
使用人工智能技术预测患者对药物的情绪
作者:Wiil, Uffe Kock
介绍
近几十年来,网站和社交媒体上的用户评论急剧增加。用户在相关网站上发布对各种产品的评论,例如药物、电影、餐馆、家用电器、临床服务和营销。人们在购买或使用产品或服务之前阅读评论,这使他们能够根据以前的评论做出明智的决定1,2,3。
医疗和临床报告、患者反馈以及对医疗系统和服务的看法是最有价值和有用的文本内容4,5,6。尽管药物生产后的安全性是在标准临床条件下进行监测和测试的,但人们仍然在药物评论网站上写下他们的评论和观点。这些网站使人们能够在使用药物之前阅读有关药物的评论。临床医生和药剂师还可以利用这些信息来满足患者的期望和体验,最终提高依从性和治疗效果。对患者反馈的情绪分析使临床医生能够通过识别患者报告的常见副作用和与药物相关的满意度来调整处方行为。这种方法增强了临床医生的决策过程,并通过强调可以改善药物疗效或患者体验的领域来为患者护理策略提供信息4,5,6。
使用情绪分析 (SA) 分析此类文本数据是更准确地评估药物有效性和副作用的有用步骤4,5,7,8,9,10,11。预测患者的医学情绪可用于促进未来的治疗,因为已经调查了不同类型的医疗治疗的结果以及对其有效性的认识。分析临床文件中患者的情绪,记录从过去到现在的治疗过程和结果,可以帮助临床医生和药剂师识别影响疾病和治疗的因素12。
SA 是自然语言处理最重要的分支之一,专注于寻找文本中的情感13。在SA中,评论分为不同的级别,包括aspect、entity、sentence和document级别13。SA被称为分类问题,一些研究使用人工智能(AI)技术来解决这个问题6。机器学习(ML)和深度学习(DL)算法是人工智能的分支,它们在临床领域的使用,特别是在临床SA和文本挖掘领域,最近有所增加6,8。
过去的许多研究都使用人工智能技术来检测非临床环境中的情绪1,2,3,14,15,16,17 号,18,19,20。然而,之前在临床和医学领域的研究6,8,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,在第 2 节中进行了回顾,有各种缺点:
-
尚未考虑用于预测情绪的各种场景。
-
大多数研究没有考虑为他们提出的模型找到最佳的超参数。
-
该领域的大多数研究都使用相对较小的数据集。
-
尚未研究在临床领域使用各种预训练词嵌入的影响。
-
AI模型的可解释性和可解释性在临床领域非常重要,但在之前的研究中尚未考虑到。
针对这些缺点,本研究旨在提供一种全面识别药物评论情绪的新方法。为此,开发了七种人工智能技术,包括机器学习和深度学习模型以及两种集成 (ENS) 模型来预测患者的情绪和评分。
总的来说,我们在这项研究中的主要贡献如下:
-
所提出的 ML 和 DL 模型在 drug.com 数据集上进行了训练和测试,该数据集是一个丰富的药物评论数据集。
-
考虑了三种情况来综合确定患者的情绪类别和评分。
-
开发了各种 ML、DL 和 ENS 算法和实验来比较患者情绪和评分的预测。
-
具有新架构的深度集成 (DL_ENS) 模型旨在预测患者的情绪和药物评论中的评分。
-
已找到 ML 和 DL 模型超参数的最佳值,并选择使用网格搜索进行预测。
-
使用各种通用和临床预训练的词嵌入模型来提高人工智能模型的性能。
-
这项研究是第一项使用与本地可解释模型无关的解释 (LIME) 来解释决策过程的研究,以便为药物审查提供可解释和可解释的人工智能模型。
本文的其余部分分为六个部分:第二部分概述了先前关于 SA 的研究,第三部分描述了本研究中使用的材料和方法,第四部分介绍了结果,第五部分是讨论,以及最后,第六节总结了研究并概述了未来的工作。
相关工作
表 1概述了之前的 SA 研究,包括其方法、数据集类型以及研究差距6,8,15,16,17 号,18,19,21,24,25,28,29,30,31,32,35,37,39。
各种研究人员试图分析人们提供的药物评论,以深入了解他们的状况、需求、情绪和每种药物的副作用6,8,28,29,30,31,32,33,34,35,36,37,38,39。SA 可以在该领域发挥重要作用,为上述目的提取有用信息。该领域的大多数研究都是基于样本数量有限的数据集。此外,大多数研究人员都使用基于规则的传统机器学习模型来进行 SA31。
