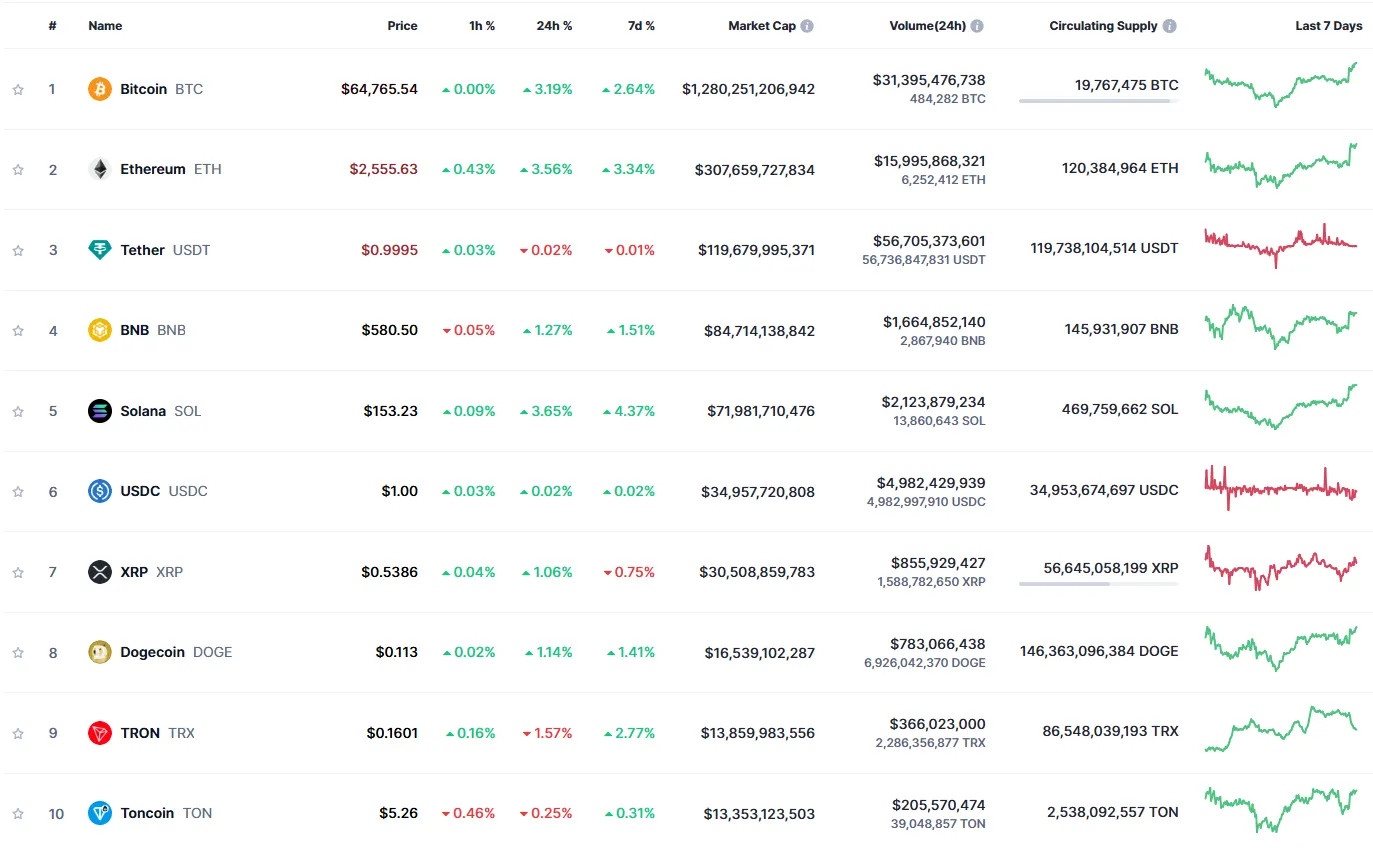
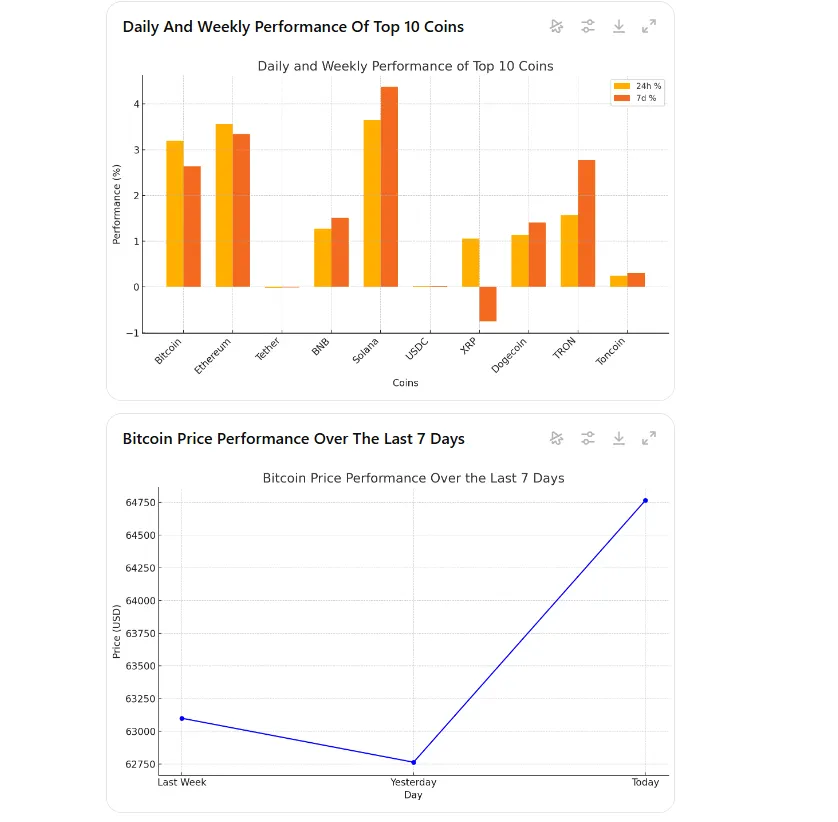
然后我们混合了两个指令,要求模型分析来自CoinMarketCap的截图,该截图显示了排名前十的代币的价格表现,然后使用代码提供一些信息。
我们的提示是:
根据过去24小时的表现来组织列表。
编写一个Python代码来绘制每个币的日度和周度表现的柱状图,并根据过去24小时和过去七天的表现信息绘制显示比特币当前价格、昨天价格和上周同一时间价格的折线图。
Aria 在根据每日表现整理硬币时失败了,出于某种原因,它认为 Tron 的表现是积极的,但实际上其价格在下跌。图表在其每日柱状图旁边添加了每周表现。它的柱状线也有缺陷:X 轴上的时间顺序排列不正确。
