
全部新闻
数学家设计了新的问题来挑战高级人工智能的推理能力——但他们几乎没有通过所有测试
数学家设计了当前先进人工智能模型难以解决的复杂数学问题,大多数模型在这些挑战上的准确率低于 2%。这个名为 FrontierMath 的新基准是由 Epoch AI 与数学教授(包括菲尔兹奖获得者)合作开发的,旨在测试超出典型高中和大学水平基准(如 MMLU)的更高水平的推理技能。当对六种最先进的人工智能模型进行测试时,没有一个模型表现出研究级的数学推理能力。尽管取得了一些小成功,但总体准确率较低,凸显了当前人工智能的数学熟练程度与人类专家表现之间的巨大差距。

价值 40 亿美元的比特币挖矿到人工智能数据中心转换项目计划在丹顿进行
Core Scientific 计划将其位于丹顿的比特币挖矿业务转变为用于人工智能高性能计算的数据中心,投资约 40 亿美元,等待市政府批准。该公司计划扩建近 43 英亩,并向市政府额外支付 500 万美元。Core Scientific 寻求在 2025 年底前完成站点改造,并预计在 2027 年至 2029 年之间完成物理改进。此举是在其破产重组以及与云计算公司 CoreWeave 达成增强人工智能功能的协议之后进行的。

印度通讯社起诉 OpenAI 在人工智能培训中使用未经批准的内容
印度通讯社 ANI 已在新德里法院对 OpenAI 提起诉讼,指控该公司未经许可使用 ANI 的内容来训练其人工智能聊天机器人 ChatGPT。此前,《纽约时报》和《芝加哥论坛报》等其他媒体组织在全球范围内也提起了类似的诉讼。在周二的第一次听证会上,法官命令 OpenAI 对 ANI 的指控做出回应。ANI 还声称 OpenAI 将虚假新闻报道归咎于该机构。OpenAI 坚称其根据合理使用原则使用公共数据,并正在与全球多家新闻机构(包括印度的潜在合作伙伴)进行许可讨论。此案将于1月28日再次审理。

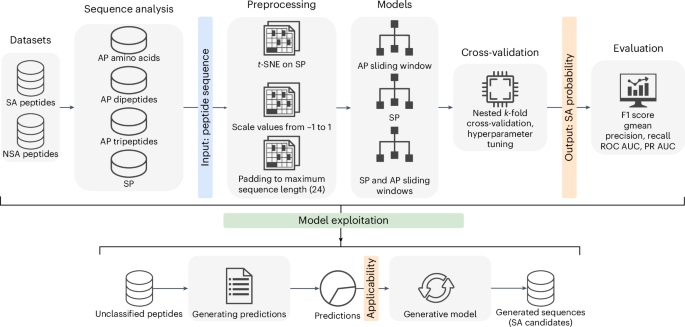
通过混合深度学习引导的生成式人工智能重塑自组装肽的发现
提供的文本似乎是研究论文或技术报告的片段,讨论用于预测肽自组装和特性的机器学习方法。根据内容总结如下:### 要点:1. **肽自组装预测**:- 该研究的重点是开发机器学习模型来预测肽如何自组装成各种结构。- 采用各种技术,包括顺序编码(例如氨基酸序列)和图形表示(例如残基相互作用)。2. **使用的机器学习模型**:- 应用长短期记忆 (LSTM)、双向 RNN 和 Transformer 等不同的神经网络架构来捕获肽序列中的复杂模式。- 使用dropout、批量归一化等技术进行正则化和提高模型性能。3. **基于软计算的生成模型**:- 使用软计算技术(可能涉及模糊逻辑或进化算法)创建可配置的生成模型,以搜索具有特定属性的催化肽。4. **引用文献**:- 参考文献包括有关神经网络、Transformer 架构等深度学习框架以及 Needleman-Wunsch 等序列比对方法的开创性著作。- 还引用了针对基于肽的纳米材料及其自组装机制的研究。### 主要贡献:- 该研究旨在开发强大的预测模型,以了解肽如何通过自组装形成复杂的结构。- 它集成了多种计算方法(序列分析、机器学习、软计算),以提高材料科学和生物技术中的预测准确性和适用性。### 未来的工作和影响:- 该研究提出了设计新型肽基纳米材料的潜在应用,该材料具有适合各种生物医学和工业用途的定制特性。- 对这些模型的进一步探索可以帮助药物输送系统、生物材料制造和在分子水平上理解疾病机制。### 结论:这项研究强调了预测肽自组装模式的计算方法的进步。此类预测可以指导开发具有特定性能和应用的功能性肽基材料的实验设计。---该摘要抓住了利用先进机器学习技术来理解和预测肽组装行为的本质,这对于推进纳米材料设计和生物技术至关重要。参考
美国专利商标局禁止员工使用生成式人工智能
出于安全考虑和潜在偏见,美国专利商标局(USPTO)去年禁止将生成式人工智能用于工作目的。员工可以在受控的内部测试环境中使用人工智能模型来了解他们的能力,但禁止在此设置之外使用 ChatGPT 或 Claude 等工具。该禁令涵盖人工智能生成的输出,但该机构公共数据库中批准的项目仍然可以访问。美国专利商标局正在努力通过增强的人工智能功能更新其专利数据库,并承认采用新技术面临官僚主义挑战。这一立场反映了政府机构关于生成式人工智能使用的更广泛趋势。

