
通过视网膜成像和可信人工智能早期检测痴呆症
作者:Zhao, Yitian
介绍
痴呆症影响了全球约5000万个体,由于人口老龄化,患者数量正在增加。1开发新的方法来研究痴呆早期的病理生理学是必要的。当前的测试,如磁共振成像(MRI)和脑脊液中蛋白质生化定量检测,费用昂贵、耗时或具有侵入性,并且无法在大规模人群中使用。
视网膜被认为是一扇通往大脑的窗口,因此可能为研究痴呆早期病理生理过程中神经退行性变化和微血管改变提供机会。2,3尸检病例的组织病理学报告确认了阿尔茨海默病(AD)患者视网膜微血管的变化。4多项临床研究支持了这一理论,证实了阿尔茨海默病患者视网膜血管、不同口径的血管以及optic disc周围和视网膜结构的变化。5,6,7,8这些变化可以通过眼科成像方式检测,例如彩色眼底照相(CFP)、光学相干断层扫描(OCT)和光学相干断层血管成像(OCTA)。目前,积累的证据表明,视网膜成像工具可能为痴呆早期病理生物学的研究和管理提供有用的生物标志物。
CFP成像在可及性和成本方面具有优势。然而,其分析主要检测视网膜微血管的变化,这些变化局限于动脉和静脉(直径为60-300 μm),由于图像分辨率的限制。9并且在检测疾病非常早期阶段的更微妙的血管变化方面存在挑战,例如轻度认知障碍8,9OCTA是一种新型成像模式,能够无创且快速地以高分辨率(5–6μ m直径)成像视网膜微血管包括毛细血管。此外,该技术提供了深入的信息,允许在不同的视网膜层和脉络膜中可视化并表示视网膜微血管网络以及中央凹无血管区的结构。
最近在人工智能(AI)方面的进展,特别是深度学习,已经使得利用眼部成像进行阿尔茨海默病检测的新方法成为可能。一项使用机器学习模型的开创性研究显示10对CFP分析的结果显示阿尔茨海默病患者和对照组之间的视网膜血管网络存在显著差异。Tian等人的研究。11开发了一个多阶段的机器学习管道,使用从CFP图像中提取的血管图,并报告了AUC为0.87的阿尔茨海默病分类结果。Kim等人。12设计了一个基于注意力的端到端卷积神经网络(CNN)模型,用于基于CFP的阿尔茨海默病分类。最近,Cheung等人。7在多中心的CFP数据集上训练了一个深度学习算法用于AD检测,获得了AUC为0.93的结果。Xie等人的研究。8使用了两阶段的CNN网络来提取OCTA图像中的血管,并提出了12个参数来研究视网膜结构变化与阿尔茨海默病(AD)之间的关联。尽管这些方法显示出潜力,但大多数依赖于CFP图像,缺乏基于大规模OCTA数据的端到端深度学习检测模型。此外,OCTA数据的多维度特性需要能够有效处理和整合多层次信息的算法。从OCTA图像中进行精确特征提取和挖掘需要仔细关注不同投影层之间的相互关系和互补性。由于设计重点在于CFP图像的特点,针对CFP数据开发的算法不适用于此任务。更重要的是,大多数现有的端到端深度学习方法缺乏可解释性。这使得向临床医生和研究人员提供有信息量的疾病见解变得具有挑战性。
另一方面,针对痴呆症早期检测的研究工作非常少。例如,早发性阿尔茨海默病(EOAD)——在65岁以下的人群中诊断出来的——为识别可能适用于散发性阿尔茨海默病的诊断指标提供了一个有希望的方向。轻度认知障碍(MCI)可能是记忆或认知能力丧失的早期阶段,并且是认知正常和阿尔茨海默病痴呆之间的中间阶段,有可能退化为阿尔茨海默病痴呆。Cheung等人。7设计了一个使用CFP区分阿尔茨海默病患者和对照组的AI模型,并取得了令人鼓舞的检测结果,AUC为0.93。然而,尚不清楚该方法是否可以用于检测早发性阿尔茨海默病(EOAD)和轻度认知障碍(MCI)。几项研究观察到,EOAD和MCI患者在深血管复合体中表现出显著的微血管形态变化,但CFP缺乏足够的分辨率来捕捉与早期病理相关的细微微血管变化。因此,能够检测如EOAD或MCI等痴呆症的工具将在治疗更加有效时为患者带来巨大的好处。
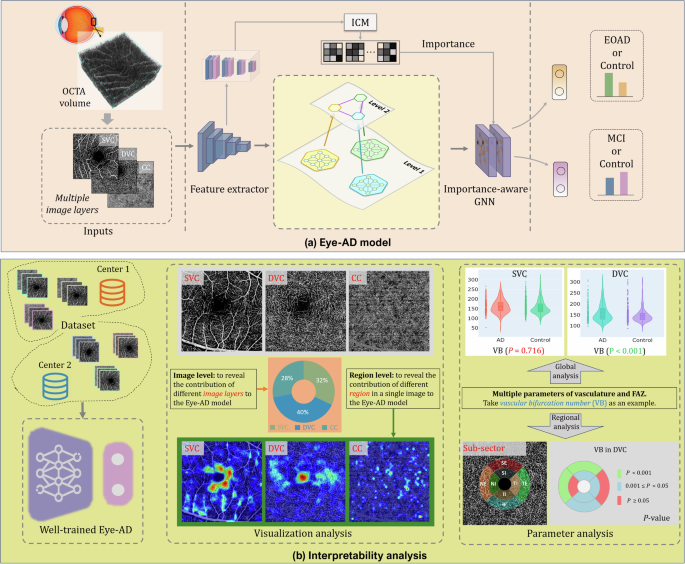
在这项工作中,我们提出了一种新颖的可解释的基于图的深度学习模型,名为Eye-AD,通过OCTA图像的独特特征来识别早发性阿尔茨海默病(EOAD)和轻度认知障碍(MCI)个体。该定制模型探索了不同视网膜和脉络膜层之间的实例内部和实例间的关系,并利用了OCTA数据的独特能力。我们将这种创新的人工智能方法与传统的生物标志物分析方法相结合,从而能够对模型的决策进行全面、可解释的评估并增强其可信度。这样的结合提供了进一步了解痴呆症对视网膜和脉络膜血管影响的见解。我们的研究工作流程如图所示。1实验结果证实,Eye-AD 在识别早发型阿尔茨海默病(EOAD)和轻度认知障碍(MCI)方面优于其他方法。来自可视化和可解释性分析的结果表明,Eye-AD 展示了与先前临床发现一致的决策模式。因此,我们的 Eye-AD 可能为在大规模人群中快速识别和筛查与痴呆症相关的疾病提供一个有用的工具。

a三个正面的;直接的视网膜图像被输入到特征提取器中以获取用于构建多级图的初始特征。然后使用一个感知重要性的图神经网络(GNN)模块来获得预测结果。b我们对训练好的Eye-AD进行了可视化和参数分析,并将Eye-AD学习到的显著模式(图像级和像素级)与传统的手工特征统计分析(全局和区域特征)进行了比较。分析了多个全局血管和黄斑无血管区(FAZ)参数,以比较不同特征的重要性。正面的;面对的对FAZ周围血管结构的亚区域参数分析也进行了评估,以确定EOAD/MCI组和对照组在这些区域是否存在显著差异。
结果
人口特征
本研究中使用的OCTA图像来自一个多中心病例对照研究,该研究涉及四个用于EOAD和MCI检测的中心。参与者的纳入和排除标准如图所示。2研究数据的详情在“方法”部分中描述。

研究数据包括基于视网膜OCTA的轻度认知障碍(EOAD)检测数据(ROAD-I,ROAD-II)和基于视网膜OCTA的轻度痴呆症前期检测数据(ROMCI-I和ROMCI-II)。我以及E分别表示内部和外部数据集。
队列参与者的人口统计详情见表所示。1我们的最终EOAD检测数据包括来自870名参与者的1192只眼睛。EOAD组与对照组之间年龄差异 marginaly 显著。(注:原文中"marginally"可能为拼写错误,若需准确翻译,请确认单词正确性。)p=P=0.049),早发性阿尔茨海默病患者平均年龄稍大。早发性阿尔茨海默病患者的高血压和糖尿病的患病率较高(p小于0.001),以及受教育年限较少(p= 0.021),与对照组相比。用于检测MCI的数据包括来自551名参与者的725只眼睛。MCI患者明显比对照组年长(p等于0.002)。此外,MCI患者高血压的患病率更高(p < 0.001).
