

中国人工智能初创公司 DeepSeek 的最新模型在“推理”任务中超越 OpenAI 的 o1 - SiliconANGLE
作者:by Mike Wheatley
中国人工智能初创公司 DeepSeek 的最新模型在“推理”任务中超越了 OpenAI 的 o1

中国人工智能初创公司深度搜索有温韦伊我编辑据称,一种新的“推理”模型与 OpenAI 的 o1 大语言模型相比非常有利,该模型旨在比传统法学硕士更准确地回答数学和科学问题。
这家初创公司是量化对冲基金 High-Flyer Capital Management Ltd. 的分支机构,于 X 揭晓今天,它推出了第一个推理模型 DeepSeek-R1 的预览版。
推理模型与标准法学硕士不同,因为它们能够“事实检查”他们的回答。为了做到这一点,他们通常会花更长的时间考虑应该如何响应提示,从而避免诸如“幻觉”之类的问题,这些问题在 ChatGPT 等聊天机器人中很常见。
当开放人工智能发布o1型号九月份,它表示它在处理需要推理技能的查询和问题方面要好得多。这是因为它依赖于一种被称为“思想链”或 CoT 的机器学习技术,该技术使其能够将复杂的任务分解为更小的步骤并逐一执行,从而提高其准确性。
DeepSeek 的工作方式类似,在遇到复杂问题时提前计划,逐一解决,以确保能够准确响应。不过,这个过程可能需要一段时间,并且像 o1 一样,它可能需要“思考”长达 10 秒才能生成问题的响应。
该模型的思维过程也是完全透明的,用户可以遵循它来处理得出答案所需的各个步骤。
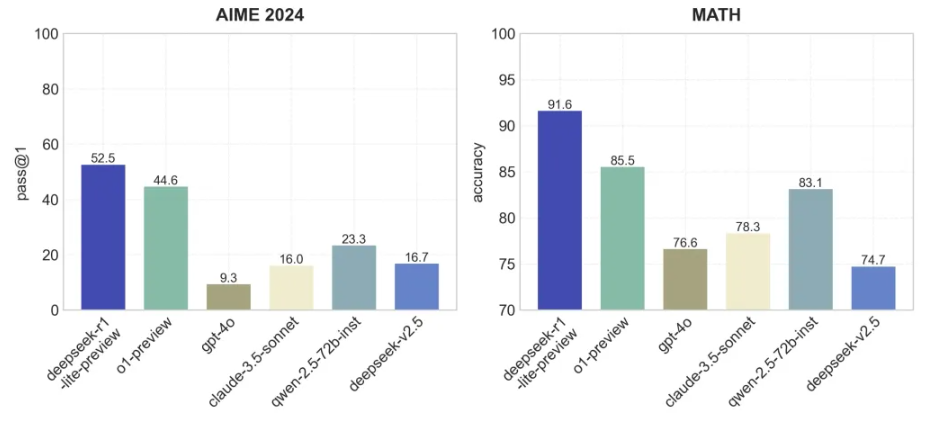
该初创公司表示,DeepSeek-R1 在 AIME 和 MATH 两个关键基准测试上超越了 o1 的功能。前者使用其他AI模型来评估LLM的表现,而后者则是一系列复杂的文字问题。此外,该模型还表明正确回答据 VentureBeat 报道,许多“诡计”问题导致 GPT-4o 和 Anthropic PBCs Claude 等现有模型陷入困境。
然而,DeepSeek-R1 确实存在许多问题,X 上的一些评论者表示它似乎很挣扎和逻辑问题例如井字游戏。也就是说,o1 也遇到了同样的问题。
用户还报告说,DeepSeek 不会回应中国政府可能认为过于敏感的询问。当被问及天安门广场大屠杀、中国国家主席习近平与唐纳德·特朗普的关系以及中国入侵台湾等事件时,它始终回答说,它“不确定如何处理此类事件”。问题。 –
DeepSeek 拒绝政治敏感查询可能源于中国开发商需要确保他们的模型“体现社会主义核心价值观”。
尽管如此,一些用户还透露,越狱 DeepSeek 非常容易,并以忽略其护栏的方式提示它。例如,一个用户找到了一种方法让它提供详细食谱以及制造甲基苯丙胺的说明,当然,这在大多数国家都是高度非法的。
DeepSeek 是一家相当不寻常的人工智能初创公司,这要归功于一家量化对冲基金的支持,该基金旨在利用法学硕士来增强其交易策略。这在人工智能领域并不新鲜,之前发布的名为 DeepSeek-V2 的法学硕士,用于通用文本和图像生成和分析。它由计算机科学专业毕业生梁文峰创立,其既定目标是实现“超级智能”人工智能。
DeepSeek-R1 可以通过以下方式访问深度搜索聊天在公司网站上申请。尽管它可以免费使用,但非付费用户每天只能发送 50 条消息。该公司还计划通过应用程序编程接口提供 DeepSeek-R1。
图片:SiliconANGLE/Freepik AI
您的支持票对我们很重要,它有助于我们保持内容免费。
一键点击即可支持我们提供免费、深入且相关的内容的使命。一个
加入我们的 YouTube 社区
加入由超过 15,000 名 #CubeAlumni 专家组成的社区,其中包括 Amazon.com 首席执行官安迪·贾西 (Andy Jassy)、戴尔技术公司 (Dell Technologies) 创始人兼首席执行官迈克尔·戴尔 (Michael Dell)、英特尔首席执行官帕特·基辛格 (Pat Gelsinger) 以及更多名人和专家。
谢谢