
全部新闻
我建立了一个代理来完成我的工作。然后就挂断了我老板的电话。
我让人工智能代理完成了我的工作一周,它制作了采访和关于人工智能在新闻业中的作用的思考文章。虽然人工智能擅长提取引言和总结观点,但它缺乏人类的直觉和深度。实验表明,当前的人工智能工具适用于基本任务,但不足以取代需要与消息来源建立关系并解释复杂叙述的记者。
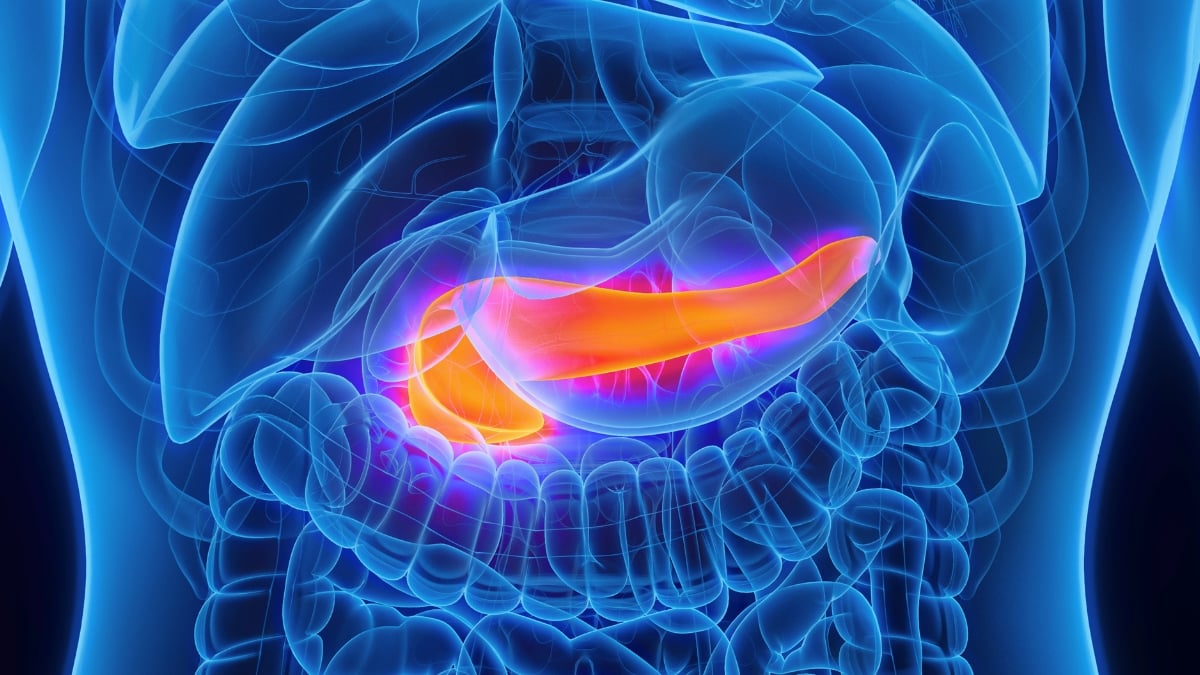
研究发现人工智能可以在诊断前数年发现胰腺癌
梅奥诊所和德克萨斯大学 MD 安德森癌症中心的研究人员开发了一种名为 REDMOD 的新人工智能模型,有望在诊断前 16 个月内检测出胰腺癌,与人类专家相比,检测率几乎翻倍。通过 CT 扫描测试,REDMOD 在近四分之三的病例中发现了癌症的早期迹象,有可能提前两年多发现肿瘤。该系统可以帮助将模式从晚期症状诊断转变为主动的临床前拦截,为胰腺癌的早期干预和治疗带来希望。
新的白宫药物滥用战略提出了废水检测、人工智能、更多治疗和基于信仰的选择
特朗普政府正在提出一项新的国家药物管制战略,其中包括废水检测、用于货物筛查的人工智能技术以及检测新威胁的算法。该计划还旨在利用电子健康记录来识别高危患者,并将基于信仰的方法纳入成瘾治疗中。尽管 2023 年高峰后用药过量死亡人数有所下降,但该报告强调了非法药物使用的增加和芬太尼类药物等新威胁。它呼吁增加成瘾治疗的可及性以及对各种物质治疗的研究。该战略强调执法部门在打击外国供应商和使过量逆转药物的获取正常化方面的作用。

Shivon Zilis 作为埃隆·马斯克 (Elon Musk) 的 OpenAI 内部人士如何运作
据透露,Shivon Zilis 是早年管理埃隆·马斯克和 OpenAI 之间沟通和监督关系的关键人物。作为 OpenAI 的顾问和后来的董事会董事,Zilis 甚至在 2018 年离开董事会后,还担任促进马斯克和该组织之间秘密互动的联络人。他们之间交换的短信表明,Zilis 建议马斯克保持与 OpenAI 的联系,以保持信息流通,并建议将一些 OpenAI 人员转移到特斯拉。此外,她还讨论了阻碍由马斯克不信任的 Demis Hassabis 领导的 Google DeepMind 人工智能开发工作的策略。这些通信凸显了马斯克与 OpenAI 之间关系中复杂的动态和战略机动。