EOAD检测性能
我们首先使用内部数据集ROAD-I评估Eye-AD在EOAD检测中的表现,定量结果见表。2五种基于最新CNN的方法和三种基于GNN的方法被选中进行比较。这些方法都需要为不同场景提供多个输入,包括早期融合。13中端融合14晚期融合15, MCC16黏液17GCN18, GAT19以及 UG-GAT20我们也选择了两种基于ViT的方法进行比较,包括ViT21和SwinV2-T22.
如表所示2,我们在ROAD-I数据集上的眼底血管异常检测模型Eye-AD在五个评估指标(准确率0.8885、精确率0.8862、F1值0.8867、Kappa系数0.7018和AUC 0.9355)上均超过了所有对比方法。值得注意的是,通过成对DeLong检验评估时,我们的方法在AUC指标上取得了统计显著性提升。此外,在给定数据集规模较小的情况下,基于CNN的方法和基于GNN的方法比ViT类模型表现得更好。由于参数量巨大且需要大量训练数据才能达到峰值性能,ViT模型容易过拟合并在当前数据集中表现不佳。MCC方法与其他多输入方法相比表现出较差的性能,这可能是由于该方法专为处理多重加权磁共振成像(MRI)设计而造成的结果。不同MRI输入结构相似,而多个OCTA结构则不同。正面的;直接的输入变化范围很大,这使得MCC在这种任务中表现不佳。此外,基于GNN的方法比使用CNN的方法表现出色。这可能是由于GNN更擅长建模和挖掘区域与实例之间的关系,并利用不同方面的相关性和互补性。正面的;直接面对的用于分类的图像。
Eye-AD模型的泛化性能在外部数据集ROAD-II上进行了验证。定量结果如表所示。2与内部数据集ROAD-I相比,虽然在ROAD-II上所有对比方法的总体性能如预期较低,但提出的Eye-AD方法再次取得了最佳表现,在准确率(0.8176)、精确率(0.8429)、F1值(0.8291)、Kappa系数(0.5865)和AUC(0.9007)方面均优于所有竞争对手。这表明提出的方法能够有效提取用于可靠EOAD检测的判别性特征,并且该模型在不同医院采集的数据集中表现出稳定性。
MCI检测的性能
我们也训练和评估了Eye-AD在MCI检测中的表现:结果如表所示。2Eye-AD 在与其它方法相比时,达到了最高的准确率(0.8487)、精确度(0.8506)、F1 值(0.8410)、Kappa(0.6229)和 AUC(0.8630)评分。ROAD 和 ROMCI 中的图像使用了不同的 OCTA 系统获取,这使我们能够在不同任务和机器设置下评估模型的泛化性能。此外,ROMCI 使用的数据量比 ROAD 小,使得模型训练更容易出现过拟合问题。
所有方法在ROMCI-II上的整体表现均不如在ROMCI-I上的表现,而提出的Eye-AD方法在准确率(0.8444)、精确率(0.8392)、F1值(0.8339)、Kappa系数(0.5489)和AUC(0.8037)方面表现出最佳性能。基于GNN的方法比基于CNN的方法表现更好,这表明考虑不同区域和实例之间的关系对于MCI检测至关重要。结果验证了我们模型在由不同医院采集的数据集上进行MCI检测的有效性和泛化能力。
可解释性分析
为了理解Eye-AD模型的决策过程并识别其检测阿尔茨海默病能力中的可辨识模式,我们进行了广泛的可视化和统计分析。我们将Eye-AD的决策模式与通过传统参数分析获得的结果进行比较。8通过这些比较,我们旨在评估Eye-AD的决策过程与以往研究结果的一致性,并确定它是否在传统的参数统计方法之上提供了任何显著优势。具体来说,我们首先使用ROAD数据集对Eye-AD进行训练,并获得每个OCTA病例在图像级别和像素级别的重要性分布。我们还计算所有样本的平均重要性分布,从而能够识别Eye-AD决策过程中的普遍趋势和模式。同样的预处理步骤也应用于ROMCI数据集。结果如图所示。3.

我们展示了不同输入的图像和区域级别的重要性。图像级别的重要性以百分比形式(红色)显示在每个图像的左上角。最后一行显示了所有案例的重要性的平均分布,其中我们可以识别出Eye-AD决策过程中的总体趋势和模式。
此外,我们还提取了八个不同的参数,这些参数描述了视网膜微血管和黄斑无血管区(FAZ)的特征。8,包括血管长度密度(VLD)、血管面积密度(VAD)、血管分叉数(VB)、血管分形维度(VFD)、黄斑中央凹区域面积(FA)、黄斑中央凹区域圆形度(FC)、黄斑中央凹区域圆整度(FR)和黄斑中央凹区域 solidity(FS)。然后我们研究EOAD/MCI组与对照组之间的差异。结果见图。4.