对于药物评论中的 SA,通过 ML 算法(例如支持向量机 (SVM)、逻辑回归 (LR)、朴素贝叶斯 (NB)、决策树 (DT)、随机森林 (RF))获得具有更多样本的数据集), 考虑了 K 最近邻 (KNN)28,30,32,38,39。最近,ML方法也被用于非英语药物评论中的SA,并将其性能与英语药物评论进行了比较32。此外,还提出了新的特征提取方法和机器学习算法来提高药物评论 SA 中模型的性能39。
在药物评论的SA中,已经开发了包括卷积神经网络(CNN)在内的深度学习算法,以在情感分类方面获得更好的性能8,35,36。随着 DL 模型的使用越来越多,这些模型的性能也与药物评论 SA 中的 ML 模型进行了比较。结果表明,与传统的 ML 模型相比,DL 模型具有令人鼓舞的结果6,33,34。最后,在最近的研究中,建议结合深度学习模型(例如 CNN 门控循环单元 (GRU))或双向模型(例如双向门控循环单元 (Bi-GRU))来分析患者药物评论数据集中的情绪29,37。
埃布拉希米等人。31提出了一种情感提取识别系统,使用基于规则和支持向量机算法来识别药物评论中的副作用。药物评论是由医学实验手工选择的,用于模型训练和测试。他们的结果表明,SVM 算法的性能明显优于基于规则的算法。
格雷尔等人。28使用 LR 执行跨域和域内 SA 来预测药物的总体满意度、有效性和副作用的情绪。他们爬行 Drugs.com 和 Druglib.com 来获取数据。在跨域 SA 中,使用 Drugs.com 数据,他们的准确率达到 70.06%,kappa 达到 26.76%。副作用结果的准确度为 49.75%,kappa 为 25.88%。
陈等人。30已使用 NB、DT、RF 和 Ripper 将药物评论的 SA 应用于正面、负面和中性标签。他们通过抓取 Druglib.com 的超文本标记语言 (HTML) 文件来收集数据。为了解决特征较多的问题,他们采用模糊粗特征选择来有效地减少数据。他们使用两种技术来确定术语的值:词袋 (BoW) 和术语频率-逆文档频率 (TF-IDF)。使用 BoW 方法获得了最佳结果。RF 模型的准确率为 66.41%,是最准确的模型,四个实现的 ML 模型的平均准确率为 63.85%。
希梅内斯-扎夫拉等人。32应用基于词典和监督学习的 SA 方法来告知患者的情绪,以达到医生和药物治疗的目的。他们从互联网论坛收集了西班牙语数据集。他们的结果表明,将药物意见与与医生相关的意见进行分类更具挑战性。刘等人。39提出了一种使用位置嵌入进行药物评论 SA 的新特征提取方法。他们使用各种机器学习模型实现了不同的特征提取技术来对情感进行分类,并得出结论认为他们提出的方法具有优越的性能。
科隆-鲁伊斯等人。8使用患者的药物评论来预测服用每种药物的感受。为此,他们开发了 CNN 进行分类。他们的结果表明,精度、召回率和 F1-Score 值优于 SVM 等经典分类方法。张等人。35提供了药物不良反应的数据集,并提出了一种新的深度学习架构用于识别。他们的结果表明,他们提出的模型在检测药物不良反应方面的性能略好于其他模型。
巴西里等人。6提出了两种不同的方法,使用 ML 和 DL 的传统技术来区分患者药物评论中的情绪。他们将自己提出的最佳方法与传统模型和深度学习模型进行了比较。根据他们报告的结果,他们将准确性和 F1-Measure 提高了 4%。
贾恩等人。29开发了 DL 模型,包括 CNN、GRU、多实例学习 (MIL) 和 CNN-GRU,以识别来自不同数据集(包括药物评论数据集)的欺骗性评论和情绪。他们使用了两种 MIL 和分层架构方法,并声称与之前开发传统 ML 模型的研究相比,他们使用 DL 模型取得了更好的结果。在药物评论数据集的SA中,CNN获得的值为76.8%、0.77和0.77,GRU获得的值为76.3%、0.76和0.76,MIL获得的值为78.2%、0.78和0.78,CNN-GRU 获得的值为 83.8%、0.84 和 0.83分别是准确率、精确率和召回率。
韩等人。37使用两个 Bi-GRU 神经网络和注意力机制来生成药物评论的双向语义表示。他们表示,与其他现代架构相比,他们提出的方法可以提高对药物审查情绪进行分类的性能。
我们的文献综述表明,之前的研究专门使用 ML 和 DL 模型来预测患者在药物评论中的情绪。然而,之前的研究没有考虑AI模型的可解释性和可解释性问题,并且没有考虑临床领域不同的预训练词嵌入用于药物评论的SA6,8,28,29,30,31,32,33,34,35,36,37,38,39。此外,ENS 学习模型尚未在其中任何一个中使用。
