


所有与人工智能相关的趋势都呈上升态势,通常增长得非常迅速。这包括人工智能工作负载的规模、新兴的人工智能公司的数量以及人工智能系统的规模和复杂性等几个方面。
由于需要提高性能以及保持组件之间的延迟较低,因此提高了计算密度,导致功率需求大幅增加,而将其压缩和提取的空间却在不断减小。听到这一点可能会令人惊讶。微软的核计划——通过位于宾夕法尼亚州三里岛的一座目前关闭的核反应堆——但说实话,这不应该令人感到惊讶。
今年早些时候的一份报告中,高盛分析师预测,人工智能工作量的增加——加上效率提升放缓——将推动一个增长趋势。数据中心电力需求增长160%到2030年,设施全球能耗将从目前的1%至2%,增加到那时的3%至4%。这将是包括电力消耗、环境、成本以及对企业及云基础设施提供商在内的持续性问题,尤其是在商务领域对人工智能采用激增的情况下。麦肯锡5月份的一项调查发现,65%的受访者表示他们的组织定期使用生成式AI,几乎是十个月前类似调查数字的两倍。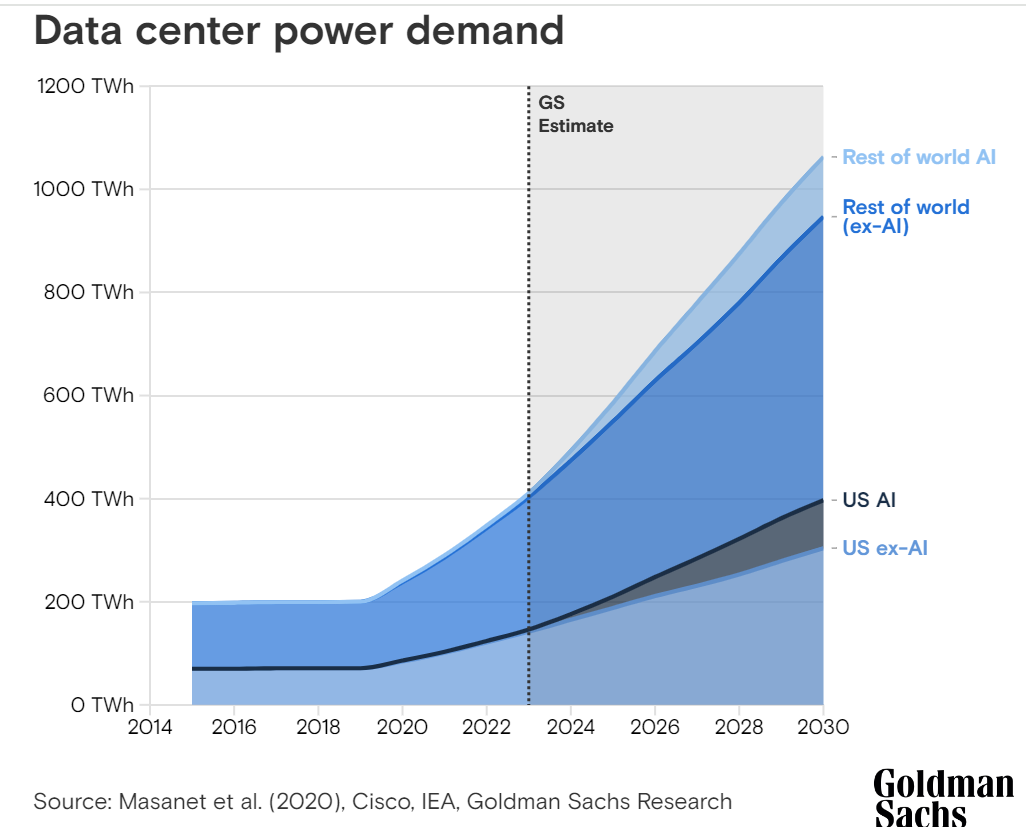
鉴于此,系统制造商正在寻找更高效的方式来管理随着人工智能和越来越密集的系统而来的热需求——包括采用诸如英伟达耗电组件之类的系统并不奇怪。“Blackwell” B100和B200 GPU加速器– 正在运行它们。这包括推动机架系统的液冷技术。液冷并不是新技术;它已经提供了多年。然而,现在这项技术变得更加紧迫。
对于许多还记得20世纪60年代、70年代和80年代的IBM大型机以及70年代和80年代的Cray超级计算机的人来说,这种液冷技术让他们有种怀旧的感觉。请习惯它。
三月份,NVIDIA发布了其DGX超级计算机的两个新版本,包括由NVIDIA强大的GB200 CPU-GPU组合驱动的、采用液冷技术的SuperPOD。在过去的几周里,联想、慧与(HPE)、戴尔科技和超微服务器都推动了针对新AI时代的服务器液冷技术。
戴尔计算和网络产品组合管理高级副总裁阿鲁努库马尔·纳拉扬在本月早些时候的一次简报中表示:“我们从这些AI解决方案中看到了一些独特的需求。”他指出,随着AI的发展,系统不再只是一个服务器。“它是一个机架级的规模解决方案,甚至是一系列机架。这就是所提供的服务正在发生的变化。为了实现这些服务,GPU和CPU的热密度正在增长。”
纳拉扬安指出AMD的新“Turin”Zen 5芯片输出功率为500瓦,增加到“我们正在达到1千瓦、1.2千瓦、1.5千瓦级别的GPU。所有这些都将需要高度的热效率。我们需要集成液冷技术。这将是未来发展的关键能力。”