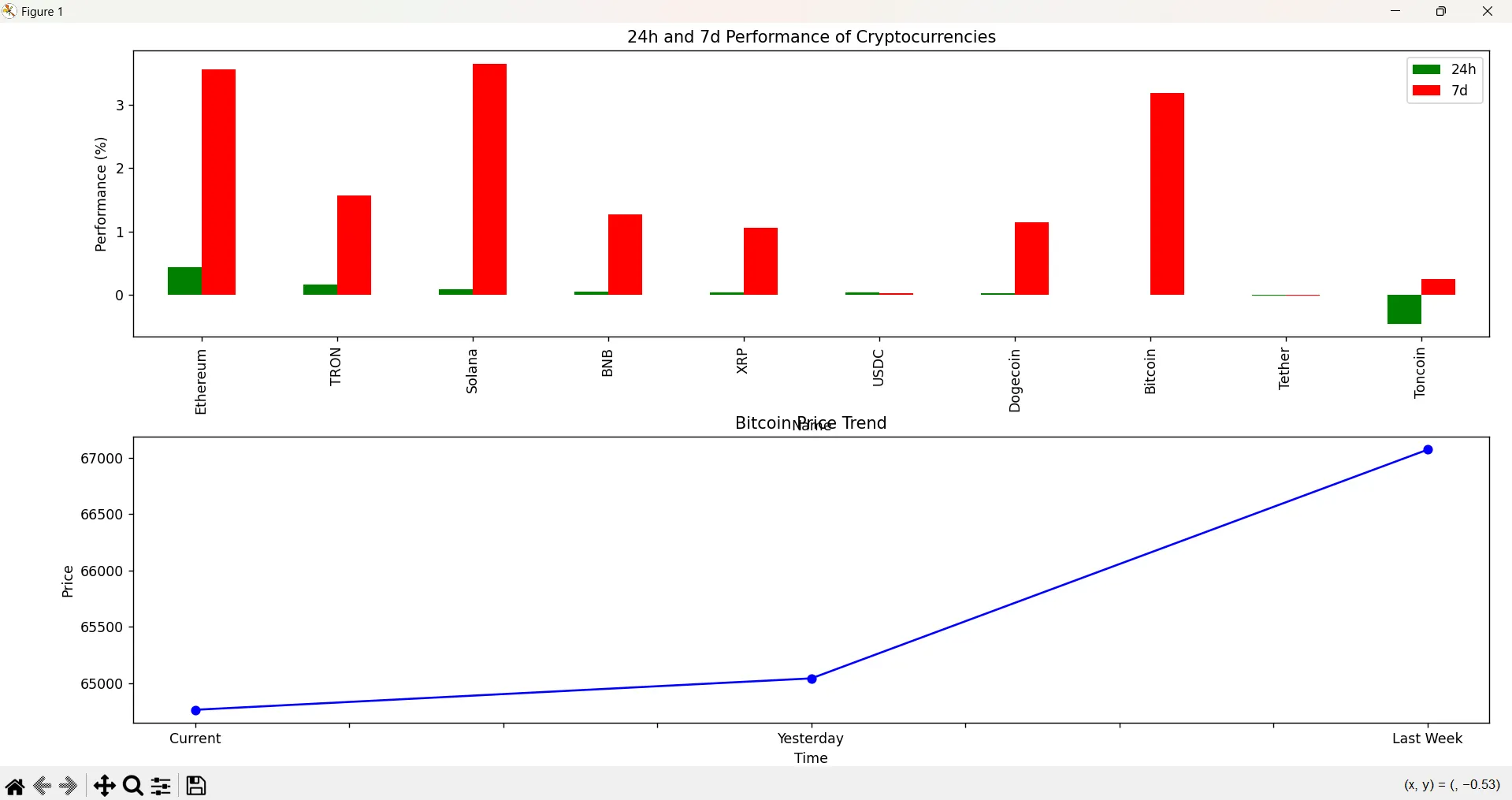
ChatGPT 更擅长理解如何正确绘制时间线,但并没有根据代币的表现来排序它们。它还像是在为 TRX 打广告,显示了积极的日表现。
视频理解
Aria 也能够充分理解视频。我们上传了一段女性移动的短片。在这段视频中,女性没有说话。
我们要求模型描述场景,并询问女性在说什么,试图看看模型是否虚构了一个回答。
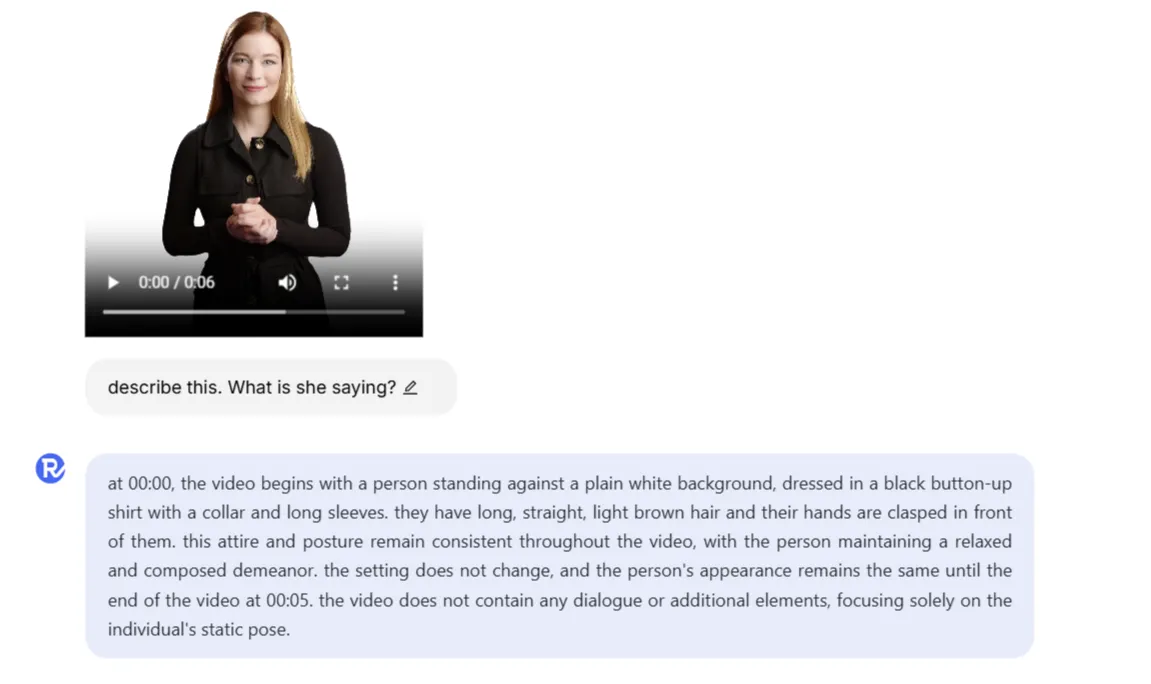
Aria能够理解任务,描述元素,并且恰当地提到那个女人没有改变她的外貌并且没有对着镜头说话。
ChatGPT无法理解视频,所以它无法处理这个提示。
创意文字
这次测试可能是最大的惊喜。Aria的故事比Grok-2或Claude 3.5 Sonnet提供的内容更具想象力,而后者在我们主观分析中一直处于领先地位。
