

研究员将屏幕录制的内容输入到Gemini中,以便轻松提取准确的信息。

最近,AI研究员Simon Willison想把他使用云服务的费用加总起来,但他需要的付款金额和日期分散在十几封不同的邮件中。手动输入会非常繁琐,所以他转向了一种他称之为“视频抓取”的技术,这种技术涉及将屏幕录制视频输入类似ChatGPT的AI模型来进行数据提取。
他所发现的表面上看似简单,但其质量对未来AI助手的发展具有更深远的影响,这些AI助手可能很快就能看到并与我们在电脑屏幕上进行的操作互动。
威尔森写道:“前几天我发现我自己需要把散落在十二封不同邮件中的若干数值加总。”详细的帖子在他的博客上。他录制了一段时长35秒的视频,展示了相关邮件的滚动过程,然后将这段视频输入到谷歌的AI工作室一个工具,允许人们试验几个版本的Google的 Gemini 1.5 Pro以及双子座1.5 Flash AI模型。
威利森然后要求Gemini从视频中提取价格数据,并将其整理成一种称为的特殊数据格式JSON(JSON格式的文本),其中包含了日期和美元金额。AI模型成功地提取了这些数据,Willison然后将其格式化为CSV(逗号分隔值)表格以供电子表格使用。在实验过程中仔细检查错误后,准确性结果——以及视频分析运行的成本——让他感到惊讶。
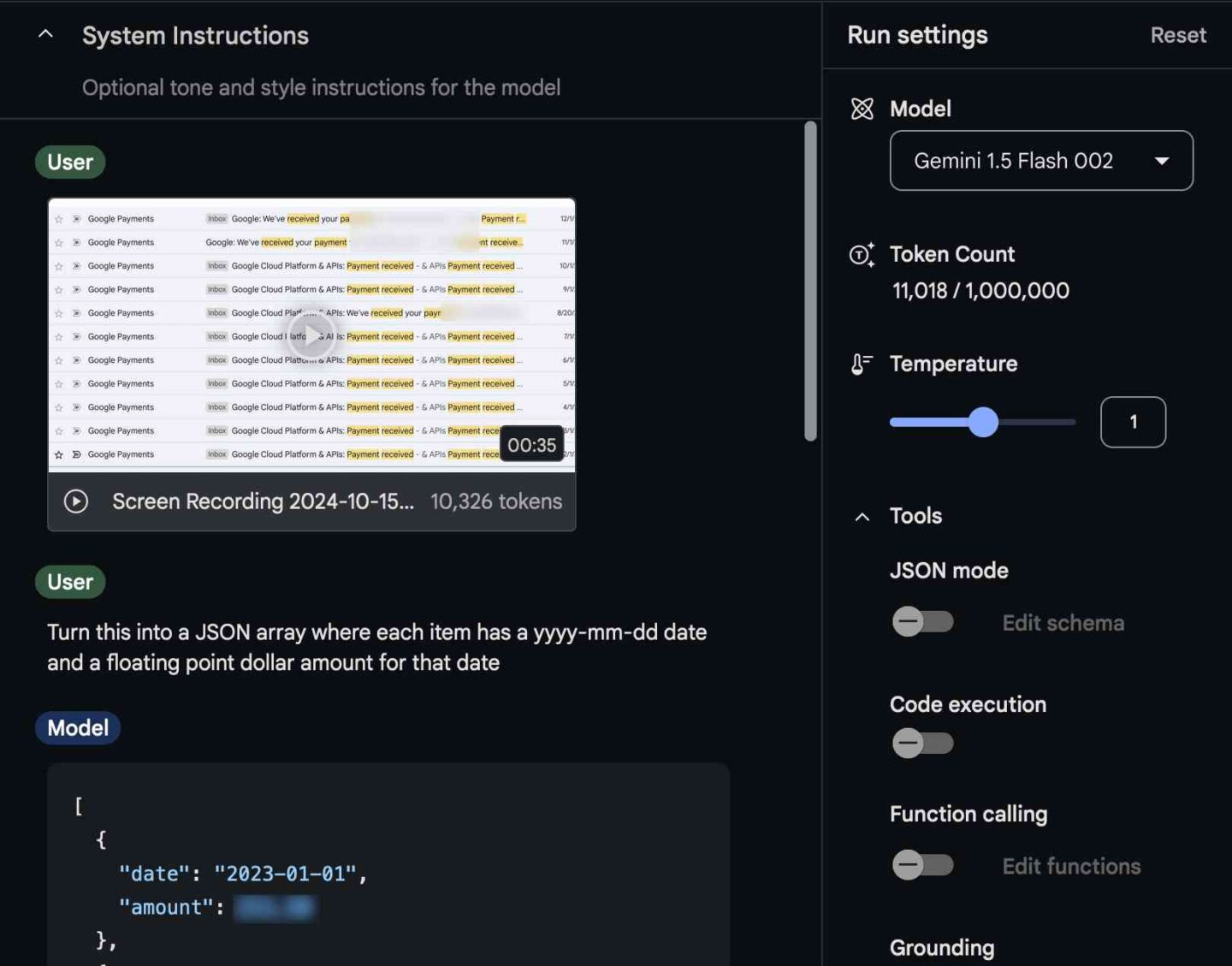
Simon Willison使用Google Gemini从屏幕录制视频中提取数据的截图。
Simon Willison使用Google Gemini从屏幕捕获视频中提取数据的截图。 credits: 标题或者表示来源、感谢等意思,具体语境不明时可以保留原词。根据要求直接翻译: credits:Simon Willison
