
当人类和人工智能的组合有用时:系统回顾和荟萃分析
作者:Malone, Thomas
主要的
人们越来越多地在医学、金融和法律等领域以及旅行、购物和交流等日常活动中使用人工智能 (AI) 工具。鉴于人类和人工智能的互补性,这些人类人工智能系统具有巨大的潜力——人类的一般智能使我们能够推理各种问题,而人工智能系统的计算能力使它们能够完成人们认为困难的特定任务。
大量工作表明,将人类创造力、直觉和情境理解与人工智能的速度、可扩展性和分析能力相结合,可以带来创新的解决方案并改进医疗保健等领域的决策1, 客户服务2和科学研究3。然而,越来越多的研究表明,人类人工智能系统并不一定比人类或人工智能本身取得的最佳结果更好。沟通障碍、信任问题、道德问题以及人类和人工智能系统之间有效协调的需要等挑战可能会阻碍协作过程4,5,6,7,8,9。
这些看似矛盾的结果提出了重要的问题:人类和人工智能何时互补,互补程度如何?为了解决这些问题,我们进行了系统的文献综述和荟萃分析,其中我们量化了人类人工智能系统的协同作用,并确定了解释其在不同环境中存在(或不存在)的因素。
我们关注两个结果:(1)人类与人工智能的协同作用,人类与人工智能群体的表现比单独的人类和单独的人工智能都更好,这类似于人类群体中的强协同作用10,11;(2) 人类增强,人类-人工智能组的表现比人类单独表现更好(参见补充信息部分)1.1了解更多详情)。
在评估人类人工智能系统时,许多研究都集中在人类增强上12,13,14,15。在由于法律、道德或安全原因而无法实现完全自动化的情况下,以及在人工智能与人类价值观不符的情况下,这一措施可以发挥重要作用。但在谈论人类人工智能系统的潜力时,大多数人隐含地认为组合系统应该比单独的系统更好;否则,他们只会使用两者中最好的16。因此,他们正在寻找人类与人工智能的协同作用。鉴于这些考虑,越来越多的工作强调评估和寻找人类人工智能系统的协同作用4,8,17 号,18,19,20。
为了评估人类与人工智能系统的协同作用,我们分析了 2020 年 1 月至 2023 年 6 月期间发表的 106 个不同实验中的 370 个独特效应大小,其中包括纯人类系统、纯人工智能系统和人类 AI 系统的性能。平均而言,我们发现了人类增强的证据,这意味着人类人工智能系统的平均表现比人类单独的表现更好。但我们并没有发现人类与人工智能的平均协同作用,这意味着人类与人工智能系统的平均表现至少比单独人类或单独人工智能系统中的一个差。因此,在实践中,如果我们只考虑研究人员研究的性能维度,那么单独使用人类或单独使用人工智能系统会比研究人类人工智能系统更好。
虽然这一总体结果可能令人沮丧,但我们还确定了有助于或不有助于人类人工智能系统协同作用的特定因素。例如,一方面,最近关于人类与人工智能协作的大部分研究都集中在使用人工智能系统来帮助人类做出决策,不仅提供建议的决策,还提供置信度或解释。但我们发现这些因素都没有显着影响人类人工智能系统的性能。
另一方面,很少有工作研究任务类型的影响以及人类单独和人工智能单独的相对表现。但我们发现这两个因素都显着影响人类人工智能的表现。因此,我们的工作为设计未来人类人工智能系统提供了有希望的方向,以释放更大协同作用的潜力。
结果
我们最初的文献检索产生了 5,126 篇论文,并且根据方法(参见“文献综述”),我们确定了 74 个符合我们的纳入标准(补充图 1)。1)。这些论文报告了 106 个独特实验的结果,其中许多实验都有多种条件,因此我们总共收集了 370 个独特的效应量,衡量人类与人工智能协作对任务绩效的影响。补充图。2突出显示我们分析中效应大小的描述性统计数据。我们在三级元分析模型中综合了这些数据(请参阅《数据分析》中的“数据分析”)方法)。我们已经通过开放科学框架存储库公开了重现结果所需的材料。
人类与人工智能协同的总体水平
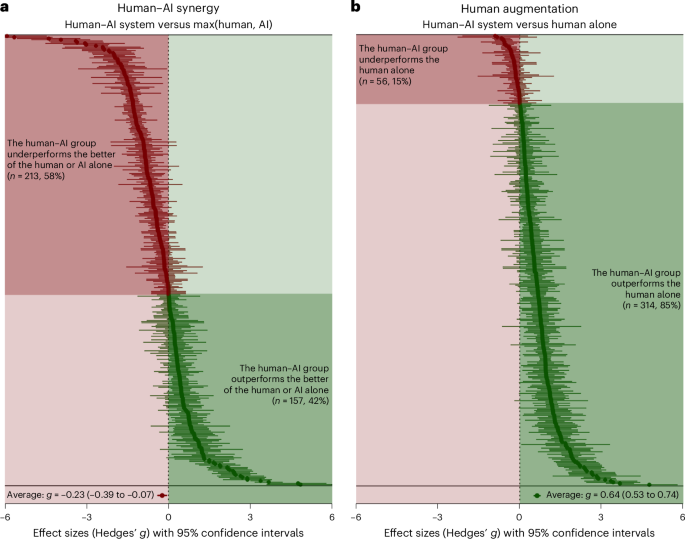
在我们的主要分析中,我们专注于人类与人工智能的协同作用,因此我们将人类与人工智能系统的性能与单独人类或单独人工智能的基线进行比较,以表现最好者为准。我们发现人类人工智能系统的整体表现明显低于该基线。总体汇总效应为负(克≤=≤0.23;t92≤=≤2.89;双尾磷≤=≤0.005;95% 置信区间 (CI),≤0.39 至 ≤0.07),根据传统解释认为较小21。
然而,当我们将人类人工智能系统的性能与不同的基线(仅人类)进行比较时,我们发现了人类增强的大量证据。人类人工智能系统的表现明显优于人类单独系统,并且这种汇总效应大小是正的(克≤=≤0.64;t98≤=≤11.87;双尾磷≤=≤0.000;95% CI,0.53 至 0.74),中到大21。数字1显示这些效应大小的森林图。换句话说,我们分析的人类-人工智能系统平均而言比单独的人类系统要好,但并不比单独的人类系统和单独的人工智能系统都好。对于与其他潜在感兴趣结果相对应的效应大小,请参阅补充表3和补充图。3。

,乙, 上点的位置x轴表示效应大小的值,条形表示效应大小的 95% CI。点和条的颜色对应于效应大小的值,负效应大小为红色,正效应大小为绿色。黑色虚线对应的效应大小为克–= –0,这意味着人类 AI 系统的表现与基线相同。图表底部的点代表荟萃分析平均效应大小和 CI。
人类与人工智能协同作用的异质性
我们还发现了在我们对人类与人工智能协同作用的估计中效应大小存在显着异质性的证据(我2–= –97.7%) 和人类增强 (我2≤=≤93.8%)(见补充表5和6了解更多详情)。我们的调节分析确定了参与者、任务和实验的特征,这些特征导致了不同程度的人类与人工智能协同作用和人类增强,这有助于解释这种异质性的来源。数字2与我们的主持人一起提供元回归结果的可视化。不同调节变量的子组定义包含在补充表中2,其他潜在感兴趣结果的回归的更多详细信息包含在补充表中7。

这里n是调节子组水平包含的效应大小的数量,并且显示每个水平的估计效应大小以及相应的 95% CI。主持人前面的符号表示人类与人工智能协同 (*) 和人类增强 (☈§)。