a显示EOAD与对照组比较的结果:b展示了MCI组与对照组之间的结果。
关于图像级别的重要性,可以观察到DVC的贡献通常大于SVC或CC,对于EOAD和MCI病例,其平均重要性得分分别为40%和49%,如图所示。3全局参数统计分析显示了类似的模式,如图所示。4对于ROAD数据集,SVC中的八个参数中有三个在EOAD组和对照组之间显示出显著差异,而DVC中的五个参数则显示了显著差异。MCI组与对照组之间的参数统计分析进一步支持了这些结论,如图所示。4DVC显示了更多具有显著差异的参数(两个参数),而SVC则显示了一个参数。这项研究证明了眼AD可解释性与视网膜微血管和FAZ特征分析之间存在强烈且一致的相关性,表明DVC在EOAD和MCI检测中扮演着更为重要的角色。此外,在EOAD和MCI的可解释性分析中最显著的区别是,无论是在SVC层还是DVC层,EOAD组间的差异都比MCI更大。这表明EOAD对视网膜结构的影响比MCI更严重。主要原因可能是虽然EOAD发生在65岁以下的人群中,但其症状可能与其他类型的AD一样严重,从而对其视网膜结构产生更大的影响。另一方面,MCI代表早期痴呆阶段,具有较轻的症状,导致视网膜变化不那么明显。这表明随着症状的恶化,痴呆对视网膜结构的影响变得更加显著。此外,在EOAD和MCI的可解释性结果中也存在类似的模式。对于这两种情况而言,DVC层之间的组间差异都大于SVC层。这种一致性表明视网膜较深层的变化可能是早期痴呆阶段更为敏感的指标,无论具体类型如何。
图示3显示每个的注意力图正面的显示EOAD/MCI和对照组的图像。它揭示了在SVC中,对照组的激活区域主要围绕FAZ和大血管;而在EOAD病例中,位于较大血管之间的较小血管区域被激活。在DVC中,激活区域主要集中在FAZ及其周围的血管上。与对照组相比,EOAD病例中的激活区域更大。CC的激活程度在AD和对照组之间差异很大,AD病例中有更多的激活区域。所有样本的平均激活图表明,FAZ及其周围血管最有可能被激活,这表明EOAD最有可能导致围绕FAZ的毛细血管发生变化。为了证实这一点,我们对围绕FAZ的微血管进行了子区参数分析,如图底部所示。4我们发现,在SVC和DVC的微血管参数中,有几个子区域显示EOAD组与对照组之间存在显著差异,表明围绕FAZ的微血管在EOAD中发生了可检测的变化。ROMCI分析的结果与ROAD相似,但ROMCI中有显著差异的参数和区域比ROAD少,如图所示。4.
讨论
我们提出了一种基于深度学习的新型模型Eye-AD,利用OCTA图像来检测早发性阿尔茨海默病(EOAD)和轻度认知障碍(MCI)。我们的方法已经展示了其在大规模人群中准确识别和快速筛查EOAD/MCI方面的潜力。此外,它提供了可信且可解释的结果,通过利用OCTA数据中的丰富空间信息来改善分析。以往的研究报告了OCTA图像中发现的生物标志物与阿尔茨海默病之间的相关性。8,23因此,使用视网膜OCTA图像可能在加速阿尔茨海默病筛查方面具有优势。与传统的阿尔茨海默病诊断方案相比,视网膜成像成本更低、更简单快捷,并且更适合小型医院或社区筛查项目,后者依赖一系列复杂和昂贵的程序,如认知评估、神经影像学检查以及脑脊液生物标志物证据。视网膜的不同层包含不同类型的信息,共同提供视网膜变化的一个相对完整的画面。SVC由大小血管混合组成,具有向心分支模式,并在FAZ周围终止于毛细血管环。DVC由排列成叶状图案且没有方向偏好的薄层毛细血管构成。CC包含了丰富的关于脉络膜循环的血管信息。24提出的Eye-AD模型采用了一种新颖的多层次图方法来建模和利用不同视网膜层之间的内部和外部实例关系,并充分地利用和融合这些层次信息以提高在阿尔茨海默病(AD)检测中的表现。在社区环境中快速识别潜在的AD患者将有助于及时转诊进行进一步检查,以及尽早治疗获得最佳结果。为此,识别具有前驱性AD或轻度认知障碍(MCI)的患者是可行且更有价值的。在这项工作中,我们在轻度认知障碍数据集上评估了我们的Eye-AD模型。我们的结果显示,MCI检测表现令人满意(内部:AUC = 0.8630;外部:AUC = 0.8037)。然而,与EOAD(早发型阿尔茨海默病)检测结果相比,MCI检测更具挑战性,可能是因为随着痴呆的发展,视网膜微血管系统可检测的变化仅缓慢积累。未来的研究可以提高Eye-AD模型在MCI检测中的敏感性和特异性:结合从眼底扫描中提取的生物标志物和其他非侵入性、易于获取的方法(如血液检查或认知测试)作为可能的解决方案。
Eye-AD提供了一个可靠且可解释的检测结果。先前的研究通过分析各种可能相关的微血管参数来探索阿尔茨海默病患者视网膜的变化。5,6,8,25,26,27这些研究得出的结论一致性较差,甚至互相矛盾。例如,几项研究表明8,25,26建议AD患者在SVC中的微血管显著减少,而对照组中两个小组之间的DVC没有观察到显著差异。相反,其他报告指出5,6发现DVC在阿尔茨海默病(AD)组和对照组之间存在显著差异,而在SVC中未发现显著差异。之前研究得出的矛盾结论可能是由于多种原因造成的。首先,大多数研究所采用的样本量相对较小,多数使用少于100名参与者:这可能导致结果容易受到数据集内在偏差的影响。此外,这些研究依赖于手工设计的特征,在计算相关参数之前需要先提取视网膜结构。所选择的参数可能不足以全面评估微血管变化,并且可能会因先前结构提取精度的变化而受到影响,从而导致不同研究之间结果不一致。我们的研究涉及1671名参与者,形成了迄今为止用于研究OCTA预测EOAD和MCI能力的最大OCTA数据集。分析Eye-AD的可解释性表明,与EOAD/MCI相关的视网膜变化会影响SVC和DVC,对DVC的影响可能更大。这一点由各自的不同贡献所证实。正面的;直接的对模型预测的结果进行分析。为了进一步增强我们可解释性结果的可信度,我们进行了统计分析,结果显示DVC的更多参数与EOAD/MCI显著相关,而SVC则不然。Eye-AD的解释性结果表明,FAZ及其周围的微血管是诊断EOAD更为敏感的生物标志物。这一发现还得到了对微血管亚区段参数进行统计分析的支持。在图像级别的重要性方面,我们的研究结果显示DVC始终表现出更高的重要性得分(EOAD为40%,MCI为49%),与SVC和CC相比。这一观察结果与我们参数分析的结果一致,在参数分析中,更多DVC的参数显示出EOAD/MCI组与对照组之间的显著差异比SVC中的多。在区域级别的重要性方面,注意力图显示EOAD病例在SVC中小血管激活程度更高,并且在FAZ周围的DVC处表现出更大的激活区域,相比对照案例而言。此外,对FAZ周围微血管的亚区段分析发现,在EOAD和对照组之间存在显著差异,特别是在DVC中,支持了我们模型的解释性结果。这些结果显示Eye-AD可解释输出与传统形态学参数分析之间的强烈且一致的相关性,强调了DVC在检测EOAD和MCI中的关键作用。
