

当人工智能摘要取代超链接时,思想本身就被扁平化了 |永旺随笔
20 世纪 90 年代末,Google 凭借谢尔盖·布林 (Sergey Brin) 和拉里·佩奇 (Larry Page) 开发的非凡创新:PageRank 算法,击败了其他搜索引擎的竞争。虽然较旧的搜索引擎,例如 AltaVista、Yahoo 和(谁能忘记)Ask Jeeves 主要依赖于将用户查询的术语与网页上相同和相似术语的频率进行匹配,但 Google 通过以下方式找到了更有用的网站:跟踪哪些页面具有最高数量和质量的传入链接。PageRank 背后的基本思想是“如果某个网页被其他重要页面指向,则该网页很重要”。布林和佩奇意识到,网络不仅仅是一个词汇环境,而且是一个社交环境,其中链接与声誉相对应,而位于网络中心的网站往往是最可靠的。佩奇后来评论说,其他搜索引擎“只查看文本,而不考虑其他信号。”
PageRank 背后的想法并不新鲜。社会学家约翰·R·西利 (John R Seeley) 在 1949 年写道,“如果一个人得到了有声望的人的认可,他就是有声望的。”1976 年,加布里埃尔·平斯基 (Gabriel Pinski) 和弗朗西斯·纳林 (Francis Narin) 将类似的方法应用于文献计量学,声称即:“如果期刊被其他有影响力的期刊引用,则该期刊具有影响力。”然而,PageRank 的新颖之处在于它在网络上的应用。PageRank 的成功是因为它认识到语言不是凭空产生的。词语模式取决于其他形式的联系:使网络成为现实世界代表的社会和物理联系。
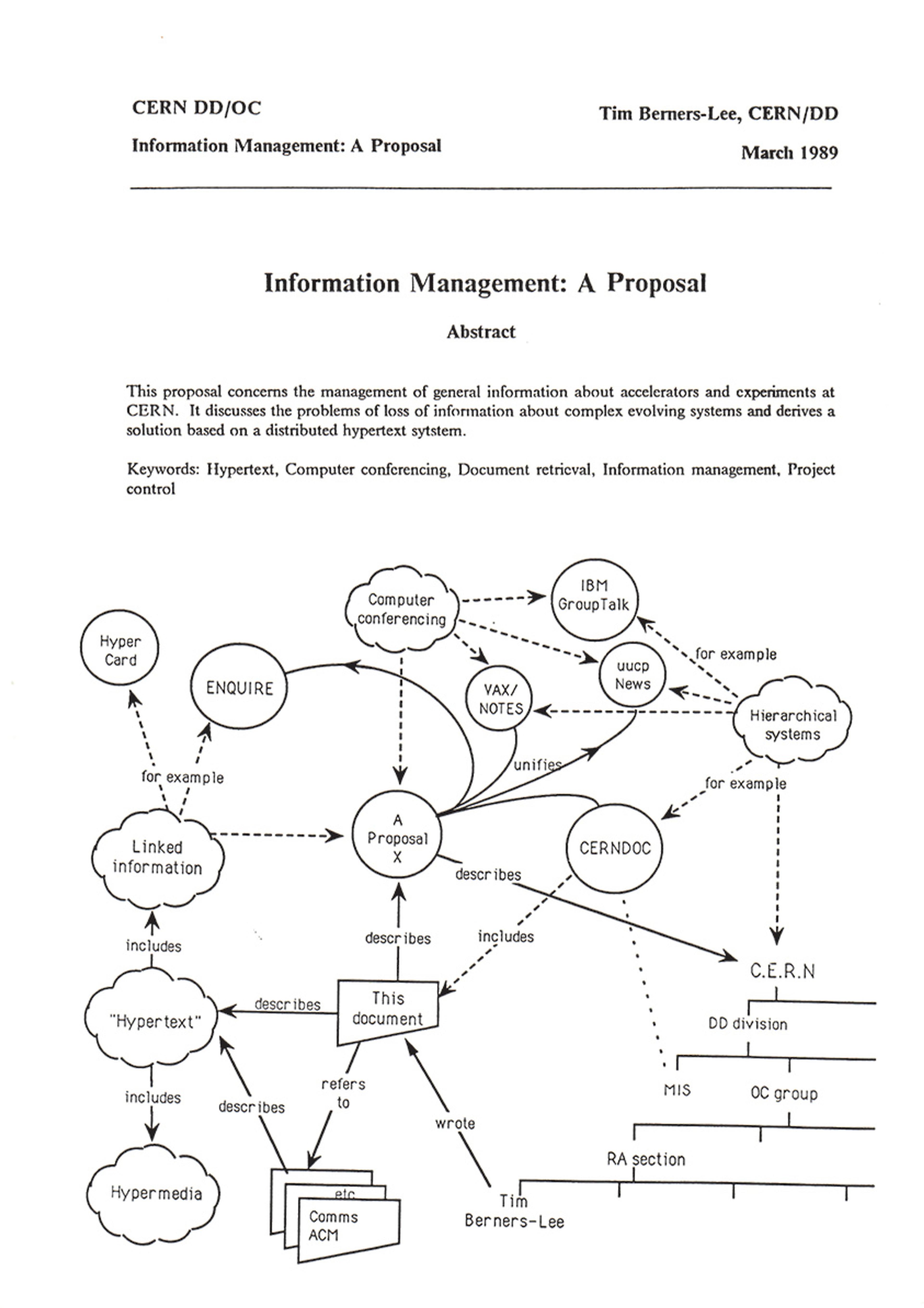
1989 年 3 月蒂姆·伯纳斯·李 (Tim Berners-Lee) 提出的万维网提案的第一页。由对方提供欧洲核子研究中心
超链接如此运作的一个原因(它们索引其他类型的联系的原因)是,它们首先被设计用来展示研究人员在开发新想法时在不同来源之间建立的联系。蒂姆·伯纳斯·李的万维网超文本协议的早期计划被提出作为记录人类思维如何从一个想法转移到另一个想法、连接外部刺激和内部反射的工具。Links 将创造力视为补救和重塑的工作,这在 Google 学术搜索的口号中得到了强调:“站在巨人的肩膀上。”
但现在谷歌和其他网站正在放弃依赖链接,转而使用人工智能聊天机器人。链接被认为是相互关联的想法的保留痕迹,作为人工智能革命的早期受害者,它是有意义的,因为大型语言模型(LLM),如 ChatGPT、Google 的 Gemini 等,抽象了在线表示的信息,并以无源摘要的形式呈现。我们正处于网络历史上的一个时刻,链接本身——网站创建者建立的无数连接,整个网络编织在一起的无尽的想法——正面临灭绝的危险。因此,我们有必要问:链接最初是如何代表信息的?从链接转向人工智能聊天界面的趋势是什么?时间