首先,我们发现任务类型显着调节了人类与人工智能的协同作用(F1,104≤=≤7.84,双尾磷≤=≤0.006)。在决策任务中(参与者在一组有限的选项之间做出决定),人类与人工智能协同作用的汇总效应大小显着为负(克≤=≤0.27;t104≤=≤3.20;双尾磷≤=≤0.002;95% CI,≤0.44 至 ≤0.10),这表明人类和人工智能结合带来的性能损失。相比之下,在创作任务中(参与者创建某种开放式响应内容的任务),人类与人工智能协同作用的汇总效应大小是正的(克≤=≤0.19;t104≤=≤1.35;双尾磷≤=≤0.180;95% CI,≤0.09 至 0.48),表明人类与人工智能之间存在协同作用。尽管创建任务的平均性能增益与 0 没有显着差异(可能是因为创建任务的样本量相对较小)n-= -34),决策任务的损失和创建任务的收益之间的差异具有统计显着性。与此相关的是,我们发现任务中涉及的数据类型显着调节了人类与人工智能的协同作用(F4,101≤=≤15.24,双尾磷–= –0.000) 和人类增强 (F4,101≤=≤6.52,双尾磷–= –0.000)。
其次,我们发现人类和人工智能的相对表现会影响人类与人工智能的协同作用(F1,104�=�81.79,双尾磷–= –0.000) 和人类增强 (F1,104≤=≤24.35,双尾磷–= –0.000)。如图所示。2,当人类单独表现优于单独人工智能时,人类与人工智能组合系统的表现优于单独人类与人工智能系统,人类与人工智能协同作用的平均汇总效应大小为克≤=≤0.46 (t104≤=≤5.06;双尾磷≤=≤0.000;95% CI,0.28 至 0.66),中等程度的影响21。但是,当人工智能单独表现优于人类单独表现时,相对于单独人工智能,组合系统中会出现性能损失,对人类与人工智能协同作用的负面影响大小为克≤=≤0.54 (t104≤=≤6.20;双尾磷≤=≤0.000;95% CI,≤0.71 至 ≤0.37),中等程度的影响21。考虑到这个调节器的重要性,我们在结果子集上拟合了单独的元分析模型,其中(1)人工智能单独表现更好,(2)人类单独表现更好,并且我们报告了人类与人工智能协同作用的结果,以及补充表中的人体增强4。
人类和人工智能之间的相对表现也影响了人类人工智能系统中人类增强的程度(F1,104≤=≤24.35,双尾磷–= –0.000)。当人工智能超越人类单独表现时,相对于单独人类,人类人工智能系统往往会出现更大的性能提升,并且人类增强的汇总效应大小为正,且幅度为中等到大(克≤=≤0.74;t104≤=≤13.50;双尾磷≤=≤0.000;95% CI,0.63 至 0.85)(参见补充图 2)4—7以更详细地可视化决策任务的结果)。
我们还发现参与实验的人工智能类型(F2,103≤=≤3.77,双尾磷�=�0.026) 和出版年份 (F3,102 人≤=≤3.65,双尾磷–= –0.015) 调节了人类与人工智能的协同作用,实验设计调节了人类增强(F1,104≤=≤4.90,双尾磷≤=≤0.029)。参见补充图。8按出版年份更详细地可视化效果大小。
我们调查的其余调节者对于人类与人工智能的协同作用或人类增强(解释、置信度、参与者类型和分工)没有统计显着性。
讨论
结合人类智能和人工智能工具的系统可以解决多个具有社会重要性的问题,从我们如何诊断疾病到我们如何设计复杂系统22,23,24。但一些研究表明,用人工智能增强人类能力比人类或人工智能单独工作可以带来更好的结果24,25,26,而其他人则表现出相反的情况4,7,9。这些看似不同的结果提出了两个重要问题:人类与人工智能的协作总体上有多有效?在什么情况下这种合作会带来性能提升而不是性能损失?我们的研究分析了三年多的最新研究,以提供对这两个问题的见解。
人类与人工智能协作造成的性能损失
关于第一个问题,我们发现,在最近的实验中,平均而言,人类与人工智能系统并没有表现出协同作用:人类与人工智能组的表现比单独的人类或单独的人工智能更差。这一结果补充了人类与人工智能协作的定性文献综述27,28,29,其中强调了在整合人类智能和人工智能时出现的一些令人惊讶的挑战。例如,人们常常过于依赖人工智能系统(过度依赖),将其建议作为强有力的指导方针,而不寻求和处理更多信息6,30,31。然而,其他时候,人类对人工智能的依赖太少(依赖不足),由于对自动化的不利态度而忽略了它的建议7,31,32。
有趣的是,我们发现,在同一组实验中,人类增强确实存在于人类人工智能系统中:人类人工智能组的表现比人类单独工作的表现更好。因此,尽管人类与人工智能的组合平均而言没有实现协同作用,但人工智能系统平均而言确实帮助人类表现得更好。当然,这种结果是可能发生的,因为根据定义,人类与人工智能协同作用的基线比人类增强的基线更为严格。然而,这种情况也可能发生,因为获得人类与人工智能的协同作用需要不同形式的人类与人工智能的互动,或者因为最近的实证研究没有适当地设计来引发人类与人工智能的协同作用。
任务类型的调节作用
利用我们收集的大型数据集,我们还对影响人类与人工智能协作有效性的因素进行了分析。我们发现任务类型显着调节了人类人工智能系统的协同作用:决策任务与性能损失相关,而创建任务与性能提升相关。
我们假设创造任务会出现这种优势,因为即使创造任务需要使用人类表现更好的创造力、知识或洞察力,它们通常也涉及大量常规的附加内容生成,而人工智能可以执行这些内容,或者比人类更好。例如,生成一个好的艺术图像通常需要一些关于图像应该是什么样子的创造性灵感,但它通常也需要对图像的细节进行大量的常规充实。同样,生成多种文本文档通常需要人类拥有而计算机不具备的知识或洞察力,但也通常需要填写文本的样板或常规部分。
然而,在我们样本中研究的大多数决策任务中,人类和人工智能系统都会做出完整的决策,而人类通常会做出最终选择。我们的结果表明,对于这些决策任务,如果实验者设计的流程中人工智能系统仅执行其明显优于人类的部分任务,则可能会获得更好的结果。我们分析的 100 多个实验中,只有 3 个通过预先将单独的子任务委托给人类和人工智能来探索此类过程。根据这 3 个实验的四种效应大小,我们发现,平均而言,人类与人工智能的协同作用(克≤=≤0.22,t104≤=≤0.69;双尾磷≤=≤0.494;95% CI,≤0.42 至 0.87)发生,但结果没有统计学意义(参见补充信息部分)2.6有关这些实验的更详细讨论)。
人类/人工智能相对表现的调节作用