尽管如此,之前的研究已将SA广泛应用于非医疗领域,表明其在购物、旅游和社交网络中的应用14,15,16,17 号,18,19,20,40。近年来,社交网络中医药相关信息的SA应用也被考虑21,22,23,24,25,26,27。此外,之前关于药物 SA 的研究尝试提供经典的 ML 和 DL 方法来预测药物评论情绪6,8,28,29,30,31,32,33,34,35,36,37,38,39。例如,最近的系统评价已证实,SA 是应对 COVID-19 大流行等意外事件的一种很有前景的工具,可用于告知公众对该疾病及其疫苗接种的看法40,41。
根据最近的系统评价6,8,28,29,30,31,32,33,34,35,36,37,38,39,42,43通过我们的文献回顾,我们发现了 SA 药物领域现有的差距。首先,互联网上有关药物的共享评论可以成为 SA 的有益来源,可以帮助临床医生深入了解患者的病情以及副作用42。其次,为临床领域的药物评论SA创建一个特殊且全面的情感词典,这一点得到了临床医生和药剂师的认可,但在之前的研究中尚未得到解决6,8,12,28,29,30,31,32,33,34,35,36,37,38,39,43。第三,尽管 drug.com 是一个丰富的 SA 分析数据集,但还没有使用该数据集的综合研究6,8,28,29,30,31,32,33,34,35,36,37,38,39,42。第四,一些研究使用了元启发式、优化和模糊方法19,30,但在特征选择过程和寻找模型最优超参数时没有考虑新开发和改进的元启发式和优化算法44,45,46。第五,没有研究在药物评论中使用临床领域的各种预先训练的词嵌入来进行 SA。最后,没有研究考虑可解释的人工智能技术来预测药物评论数据集中的 SA6,8,28,29,30,31,32,33,34,35,36,37,38,39,42,43。
因此,为了解决这些差距,本研究提出了DL_ENS模型来综合预测患者在药物评论中的情绪分析28与不同的场景。此外,临床领域中不同的预训练词嵌入被集成到所提出的模型中,以克服药物 SA 挑战缺乏特定词典的问题。此外,使用可解释的人工智能方法来提高我们提出的最佳模型(DL_ENS)的透明度和可解释性。解决这个问题可以帮助临床医生了解决策过程并增加他们对结果的信任。
材料与方法
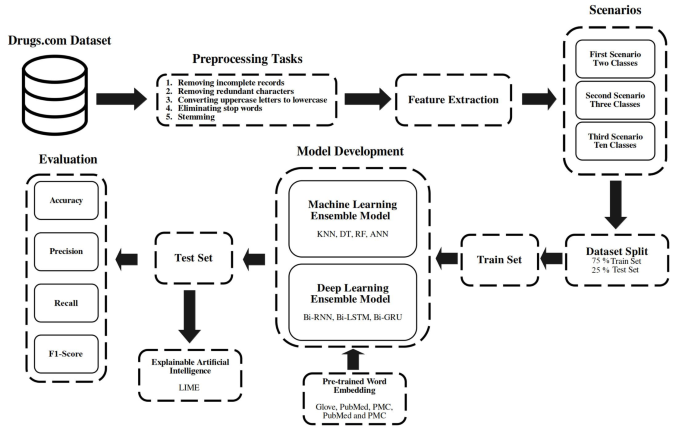
本研究的数据集摘自drugs.com28,可在 UCI 机器学习“药物评论数据集 (Drugs.com)”存储库中公开获取。药物评论数据集包含 215,063 名患者对其所用药物的看法(文本),以及患者已注册的从 1 到 10 的分数(数字)以及药物状况(文本)28。本研究的方法图如图所示。 1。

说明本研究中执行的步骤的工作流程图。
数据预处理
在本研究中,NumPy 和 NLTK 库用于对药物评论文本执行预处理任务。该阶段有五个步骤:(1)删除所有不完整的记录,(2)从所有文本中删除多余的标点符号和字符,(3)将数据集中所有实例中的大写字母转换为小写字母,(4)删除停用词,因为它们经常出现在文本中,并且没有为我们提供性能方面的有用信息,以及(5)使用 Snowball Stemmer 删除数据集中单词的后缀并找到它们的根源。经过充分预处理后,剩下213,869个样本。
从文本中提取特征
预处理阶段之后,创建了干净且一致的数据集。ML 和 DL 模型无法直接处理文本。因此,文本应该转换为数字向量。本研究利用 BoW 和词嵌入技术从文本中提取特征。BoW 是一种计算单词重复次数的简单方法,也是一种将文本转换为向量以用于分类模型的易于使用的技术47。
词嵌入是一种使用数字向量表示任何单词的新方法,使得向量中的每个数字代表单词的一个潜在特征,并且向量代表单词的不同潜在特征48。Word2Vec 是一种基于神经网络的词嵌入技术。该方法包括三层:输入层、隐藏层和输出层。Word2Vec方法由两种结构组成,Skip-Gram (SG) 和 Continuous BoW (CBOW)48。此外,本研究还考虑了预训练的词嵌入,包括一般领域中的 Glove 以及临床领域中的 PubMed、PMC 以及 PubMed 和 PMC 组合49,50。
研究设计
本研究实施了三种场景。在第一个场景中,药物评论数据集的分数分为两类:阴性(分数小于或等于 5)和阳性(分数大于 5)。在第二种情况下,分数分为三类:负面(分数小于 5)、中性(分数 5 和 6)和正面(分数大于 6)。最终,在第三种情况下,每次药物审查的本研究的数据集分数被考虑为从 1 到 10。