我们的研究为理解阿尔茨海默病对视网膜的影响提供了帮助。从Eye-AD获得的可解释结果提供了宝贵的新见解。我们的发现表明,与感觉血管复合体(SVC)或脉络膜丛(CC)的变化相比,弥漫性血管复合体(DVC)的变化更显著地与早发性阿尔茨海默病及相关轻度认知障碍(EOAD/MCI)相关。DVC由毛细血管组成,并且具有薄的横截面,这使得它对疾病进展过程更为敏感。28重要的是,DVC负责视网膜的静脉循环。29最近的报告30,31,32已经强调了脑静脉退行性变在阿尔茨海默病(AD)中的作用;鉴于视网膜微血管反映大脑微循环,可以合理地认为这些视网膜变化反映了潜在的大脑变化。ROAD和ROMCI数据集的参数统计显示,在轻度认知障碍(MCI)组与对照组之间存在显著差异的参数比早发性阿尔茨海默病(EOAD)组与对照组之间的少。具体而言,DVC中的五个参数(VLD、VAD、VB、VFD和FR)在EOAD和对照组之间显示出显著差异,而仅两个参数(VAD和FR)显示MCI组与对照组之间存在显著差异。这些发现表明,在认知下降的早期阶段视网膜血管变化可能较为细微,但随着痴呆症的发展,视网膜微循环的退化会加剧。此外,消融实验表明,通过利用SVC、DVC和CC的互补信息,可以更准确地检测EOAD和MCI。此外,我们的研究发现EOAD与脉络膜之间存在关键关联,这由EOAD病例与对照组之间的CC像素级重要性分布差异所表明。尽管早期研究由于图像分辨率限制而未能充分探讨脉络膜在AD中的作用,但本研究表明脉络膜可以作为该疾病的潜在诊断生物标志物,如前所述。33随着OCTA技术的进步,未来的研究必须更加重视探讨脉络膜在快速筛查阿尔茨海默病(AD)中的作用。此类研究有望实现早期发现AD,为AD的诊断和干预提供重大益处。
提出的Eye-AD模型不仅为EOAD和MCI的快速检测和筛查提供了解决方案,还为理解视网膜生物标志物与痴呆之间的关联提供了可解释的深度学习模型的概念验证。然而,重要的是要承认我们研究的局限性。首先,尽管我们的数据集比以前关于EOAD和MCI的OCTA研究更大,但样本量对于深度学习而言仍然相对较小。特别是,我们的数据集中缺乏种族多样性。由于本研究仅限于中国人群,其在其他种族中的适用性尚不清楚。目前从EOAD患者中获取视网膜影像的困难限制了样本大小。此外,排除不能配合检查的患者可能会进一步偏斜结果。鉴于识别EOAD和MCI是一个有价值的任务,我们还在EOAD、MCI和对照组的样本上使用我们的模型和数据集进行了多标签识别任务。结果如下:准确率:0.8758 和 AUC:0.9320。然而,正如审稿人指出的那样,检测MCI和EOAD是一个更困难的任务,并且我们认为这些结果可能主要是由于数据异质性所致,尤其是用于检测MCI和EOAD队列的不同OCTA设备模型不同造成的这种差异可能会使模型学习到与疾病无关的信息。在未来的工作中,我们将建立更加同质化的队列以进一步研究痴呆症各个阶段对眼底的影响。其次,当前的模型仅关注视网膜OCTA图像,虽然很有价值,但可能无法捕捉到AD病理学的全貌。整合多模态数据,如血液生物标志物、基因信息和认知评估等,可以增强模型的预测能力和适用性。第三,在临床环境中部署Eye-AD面临许多挑战。这包括在不同设备和机构间标准化成像协议,确保数据隐私和安全以及获得监管批准等问题。解决这些问题需要研究人员、临床医生和政策制定者之间的合作努力。最后,纵向研究对于验证视网膜生物标志物预测认知能力下降进展的实用性是必要的。这类研究将提供关于AD和MCI中视网膜变化的时间动态的见解,并且可以帮助制定干预策略以阻止或减缓疾病的发展进程。简而言之,需要更大的纵向研究来评估视网膜生物标志物在不同人群中的适用性。未来的工作应集中于标准化早期AD检测的眼底影像和认知评估。
总之,我们提出了一种新颖的多级图深度学习模型Eye-AD,通过OCTA图像的独特特征来检测早发性阿尔茨海默病(EOAD)和轻度认知障碍(MCI)。该模型允许对不同视网膜层次之间的实例内和实例间关系进行重要的探索和理解。Eye-AD在区分AD患者与健康对照方面达到了最先进的性能水平。当在外部数据集上验证时,该模型也表现出其泛化能力。我们的可解释性分析显示,Eye-AD可以识别出与EOAD/MCI相关的有意义的模式。我们发现DVC的变化比SVC或CC的变化更显著地与EOAD/MCI相关联。我们也发现,在认知功能下降的早期阶段视网膜血管改变可能是微小的,并且随着痴呆症的发展,视网膜微血管结构会进一步恶化。我们的研究结果提供了证据表明结合了人工智能技术的视网膜OCTA成像可以作为EOAD和MCI检测与筛查的一种快速非侵入性方法。尽管我们的研究在理解视网膜变化与EOAD/MCI之间的关联方面取得了进展,但仍需进行更多的后续研究。通过结合多种数据模式并扩大数据集,所提出的模型具有在大规模社区筛查以及阿尔茨海默病的纵向监测中应用的潜力。
方法
学习数据
研究数据包括基于视网膜OCTA的EOAD检测(ROAD-I,ROAD-II)和基于视网膜OCTA的MCI检测(ROMCI-I和ROMCI-II)的数据。本研究已获得中国科学院宁波材料技术与工程研究所先进诊疗材料和技术实验室伦理委员会及四川大学华西医院伦理委员会的批准(伦理编号2020[922])。所有获取的OCTA图像都以中央凹为中心,并且正面的浅层血管复合体(SVC)、深层血管复合体(DVC)和脉络膜毛细血管(CC)的图像用于分析24任何主题的图像仅用于训练集或测试集之一,以避免信息泄露。OCTA成像设备包括内置的校正算法,可以从图像中移除伪影。为解决潜在的数据偏差问题,我们确保了在相同任务中使用相同的采集设备型号。此外,在建立队列时,我们在不同机构之间应用了相同的数据纳入和排除标准。
EOAD研究(ROAD)的视网膜OCTA数据包含一个内部(ROAD-I)和一个外部(ROAD-II)子集。ROAD-I用于开发和内部测试提出的Eye-AD模型以检测EOAD,而ROAD-II仅用于其外部测试。公路-I包含中国宁波大学附属人民医院的810份OCTA数据卷,其中包括199份EOAD患者的OCTA数据卷和611份对照组的数据卷(每位患者每只眼睛一个数据卷)。EOAD患者符合美国国家老龄化研究所和阿尔茨海默病协会(NIA-AA)的标准。34并且在65岁之前被诊断出来。纳入标准如下:具有签署知情同意书的能力,或者如果存在认知障碍,则有合法授权的代表能够提供知情同意;能够完成OCTA成像;并愿意且有能力完成所有研究程序。排除标准如下:不处于怀孕或哺乳期;无其他脑部疾病史(包括神经学和精神疾病的病史,但与早发性阿尔茨海默病相关联的癫痫发作以及头痛除外);未参加过治疗试验;过去12个月内没有滥用药物或自杀行为的历史。具有MRI证据表明存在感染、局灶性病变如中风、多处或多策略腔隙和/或占位性病变的个体也将被排除在外。对照组为无痴呆症或认知障碍的人群,定义为在神经心理学评估中没有任何客观上的损害。这些参与者没有神经系统疾病。我们采用五折交叉验证的方法来训练和评价模型。每个单独的数据折(20%)依次用作内部测试集,而其他四个数据折(80%)则作为训练集。ROAD-II这是一个从不同医院(四川大学西川医院,中国成都)独立获取的数据集,旨在进一步评估我们Eye-AD模型的泛化能力。纳入/排除标准与ROAD-I中的相同。该数据集中包含382个OCTA体积数据,其中包括150个EOAD患者的OCTA体积数据和232个对照组的OCTA体积数据。