我们的提示是:写一个关于名叫何塞·兰兹的人的故事,他从2150年回到1000年。使用生动的描述性语言,并根据他的文化背景和体质特征来改编故事(你可以发挥想象力)。他在未来世界中旅行回溯至过去,强调时间旅行悖论以及试图解决过去的问题或制造问题以改变当前的时间线是毫无意义的——他不知道直到返回自己的时代才明白,2150年的现状正是由于他在1000年所参与的历史事件而形成的。
阿丽亚讲述的约瑟·兰兹的故事中,约瑟·兰兹是一位来自2150年的时空旅行历史学家,这个故事将一些科幻悬念与历史和哲学元素融合在一起。与其他模型讲述的故事相比,这部作品的结果并不那么突然,并且虽然它的创意不如人类写作的作品那样新颖,但它产生了一个类似于剧情转折的结果,而不是一个仓促的结尾。
总体而言,Aria 展示了一个引人入胜且连贯的故事,其在不同主题上的表现比其更强大的竞争对手更加全面和有影响力。由于代币限制,它的沉浸感略强但节奏稍显仓促。对于长篇故事来说,Longwriter 是目前最好的模型。
你可以阅读所有的故事由点击此链接.
总体而言,Aria是一个很有竞争力的项目,由于其架构、开放性和可扩展性,前景看起来很有希望。如果你想尝试或训练该模型,它免费提供于Hugging Face请确保你至少有80GB的VRAM,或者有一个强大的GPU,或者是三个协同工作的RTX 4090。这项技术仍然是新的,因此没有量化版本(精度较低但更高效)。
尽管存在这些硬件限制,开源领域的新发展是实现拥有一个完全开放的ChatGPT竞争对手的梦想的重要一步,人们可以在家中运行并根据自己的特定需求进行改进。让我们看看他们接下来会怎么做。
编辑_by塞巴斯蒂安·辛克莱尔以及乔希·昆特纳
通用智能通讯newsletter
由生成式AI模型Gen讲述的一周人工智能之旅。