数据集分割
本研究使用 Hold-Out 交叉验证来分割患者的药物审查数据集51。根据该方法,数据集被随机分为两个训练集和测试集,因此75%的数据集被认为用于训练(160,093个样本),25%用于测试(53,776个样本)。
预测模型
不同理论背景的ML、DL、ENS的九种常见模型,包括KNN、DT、RF、人工神经网络(ANN)、双向循环神经网络(Bi-RNN)、双向长短期记忆(Bi-LSTM)、Bi-GRU、机器 ENS 学习 (ML_ENS) 和 DL_ENS52,53,54,55,56,57,旨在预测患者的情绪和评分。本研究中提出的所有 ML 算法均在附录 A 中详细描述。
深度学习算法在学习过程中依赖于激活函数和损失函数。通过利用这些函数并更新权重,模型被训练来进行预测。修正线性单元(ReLU)是一种激活函数,用于神经网络中,向神经网络引入非线性特性,帮助神经网络学习复杂的模式并更准确地进行预测55。该函数将输入的负值设置为零,同时保持正值不变55。ReLU激活函数的数学方程如下:
$$\:f\left(x\right)={max}\left(0,x\right)$$
(1)
在哪里\(\:x\)代表输入值。
Sigmoid 是神经网络中的一种激活函数,它接受任何输入并将其转换为 0 到 1 范围内的输出值55。sigmoid函数常用于二元分类任务55。以下等式显示了 sigmoid 激活函数的工作原理:
$$\:\sigma\:\left(x\right)=\frac{1}{1+{e}^{-x}}$$
(2)
在哪里\(\:\西格玛\:\)代表 sigmoid 函数,并且\(\:e\)代表欧拉数。
Softmax 是一种将数字或逻辑转换为概率的激活函数。Softmax 的输出是可能结果的概率向量55。它用于标准化神经网络的输出。与 sigmoid 激活函数不同,它通常用于多元分类任务55。以下等式显示了 softmax 激活函数的工作原理:
$$\:S{\left(\overrightarrow{z}\right)}_{i}=\frac{{e}^{{z}_{i}}}{{\sum\:}_{j=1}^{K}{e}^{{z}_{j}}}$$
(3)
在哪里\(\:S\)是softmax,\(\:\overrightarrow{z}\)投入输入向量,\(\:{e}^{{z}_{i}}\)输入向量的标准指数函数,\(\:K\)显示多变量分类中的类数,以及\(\:{e}^{{z}_{j}}\)表示输出向量的标准指数函数。
损失函数是计算用于评估模型在数据集建模中的性能的函数55。换句话说,它衡量预测目标值和实际目标值之间的差异55。以下等式表示如何计算二进制对数损失:
$$\:二元对数损失\:=\:-\frac{1}{N}{\varSigma\:}_{i=1}^{N}{y}_{i}log{\widehat{y}}_{i}+\left(1-{y}_{i}\right){log}\left(1-{\widehat{y}}_{i}\right)$$
(4)
在哪里\(\:{y}_{i}\)显示实际值,并且\(\:{\widehat{y}}_{i}\)显示模型预测。
用于多变量分类的另一个损失函数是分类交叉熵损失55,计算如下:
$$\:分类交叉熵损失=\:-{\sum\:}_{j=1}^{K}{y}_{j}{log}\left({\widehat{y}}_{j}\右)$$
(5)
在哪里\(\:{y}_{i}\)显示实际值,并且\(\:{\widehat{y}}_{i}\:\)显示模型预测55。
RNN 是 ANN 的一种,用于文本、语音和顺序数据处理54,55。与前馈网络不同,RNN 有一个反馈层,网络的输出和下一个输入被反馈到网络55。RNN 具有内部存储器,因此它们可以记住之前的输入并使用其存储器来处理顺序输入。长短期记忆 (LSTM) 和 GRU 属于 RNN 算法,其中前一层的输出用作后续层的输入54。LSTM 和 GRU 在其架构中解决了 RNN 中出现的梯度消失问题54,55。Bi-RNN、Bi-LSTM 和 Bi-GRU 算法具有双向架构55。这三种算法以渐进和回归的方式在两个方向(向前和向后)移动和学习55。
Bi-RNN 的输出为:
$$\:p\left(\left.{y}_{t}\right|{\left\{{x}_{d}\right\}}_{d\ne\:t}\right)=\varphi\:\left({W}_{y}^{f}{h}_{t}^{f}+{W}_{y}^{b}{h}_{t}^{b}+{b}_{y}\右)$$