有趣的是,当人工智能单独表现优于人类单独表现时,人类人工智能系统会出现严重的性能损失。然而,当人类单独超越人工智能时,人类人工智能系统的性能就会提高。这一发现表明,人类与人工智能的表现不能用人类和人工智能的简单平均值来解释。在这种情况下,人类与人工智能的协同作用永远不可能存在33。
我们数据集中的大多数(>95%)人类人工智能系统都是由人类在接收人工智能算法的输入后做出最终决定。在这些情况下,对我们结果的一个可能的解释是,当人类总体上比算法更好时,他们也更擅长决定在哪些情况下应该相信自己的意见,在哪些情况下应该更多地依赖算法的意见。
例如,卡布雷拉等人。34使用了一种实验设计,其中人类人工智能条件下的参与者看到了一个问题实例,对该实例的人工智能预测,以及在某些情况下,对此类实例中人工智能准确性的附加描述。相同的实验设计,具有相同的任务界面、参与者池和人工智能系统的准确性,用于三个独立的任务:虚假酒店评论检测、卫星图像分类和鸟类图像分类。对于虚假酒店评论检测,研究人员发现,单独人工智能的准确率达到 73%,单独人类的准确率达到 55%,人类人工智能系统的准确率达到 69%。在这种情况下,我们假设,由于人们总体上不如人工智能算法准确,他们也不擅长决定何时信任算法以及何时信任自己的判断,因此他们的参与导致总体得分较低性能优于单独的人工智能算法。
相比之下,卡布雷拉等人。34研究发现,对于鸟类图像分类,单独人工智能的准确率达到 73%,单独人类的准确率达到 81%,人类人工智能系统的准确率达到 90%。在这里,单独的人类比单独的人工智能算法更准确,因此我们假设人类善于决定何时相信自己的判断和算法的判断,因此整体性能比单独的人类或单独的人工智能有所提高。
令人惊讶的是微不足道的版主
我们还调查了其他调节因素,例如是否存在解释、人工智能输出的置信度以及评估的参与者类型。这些因素近年来备受关注4,24,26,35。鉴于我们的结果是,平均而言,在 300 多个效应大小中,它们不会影响人类与人工智能协作的有效性,我们认为研究人员可能希望不再强调这一探究方向,而是将焦点转移到重要且研究较少的领域我们确定的调节因素:人类和人工智能单独的基线表现、他们执行的任务类型以及他们之间的分工。
局限性
我们想强调我们的荟萃分析方法的一些一般局限性,以帮助解释我们的结果。首先,我们的定量结果适用于我们通过系统文献综述收集的研究子集。为了评估人类与人工智能的协同作用,我们要求论文报告(1)人类单独的表现,(2)单独人工智能的表现以及(3)人类与人工智能系统的表现。然而,我们可以想象人类和/或人工智能无法单独执行但可以与其他人合作执行的任务。我们的分析不包括此类研究。
其次,我们计算了与任务准确性、错误和质量等不同定量指标相对应的效应大小。通过计算对冲 –克,一个无单位的标准化效应量,我们可以描述这些实验之间的重要关系,使它们在具有不同结果变量的不同研究设计中具有可比性36。不过,我们数据集中的研究来自不同的人群样本——有些是针对医生的37,38,39,其他众包工作者4,6,34还有一些学生13,40,41– 这种变化会在一定程度上限制效应大小的可比性36。不同实验的测量误差也可能有所不同。例如,一些研究根据对多达 500 张不同图像的评估来估计总体准确性25,而其他人则根据对 15 个不同的评估的评估来估计它42。正如典型的荟萃分析一样43,在我们的三水平模型中,我们将效应大小加权为参与者之间方差的函数,因此我们没有考虑测量中的其他变异来源。
第三,虽然我们没有发现发表偏见的证据,但它们仍然有可能存在,这将影响我们的文献基础,进而影响我们的荟萃分析结果。然而,我们预计,如果这里存在发表偏见,那么发表显示人类和人工智能结合带来显着收益的研究将是一种偏见。由于我们的总体结果显示相反,因此它们似乎不太可能是出版偏见的结果。
第四,我们的结果仅适用于研究人员选择研究的任务、流程和参与者池,这些配置可能不能代表实验室外人工智能实际应用中人类人工智能系统的配置方式。换句话说,即使我们分析的研究不存在发表偏倚,也可能存在研究主题选择偏倚。
第五,我们分析的质量取决于我们综合研究的质量。我们试图通过仅纳入同行评审出版物中发表的研究来控制这个问题,但研究的严谨程度可能仍然有所不同。例如,研究使用了不同的注意力检查机制和绩效激励结构,这两者都会影响响应的质量,从而在我们的数据中引入另一个噪声源。
最后,我们在分析中发现效应大小之间存在高度异质性。我们调查的调节者在一定程度上解释了这种异质性,但仍有许多问题无法解释。我们假设我们编码的变量之间存在交互效应(例如,人工智能的解释和类型),但我们没有足够的研究来检测这种效应。当然还有一些我们没有分析的潜在调节者。例如,研究人员大多使用自己的实验平台和刺激,这自然会引入他们的研究之间的变异来源。随着人类与人工智能协作文献的发展,我们希望未来的工作能够识别更多影响人类与人工智能协同的因素,并评估它们之间的相互作用。
未来工作路线图:寻找人类与人工智能的协同作用
尽管我们的主要结果表明,平均而言,人类和人工智能的结合会导致性能损失,但我们并不认为这意味着人类和人工智能的结合是一个坏主意。相反,我们认为这只是意味着未来的工作需要更加专注于寻找整合人类和人工智能的有效流程。我们的其他结果表明了有希望的进展方式。
开发用于创作任务的生成式人工智能
在我们近期实验的广泛样本中,绝大多数(约 85%)的效应大小是针对参与者在一组预定义选项中进行选择的决策任务。但在这些情况下,我们发现人类与人工智能协同作用的平均效应大小显着为负。相比之下,研究人员研究的效应大小中只有大约 10% 是针对创造任务——那些涉及开放式反应的任务。在这些案例中,我们发现人类与人工智能协同作用的平均效应大小是正的,并且明显大于决策任务的平均效应大小。这一结果表明,研究人类与人工智能在创造任务中的协同作用(其中许多任务可以通过生成式人工智能来完成)可能是一个特别富有成果的研究领域。
然而,最近与人类参与者有关生成人工智能的大部分工作都倾向于关注对该工具的态度44,45、与参与者访谈或自言自语46,47,48,或用户体验而不是任务绩效49,50,51。此外,根据定量绩效指标评估人类与人工智能协作的工作相对较少,往往只报告人类单独的绩效以及人类与人工智能组合(而不是单独的人工智能)的绩效52。这种限制使得评估人类与人工智能的协同作用变得困难,因为单独的人工智能可能能够以比参与实验的参与者(通常是众包工作者)更高的质量和速度执行任务。因此,我们需要研究进一步探索人类与人工智能在不同任务中的协作,同时报告人类单独、单独人工智能和人类与人工智能系统的表现。