黄斑变性认知障碍研究(ROMCI)的视网膜OCTA数据也包括一个内部子集(ROMCI-I)和一个外部子集(ROMCI-II),用于验证检测MCI模型的有效性。ROMCI-I参与者来自中国杭州浙江大学第二附属医院。最初,MCI(轻度认知障碍)患者由一位经验丰富的神经学家根据Petersen诊断标准和建议进行临床评估和诊断。35临床病史、认知测试和神经影像由专门研究记忆障碍的有经验的神经学家进行了诊断准确性评估。排除标准为:(1)显著的感觉功能障碍,例如言语或听力障碍等;以及(2)存在重度抑郁或其他精神疾病。总共使用了545个OCTA数据集来构建该数据集,其中包括104个MCI患者的OCTA数据和441个对照组的OCTA数据。我们采用五折交叉验证的方法来进行模型开发与性能评估。ROMCI-II受试者来自宁波大学附属人民医院,中国的入选标准与ROMCI-I研究中的轻度认知障碍患者和对照组的纳入标准相同。该第二数据集包含180个OCTA体积数据,其中包括35个轻度认知障碍患者的OCTA体积数据和145个对照组的OCTA体积数据。
模型架构
Eye-AD包含两个主要组件:用于嵌入提取的CNN和用于最终预测的多级GNN,如图所示。5我们应用ResNet1836作为编码器,保留前四个块。输入正面面对图片Xk ∈ X大小为h × w被划分为n × n不重叠的区域。k ∈ [1, K], 和K是总共的数量为正面地;直接面对地患者的图像。

aEye-AD架构示意图,包括嵌入提取模块和诊断模块。b关于子图一致性的正则化细节。c重要性计算模块(ICM)的神经网络结构。
我们设计了一个分层多级图,包括实例级别的图和主题级别的图,以 modeling 不同实例之间的关系和内部关系。(注:modeling一词在这里可能是原文中的保留部分,若需翻译可改为“描述”或“建模”,此处保持原样)正面的血管造影片,如图所示。6我们从底层(即图中的第1层)构建图集。6从顶层(即图中级别2)开始6). 基于一个实例构建了实例级别的图正面的图像,然后基于实例级别的图构建主题级别图。每个区域都被视为一个实例级别图的节点,节点特征来自于编码器的最后一层,即ResNet18第四块的输出。根据图像中区域之间的邻接关系,在节点对之间分配无向边。我们描述\(\mathbb{G}=(\mathbb{V},\mathbb{E})\)作为实例级别的图,包含|\(\mathbb{V}\)|= \(n^2\)节点和(| \(\mathbb{E}\)|)边缘。∣ ⋅ ∣表示集合的基数。对于每个\(v_i \in \mathbb{V}\), hi是对应的F维特征向量。令\(H \in \mathbb{R}^{n^2 \times F}\)表示节点特征矩阵,和\(A^\mathrm{T}\in \mathbb{R}^{n^2\times n^2}\)为稀疏邻接矩阵,编码节点之间的边连接。实例级别的图被输入到感知重要性的图注意力层中以获得聚合嵌入,这些嵌入用于构建主题级别图。主题级图包括不同对象之间的关系正面的;直接的图像。它表示为\(\mathcal{G}=(\mathcal{V},\mathcal{E})\)主体级别的图是一个完全连接的图,其中每个节点代表一个主体。正面朝向图像实例,并且每两个实例之间都有一个边连接,kth节点功能的\(\mathbb{G}\)是聚合嵌入的\(\mathbb{G}^k\).

一级是实例级别的图,二级是主题级别的图。实例级别的图是基于一个实例构建的正面的;当面的图像,然后基于实例级别的图构建主体级别的图。
ICM由多个带有下采样操作的卷积层、一个最终带有池化操作的卷积层和一个 sigmoid 激活层组成,用于将特征映射到大小为的概率图形式中。n × n × K这可以被视为重要性。ICM将编码器的不同层次的特征作为输入,对应的输出是每个层获得的重要性。正面的;直接的如图所示。5ICM的输出首先被应用于CNN模块预训练过程中的重要性聚合。具体来说,不同的重要性图分别与对应的编码特征相乘,然后将结果输入全连接层进行分类。这一操作确保了ICM可以在CNN预训练阶段进行训练。此外,在图卷积运算中还会使用到重要性矩阵,如公式(所示)。1)–(4).
具体地说,给定一个实例级别的图\(\mathbb{G}^k=(\mathbb{V},\mathbb{E})\)具有节点特征的一组节点\(h=\left\{\vec{h}_{1},\vec{h}_{2},..., \vec{h}_{{n}^{2}}\right\}, \vec{h}_{i} \in \mathbb{R}^{F}\)IAGAT层更新节点特征并获得新的嵌入,即\({h}^{{\prime} }=\left\{{\vec{h}}_{1}^{{\prime} },{\vec{h}}_{2}^{{\prime} },...,{\vec{h}}_{{n}^{2}}^{{\prime} }\right\},{\vec{h}}_{i}^{{\prime} }\in {{\mathbb{R}}}^{{F}^{{\prime} }}\),和\(F'\)是更新后的节点特征的维度。更新的详细信息如下。首先,通过由共享权重矩阵参数化的线性变换\(W\in \mathbb{R}^{F'^{\times}F}\) 注意:上述表达式中的“\(^{\times}\)”可能是符号错误或特殊含义,通常情况下应为“\(\times\)”表示矩阵的维度。如果“\(^{\times}\)”是特定上下文中的一个特殊符号,请根据具体情况调整翻译。为每个节点分配。然后我们计算注意力系数eij使用自注意力操作:
$${e}_{ij}=\text{LeakyReLU}({\vec{a}}^T[W{\vec{h}}_i\parallel W{\vec{h}}_j]),$$
(1)
哪里eij ∈ E表示节点的注意力值j连接到节点i,并且 \(E \in \mathbb{R}^{n^2 \times n^2}\)是注意力系数矩阵。∥是连接操作:\(\vec{a}^{T} \in \mathbb{R}^{2F'}\)是一个由全连接层实现的学习权重向量,后面跟着带负输入斜率的LeakyReLU激活函数α = 0.2).