(6)
在哪里
$$\:{h}_{t}^{f}=\:tanh\:({W}_{h}^{f}{h}_{t-1}^{f}+\:{W}_{x}^{f}{x}_{t}+\:{b}_{h}^{f})$$
(7)
$$\:{h}_{t}^{b}=\:tanh\:\left({W}_{h}^{b}{h}_{t-1}^{b}+\:{W}_{x}^{b}{x}_{t}+\:{b}_{h}^{b}\右)$$
(8)
那\(\:{x}_{t}\)表示当时的输入向量\(\:t\),\(\:{y}_{t}\)是当时的输出向量\(\:t\),\(\:\:{h}_{t}\)是当时的隐藏层\(\:t\),\(\:f\)意味着前进,\(\:b\)意味着向后,并且\(\:{W}_{y}\),\(\:{W}_{h}\), 和\(\:{W}_{x}\)分别表示连接隐藏层到输出层、隐藏层到隐藏层以及输入层到隐藏层的权重矩阵。\(\:{经过}\)和\(\:{b}_{h}\)分别是输出层和隐藏层的偏置向量55。
下面解释Bi-LSTM的计算过程:
$$\:{f}_{t}=\sigma\:({W}_{f}\left[{h}_{t-1},{x}_{t}\right]+{b}_{f}$$
(9)
$$\:{i}_{t}=\sigma\:({W}_{i}\left[{h}_{t-1},{x}_{t}\right]+{b}_{i}$$
。
$$\:{\stackrel{\sim}{C}}_{t}=tanh\:({W}_{c}\left[{h}_{t-1},{x}_{t}\右]+{b}_{c}$$
(11)
$$\:{C}_{t}=\:{f}_{t}{C}_{t-1}+\:{i}_{t}{\stackrel{\sim}{C}}_{t}$$
(12)
$$\:{o}_{t}=\sigma\:({W}_{o}\left[{h}_{t-1},{x}_{t}\right]+{b}_{o}$$
(13)
$$\:{h}_{t}=\:{o}_{t}\:{tan}h\left({C}_{t}\right)$$
(14)
方程(9—14)分别是遗忘门、输入门、单元当前状态、存储单元状态值、输出门和隐藏门的方程。这\(\:b\)和\(\:W\)表示偏置向量和权重系数矩阵55。\(\:\西格玛\:\)显示 sigmoid 激活函数55。\(\:\:{x}_{t}\)表示当时的输入向量\(\:t\)和\(\:{h}_{t}\)是当时的隐藏层\(\:t\)55。Bi-LSTM 的输出为:
$$\:{y}_{t}=g({V}_{{h}^{f}}{h}_{t}^{f}+\:{V}_{{h}^{b}}{h}_{t}^{b\:}+\:{b}_{y})\:$$
(15)
在哪里
$$\:{h}_{t}^{f}=g({U}_{{h}^{f}}{x}_{t}+{W}_{{h}^{f}}{h}_{t-1}^{f}+{b}_{h}^{f})$$
(16)
$$\:{h}_{t}^{b}=g({U}_{{h}^{b}}{x}_{t}+{W}_{{h}^{b}}{h}_{t-1}^{b}+{b}_{h}^{b})$$
(17)
那\(\:{y}_{t}\)是当时的输出向量\(\:t\),\(\:\:f\)意味着前进,\(\:b\)意味着向后,并且\(\:V\),\(\:W\), 和\(\:U\)分别表示连接隐藏层到输出层、隐藏层到隐藏层、输入层到隐藏层的权重矩阵54。
Bi-GRU的计算过程为:
$$\:{z}_{t}=\sigma\:{(W}_{xz}{x}_{t}+{W}_{hz}{h}_{t-1}+{b}_{z})$$
(18)
$$\:{r}_{t}=\sigma\:{(W}_{xx}{x}_{t}+{W}_{hr}{h}_{t-1}+{b}_{r})$$
(19)
$$\:{\stackrel{\sim}{h}}_{t}=\:tanh\:{(W}_{xh}{x}_{t}+\:{r}_{t}^\circ\:\:{h}_{t-1}{W}_{hh}+\:{b}_{h}$$
(20)
$$\:{h}_{t}=\:(1\:-\:{z}_{t})^\circ\:\:{\stackrel{\sim}{h}}_{t}\:+\:{z}_{t}^\circ\:{h}_{t-1}$$
(21)