要回答这些问题,我们需要回到17世纪,当作家和哲学家发展出最终启发早期超文本计划的心灵理论时。在这个时代,著名的哲学家,包括托马斯·霍布斯和约翰·洛克,争论了一个人在多大程度上控制出现在她脑海中的想法的连续性。他们认为,思想的连续性反映了从感官接收到的数据与人的心智能力(理性和想象力)之间的相互作用。随后,大卫·休谟认为所有连续的想法都是通过联想联系起来的。他列举了思想之间的三种联想联系:相似性、邻近性和因果性。在关于人类理解的探究(1748),休谟提供了每种关系的例子:
一幅画自然而然地将我们的思绪引向原著:提到建筑物中的一间公寓,自然会引发对其他公寓的询问或讨论:如果我们想到伤口,我们几乎会忍不住反思它所带来的痛苦。跟随它。
头脑遵循在世界上发现的联系。洛克和休谟认为,人类所有的知识都来自经验,因此他们必须解释大脑如何接收、处理和存储外部数据。他们经常利用媒体隐喻来描述思想与世界之间的关系。洛克将心灵比作一块空白的平板电脑、一个柜子和一个暗箱。休谟依靠印刷语言来区分印在人们感官上的生动印象和脑海中回忆起的想法。
印刷术实现了远距离通信,这为歧义和有争议的含义创造了新的机会
比较也有相反的情况。洛克、休谟和其他人探索了他们周围的物质如何表现出思维模式。在新的梳妆台方法(1685),后来出版为制作普通书籍的新方法(1706),洛克在常见的书籍格式中添加了主题索引,这种格式自古以来一直用于记笔记。一位历史学家认为,通过索引添加主题关联“将知识转化为模式和系统,以便即时、有动力地使用。”当代作家和印刷商同样开发了网络化、非线性形式的方案。可能容纳心理联系的媒体。随着 1700 年代印刷品的爆炸性流行,作家们使用了交叉引用、索引,并且在那个时代的一部伟大作品中还使用了脚注。亚历山大·蒲柏的讽刺诗邓西亚德(1728)被马歇尔·麦克卢汉称为“印刷文字的史诗”,攻击印刷商用廉价的小册子和单页大幅面充斥伦敦。然而,在戏仿中,这首诗也将印刷格式推向了一个新的复杂水平。
这首诗讲述了一群笨蛋的故事,女神愚钝在伦敦加冕为新的胡言乱语之王,波普在诗中散布了他现实生活中目标的荒谬版本。它一开始是一部典型的模仿史诗讽刺剧,蒲柏采用了荷马的风格。伊利亚特和奥德赛讽刺他的文学对手的琐碎失败。许多竞争对手都以评论和“钥匙”的形式做出回应,声称要破译这首诗的出处。反过来,波普又在这首诗的众多后续版本中添加了大部分评论(以及一位虚构编辑的评论)作为脚注。在 Pope 1743 年的最终版本中,页面通常只包含一两行诗,后面跟着几段评论。这本书是超文本的。它将读者从诗句发送到注释,再到注释上的注释,到各种序言和附录,然后回到诗句。邓西亚德类似于充满超链接和评论的网站。
在不断修改讽刺作品的过程中,波普发现很难用印刷品来辨别世界上的人和物体。他的朋友兼讽刺作家乔纳森·斯威夫特 (Jonathan Swift) 对教皇说:“我长期以来观察到,20英里在伦敦,没有人能理解暗示、首字母、城镇事实和段落;几年之内,甚至那些住在伦敦的人也不会这样了。”与需要密切社区的口头和手稿文化不同,印刷品实现了远距离交流,这为歧义和有争议的意义创造了新的机会。印刷品需要新的修辞和安排策略。后来的迭代这邓西亚德 波普强调印刷媒体产生的沉闷的形状和形式,转向抽象字符。在第三册,《废话之王》提供了一种沉闷的景象——以圆形、反射性运动的模式永久回归:
正如人类迈安德斯走向生命之泉
卷起他们所有的潮汐,然后带回他们的圈子;
或者是由熟练的侍者旋转的旋转木马,
将线吸进去,然后再次将其释放:
因此,无论古代还是现代,所有的废话,
将以你为中心,从你开始流通。
“Maeanders”在古希腊指的是蜿蜒的河流,当然也指蜿蜒的一般动作。波普的诗充满了回声、反射和漩涡的图像,暗示着复制品如何呈现其来源的暗淡版本,就像月亮仅暗示太阳的亮度一样。就像泉水一样,这 邓西亚德这句话在伦敦各地流传,在波普所攻击的作家和印刷商的作品中,他们的言论同样在他的诗的后来版本中再次出现。由此产生的互文网络取代了这首诗最初创造的网络,成为对新兴印刷世界的新描述。时间
在此期间,作家和印刷商不断开发印刷语言的排列方式,挑战了媒体典型的线性结构。著名的例子包括法国的交叉引用和雕刻图百科全书 (1751-72)。该项目以 Ephraim Chambers 的英语为基础百科全书(1728),明确引用关联理论来解释交叉引用如何使读者能够从单个条目中重建知识体系。

以法莲钱伯斯百科全书(1728)。维基百科提供
一个世纪后,我们可以观察到作家如何理解思想与媒体之间的关系的另一个转变。詹姆斯·米尔和他的儿子约翰·斯图尔特·密尔提出了建立在 18 世纪联想理论基础上的综合心理学理论。然而,联想主义理论最持久的影响来自西格蒙德·弗洛伊德将自由联想发展为精神分析治疗的实践。在联想主义与文学想象力(2007),凯恩斯·克雷格(Cairns Craig)观察到,“弗洛伊德的‘自由联想’技巧邀请病人去做经验主义传统的联想主义美学一直坚持读者在体验一首诗时所做的事情。”他引用了 18 世纪末散文家阿奇博尔德·艾利森 (Archibald Alison) 的话,他将阅读一首诗描述为 [letting]我们的想象力“忙于追寻诗人的所有那些思绪”。
早期心理学对思想关联的强调伴随着观察思想序列的媒介从印刷技术转向音频技术的转变。1912年,弗洛伊德将精神分析师的角色比作电话听筒:
正如接收器将电话线上由声波产生的电振荡转换回声波一样,医生的无意识也能够从传达给他的无意识的衍生物中重建出无意识。,这决定了患者的自由联想。
弗洛伊德的技术想象了一种新的联想情境,在这种情境中,治疗师能够观察和分析患者想法之间的每一个联系。就像几个世纪前的洛克一样,弗洛伊德通过他那个时代的媒体来更好地理解人类的思想。
“我所有的计算机工作都是为了表达和展示作品之间的相互联系”