“成本如此之低,以至于我不得不重新计算了三次以确保我没有出错,”他写道。Willison表示,整个视频分析过程实际花费不到一分钱的十分之一,只使用了11,018个令牌。双子座1.5闪存002他最终并没有付费,因为Google AI工作室目前对于某些类型的使用是免费的。
视频抓取只是在最新大型语言模型(LLM)出现后可能实现的许多新功能之一,例如谷歌的Gemini和GPT-4o这些模型实际上是“多模态”模型,可以处理音频、视频、图像和文本输入。这些模型将任何多媒体输入转换为令牌(数据块),并使用这些令牌来预测序列中的下一个令牌应为何。
类似于“令牌预测模型”(TPM)这样的术语可能比“LLM”更准确。这几天对于具有多模态输入和输出的AI模型而言,但一个通用的替代术语还没有真正流行起来。但是无论你怎么称呼它,拥有可以接受视频输入的AI模型都有有趣的含义,既有积极的一面,也有潜在的消极影响。
打破输入障碍
威尔森并不是第一个将视频输入AI模型以获得有趣结果的人(关于这一点请见下文,这里有一个链接)2015年论文他使用了包含“视频抓取”术语的工具,但一等到Gemini推出了它的视频输入功能,他就开始认真地进行实验。
二月,Willison展示了他在博客上早期应用AI视频抓取的另一个例子是,他拍摄了书架上书籍的一段七秒视频,然后让Gemini 1.5 Pro提取视频中看到的所有书名,并将它们整理成一个结构化或有组织的列表。
将非结构化数据转换为结构化数据对于Willison来说很重要,因为他也是一个数据记者威利森过去为数据记者创建过工具,比如Datasette项目,允许任何人将数据发布为一个互动网站。
令每一位数据记者沮丧的是,由于数据的格式、存储或呈现方式,一些数据来源难以被抓取(用于分析)。在这种情况下,Willison 对于AI视频抓取的潜力感到兴奋,因为它绕过了这些传统数据提取的障碍。
威尔森在他的博客上指出:“无论网站的认证级别或反抓取技术如何,都无法阻止我手动点击网页应用程序并录制屏幕视频。”他的方法适用于任何屏幕上可见的内容。
视频是新的文本