开发创新流程
此外,正如参考文献中所讨论的。33人类与人工智能的协同作用要求人类在任务的某些部分做得更好,人工智能在任务的其他部分做得更好,而系统作为一个整体善于将子任务适当地分配给最适合该子任务的合作伙伴。有时,这是通过让更有能力的合作伙伴决定如何分配子任务来完成的,有时是通过先将不同的子任务分配给最有能力的合作伙伴来完成(参见补充信息部分)2.6有关我们数据集中实验的具体示例)。一般来说,为了在实践中有效地使用人工智能,设计如何将人类和人工智能结合起来的创新流程可能与设计创新技术同样重要53。
为人类人工智能系统开发更强大的评估指标
我们分析中的许多实验都是根据整体准确性的单一衡量标准来评估性能,但这种衡量标准根据具体情况对应不同的事物,并且忽略了人类人工智能系统的其他重要标准。例如,当接近性能上限(例如 100% 准确度)时,提高性能所需的改进对于人类和人工智能系统来说通常会变得更加困难。在这些情况下,我们可能希望考虑一种对整体分类精度应用非线性缩放的度量,从而考虑到这些因素54(补充信息部分1.2)。
更重要的是,在许多实际情况下,良好的性能取决于多个标准。例如,在放射诊断和保释预测等许多高风险环境中,相对罕见的错误可能会带来极高的财务或其他成本。在这些情况下,即使人工智能平均可以比人类更准确、更便宜地执行任务,但如果人类能够减少罕见但非常不受欢迎的错误的数量,那么将人类纳入该过程可能仍然是可取的。对于此类情况,一种可能的方法是创建综合性能指标,其中包含各种错误的预期成本。所描述的人体增强措施也适用于这些高风险环境。
一般来说,我们鼓励研究人员开发、采用和报告更稳健的指标,考虑任务完成时间、财务成本和不同类型错误的实际影响等因素。这些进展将帮助我们更好地理解任务绩效改进的重要性以及人类与人工智能协作的影响。
制定可通约性标准
随着研究人员继续研究人类与人工智能的协作,我们还敦促该领域制定一套可通约性标准,这可以促进研究之间更系统的比较,并帮助我们跟踪寻找人类与人工智能协同作用领域的进展。这些标准可以为关键研究设计要素提供标准化指南,例如:
-
(1)
任务设计:建立一组涉及人类人工智能系统的基准任务
-
(2)
质量约束:指定人类、人工智能和人类人工智能系统必须满足的可接受的质量阈值或要求
-
(3)
激励计划:概述用于激励人类参与者的激励结构(例如,支付计划和奖金)
-
(4)
流程类型:开发交互协议、用户界面设计和任务工作流程的分类,以实现有效的人机协作
-
(5)
评估指标:根据明确定义的性能指标报告人类、人工智能和人类-人工智能系统的性能
为了进一步促进可通约性和研究综合,我们鼓励该领域建立一个标准化和开放的报告存储库,专门用于人类与人工智能的协作实验。这个集中数据库将托管研究——原始数据、代码、系统输出、交互日志和详细文档,并遵守拟议的报告指南。因此,它将促进该领域研究的复制、扩展和综合。例如,通过在此类数据集上应用先进的机器学习技术,我们可以开发预测模型来指导针对特定约束和环境进行优化的人类人工智能系统的设计。此外,它将提供一种方法来跟踪寻找人类与人工智能协同作用的更大领域的进展。
总之,我们的结果表明,人类人工智能系统的表现通常比单独人类或单独人工智能系统更差。但我们的分析也为未来开发更有效的人类人工智能系统提出了有希望的方向。我们希望这项工作将有助于指导开发此类系统的进展,并利用它们来解决商业、科学和社会中一些最重要的问题。
方法
我们根据 Kitchenham 的指导方针进行了这项荟萃分析55系统评价,我们遵循系统评价和荟萃分析的首选报告项目规定的标准56。
文献综述
资格标准
根据我们的预注册(https://osf.io/wrq7c/?view_only=b9e1e86079c048b4bfb03bee6966e560),我们应用以下标准来选择适合我们研究问题的研究。首先,论文需要提出一个原始实验,评估人类和人工智能系统协同执行任务的某些实例。其次,它需要根据一些定量指标报告(1)人类单独、(2)人工智能单独和(3)人类-人工智能系统的表现。因此,我们排除了仅报告人类表现而非仅报告人工智能表现的研究,同样,我们排除了仅报告人工智能表现而非仅报告人类表现的研究。根据这一规定,我们还排除了纯粹的荟萃分析和文献综述、理论工作、定性分析、评论、观点和模拟。第三,我们要求论文包含实验设计、每种条件下的参与者数量以及每种条件下结果的标准差,或者足够的信息来从其他量中计算出来。最后,我们要求论文用英文写。
搜索策略
鉴于人类与人工智能交互研究的跨学科性质,我们在涵盖计算机科学、信息科学和社会科学以及其他领域的会议和期刊的多个数据库中进行了搜索。通过与这些领域的图书馆专家的磋商,我们决定针对计算机数字图书馆协会,信息系统纤维化协会和科学核心核心收集协会,以供我们评论。为了关注当前的AI形式,我们将搜索限制在2020年1月1日至2023年6月30日之间发表的研究。
为了开发搜索字符串,我们首先要提炼评估人AI系统性能的研究方面。我们需要以下内容:(1)人类组件,(2)计算机组件,(3)协作组件和(4)实验组件。鉴于我们的研究问题的多学科性质,在不同的地点发表的论文倾向于以各种名称为参考这些组成部分8,12,13,57,58。对于广泛的覆盖范围,我们为每个组件编制了同义词和缩写列表,然后将这些术语与布尔操作相结合,从而导致以下搜索字符串:
-
(1)
人:人,专家或参与者,人类或专家或参与者
-
(2)
AI:AI或人工智能或ML或机器学习或深度学习
-
(3)
协作:协作,协助或援助或互动或帮助
-
(4)
实验:“实验或实验”或“用户研究”或众包研究或众包研究或众包研究实验室研究或实验室研究
搜索词是摘要中的(1)和(2)和(3)和(4)。请参阅补充表1对于每个数据库的精确语法。为了进一步确保全面的覆盖范围,我们还对所有研究符合我们的纳入标准进行了前进和向后搜索。
数据收集和编码
我们在2023年7月在每个数据库中进行了搜索。为了计算我们感兴趣的主要结果。我们记录了单独的人类任务绩效的平均值和标准偏差的效果。
,单独的AI以及人类和AI相互工作,以及每个条件中的参与者数量(请参阅补充信息部分1.3了解详情)。