同样,在 20 世纪初,早期的计算机技术通过将印刷的文本形式与电力的速度相结合,提供了一种捕捉工作中思维的新方法。在第二次世界大战和原子弹爆炸之后,麻省理工学院的科学家万尼瓦尔·布什探索了技术如何能够丰富而不是摧毁人类社会。在发表于的一篇文章中这 大西洋在 1945 年的杂志上,他提出了计算机技术史上最著名的 vapourware 之一,即一种双屏缩微胶片机,他将其称为“memex”,这是“内存扩展器”的混合词。他的想法是允许用户在文章和书籍的文本以及他们自己的笔记之间创建连接链,即“关联轨迹”,从而产生类似于洛克常见书籍的电子版本。用户可以将代码附加到特定的段落和注释中,以创建他们可以追溯的轨迹,以恢复他们最初的思路。当泰德·尼尔森 (Ted Nelson) 1965 年在一篇文章中创造“超文本”一词时,他将布什的模拟设计视为模型。纳尔逊将超文本解释为“以复杂方式相互关联的材料,无法方便地在纸上呈现或表示。”超级- 前缀表示“扩展和一般性”,在数学中用于指代多维空间。尼尔森想象了一种可以代表思维的网络形态而不受印刷品二维限制的形式。

Ted Nelson 在 1965 年的原创文章中介绍了“超文本”一词。由互联网档案馆提供/Ted Nelson
布什和纳尔逊设想媒体能够让用户捕捉他们的思维习惯,尤其是一个想法立即引发另一个想法的感觉。在沃纳·赫尔佐格有关互联网的纪录片中,你瞧(2016),尼尔森描述了一段童年记忆,他认为这段记忆启发了他对超文本的愿景:
我把手伸进水里,想着水如何在我的手指周围移动,一侧张开,另一侧闭合,以及那种不断变化的关系系统……并将其推广到整个宇宙世界是一个不断变化的关系和结构的系统,这让我觉得这是一个巨大的真理……因此互连和表达互连一直是我所有思考的中心,我所有的计算机工作都是关于表达和表达代表并展示著作之间的相互联系。
尼尔森被广泛认为是 20 世纪 90 年代网络发展中最有影响力的作家之一。然而,他长期以来一直认为自己是一个被遗弃的人。和布什一样,他对新媒体最雄心勃勃的计划从未实现。其中包括一个名为“Xanadu”的网络浏览器,它可以容纳比我们熟悉的更强大的链接模型。对于纳尔逊来说,参考文献和链接应该指向其来源。如果您在文本中引用一位作者,那么该文本应该链接到原始文档,并且读者应该能够并排查看引用文档和原始文档,就像布什对模因的布局所设想的那样。从某种意义上说,纳尔逊想象了教皇的通用版本邓西亚德——人类思想史,用户可以在其中追踪台词和短语如何从一部作品转移到另一部作品。
我n你瞧赫尔佐格想知道互联网已经并将继续改变我们与语言和世界联系的方式。在影片的结尾,赫尔佐格问几位受访者:“互联网会梦想自己吗?”他将这个问题解释为对普鲁士战争理论家卡尔·冯·克劳塞维茨的一句话的重复,即““有时战争梦想本身就是如此”(尽管这一说法可能是杜撰的)。克劳塞维茨认为,战争可以有自己的生命。它可以自主地继续。一位受访者认为,这个问题暗示了互联网在没有任何人主动设计的情况下产生的“活动模式”。如果对波普来说,印刷机似乎鼓励在没有上下文的情况下进行复制和传播,那么互联网启动了哪些超出工程师和网页设计师控制范围的活动呢?