在哪里\(\:W\)是权重矩阵,\(\:{z}_{t}\)显示更新门,\(\:{r}_{t}\:\)代表复位门,\(\:{\stackrel{\sim}{h}}_{t}\)显示重置内存,以及\(\:{h}_{t}\)显示新的记忆。\(\:{x}_{t}\)表示当时的输入向量\(\:t\), 和\(\:b\)是偏置向量55。Bi-GRU 的输出为:
$$\:{h}_{t}=\:{W}_{{h}_{t}^{f}}{h}_{t}^{f}+\:{W}_{{h}_{t}^{b}}{h}_{t}^{b}+\:{b}_{t}$$
(22)
在哪里
$$\:{h}_{t}^{f}=GRU({x}_{t},\:{h}_{t-1}^{f})$$
(23)
$$\:{h}_{t}^{b}=GRU({x}_{t},\:{h}_{t-1}^{b})$$
(24)
那\(\:格鲁乌\)是传统的GRU计算过程,\(\:f\)和\(\:b\)分别表示向前和向后,并且\(\:{b}_{t}\)是当时的偏置向量\(\:t\)。
假如\(\:h\)等于等式(6) 对于 Bi-RNN,方程 (15) 对于 Bi-LSTM,方程 (22)对于Bi-GRU,参数为:这些模型单元的数量为\(\:150\),第一个全连接层的单元数量为\(\:n=128\),第二个全连接层的单元数量为\(\:z\),给定单个时间步输入:
$$\:{o}_{1}=ReLU\left({W}_{1}h+{b}_{1}\right)$$
(25)
$$\:{o}_{2}=\:{f}_{i}\left({W}_{2}{o}_{1}+{b}_{2}\right)$$
(26)
其中等式(25,26) 分别是具有 ReLU 激活的第一个全连接层和第二个全连接层的方程。\(\:{f}_{i}\)可以是 sigmoid 方程(2)对于第一种方法,它可以是 softmax,如方程(3)对于第二种和第三种方法。这\(\:{b}_{1}\)和\(\:{b}_{2}\)表示偏置向量并且\(\:{W}_{1}\)和\(\:{W}_{2}\)表示权重系数矩阵。
通过了解\(\:t=1\), 和\(\:{f}_{i}\)是 sigmoid,我们提出了这些算法:
$$\:Bi-RNN=\:Sigmoid\left({W}_{2}\left(ReLU\left({W}_{1}\left(\varphi\:\left({W}_{y}^{f}{h}_{t}^{f}+{W}_{y}^{b}{h}_{t}^{b}+{b}_{y}\右)\右)+{b}_{1}\右)\右)+{b}_{2}\右)$$
(27)
$$\:Bi-LSTM=\:Sigmoid\left({W}_{2}\left(ReLU\left({W}_{1}\left(g\right({V}_{{h})^{f}}{h}_{t}^{f}+\:{V}_{{h}^{b}}{h}_{t}^{b\:}+\:{b}_{y}\左)\右)+{b}_{1}\右)\右)+{b}_{2}\右)$$
(28)
$$\:Bi-GRU=\:Sigmoid\left({W}_{2}\left(ReLU\left({W}_{1}({W}_{{h}_{t}^{f}}{h}_{t}^{f}+\:{W}_{{h}_{t}^{b}}{h}_{t}^{b}+\:{b}_{t})+{b}_{1}\右)\右)+{b}_{2}\右)$$
(29)
另外,如果\(\:t=1\), 和\(\:{f}_{i}\)是softmax,我们提出了这些算法:
$$\:Bi-RNN=\:Softmax\left({W}_{2}\left(ReLU\left({W}_{1}\left(\varphi\:\left({W}_{y}^{f}{h}_{t}^{f}+{W}_{y}^{b}{h}_{t}^{b}+{b}_{y}\右)\右)+{b}_{1}\右)\右)+{b}_{2}\右)$$
(30)
$$\:Bi-LSTM=\:Softmax\left({W}_{2}\left(ReLU\left({W}_{1}\left(g\right({V}_{{h})^{f}}{h}_{t}^{f}+\:{V}_{{h}^{b}}{h}_{t}^{b\:}+\:{b}_{y}\左)\右)+{b}_{1}\右)\右)+{b}_{2}\右)$$
(31)
$$\:Bi-GRU=\:Softmax\left({W}_{2}\left(ReLU\left({W}_{1}({W}_{{h}_{t}^{f}}{h}_{t}^{f}+\:{W}_{{h}_{t}^{b}}{h}_{t}^{b}+\:{b}_{t})+{b}_{1}\右)\右)+{b}_{2}\右)$$