许多作者直接在论文正文中报告了所有这些值。然而,值得注意的数字是通过提供 95% CI 或标准误差而不是原始标准差来间接报告它们。为此,我们使用适当的公式计算了标准偏差59。此外,多篇论文没有提供此类公式所需的确切数字,但作者公开了他们研究的原始数据。在这些情况下,我们下载数据集并使用 Python (v.3.11.9) 或 R (v.2023.06.0+421) 计算平均值和标准差。如果相关数据仅在论文的图表中呈现,我们会联系相应作者索取数值。如果作者没有响应,我们使用了WebPlotDigitizer60将绘制值转换为数值。对于进行了符合我们的纳入标准但没有报告计算效果大小所需的所有值的实验的论文,我们还直接联系了相应的作者,以询问必要的信息。如果作者没有响应,我们将无法计算研究的效果大小,也没有将其包括在我们的分析中。
我们考虑并编码了人AI性能的多个潜在主持人:(1)出版日期,(2)预注册状态,(3)实验设计,(4)数据类型,(5)任务类型,(6)任务输出,(7)AI类型,(8)AI说明,(9)AI信心,(10)参与者类型和(11)性能指标。请参阅补充表2有关这些主持人变量的描述。我们记录的其他信息具有描述性和探索性目的。
许多论文进行了多个实验,包含多种治疗方法或根据多种措施进行了评估的绩效。在这种情况下,我们分配了一个唯一的实验识别编号,治疗识别编号和测量识别编号,从论文中的效果大小。请注意,我们根据不同参与者集的样本定义了实验。
数据分析
效果大小的计算
我们计算了树篱克衡量结合人类智能和人工智能对任务绩效的影响61。为了强大的协同作用,树篱克代表人AI系统的性能与基线的标准均值差异,这可以是人类单独的或单独的人AI,平均而言,以较高为准。对于人类的增强,树篱克代表人类AI系统的性能与单独的人类基线之间的标准化平均差异。我们选择了树篱
克作为效果大小的度量,因为它是无单位的,因此它使我们能够比较不同指标的人类AI的性能,并且可以纠正原始标准化平均差异的向上偏见(Cohensd)61。请参阅补充信息部分1.4有关此计算的更多详细信息。
元分析模型
我们分析的论文的实验差异很大。例如,他们评估了不同的任务,招募了来自不同背景的参与者,并采用了不同的实验设计。由于我们期望在真实效应大小中实现实验性的异质性,因此,对于我们的分析,我们使用了一个随机效应模型,该模型说明了效果大小的差异,这些效应大小都来自采样误差和整个实验的真实变异性62。
此外,我们认为产生了多个依赖性效应大小的某些实验:它们可能涉及多个治疗组,例如,它们可以根据多种测量方法进行评估。更常用的荟萃分析模型假定效应大小的独立性,这使它们不适合我们的分析63。因此,我们采用了一个三级荟萃分析模型,其中效应大小嵌套在实验中,因此我们明确考虑了模型中数据中的依赖项63,64。此外,我们使用了鲁棒的差异估计方法来计算效应大小估计值的方差以及相关的标准误差,顺式和统计测试的一致估计,这解释了在实验中比较多个实验中发生的样本中抽样错误的依赖性的依赖性单个对照组的治疗组65。在评估结果的重要性时,我们应用了KNAPP和HARTUNG调整,并计算了测试统计误差,标准误差,磷价值和CI基于t分布与kp自由度,其中k表示效应大小簇的数量(即实验数)和p表示模型中系数的数量。为了执行主持人分析,我们针对每个主持人变量进行了单独的元回归。
为了解释效应大小的异质性程度,我们计算了流行的我2统计参考。66,这量化了不是抽样误差的生效大小变化百分比。此外,为了区分这种异质性的来源,我们还计算了统计量的多级版本。64。
偏置测试
在我们的荟萃分析的背景下,如果研究人员发布实验表明人AI协同作用的证据比没有的证据更频繁,则可能发生出版偏见。此类行动将影响我们收集的数据并扭曲了我们的发现。为了评估这种风险,我们采用了Viechtbauer和Cheung概述的多个诊断程序67。首先,我们创建了漏斗图,以绘制观察到的效果大小x轴和相应的标准错误y轴68。在没有出版偏见的情况下,我们希望这些要点大致对称地围绕y轴。我们用颜色增强了这些图,表明每个效果大小的显着性水平,以帮助区分出版物偏见与其他不对称原因69。统计不显着的区域中缺乏效应大小,表明出版偏见的风险更大。我们在视觉上检查了图并进行了Egger的回归测试70以及等级相关测试71评估漏斗图中的结果。这些测试检查了观察到的效应大小与其相关采样方差之间的相关性。高相关性表明漏斗图中的不对称性,这可能源于出版偏见。
补充图。9显示随附效应大小的漏斗图,我们没有观察到该图中的显着不对称性或缺失数据的区域,即我们的主要结果,即人类AI协同作用。Egger的回归没有表明样本中出版偏见的证据( -= 0.67;t104= 0.78;双尾磷= 0.438;95%CI,2.39至1.04),秩相关测试也不 -= 0.05,两尾磷= 0.121)。总体而言,这些测试表明,我们对人AI协同作用的结果对潜在的出版偏见是强大的。
但是,重要的是,我们确实发现了出版偏见的潜在证据,这有利于报告的研究导致人类AI系统的表现优于人类(人类增强)。在这种情况下,Egger的回归确实表明了样本中的出版偏见( -= 1.96;t104= 3.24;双尾磷= 0.002;95%CI,0.76至3.16),等级相关测试也是如此( -= 0.19,两尾磷= 0.000)。请注意,我们没有试图纠正潜在的出版偏见,以保留原始数据的完整性并保持报告中的透明度。许多提出的调整方法也会导致过度纠正和扭曲结果72。
人类AI协同渠道图中的对称性之间的对称性之间的差异与人类增强漏斗图中的不对称性可能反映了有多少研究人员和期刊暗中对人类的增强具有兴趣,将人类AI系统与人类单独的人类单独进行比较。
敏感性分析
在我们的主要分析中,我们开发了一个三级荟萃分析模型,该模型解释了观察到的效应大小(第一级)的差异,同一实验(第二级)的效应大小之间的差异以及实验之间的差异(第三级)。然后,我们根据效应大小估计值计算了群集射击标准误差,顺式和统计测试,其中我们在实验水平上定义了簇。该模型说明了对共同对照组的多种治疗方法评估多种治疗方法并根据多种措施评估绩效所致的依赖性大小。但是,它确实将我们的分析中的实验视为彼此独立的,即使它们来自同一论文。我们认为这一假设是合理的,因为实验招募了不同的参与者集,并需要采取不同的任务或干预措施。