一种答案可能是链接所体现的连接。第一个实际的超文本系统比网络出现早大约五年,即 20 世纪 80 年代初。正如软件历史学家 Matthew Kirschenbaum 所观察到的,早期的超文本应用程序,包括 Apple 的 HyperCard 和 Eastgate 的 Storyspace(均于 1987 年首次发布),是个人计算机革命的产物,而不是网络。杰·大卫·博尔特 (Jay David Bolter) 和迈克尔·乔伊斯 (Michael Joyce) 开发了 Storyspace,作为一款用于创建超文本小说、选择自己的冒险类型故事的软件,其中读者决定如何浏览通过链接连接的剧集。乔伊斯使用该软件编写了被认为是第一部长篇超文本小说,下午,一个故事(1987)。他想要创造“一个每次阅读都会发生变化的故事”。读者通过作品的节点和链接的路径构建了故事的情节。这项工作与斯图尔特·莫尔索普斯 (Stuart Moulthrop) 合作胜利花园(1991) 和雪莱·杰克逊 (Shelley Jackson)拼布女孩(1995)构成了后来被称为超文本文学的“故事空间学派”。
虽然这些作品在 20 世纪 90 年代中后期引起了广泛关注,但并未产生持久影响。然而,为使超文本小说成为可能而开发的软件和工具仍然很流行。当然,最著名的超文本系统是万维网,它比早期的系统更先进,允许用户在位于世界各地的服务器上托管的站点之间进行链接。笔记和组织应用程序也合并了超文本功能。虽然 Eastgate 最初是一家创作超文本小说的公司,但后来它的 Tinderbox 应用程序取得了成功,这是一款笔记应用程序,可以根据用户创建的主题链接笔记和媒体。从互联网到万维网的数字网络所鼓励的活动模式是建立联系,创建更复杂的网络。
这些平台的主要特点是综合、总结和解释信息的能力
人工智能聊天机器人旨在取代在网站之间和个人思维中建立联系的工作。大多数关于人工智能的讨论都关注人工智能模型多久能实现“通用人工智能”,或者人工智能实体何时能够决定自己的任务并做出自己的选择。但一个更基本、更紧迫的问题是:人工智能平台目前产生什么样的活动模式?AI会做自己的梦吗?
如果波普的诗让读者充满声音——从诗中的笨蛋到脚注中的竞争评论者,人工智能聊天机器人往往会产生相反的效果。无论是 ChatGPT 还是 Google 的 Gemini,人工智能都会将众多声音合成为单调的声音。这些平台提供了一个开场答案、项目符号列表和结论性摘要。如果你要求 ChatGPT 描述它的声音,它会说它已经过训练,可以用中性而清晰的语气回答。该平台的重点是听起来像没有人。
不过,并非所有基于人工智能的网站都会丢弃链接。Perplexity 是一个人工智能搜索平台,旨在通过添加外部来源的脚注来纠正 ChatGPT 和其他机器人提供的引用不足的问题。(Arc Search 是另一个尝试这种方法的平台。)Perplexity 平台可以链接到源,因为它实际上是一个混合搜索引擎和 AI 语言模型。与所有人工智能聊天机器人一样,法学硕士会对用户的问题做出答复,但 Perplexity 将这种答复与其搜索引擎的结果结合起来,该搜索引擎每天都会对网络进行索引。问题是,在爬行不同的网站时,人们发现 Perplexity 抄袭文章和图像,但很少或根本没有提及来源。但更根本的是,搜索已经解决了为用户查询找到可靠信息的问题,至少达到了与人工智能平台相同的程度。搜索对于人们使用人工智能聊天机器人的原因来说是偶然的。这些平台的主要特点是它们综合、总结和解释信息的能力。他们执行这些任务的能力取决于消化大量文本并从特定来源抽象语言模式。
在文学批评中,克林斯·布鲁克斯攻击了他所谓的“释义异端”。在精心打造的瓮(1947),他认为读者不能通过解释一首诗“所说的”来总结一首诗。诗歌不像普通语言那样发挥作用。它不能还原为其命题内容。相反,定义一首诗的是其语义元素和非语义元素之间的相互作用。“诗歌的结构类似于芭蕾舞或音乐作品的结构,”布鲁克斯认为。“这是一种决议、平衡与协调的模式。”