一个 cybernetic 眼球的插图。
一个 Cybernetic 眼球的插图。信用: (如果没有更多实际内容需要翻译,则保持原样输出。)Getty Images
威勒森的技术的简便性和有效性反映了现在正在进行的一项重要转变,即一些用户将如何与令牌预测模型进行互动。不再需要用户手动在聊天对话框中粘贴或输入数据——或者详细地用文本向聊天机器人描述每一种场景——一些人工智能应用程序越来越多地直接使用屏幕上捕获的视觉数据工作。例如,如果你在一个披萨网站上遇到糟糕界面的问题,一个AI模型可以介入并帮助你执行必要的鼠标点击为你点披萨。
事实上,视频抓取已经进入了每个主要人工智能实验室的视野,尽管他们目前可能不会用这样的术语来称呼它。相反,科技公司通常将这些技术称为“视频理解或者简单地说 ""视觉."
今年五月,OpenAI展示了其原型版本之一ChatGPT Mac应用程序带有允许ChatGPT查看和互动您屏幕内容的选项,但该功能尚未发布。微软展示了一个类似的"副驾视觉系统上个月提出的一个原型概念(基于OpenAI的技术),该概念能够“观看”你的屏幕并帮助你提取数据和与正在运行的应用程序进行交互。
尽管有这些研究预告,OpenAI的ChatGPT和Anthropic的克劳德尚未为其模型实现公共视频输入功能,可能是因为处理“标记化”视频流的额外令牌对他们来说在计算上相对昂贵。
目前,谷歌正在通过其从搜索收入中积累的资金和庞大的数据中心舰队(公平地说,OpenAI也在补贴,但主要来自投资者的资金和微软的帮助)来大幅补贴用户的人工智能成本。但是,人工智能计算的总体成本每天都在下降,这将随着时间的推移使该技术的新能力为更广泛的用户群体所利用。
应对隐私问题
正如你可以想象的,让AI模型看到你在电脑屏幕上的操作可能有其不利之处。目前,视频抓取对Willison来说非常有用,他无疑会以积极和有益的方式使用捕获的数据。但这也预示着一种未来可能会被用来侵犯隐私或自主使用的功能。监视计算机用户在以往不可能的规模上。
另一种形式的视频抓取最近因为同样的原因引发了巨大的争议。诸如第三方应用程序之类的软件回溯AI在Mac上和微软的召回这将被集成到Windows 11中的功能通过将屏幕上的视频输入到一个AI模型中来运行,该模型会将提取的数据存储在一个数据库中以备以后的AI调用。不幸的是,这种方法也引入了潜在的隐私问题,因为它记录了你在机器上所做的所有事情,并将其存放在一个日后可能被黑客攻击的地方。

到目前为止,虽然威尔森的技术目前涉及将数据视频上传到谷歌进行处理,但他很高兴自己仍然可以决定AI模型看到什么以及何时看。
“这种视频抓取技术的伟大之处在于,它可以用于你在屏幕上能看到的任何内容……并且它让你完全控制最终暴露给AI模型的内容,”威尔森在他的博客文章中解释道。
未来也有可能,一个本地运行的开源权重AI模型能够在完全没有云连接的情况下完成相同的视频分析方法。Microsoft Recall 在支持的设备上本地运行,但它仍然需要一个云端连接大量的不实信任目前,Willison完全满足于在必要时选择性地向AI模型提供视频数据。
“我预计将来我会更多地使用这种技术,”他写道,也许以不同的形式,许多人也会这样做。如果以往的情况可以作为参考,Willison——创造了这个词“提示注入”在2022年——似乎总是领先几步探索AI工具的新颖应用。目前,他的关注点在于AI与视频的新含义,你也应该关注这一点。

本杰明·爱德华兹是Ars Technica的高级AI记者,并于2022年创立了该网站的专门AI板块。他还是广受引用的技术历史学家。在业余时间,他会写歌和录制音乐、收集古董计算机,并享受大自然。他居住在北卡罗来纳州的雷利市。