(32)
ENS 学习是一种人工智能技术,旨在提高模型估计数据输出的能力,它结合使用多个模型并同时做出决策56。ENS学习方法之一是投票法,根据模型的投票做出决策,包括硬投票和软投票两种方法52。在硬投票中,目标的选择基于模型对输出的最大投票数56。在软投票中,目标选择基于模型对输出的最高联合概率52,56。本文采用硬投票方法开发了ML_ENS和DL_ENS两种ENS模型。硬投票的方程表示如下:
$$\:\sum\:_{t=1}^{T}{d}_{t,J}=ma{x}_{j=1}^{C}\sum\:_{t=1}^{T}{d}_{t,j}$$
(33)
在哪里\(\:t=\:\{KNN,DT,\:RF,\:ANN\}\)在 ML_ENS 模型中和\(\:t=\{Bi-RNN,\:Bi-LSTM,\:\:Bi-GRU\}\)在DL_ENS模型中,\(\:\:j=\{负数,\:正数\}\)在第一个场景中,\(\:\:j=\{负数,\:\:中性\:,正数\}\)在第二种情况下,并且\(\:\:j=\{一、\:二、\:三、\:四、\:五、\:六、\:七、\:八、\:九、\:十\}\)在第三种情况下。\(\:T\)代表模型的数量,并且\(\:C\)代表类的数量。尽管如此,根据前面提到的句子,ML_ENS 和 DL_ENS 模型的数学形式通过对所有提出的算法进行投票来确定每种方法中的目标类别。
在本研究中,使用Sklearn和TensorFlow库来实现。应用网格搜索来查找超参数的最佳值。此方法搜索并评估指定超参数及其值的网格,并确定每个模型的最佳超参数值57。最佳选择模型的最佳选择的超参数显示在表格中 2。一旦为每个模型确定了最佳的超参数,选择这些调整模型以创建ML_ENS和DL_ENS模型。然后,ENS方法结合了这些优化模型的预测。这些调整模型的汇总投票确定了每个ENS模型的最终预测。该过程确保了合奏模型从每个单独优化模型的优势中受益,以提高整体预测性能。此外,考虑加权损失功能可以解决阶级失衡,并确保模型在训练过程中更加关注少数群体。具体而言,根据数据集中的频率分配了一个权重,以便在优化过程中使代表性不足的类更为重要。这种方法有助于减轻类不平衡对模型性能的负面影响。我们通过GPU NVIDIA GTX 1650在具有32 GB RAM,Intel E5-2650 CPU和4 GB内存的服务器上开发了算法。
评估模型
考虑以下评估标准来评估所提出模型的性能58:
$$ \:准确= \:\ frac {tp+tn} {tp+fp+fp+fn+tn} $$
(34)
$$ \:precision = \:\ frac {tp} {tp+fp} $$
(35)
$$ \:回忆= \:\ frac {tp} {tp+fn} $$
(36)
$$ \:f1-core = \:\ frac {2 \:\ times \:precision \:precision \:\ times \:request} {precision+resse+回忆} $$
(37)
TP,TN,FP和FN是真正的积极,真为负,假积极和假阴性。这些是混乱矩阵的组成部分59。此外,使用曲线下的面积(AUC)度量来估计最佳模型的性能,因为它通常比精度度量标准更好地评估性能的评估60。
石灰是AI黑匣子模型的一种可解释和可解释的方法59,61。石灰是一种简单但有力的解释和解释模型决策过程的方法59,61。该方法考虑了最有影响力的特征,以解释模型的预测方式。石灰通过在类周围的输入中形成干扰来局部近似预测,以便在达到线性近似时,它可以解释并证明模型的行为和性能合理61。
结果
SA是自然语言处理应用的重要组成部分。吸引研究人员注意力的一个领域是使用SA来评估药物及其对患者的影响。当前的研究使用药物审查数据集根据拟议方案中对药物的反应来预测患者的观点和率评分。为此,开发了四个ML模型,三个DL模型和两个具有硬投票方法的ENS模型。
患者的药物评论数据库已进行了预处理,以实现最佳性能。因此,除去冗余样品,并尽可能避免其对模型性能的负面影响和偏差。在预处理结束时,213,869名患者评论仍然是本研究的主要数据集。图 2在此数据集中显示了最常见的患者状况,其中有两千多个样本。根据图 2,节育,抑郁,疼痛,焦虑和痤疮是最常见的五个条件。另外,图 3在此数据集中显示每个分数的份额。根据图 310、9、1、8和7的分数在此数据集中拥有最大的份额。