但是,作为鲁棒性检查,我们进行了灵敏度重新分析,其中我们在纸张水平而不是实验水平上聚类。该多级模型解释了观察到的效应大小(第一级)的差异,同一论文(第二级)效应大小之间的差异以及论文之间的差异(第三级)。我们仍然针对我们的效应大小估计值计算了群集射击标准误差,顺式和统计测试,在该效果大小估计中,我们在实验水平上定义了簇,因为参与者样本仅在实验水平上重叠。使用这种方法,我们发现人AI协同作用的总体效应大小可比(克= 0.22;t67= 2.46;双尾磷= 0.017;95%CI,0.41至0.04)和人类增强(克= 0.65;t69= 9.96;双尾磷= 0.000;95%CI,0.52至0.78)。
我们还评估了结果的鲁棒性,即偏远和有影响力的数据点。为了检测此类数据,我们计算了每个效果大小的残差和库克距离。我们认为,剩余值大于或少于三个标准偏差,与均值为异常值以及参考文献之后。73,我们认为值大于4/n作为很高的影响力,n是我们分析中数据点的数量。使用这种方法,我们确定了人AI协同作用的11个异常值和人类增强的9个异常值。我们对不包括这些效应大小的数据集进行了灵敏度重新分析,这对人AI协同作用了相似的效应大小(克= 0.25;t104= 3.45;双尾磷= 0.001;95%CI,0.39至0.11)和人类增强(克= 0.60;t104= 12.60;双尾磷= 0.000;95%CI,0.50至0.69)。
此外,我们进行了一对一的分析,其中通过在我们的原始数据集中忽略一个效应大小而获得的不同效果大小子集进行了一系列灵敏度重新分析。我们还在实验和出版级别进行了一项分析。这些测试表明,每个效果大小,实验和出版物如何影响我们对人AI协作对任务绩效影响的总体估计。人AI协同作用的摘要效应大小范围为0.28至0.19,两尾磷在所有情况下,<0.05(0.000至0.019),表明我们的结果对任何单个效应大小,实验或纸张的稳健性;同样,人类增强的摘要效应大小范围为0.61至0.66,两尾磷在所有情况下,<0.05(0.000至0.000),表明我们的结果对任何单个效应大小,实验或纸张的稳健性。
最后,我们对数据集进行了敏感性重新分析,该数据集省略了使用WebPlotDigitizer或作者在论文中提供的信息估计的效果大小,我们再次发现了人类AI Synergy几乎相同的结果(克= 0.21;t98= 2.59;双尾磷= 0.011;95%CI,0.36至0.05)和人类增强(克= 0.64;t98= 11.73;双尾磷= 0.000;95%CI,0.53至0.75)。
我们使用R统计编程语言进行了所有定量分析,我们主要依靠包装元。74。
报告摘要
有关研究设计的更多信息可在自然投资组合报告摘要链接到本文。
数据可用性
我们根据我们的系统文献综述中确定的研究编制了此分析中使用的数据。我们已经制作了通过项目开放科学框架存储库获得的数据(https://osf.io/wrq7c/?view_only = b9e1E86079C048B4BFB03BEE6BEE6966E560)。在我们的系统评论中,我们搜索了以下数据库:计算机械数字库协会(https://dl.acm.org/),科学网(https://clarivate.com/webofsciencegroup/solutions/web-of-science/)和信息系统协会eLibrary(https://aisnet.org/page/aiselibrary)。
代码可用性
我们已经分享了用于通过开放科学框架存储库进行分析的代码(https://osf.io/wrq7c/?view_only = b9e1E86079C048B4BFB03BEE6BEE6966E560)。
参考
Bohr,A。和Memarzadeh,K。in医疗保健中的人工智能(Eds Bohr,A。和Memarzadeh,K。)25 60(Elsevier,2020年)。
Nicolescu,L。&Tudorache,M。T.客户服务中的人类计算机互动:AI Chatbots的体验系统文献综述。电子产品 11,1579(2022)。
Koepnick,B。等。公民科学家的从头蛋白设计。自然 第570章,390â394(2019)。
班萨尔,G.等人。整体是否超过其部分?人工智能解释对互补团队绩效的影响。在过程。2021年 CHI关于计算系统中人为因素的会议81(计算机协会,2021年)。
Buã§Inca,Z.,Lin,P.,Gajos,K。Z.&Glassman,E。L.代理任务和主观措施在评估可解释的AI系统时可能会误导。在过程。第25届智能用户界面国际会议454 A 464(计算机协会,2020年);https://doi.org/10.1145/3377325.3377498
Lai,V.,Liu,H。&Tan,C。``为什么芝加哥欺骗性?在过程。2020 CHI关于计算系统中人为因素的会议1 -13(计算机协会,2020年);https://doi.org/10.1145/3313831.3376873
Zhang,Y.,Liao,Q。V.&Bellamy,R。K. E.信心和解释对AI辅助决策中准确性和信任校准的影响。在过程。2020年公平,问责制和透明会议295 305(计算机协会,2020年);https://doi.org/10.1145/3351095.3372852
班萨尔,G.等人。人类AI团队的更新:理解和解决绩效/兼容性权衡。在过程。第33届AAAI人工智能会议和人工智能会议的第31届创新应用和第9届AAAI人工智能教育进步研讨会2429 2437(AAAI出版社,2019年);https://doi.org/10.1609/aaai.v33i01.33012429
Vaccaro,M。&Waldo,J。混合机器学习与人类判断的影响。交流。ACM 62,104 - 110(2019)。
Larson,J。R. Jr寻找小组表演的协同作用(心理学出版社,2013年)。
Almaatouq,A.,Alsobay,M.,Yin,M。&Watts,D。J.任务复杂性调节组协同作用。过程。国家科学院。科学。美国 118,E2101062118(2021)。
Bo,Z.-H。等人。通过深层神经网络对颅内动脉瘤进行无人干预的临床诊断。图案 2,100197(2021)。