考虑到每个区域在疾病诊断中的重要性,即实例级别图的节点,我们使用ICM获得的重要性值重新加权注意力系数。我们用重要性矩阵表示为\({{\mathbb{G}}}^{k}\)作为Mk,其大小为n2重新加权操作定义为:
$${E}^{\prime}=E(\text{Diag}(M^k)),$$
(2)
哪里Diag(⋅)是对角化操作。然后我们对系数进行归一化处理\({e_{ij}}'\)使用softmax函数使其在不同节点之间可以比较:
$${\alpha }_{ij}=softmax_j({e}_{ij}^{\prime})=\frac{exp({e}_{ij}^{\prime})}{\sum_{l \in N_i} exp({e}_{il}^{\prime})},$$
(3)
哪里Ni表示节点的邻域i在图中显示仅有多项式函数满足条件,其余函数不满足。如果不包含具体上下文,默认只翻译给出的部分:“在图中显示仅有”。请根据实际需求调整。如果要求严格按照给定文本翻译且无更多上下文,则输出原文:" 在图中显示仅有 "\({e_{ij}}'\)对于相邻节点j ∈ Ni在更新节点特征时会考虑到这一点,以避免涉及不相关的节点。最后,我们使用归一化的注意力系数αij计算参与节点特征的加权和以获得每个节点的更新后的特征:
$${\vec{h}}_{i}^{{\prime} }=\text{ELU}\left(\sum _{j\in {N}_{i}}{\alpha }_{ij}W\,{\vec{h}}_{j}\right),$$
(4)
其中 ELU 表示指数线性单元(ELU)非线性函数。通过这种方式,所提出的 IAGAT 层可以通过级联更新后的节点特征来提取实例嵌入。\(\mathbb{G}^k\),用于构建主体级别的图\(\mathcal{G}\)然后,我们使用GAT层19一种流行的带有注意力机制的GNN方法作为提取器来获取主体特征。最后,将主体特征输入全连接层,然后通过softmax激活层进行最终的主题分类。
为了提高泛化能力并捕捉同一主体的不同子图之间的细微差异,我们设计了一个基于子图一致性正则化的损失函数(SCR)。该SCR从同一个主体级别的图中随机抽取两个子图,并最小化它们的平方差L2在通过两层MLP网络之后的距离。具体来说,对于每个输入,生成一个由不同投影层组成的具有n个节点的图。在训练过程中,通过对n个节点进行随机采样来从n个节点中抽取两个不同的n-1节点子图。我们希望这两个子图所表示的与疾病预测相关的特征保持一致,这是通过SCR损失函数的一致性约束实现的。这种SCR鼓励模型学习更加稳健和判别性的表示形式,可以捕捉同一主体的不同子图之间的细微差别,从而提高模型的泛化能力。这一正则化项对于小数据集特别有效,在这些数据集中过拟合是一个主要问题,并且在我们的实验中已经证明它可以改善分类性能。
训练策略
Eye-AD是一个端到端的框架。我们在实践中发现,合适的训练策略对于获得一个良好的模型至关重要。为了提取更多具有区分性的与疾病相关的嵌入并向量并加快收敛速度,我们添加了一个中间目标。\({{\mathcal{L}}_{CE}(\hat{y}_{CNN},y)}\)对于CNN组件,如图所示。5Eye-AD中的总损失包括CNN损失\({{\mathcal{L}}_{CE}(\hat{y}_{CNN},y)}\)一致性损失\(\mathcal{L}_{SCR}\)最终预测损失\({{\mathcal{L}}_{CE}}(\hat{y}, y)\)由于CNN和GNN具有不同的收敛特性,通过最小化这三种损失的总和同时训练CNN和GNN可能会导致模型陷入局部最优解甚至造成梯度消失。因此,我们采用交替策略来更新模型。为了加速收敛,我们首先预训练CNN,然后进行联合交替训练。在第一步中,我们仅通过最小化来优化CNN\(\mathcal{L}_{CE}(\hat{y}_{CNN}, y)\)然后通过最小化损失的总和来更新GNN模型的参数\({{\mathcal{L}}_{CE}}(\hat{y}, y)\)和\({{\mathcal{L}}_{\text{SCR}}}\)最终,通过最小化最终预测损失来优化CNN\({{\mathcal{L}}_{CE}(\hat{y},y)}\)上述交替过程通过训练迭代重复进行。我们在补充算法中总结了训练策略。1提出的训练策略的有效性如图所示。7.

通过使用提出的训练策略,模型可以更容易地收敛到全局最优解,从而实现更好的性能。
实现细节
所有的实验均使用PyTorch实现,并在配备4块NVIDIA GeForce 3090 GPU的工作站上运行。我们采用ResNet18作为CNN分支中嵌入提取器的骨干网络。第1级图模块由一个IAGAT层和一个GAT层组成。第2级图模块包含一个GAT层和一个全连接层,之后是一个用于主题分类的softmax激活层。在GNN分支中的IAGAT和GAT层均具有两个注意力头,每个头计算512维特征。
使用Adam优化器来优化模型,权重衰减设置为0.0005,批量大小为16。CNN和GNN的初始学习率分别设置为0.0001和0.00001,并通过余弦退火调度程序逐渐衰减至零。权衡因子λ设置为2。不同步骤的迭代次数分别为,K1, K2,和K3这些值分别设置为1、4和1。此外,采用了数据增强方法,包括随机水平和垂直翻转以扩充训练数据集。对于训练好的模型,图像级别的重要性计算如参考文献所示。37,而像素级别是使用Grad-cam计算的38.