本周在美国加利福尼亚州圣何塞举行的OCP全球峰会上,戴尔宣布了集成机柜7000,这是一个高度密集的OCP标准机柜,专为液冷设计,并适用于更高密度的GPU和CPU。该新机柜将在明年第一季度上市,其中一款可容纳在新机柜中的系统是PowerEdge XE9712,用于大规模语言模型(LLM)训练以及实时推理用于大规模人工智能工作负载。该系统将由液冷GB200 NVL72驱动,该系统通过NVLink将多达36个Nvidia Grace CPU与72个Blackwell GPU连接起来。液冷技术将使GB200 NVL72的效率比使用NVIDIA H100 GPU的系统的效率高出25倍。
本周在西雅图举行的Tech World活动上,联想推出了ThinkSystem SC777 V4 Neptune系统,该系统由Nvidia的GB200s驱动,用于运行万亿参数的人工智能模型,并包括系统制造商的新一代ThinkSystem N1380 Neptune,这是其液体冷却技术的第六代。据联想称,这款新的Neptune系统可以将功耗降低多达40%,因此对于每台服务器机柜消耗100KW或更多电力的数据中心来说,不需要空调设备来保持低温环境。
它将帮助希望采用混合AI模型的企业,其中一些AI工作负载在云中运行,而另一些则可以在本地完成。Lenovo基础设施解决方案集团首席营销官Flynn Maloy表示,在展示会前的简报中说道,数据中心的电力用于处理工作负载,而不是用于冷却。
最新版本的Neptune配备了全新的垂直设计和专为行业标准19英寸机架设计的新底盘。它采用开放式温水冷却系统,并包含八个托盘、四个15千瓦钛金电源转换站,以及一个集成盲插机制和航空航天级无滴漏连接器的重新设计水流分配系统,据该公司介绍。

“大多数服务器看起来像一堆垂直堆叠的披萨盒,”Maloy说。“我们将这些披萨盒垂直排列,使得节点也变为垂直。这基本上利用了重力和压力,并且通过过程可以更有效地消除热量。我们重新设计了整个技术的背板。这样可以实现100%的热量去除。”
他说联想所做的工程支持“目前最高的加速计算需求。当你像这样减少能耗时,你可以在各种计算环境中获得更高的性能。”新的Neptune系统采用了开放式直接温水冷却技术。
戴尔和联想的系统是在HPE和Supermicro发布类似声明之后推出的。在上周的人工智能日上,HPE展示了专为人工智能系统设计的完全无风扇直接液冷(DLC)架构,CEO安东尼奥·内里宣称与传统空调系统相比,该架构冷却功耗提高了90%。这是一个八组件的设计方案,包括对GPU、CPU以及服务器刀片、本地存储、网络结构、机柜、集群和冷却剂分配单元的液体冷却。

鉴于2007年至2024年间晶体管密度(5倍)和功耗(33倍)的巨大增长,这是必要的。该公司首次在其产品中使用了100%无风扇的DLC。Cray EX超级计算机,采用的架构通过冷板将冷却液泵送到GPU、CPU、内存和整流器中,消除了风扇的需求。这些系统中的开关和互连设备也采用了水冷技术,据称。HPE文档“为什么它能如此高效地工作?当你比较相同体积的液态和气态空气时,液态的冷却能力比气态的高出3,000多倍。”
几天前,Supermicro发布了一种液冷解决方案,包括冷却液分配单元、冷板、冷却液分配总管、冷却塔和管理软件。机架分配单元提供250千瓦的冷却容量,并且支持热插拔泵和电源供应器,冷板让液体通过微通道流动以散发高达1600千瓦的热量,而分配总管则支持每机柜多达96个Nvidia B200 GPU的密度。SuperCloud Composer软件监控系统、机架、冷却塔以及各种组件。
总的来说,该系统通过去除空调设备的需要,在基础设施能源上节省了40%,在数据中心空间上节省了80%。

订阅我们的Newsletter
带来每周的亮点、分析和故事,直接从我们发送到您的收件箱,没有其他内容干扰。
立即订阅