Boskemper,M。M.,Bartlett,M。L.&McCarley,J。S.在模拟的行李筛查任务中测量自动化辅助性能的效率。哼。因素 64,945â961(2022)。
Bondi,E。等。人AI相互作用在选择性预测中的作用。过程。AAAI 会议阿蒂夫。英特尔。 36,5286 - 5294(2022)。
谷歌学术一个
Schemmer,M.,Hemmer,P.,Nitsche,M.,Kã¼hl,N。&Vã¶ssing,M。对人类AI决策中可解释的人工智能实用性的荟萃分析。在过程。2022 AAAI/ACM AI,道德和社会会议617 A 626(计算机协会,2022年)。
Wilson,H。J.&Daugherty,P。R.合作情报:人类和AI正在携手。哈夫。公共汽车。牧师。 96,114 - 123(2018)。
谷歌学术一个
Bansal,G.,Nushi,B.,Kamar,E.优化人工智能以促进团队合作。过程。AAAI 会议阿蒂夫。英特尔。 35,11405年11414(2021)。
谷歌学术一个
Wilder, B.、Horvitz, E. 和 Kamar, E. 学习补充人类。在过程。第29届国际人工智能会议1526年1533年(计算机协会,2020年)。
Rastogi,C.,Leqi,L.,Holstein,K。&Heidari,H。决策中人类和ML优势的分类法,以调查人类ML互补性。过程。AAAI 会议哼。计算。Crowdsourc。 11,127 A39(2023)。
谷歌学术一个
Mozannar,H。等。通过学习的自然语言规则和入职,有效的人AI团队。副词。神经信息。过程。系统。 36(2023)。
Cohen,J。行为科学的统计功效分析(学术出版社,2013年)。
Shin,W.,Han,J。&Rhee,W。可再生能源系统的预测维护。活力 221,119775(2021)。
Noti,G。&Chen,Y。学习何时为人类决策者提供建议。在过程。第33届国际人工智能会议3038 3048(计算机协会,2022年);https://doi.org/10.24963/ijcai.2023/339
Chen,V.,Liao,Q。V.,Wortman Vaughan,J。&Bansal,G。了解人类直觉在人类AI决策中的作用,并通过解释。过程。ACM 嗡嗡声。计算。相互影响。 7,370(2023)。
Reverberi,C.等人。有效的人AI在医疗决策中合作的实验证据。科学。代表。 12,14952(2022)。
Liu,H.,Lai,V。&Tan,C。了解分布外的例子和互动解释对人AI决策的影响。过程。ACM 嗡嗡声。计算。相互影响。 5,408(2021)。
Lai,V.,Chen,C.,Smith-Renner,A.在过程。2023 ACM公平,问责制和透明会议1369年1385年(计算机协会,2023年);https://doi.org/10.1145/3593013.3594087
Sperrle,F。等。以人为中心的机器学习中以人为中心的评估的调查。计算。图形。论坛 40,543 - 568(2021)。
Maadi,M.,Akbarzadeh Khorshidi,H。&Aickelin,U。国际。J.环境。资源。公共卫生 18,2121(2021)。
Skitka,L。J.,Mosier,K。L.&Burdick,M。自动化偏见决策吗?国际。J.哼。计算。螺柱。 51,991 1006(1999)。
Buã§Inca,Z.,Malaya,M。B.&Gajos,K。Z.信任或思考:认知强迫功能可以减少对AI辅助决策中对AI的过度依赖。过程。ACM 嗡嗡声。计算。相互影响。 5,188(2021)。
Vasconcelos,H。等。解释可以减少决策过程中对AI系统的过度依赖。过程。ACM 嗡嗡声。计算。相互影响。 7,129(2023)。
Donahue,K.,Chouldechova,A。和Kenthapadi,K。人类算法合作:实现互补性并避免不公平。在过程。2022 ACM公平,问责制和透明会议1639年1656年(计算机协会,2022年);https://doi.org/10.1145/3531146.3533221
Cabrera,A。A.,Perer,A。&Hong,J。I.通过描述AI行为,改善了人类AI的合作。过程。ACM 嗡嗡声。计算。相互影响。https://doi.org/10.1145/3579612(2023)。拉斯托吉,C.等人。
快决策和慢决策:认知偏差在人工智能辅助决策中的作用。过程。ACM 嗡嗡声。计算。相互影响。https://doi.org/10.1145/3512930(2022)。Hedges,L。V.什么是效果大小,为什么我们需要它们?
儿童开发。透视。 2,167 - 171(2008)。
Jacobs,M。等。机器学习建议如何影响临床医生治疗选择:抗抑郁药选择的例子。译。精神病学 11,108(2021)。
Tschandl,P。等。人类计算机识别的计算机协作。纳特。医学。 26,1229年1234(2020)。
Jussupow,E.,Spohrer,K.,Heinzl,A。&Gawlitza,J。增强医学诊断决定?通过人工智能对医师决策过程的调查。信息。系统。资源。 32,713 - 735(2021)。
He,Z.,Song,Y.,Zhou,S。&Cai,Z。思想相互作用:旨在与能力意识到的共同的心理模型中的人AI合作中调解任务分配。在过程。2023 CHI关于计算系统中人为因素会议353(计算机协会,2023年);https://doi.org/10.1145/3544548.3580983
Liang,G.,Sloane,J。F.,Donkin,C。&Newell,B。R.适应算法:准确性比较如何促进决策辅助的使用。认知。资源。王子。隐含的。 7,14(2022)。
Papenmeier,A.,Kern,D.,Englebienne,G。&Seifert,C。这很复杂:AI中用户信任,模型准确性和解释之间的关系。ACM 翻译。计算。哼。相互影响。https://doi.org/10.1145/3495013(2022)。Borenstein,M.,Hedges,L。V.,Higgins,J。P.&Rothstein,H。R.