YouTube 向整个好莱坞开放 AI Deepfake 检测工具(独家)
YouTube 开发了一种 Deepfake 检测工具,以保护演员、运动员和创作者等高风险个人免遭其平台上的滥用。这项专有技术最初由著名创作者进行测试,后来扩展到政治家和公众人物,现在可供任何因深度造假而面临生计受损风险的人使用。高管们强调在数字空间中保护个人身份的重要性,并将此工具视为责任的基础层。虽然人们正在讨论未来深度伪造内容的潜在盈利能力,但 YouTube 目前的重点仍然是提供保护,防止未经授权的使用。

Uber首席执行官表示其他高管在人工智能问题上撒了谎:“他们说会没事的”但私下承认数百万个工作岗位消失了
Uber 首席执行官达拉·科斯罗萨西 (Dara Khosrowshahi) 与典型的科技首席执行官不同,他公开承认人工智能对就业的颠覆性潜力。他估计,人工智能将在 10 年内取代人类 80% 的智力工作,并在 15-20 年内取代驾驶等体力工作。Uber 拥有 950 万名司机,科斯罗萨西认识到即将向自动驾驶汽车转变,但没有为失业工人提供解决方案。最近因人工智能进步而进行的值得注意的裁员包括 Block(4,000 个职位)和 Atlassian(1,600 个职位)。

苹果选择接替蒂姆·库克暗示其人工智能时代的计划美国有线电视新闻网商业频道
苹果首席执行官蒂姆·库克(Tim Cook)即将卸任,约翰·特努斯(John Ternus)将接任新任领导人。这一转变标志着苹果致力于引领人工智能 (AI) 快速发展的决心。尽管苹果在 iPhone 上取得了成功,并扩展到可穿戴设备和数字服务领域,但它尚未制定全面的人工智能战略以实现未来的增长。Ternus 在硬件工程方面的广泛背景被认为对于将人工智能功能集成到苹果专有设备中至关重要,特别是在该公司探索智能眼镜等新的人工智能驱动产品时。分析师预测,硬件创新仍将是苹果在 Ternus 领导下取得成功的核心,Ternus 需要在技术执行与人工智能战略愿景之间取得平衡。

大众汽车宣布今年晚些时候将在其中国汽车中配备语音人工智能
大众汽车宣布计划从 2023 年下半年起将人工智能语音指令集成到面向中国市场的汽车中。该公司在北京展示了包括 ID.5 在内的四款汽车。UNYX 09 与小鹏汽车共同开发,作为夺回中国快速发展的电动汽车行业失去的市场份额战略的一部分。大众汽车的人工智能系统将利用腾讯和百度等中国科技巨头的技术,使用完全在汽车本身上运行的本地训练的大型语言模型。该公司还与地平线机器人公司合作开发先进的汽车芯片,并在即将推出的电动 SUV 中使用小鹏汽车的图灵芯片。大众汽车旨在通过其位于合肥的研究中心加快技术开发和审批流程,从而缩短上市时间。中国德国商会的一份报告显示,德国汽车制造商加大了在华研发活动,从而降低了成本并加快了创新速度。

“护士的优步”:报告发现零工应用程序游说放松医疗保健管制
科技平台正在推动“优步护理”行业放松管制,以扩大医疗保健领域的零工工作。AI Now Institute 的一份报告强调了人工智能如何被用于医院和其他医疗机构的工作人员,而这往往以牺牲工人的权利、保护和工资为代价。零工护理公司使用人工智能来设定薪资、监控绩效指标并根据数据确定未来的工作机会。这种模式对这些平台来说是有利可图的,它们获得了大量投资和政府合同,但因轮班竞价战以及取消或迟到的惩罚积分制度等做法而面临批评。自 2022 年以来,零工护理平台已在至少 17 个州进行游说,要求其免受医疗人员配置法规和工人保护法的约束,导致多个州的立法取得进展,削弱了这些保护。该报告警告说,如果这种趋势持续下去,将对工作质量和公共安全产生潜在影响。
为什么受人尊敬的电影制作人突然拥抱人工智能?
史蒂文·索德伯格的新片《克里斯托弗一家》通过一位隐居的艺术家与该艺术家贪婪的孩子雇用的伪造者纠缠在一起,探索了艺术性和作者身份的主题。这部电影提出了有关创造力和技术的问题,尤其是索德伯格表示有兴趣在未来的项目中使用人工智能,尽管他过去曾退出电影制作。这一立场引发了批评者和粉丝之间的争论,特别是考虑到行业内对人工智能的看法相互矛盾,詹姆斯·卡梅隆等人物持谨慎态度,而桑德拉·布洛克等人则主张使用人工智能。这篇文章质疑反人工智能倡导者可以容忍他们的创意英雄有多少支持,并警告如果不明智地使用,电影质量可能会下降。我