我们计算了不同模型的参数大小和FLOPS。从表中可以看到3很明显,不同方法的参数大小和FLOPs存在显著差异。例如,MCC方法具有最高的参数大小,为94.37 M,表明其模型更为复杂且可能需要更高的计算资源。相比之下,早期融合方法(Early Fusion)拥有最低的参数大小,仅为11.87 M,这表明该模型较为简单,并且对计算要求较低。在FLOPs方面,UG-GAT展示了最高的计算复杂度,为54.19 GMacs,而早期融合方法再次表现出最低的复杂度,为5.36 GMacs。我们提出的方法参数大小为66.32 M,FLOPs为33.83 GMacs,在模型复杂性和计算效率之间实现了平衡。这种平衡对于需要高性能同时又可管理资源的应用至关重要。
消融实验
我们进行了消融研究,以调查不同组件在内部ROAD数据集上的影响。在Eye-AD中,通过将图像分割为若干部分来构建实例级图。n × n补丁。为了调查补丁大小对结果的影响,我们将图像分别划分为3×3、5×5、7×7和9×9的补丁,对应于实例级别图中的9、25、49和81个节点。如表所示4可以看出,5×5配置获得了最高的AUC值,而9×9配置的得分略低于其他配置。一个可能的原因是如果一个节点中的区域太小,则包含的像素较少,从而提供的疾病检测信息量也较少。
表格5展示了提出的Eye-AD模型在包含和不包含某些提议组件情况下的结果。可以看出,使用ICM(兴趣区域引导的对比记忆模块)将F1分数从0.8539提高到了0.884。我们也研究了SCR(空间对比关系)的有效性。在移除它之后,Eye-AD模型的各项性能指标均有所下降,尤其是在Kappa系数方面,从0.6943降到了0.6322。
然后我们研究了利用不同因素之间相关性和互补性的重要性。正面的特别是,我们通过用三个相同的输入替换不同的输入来比较仅使用SVC、DVC和CC时的性能。表6展示了Eye-AD在使用来自ROAD数据集的不同输入时的表现。很容易观察到,多输入在所有指标上都优于单一输入,表明多种输入可以为模型提供更多信息,从而导致更准确和可靠的结果。此外,我们还可以看到,当仅使用DVC作为输入时,其总体表现优于SVC或CC。
此外,我们进行了实验以研究不同编码器对性能的影响,包括ResNet18、ResNet50、DenseNet、EfficientNet、ConvNeXt和ViT。如表所示7不同基于CNN的特征提取器之间的性能差距并不显著,ConvNeXt仅以微弱优势领先。这表明分类性能的关键在于不同层之间特征融合的能力,并且通用的特征提取器已经足够满足我们的需求。此外,基于ViT的编码器表现较差,可能是因为ViT模型需要大量的训练数据才能达到最佳性能。在我们目前的数据集上,ViT容易过拟合并比CNN取得更差的结果。
统计分析
为了分析微血管和FAZ的参数,我们首先使用多任务学习方法提取视网膜结构,即微血管、FAZ和血管分叉点。39最终的血管和FAZ检测结果是使用OTSU自动阈值法获得的。然后计算了八个参数,包括血管长度密度(VLD)、血管面积密度(VAD)、血管分叉数(VB)、血管分形维数(VFD)、黄斑注视区面积(FA)、黄斑注视区圆形度(FC)、黄斑注视区圆整度(FR)和黄斑注视区紧凑度(FS)。
-
语音活动检测(Voice Activity Detection)定义为单位分析图像面积中的灌注视网膜微血管的总长度(以毫米为单位)。
-
VLD定义为微血管中心线上的总像素数与测量区域的比例。
-
变频驱动器是衡量血管全球分支复杂性的指标。
-
VB是分析区域内分支的总数。
-
FAFAZ区域的总像素数。
-
FC测量FAZ圆度的程度,计算公式为:FC = 4π*FA/FP2. FPFAZ的周长。较大的FC值表示更接近圆形的形状。值为1.0表示完美圆圈。
-
原文:FR类似于FC,但对FAZ周边不规则边界的敏感度较低,计算公式为:\(FR=4\pi \times FA/{L_{major}}^2\). /Lm一个jor是FAZ的主要轴向长度。
-
FS描述FAZ的凸度或凹度的程度:它被定义为FAZ面积与其覆盖FAZ的凸包面积之比。固实度偏离1越远,结构的凹陷程度越大。
我们探讨了这些参数在全图以及子区域中阿尔茨海默病组与健康对照组之间的差异。子区域包括上内侧、颞下内侧、下内侧、鼻内侧、上外侧、颞下外侧、下外侧和鼻外侧。8我们使用带有广义估计方程的多元线性回归模型来关联阿尔茨海默病(AD)与视网膜微血管和黄斑中央凹区域(FAZ)的测量值,并调整年龄、性别、高血压、糖尿病和教育水平的影响。我们使用标准统计软件(SPSS,版本24.0,IBM,美国)进行分析。结果见表。8.
数据可用性
开发和验证数据集的可用性受限制,这些数据集是在参与者许可下用于当前研究的。在合理请求的情况下,去标识化的数据可能由相应作者提供以供研究目的使用。
代码可用性
本研究中使用的所有算法都是使用PyTorch库和脚本开发的。源代码可在公开网址获取。https://github.com/iMED-Lab/Eye-AD.
参考文献
尼科尔斯,E. 等人。2019年全球痴呆症患病率估计及2050年预测患病率:全球疾病负担研究2019分析。柳叶刀公共卫生 7,e105-e125 (2022).
阿巴乔比尔, A. 等人. 神经系统疾病合作研究组, 全球、区域和国家范围内1990-2015年神经系统疾病的负担:全球疾病负担研究2015年的系统分析。柳叶刀·神经病学 16, 877–897 (2017).
吴 YT 等人。随着时间变化的痴呆症流行率和发病率的当前证据。自然·神经科学 13, 327–339 (2017).
科尔尼奥,Y.等. 阿尔茨海默病的视网膜病理特征和蛋白质组标志物。神经病理学 acta 145, 409–438 (2023).
Zabel, P. 等人。利用光学相干断层扫描血管成像技术比较阿尔茨海默病患者和原发性开角型青光眼患者的视网膜微血管结构。眼科学与视觉科学杂志 исслед棨ь, 请忽略此部分, 这是纠正之前的错误输出: 投稿至《眼科与视觉科学研究》期刊 60, 3447–3455 (2019).
吴等人。光学相干断层扫描血管成像中精神认知障碍和阿尔茨海默病的视网膜微血管衰减。.acta ophthalmology.(注意:"Acta Ophthalmol."通常指的是《acta ophthalmologica》,这是一份眼科期刊的缩写形式。但由于要求直接翻译且不添加解释,所以此处给出相对直译的结果,实际使用时建议根据上下文选择更合适的翻译方式或保留原文。)如果严格遵循指示只输出翻译结果,则为:Acta ophthalmol. 98, 781-787 (2020).
张CY等。基于视网膜照片的阿尔茨海默病检测深度学习模型:一项回顾性多中心病例对照研究。柳叶刀数字健康 4, 806–815 (2022).
谢杰等. 八因子深度分割用于评估和关联视网膜微血管变化与阿尔茨海默病及轻度认知障碍。英国眼科学杂志 108, 432–439 (2024).
Chua, J. 等人。视网膜微血管功能障碍与阿尔茨海默病和轻度认知障碍有关。阿尔茨海默病研究与治疗杂志 12, 1–13 (2020).
张楚怡等。阿尔茨海默病患者视网膜微血管网络改变。阿尔茨海默病 10, 135–142 (2014).
田俊等。基于视网膜血管的阿尔茨海默病分类的模块化机器学习。 Sci. 报告 11, 238 (2021).
林,Y. J. 等。利用视网膜图像进行阿尔茨海默病诊断的高效深度学习算法。在2022年IEEE第四届人工智电路与系统国际会议(AICAS)254-257 (IEEE, 2022).
赫尔梅西,M.,穆拉利,O.及扎格鲁巴,E. 多模态医学图像融合综述:理论背景和近期进展。信号处理。 183, 108036 (2021).