荟萃分析简介(John Wiley&Sons,2021)。Wilcox, L.、Brewer, R. 和 Diaz, F. AI 同意未来:临床医生语音数据收集的案例研究。
过程。ACM 嗡嗡声。计算。相互影响。 7,316(2023)。
Karinshak,E.,Liu,S。X.,Park,J。S.&Hancock,J。T.与AI合作以说服:检查大语言模型的生成亲疫苗接种消息的能力。过程。ACM 嗡嗡声。计算。相互影响。 7,116(2023)。
Vimpari,V.,Kultima,A.,Hémâ€隆,P。&Guckelsberger,C。 - 游戏行业专业人员的图像生日。过程。ACM 嗡嗡声。计算。相互影响。 7,131 - 164(2023)。
Liu,X。B.等。体验视觉感官:使用大型语言模型增强实时视觉效果的交流。在兼职第36届年度ACM用户界面软件和技术研讨会85(计算机协会,2023年);https://doi.org/10.1145/3586182.3615978
Jo,E.,Epstein,D.A.,Jung,H。&Kim,Y.-H。了解部署会话AI利用大型语言模型进行公共卫生干预的好处和挑战。在过程。2023 CHI关于计算系统中人为因素会议18(计算机协会,2023年)。
Petridis,S。等。Anglekindling:通过大语言模型支持新闻角度构想。在过程。2023 CHI关于计算系统中人为因素会议225(计算机协会,2023年)。
Jakesch,M.,Bhat,A.,Buschek,D.,Zalmanson,L。&Naaman,M。与有见识的语言模型共同写作会影响用户的观点。在过程。2023 CHI关于计算系统中人为因素会议111(计算机协会,2023年)。
Mirowski,P。,Mathewson,K。W.,Pittman,J。&Evans,R。与语言模型共同创作的剧本和戏剧脚本:行业专业人员评估。在过程。2023 CHI关于计算系统中人为因素会议355(计算机协会2023)。
Noy,S。&Zhang,W。有关生成人工智能的生产力影响的实验证据。科学 第381章,187年(2023)。
贝尔(P.哈佛商业评论(2024年2月26日);https://hbr.org/2024/02/your-organization-isnt-designed to-work-with-genai
Campero,A。等。评估人类计算机系统性能的测试。预印本于https://arxiv.org/abs/2206.12390(2022)。
Kitchenham,B。执行系统评价的程序。技术报告TR/SE-0401(Keele University,2004年);https://citeseerx.ist.ist.psu.edu/document?repid=rep1&type=pdf&doi = 29890a9366639862f45cb9a987ddd5999999dce9759bf5
Moher,D.,Liberati,A.,Tetzlaff,J.,Altman,D。G.&Prisma Group更喜欢报告项目的项目评论和荟萃分析:Prisma声明。安.实习生。医学。 151,264 269(2009)。
Groh, M.、Epstein, Z.、Firestone, C. 和 Picard, R. 人类群体、机器和机器知情群体的 Deepfake 检测。过程。国家科学院。科学。美国 119,E2110013119(2022)。
Tejeda, H.、Kumar, A.、Smyth, P. 和 Steyvers, M. 人工智能辅助决策:一种推断潜在依赖策略的认知建模方法。计算。大脑行为。 5,491 - 508(2022)。
希金斯(J. P.在干预系统评价 Cochrane 手册6.5版(Eds Higgins,J.P。T.等人)6(Cochrane,2024)。
Rohatgi,A。WebPlotDigitizer v.4.5https://automeris.io/webplotdigitizer(汽车,2020年)。
Hedges,L。V.玻璃的效应大小和相关估计量的分布理论。J.教育。统计。 6,107â128(1981)。
Hedges,L。V。&Olkin,I。荟萃分析的统计方法(学术出版社,2014年)。
Van den noortgate,W.,Lã³pez-lãpez,J.A.行为。资源。方法 47,1274年1294(2015)。
张,M。W。-L。使用三级荟萃分析建模依赖性效应大小:一种结构方程建模方法。心理。方法 19,211 229(2014)。
Hedges,L。V.,Tipton,E。&Johnson,M。C.元回归的稳健方差估计,并具有依赖性效应大小估计。资源。合成器。方法 1,39 - 65(2010)。
Higgins,J。P.和Thompson,S。G.量化荟萃分析中的异质性。统计。医学。 21,1539年1558(2002)。
Viechtbauer,W。&Cheung,M。W.-L.荟萃分析的异常值和影响诊断。资源。合成器。方法 1,112â125(2010)。
Sterne,J。A.和Egger,M。用于检测荟萃分析偏置的漏斗图:轴选择指南。J.克林。流行病。 54,1046 1055(2001)。
Peters,J。L.,Sutton,A。J.,Jones,D。R.,Abrams,K。R.&Rushton,L。Contour-Contour-Contour-grom-has-hanged荟萃分析漏斗图有助于区分出版偏见和其他不对称原因。J.克林。流行病。 61,991 - 996(2008)。
Egger,M.,Smith,G。D.,Schneider,M。&Minder,C。通过简单的图形测试检测到的荟萃分析中的偏差。英国医学杂志 315,629 - 634(1997)。
Begg,C。B.&Mazumdar,M。出版偏见的等级相关测试的操作特征。生物识别技术 50,1088年1101(1994)。
Rothstein,H。R.,Sutton,A。J.&Borenstein,M。In荟萃分析中的出版偏见:预防,评估和调整(Eds Rothstein,H。R.等人)1â7(John Wiley&Sons,2005年)。
Altman,N。&Krzywinski,M。分析异常值:有影响力还是令人讨厌?纳特。方法 13,281 283(2016)。
Viechtbauer, W. 使用 metafor 包在 R 中进行荟萃分析。J. 统计。软件。 36,1 - 48(2010)。
致谢
MV由埃森哲技术融合奖学金资助。额外的资金给T.M.由丰田研究所(Toyota Research Institute),麻省理工学院的情报探索和新加坡总理办公室的国家研究基金会提供,在其卓越研究和技术企业校园下提供。资助者在研究设计、数据收集和分析、出版决定或手稿准备中没有任何作用。我们感谢J. Kim和G. Campagna为该项目收集数据的帮助,并感谢D. Eckles,M。Alsobay,R。Na和E. Hu的有益反馈。
道德声明
利益竞争
作者声明没有竞争利益。
同行评审
同行评审信息
自然人类行为感谢Hamsa Bastani和另一个匿名,评论者对这项工作的同行评审的贡献。同行评审者报告可用。
附加信息
出版商备注施普林格·自然对于已出版的地图和机构隶属关系中的管辖权主张保持中立。
补充资料
权利和权限
开放获取本文根据知识共享署名 4.0 国际许可证获得许可,该许可证允许以任何媒介或格式使用、共享、改编、分发和复制,只要您对原作者和来源给予适当的认可,并提供链接到知识共享许可证,并指出是否进行了更改。本文中的图像或其他第三方材料包含在文章的创意共享许可证中,除非在材料的信用额度中另有说明。如果文章的创意共享许可中未包含材料,并且您的预期用途不得由法定法规允许或超过允许的用途,则需要直接从版权所有者那里获得许可。要查看该许可证的副本,请访问http://creativecommons.org/licenses/by/4.0/。转载和许可
引用这篇文章

Vaccaro,M.,Almaatouq,A。&Malone,T。人类和AI的组合有用时:系统评价和荟萃分析。
Nat Hum Chand(2024)。https://doi.org/10.1038/s41562-024-02024-1
已收到:
公认:
已发表:
DOI:https://doi.org/10.1038/s41562-024-02024-1