谷歌学术能否在人工智能革命中幸存下来?
Google Scholar 庆祝其作为领先的学术搜索引擎成立 20 周年,面临来自 ChatGPT 和 OpenAlex 等人工智能驱动工具的新竞争。尽管面临挑战,但由于免费访问、全面的覆盖范围和复杂的搜索选项,谷歌学术仍然占据主导地位。然而,新兴平台现在也提供类似的功能,可能威胁到谷歌学术搜索的主导地位。该工具使用人工智能对文章进行排名并建议查询,但尚未像竞争对手那样提供人工智能生成的查询结果摘要。

马克·扎克伯格如何全力以赴让 Meta 成为主要的人工智能玩家并威胁 OpenAI 的主导地位
这篇文章详细介绍了马克·扎克伯格如何通过重大投资和旨在通过 Llama 等开源模型将人工智能技术商品化的战略举措,将 Meta Platforms(前身为 Facebook)转变为人工智能领域的主要参与者。这一转变被视为是对公众对过去人工智能使用不信任的回应,也是避免少数大型科技公司垄断控制的雄心勃勃的尝试。以下是这篇文章的要点:1. **Meta的转型**:扎克伯格一直在重组Meta的内部运营,将FAIR(Facebook人工智能研究)等研究小组与负责在其各种应用程序中部署生成式AI产品的团队合并,从而更容易将理论工作转化为快速了解现实世界的产品功能。2. **人工智能焦点和公众信任问题**:虽然 Meta 正在推进 Llama 战略,但他的政府可能会认为像 Llama 这样的全球开源技术可以从自由获取相同的人工智能进步中受益。这可能意味着对 Meta 的人工智能实践的更多审查将针对科技巨头和初创公司,部分原因是地缘政治联盟。3. **对开源策略的批评和辩护**:有人认为这种策略不是“真正的”开源,引发了对技术潜在恶意使用的担忧。与此同时,Meta 首席执行官尼克·克莱格 (Nick Clegg) 反驳了批评者,认为他们反应过度。一些人担心这可能会导致类似于冷战时期科技巨头 Asana 的人工智能军备竞赛,并认为扎克伯格的举动可能会引发一场新的冷科技战争。

估值达到顶峰之际,人工智能却碰壁了美国有线电视新闻网商业频道
OpenAI 发布 ChatGPT 两年后,人们对人工智能进步的潜在局限性的担忧日益增加。尽管对人工智能公司进行了大量投资,但最近的报告表明,像 OpenAI 的 Orion 这样的领先语言模型可能不会显着优于其前辈。这可能表明进展中可能出现平台期,而不是持续指数级改进。这场辩论凸显了行业领导者的乐观态度和批评者的怀疑态度,他们警告说,如果承诺的突破没有实现,就会出现过度投资和潜在的经济衰退。

亿万富翁 Philippe Laffont 出售了 Coatue 所持 Nvidia 80% 的股份,转而买入这只历史上最便宜的人工智能 (AI) 股票杂七杂八的傻瓜
由于对竞争和内幕销售趋势的担忧,Coatue Management 的 Philippe Laffont 已大幅减少其基金在 Nvidia 的持股,出售了 80% 的股份。与此同时,拉丰大幅增持阿里巴巴股份2,441,557股,此举受到该公司在中国云基础设施市场的强势地位及其大量现金储备的影响。

美国警察局长最大规模的聚会如何谈论人工智能
《华盛顿邮报》的这篇文章讨论了美国警察部门如何在没有统一监管框架或监督的情况下迅速采用人工智能 (AI) 技术。以下是要点:1. **混乱的采用**:没有一个集中的机构来管理人工智能在警务中的使用,导致美国近 18,000 个自治警察部门采取分散且不协调的做法。2. **自主决策**:每个部门独立决定购买和部署哪些人工智能工具,导致道德、隐私和准确性的标准不同。3. **缺乏监管**:缺乏联邦法规意味着人工智能的道德和负责任使用指南目前由警察部门和科技公司自己制定,而不是通过标准化的法律框架。4. **营利性公司**:警察技术公司根据执法机构想要购买的产品开发工具,通常将利润置于隐私和准确性等公共利益考虑之上。5. **滥用的可能性**:由于没有总体指导方针或限制,人工智能的使用方式可能会损害公民自由或破坏刑事司法系统内的问责制。6. **政策影响**:文章指出了政治变化的潜在影响;例如,特朗普政府可能会鼓励采取更积极的治安策略,而拜登政府正在努力在 2025 年 1 月离任前将其提出的一些改革编入法典。美国警察部门混乱地采用人工智能,引发了人们对问责制以及在没有适当监督和监管的情况下可能滥用先进技术的严重担忧。