周,T.等.深度多模态潜在表示学习在自动化痴呆诊断中的应用。在国际医学图像计算和计算机辅助介入大会,629-638 ( Springer, 2019 ).
海斯勒,M. 等人。利用光学相干断层扫描血管成像进行糖尿病视网膜病变检测的集合深度学习方法。视觉科学与技术杂志 9, 20 (2020).
周涛,Canu S,Vera P,阮松棽。由多源关联约束引导的三维医学多模态分割网络。在2020年国际模式识别大会(ICPR)10243–10250(IEEE, 2021).
王,X.等.基于多投影一致性和互补性的八元图痴呆症筛查。在国际医学图像计算与计算机辅助干预大会688–698 (施普林格,2022).
Kipf, T. N. & Welling, M. 基于图卷积网络的半监督分类。在国际学习表征大会 (2022).
维利科维奇,P. 等人。图注意力网络。统计学 1050, 10–48550 (2017).
郝杰等。基于不确定性引导的图注意力网络用于肺旁积液诊断。医学图像分析 75, 102217 (2022).
Dosovitskiy, A. 等。一图胜千文:大规模图像识别中的变压器。在国际学习表征大会 (2020).
刘,Z.等.Swin变压器v2:扩大容量和分辨率。在IEEE/CVF计算机视觉和模式识别会议论文集,12009–12019(IEEE,2022)。
卡茨普里斯,A. 等人. 光学相干断层扫描血管成像在阿尔茨海默病中的应用:系统回顾和元分析。眼睛 36, 1419–1426 (2022).
坎贝尔,J. 等人。利用投影解析光学 coherence 植入术血管成像的人眼视网膜详细血管解剖学。 注:这里的“coherence tomography”应翻译为“相干断层扫描”,整句更准确的翻译是:“Campbell, J. 等人。利用投影解析光学相干断层扫描血管成像技术的人眼视网膜详细血管解剖学。”科学报告 7, 42201 (2017).
Lahme, L. 等人使用光学相干断层扫描血管成像评估阿尔茨海默病的眼球灌注。阿尔茨海默病杂志 66, 1745–1752 (2018).
张YS等。光学相干断层扫描血管成像中遗忘性轻度认知障碍和早期阿尔茨海默病的旁黄斑血管丢失及周边视网膜血管密度与认知表现的相关性。PLOS.ONE 14吴0214685 (2019).
江,H.等.轻度认知障碍和阿尔茨海默病患者的黄斑微血管改变。神经眼科学杂志 北美神经眼科学会官方期刊 38, 292 (2018).
梁威,Olwen M.,Gonzalez C. N.,Calabresi P. A.及Shiv S. 光学相干断层扫描血管成像(OCTA)在神经科学研究中的新兴应用。眼睛视力 5, 11– (2018).
霍尔默,T. T., 贾,Y., 姬,Y., 黄,T. S. & 黄,D. 投影解析光学相干断层扫描血管成像下的视网膜血管解剖和病理的plexus特异性观察。程序性视网膜眼研究 80, 100878 (2020).
来,A. Y. 等人。转基因阿尔茨海默病模型中的静脉退化导致血管功能障碍。大脑 138, 1046–1058 (2015).
费舍尔,R. A.,米尼尔斯,J. S. & 爱德,S. 阿尔茨海默病脑血管病理变化:新视角。脑病病理学杂志 32吴13061(2022).
何丽等。动态脑自主调节对深髓静脉变化与脑小血管病关联的影响。生理学前沿 14, 1037871 (2023).
阿萨纳德,S. 等人。视网膜脉络膜作为阿尔茨海默病眼血管生物标志物的组织病理学研究(严重病例)。阿尔茨海默病诊断评估与监测杂志 11, 775–783 (2019).
McKhann, G. M. 等人. 阿尔茨海默病痴呆的诊断:来自美国国家老龄化研究所-阿尔茨海默病协会诊断指南工作小组的推荐意见。阿尔茨海默病 dementia 7, 263–269 (2011).
阿尔伯特等。轻度认知障碍(由于阿尔茨海默病)的诊断:来自美国国家老龄问题研究所-阿尔茨海默病协会工作小组关于阿尔茨海默病诊断指南的推荐。阿尔茨海默病 dementia 7, 270–279 (2011).
何凯明,张翔,任少卿,孙剑。深度残差学习在图像识别中的应用。在IEEE计算机视觉与模式识别会议论文集770–778 (IEEE, 2016).
陈泽,刘杰,朱明,伍佩玉,袁野. 基于实例重要性的图卷积网络在三维医学诊断中的应用。医学图像分析 78, 102421 (2022).
Selvaraju, R. R. 等人。Grad-CAM:通过基于梯度的定位从深度网络中获取视觉解释。在IEEE国际计算机视觉大会论文集618–626 (IEEE, 2017).
郝俊等人。基于投票的多任务学习在OCTA图像中检测视网膜结构。IEEE医学影像杂志 41, 3969–3980 (2022).
致谢
本工作部分得到了中国国家自然科学基金项目(62422122, 62272444, 62371442, 62302488)、中国科学院青年创新促进会(2021298)、中国浙江省自然科学基金(LR22F020008, LQ23F010007, LR24F010002, LZ23F010002)、浙江省重点研发计划项目(2024C03101, 2024C03204)和宁波市公益科技重点项目(2023S012)的支持。AFF 得到了英国皇家工程院主席 INSILEX(CiET1819\9)以及 UKRI 边缘研究保证 INSILICO(EP\Y030494\1)的支持。AFF 的研究在国家健康与护理研究所(NIHR)曼彻斯特生物医学研究中心(BRC)(NIHR203308)进行。
伦理声明
利益冲突
作者声明没有利益冲突。
附加信息
出版者注施普林格·自然对于出版地图和机构 affiliation 的管辖权主张保持中立。注意,affiliation(隶属关系或关联)这一术语在不同语境下可能有不同的翻译方式,在此处可以理解为“所属机构”的声明或关联,根据具体上下文选择最合适的翻译。如果需要更贴近原文的表达,则保留为“机构附属关系”。
补充信息
权利与许可
开放访问本文根据知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议发布,该许可协议允许任何形式和格式的任何非商业用途、分享、分发及复制,只要您适当引用原作者及来源,并提供链接至知识共享许可协议,并说明是否修改了受许可的内容。未经此许可协议授权,您无权分享基于本文或其部分内容改编的作品。除非另有声明,文中包含的图片或其他第三方材料均包括在文章的知识共享许可协议中。如果材料未包含在此文章的知识共享许可协议内且您的预期用途不受法律条文规定的豁免,则需要直接从版权所有者那里获得使用授权。要查看此许可证副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/.
关于这篇文章

引用这篇文章
郝嘉,Kwapong WR,沈婷婷等著述者通过视网膜成像和可信人工智能早期检测痴呆症。npj数字医学 7,294 (2024). https://doi.org/10.1038/s41746-024-01292-5
收到:
接受:
发布:
DOI: https://doi.org/10.1038/s41746-024-01292-5