

苹果的研究揭示了大型语言模型“推理”能力中的深层次缺陷
这种差异——无论是不同GSM-Symbolic运行之间,还是与GSM8K结果相比——都相当令人惊讶,因为正如研究人员指出的,“解决一个问题所需的总体推理步骤保持不变。”这样的小变化导致如此多样的结果表明,这些模型并没有进行任何“正式”的推理,而是“试图执行一种分布内模式匹配,将给定的问题和解答步骤与训练数据中看到的类似情况对齐。”
不要分心
然而,总体而言,GSM-Symbolic测试显示的差异通常在整体范围内相对较小。例如,OpenAI的ChatGPT-4o从GSM8K上的95.2%准确率下降到GSM-Symbolic上的94.9%,尽管如此,这个成绩仍然非常出色。无论模型背后是否使用了“形式化”的推理方法(尽管当研究人员在问题中添加一个或两个额外的逻辑步骤时,许多模型的总准确率急剧下降),这两个基准测试都显示了一个相当高的成功率。

一个示例,展示了某些模型如何被添加到GSM8K基准套件中的无关信息误导。
一个示例,展示了某些模型如何被添加到GSM8K基准套件中的无关信息误导。致谢:苹果研究
然而,当苹果公司的研究人员通过在问题中添加“看似相关但实际上无关紧要的陈述”来修改GSM-Symbolic基准测试时,被测的大规模语言模型表现得差得多。对于这个称为“无操作”的“GSM-NoOp”基准测试集来说,一个关于某人在多天内采摘了多少猕猴桃的问题可能会被修改为包括这样一个无关紧要的细节:“其中五只猕猴桃比平均大小稍小一些。”
加入这些误导信息导致了研究人员所称的“灾难性的性能下降”,与GSM8K相比,准确率分别降低了17.5%到惊人的65.7%,具体取决于测试的模型。这些巨大的准确性下降突显了使用简单的“模式匹配”来“将陈述转换为操作而不真正理解其含义”的内在局限性,研究人员写道。
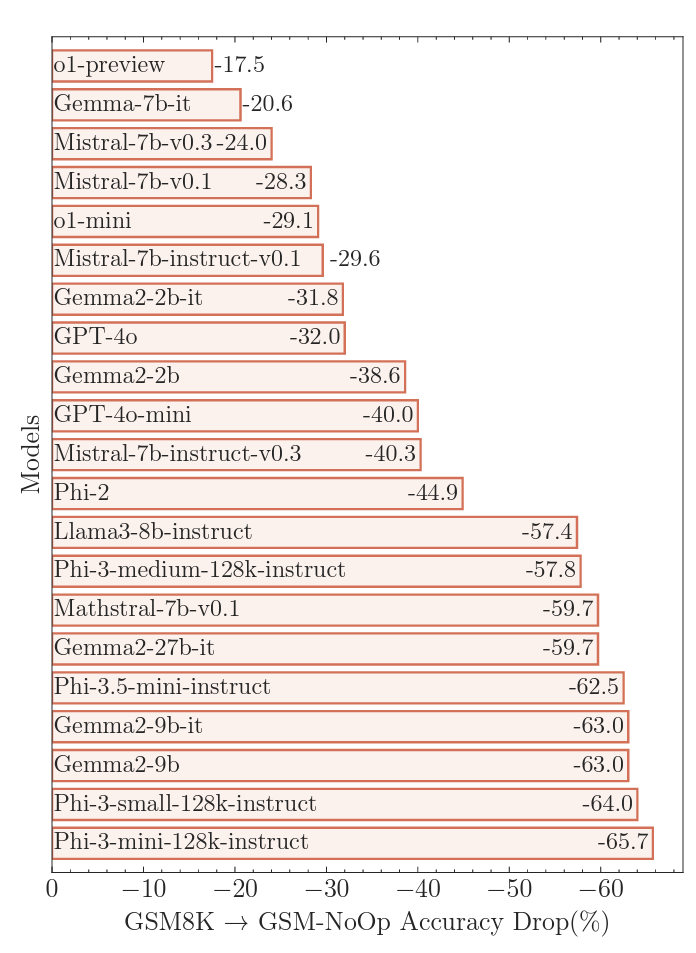
将无关信息引入提示通常会导致大多数“推理”大型语言模型出现“灾难性”失败。
将无关信息引入提示常常会导致大多数“推理”大型语言模型出现“灾难性”失败。版权说明:(如果上下文表明这是关于信用的部分,则可以译为:" credits: " 或 " 信用:" ,但根据提供的文本来看,这里似乎缺少具体内容,所以保留较为通用的表达。如果没有具体含义,默认输出原文) Credit:Apple研究
在较小猕猴桃的例子中,大多数模型试图从最终总数中减去较小的水果,因为研究人员推测,“它们的训练数据集中包括了需要转换为减法运算的类似例子。” 这就是研究人员所说的“关键缺陷”,这种缺陷表明了“模型推理过程中的更深层次问题”,这些问题无法通过微调或其他改进来解决。