当我们通过链接浏览网络时,我们正在浏览其他人建立的一系列连接
尽管领域不同,布鲁克斯的批评呼应了布什和纳尔逊在超文本系统计划中表达的想法。链接揭示了一个往往隐藏在作家头脑中的创作过程——连接想法和构建更大事物的过程:论证、故事甚至诗歌。布什和纳尔逊认为,链接展示了自然的思维模式——思维从一个想法跳到另一个想法的方式——而且也展示了我们阅读和写作的模式。我们读了一段话,它引发了与我们之前遇到的其他五件事的联系。释义是异端,因为它平息了诗歌的紧张、讽刺和冲突。乔治·兰多 (George Landow) 在他的超文本理论中描述布什的模因方法是“诗意的机器”,是根据类比和联想工作的机器,是捕捉和创造人类想象力的无政府主义才华的机器。
我们可能会考虑研究某个主题的用户如何通过搜索和链接浏览网络。初始查询会生成一个结果列表,其中一些相关且值得信赖,另一些则不太相关。研究人员在新选项卡中打开了几个链接。然后,她浏览最有希望的页面,单击指向要更详细探讨的主题各个方面的嵌入式链接。当研究人员遵循不同的联想轨迹时,她面临着矛盾和令人困惑的观点。她必须弄清楚如何解决跨多个页面出现的紧张和冲突。在关于 memex 的第二篇文章中,布什描述了他的链接微胶片台所容纳的类似过程:
可以说,模因的所有者对弓箭的起源和特性感兴趣。具体来说,他正在研究为什么土耳其短弓在十字军东征的小冲突中明显优于英国长弓。他的模因中有数十本可能相关的书籍和文章。首先,他浏览了一本百科全书,找到了一篇有趣但粗略的文章,然后将其投影出来。接下来,在历史中,他找到了另一个相关项目,并将两者联系在一起。他就这样走着,建立了一条由许多物品组成的踪迹。有时,他会插入自己的注释,要么将其链接到主路径中,要么通过旁路将其连接到特定项目。
网络通过保留关联痕迹,使布什描述的调查过程成为可能。当我们通过链接浏览网络时,从某种意义上说,我们是在浏览别人建立的一系列连接,就像阅读他们写的东西一样。这是教皇的一部分邓西亚德揭示了——媒介的形状——形式传达其内容,而形式和内容之间的相互作用是其产生意义的方式。这当然是 Page 和 Brin 在实现 PageRank 算法时认识到的。链接和文本一样重要。
D尽管有这一突破性的发现,2024 年 5 月 14 日在 Google 的 I/O 大会上,该公司宣布计划放弃搜索结果界面,转向人工智能摘要。谷歌母公司 Alphabet 首席执行官桑达尔·皮查伊 (Sundar Pichai) 透露,此次会议恰逢“AI Overviews”本周在美国发布。概述显示对查询的摘要响应(如 ChatGPT 的界面),而不是传统的其他网站链接列表。谷歌搜索主管莉兹·里德宣称,似乎是为了让她的工作变得多余,让谷歌“为你进行谷歌搜索”。评论员指出具有讽刺意味的是,谷歌的人工智能模型 Gemini(与所有法学硕士一样)依赖外部网站获取训练数据,以便能够返回准确的响应,但聊天机器人界面似乎会危及其主要数据源,因为用户不鼓励访问这些网站。
布什提出将模因作为一种记忆辅助工具,不仅可以让研究人员追溯思路,还可以让其他用户更好地理解早期思想家建立的联系。网络代表了最大的集体记忆集合存储库,无论是在托管的各个网页中还是在允许用户遍历它们的链接中。如果用户很少访问 Google 或 ChatGPT 的主页,那么如何支持和开发这个存储库?
虽然网络的未来可能看起来很黑暗,但我们可以从波普对印刷品兴起的反应中得到启发。对于波普来说,印刷体裁和惯例的激增导致了麦克卢汉所描述的“视觉能力与其他感官相互作用的日益分离”。然而,尽管印刷品似乎要求一致性和规律性,波普还是找到了一种方法,以代表 18 世纪伦敦城市环境的不和谐声音的方式捕捉印刷品中对立声音的相互作用。网络可能仍会发生变化让我们惊讶。