数据集中最常见的患者状况。

图表显示数据集中每个分数的分布。
根据表 3,这项研究考虑了预测情感类别和费率分数的不同情况。这些不同情况的原因是每个班级的样本数量不平衡。尤其是在第二种情况下,中性类的样本数量比其他类别少。因此,第三种情况是使用十个类创建的,以提高性能。
根据实验,我们在值(10,000 25,000)中选择了ML模型的弓矢量大小为20,000。同样,从Python中的Gensim库中的CBOW方法是通过值(1,000 25,000)中DL模型的15,000个单词数量大小的维度选择的。完成预处理并选择最佳的超参数后,我们提出的模型被执行并测试。然后,根据评估标准对模型进行评估(eqs。(3437))在教派中考虑。评估模型。
如前所述,根据三种情况预测了患者的观点。计算所有模型的准确性,精度,召回和F1得分。表 4在第一个方案(两个类)中显示了所有提出的模型的结果。从传统的ML和DL模型中,RF和Bi-Gru分别具有最佳性能。此外,DL_ENS模型的表现优于本研究中提出的所有ML,DL和ENS模型。
在表格中显示了第二种情况下所有模型的结果(三个类) 5。如图所示,RF模型在ML模型中具有最佳性能。在拟议的DL模型中,BI-GRU模型具有更好的性能。DL_ENS模型在所有提出的模型中也取得了最高的成就。本研究中提出的模型的结果在第三种情况(十个类)中显示在表中 6。RF模型的性能比其他ML模型更好。在拟议的DL模型中,BI-GRU模型具有最佳性能。最后,最佳建议的模型(DL_ENS)显示出比所有ML,DL和ML_ENS模型更好的结果。
根据表 4,5和6在所有情况下,DL_ENS模型的结果清楚地表明,该模型(DL_ENS)的表现优于其他实现的模型。因此,使用一般和临床预训练的单词嵌入使用了DL_ENS模型并测试进行进一步研究。这些实验的第一个,第二和第三种情况的结果在表中呈现 7,8和9。值得注意的是,临床预训练的单词嵌入(合并的PubMed和PMC)在拟议的最佳模型中具有较高的性能,并且能够提高其准确性和F1分数值。同样,临床预训练的单词嵌入对模型性能的积极影响比通用训练的单词嵌入更大。此外,本研究最佳模型的计算时间在表中显示 10。此外,将提出的最佳模型与以前的研究进行了比较6,8,28,29,30在同一数据集上,比较在表中给出 11。该表显示DL_ENS优于其他先前报道的模型6,8,28,29,30。
数字 4和5分别显示提出的DL_ENS模型的所有场景的AUC图和混淆矩阵。如图所示。 6,7和8,和图。附录A中的S1-S6,随机选择了来自测试数据集的三个评论,以解释所有情况下最佳模型的决策。因此,这项研究利用了石灰,解释了这些随机药物评论的决定。

AUC图说明了最佳模型的性能。

混淆矩阵说明了最佳模型的分类性能。

解释第一种情况下最好的模型做出的决策。

在第二种情况下由最佳模型做出的决定的解释。

解释第三种情况下最好的模型做出的决策。
讨论
在这项研究中,提出了三种不同的情况,以预测患者有关药物的SA。第一种和第二种情况是预测SA的最常见模式,如大多数研究中所用6,8,28,29,30。在第一种情况下,分数少于5被归类为负数,而得分5及以上被归类为正面。在第二种情况下,分数小于5被归类为负,分数为5和6为中性,而得分高于6。为了更准确地确定患者对药物的情绪,第三种情况认为十个类别,根据每种药物记录的患者的记录,得分范围为1至10个。
比较表中最佳拟议模型的结果 4,5和6用桌子 7,8和9,在第一种情况下,精度值增加了1.57%,F1得分的值增加了1.58%。同样,在第二种情况下,精度值增加了1.23%,F1得分值增加了1.15%。最后,在第三种情况下,精度值增加了0.36%,F1得分值增加了0.83%。在本研究的所有情况下,具有预训练的单词嵌入(PubMed和PMC的组合)的最佳拟议模型获得了最佳结果。
根据表 10,最佳模型的计算时间(带有PubMed和PMC预训练的单词嵌入)与其他单词嵌入的计算时间相当。重要的是要注意,不同模型配置的计算成本可能会有所不同,这对于评估现实世界应用中模型的实用性至关重要。尽管PubMed和PMC组合的性能最高,但其计算时间比其他单词嵌入时间略长。例如,PubMed和PMC嵌入的第三种情况的运行时间为18,952.50,而Word2Vec和Glove的运行时间分别需要18,055.00和18,495.00。在评估模型准确性和计算效率之间的权衡时,应考虑这些时间差异,尤其是在资源受限的环境中。
基于62,图中提供的结果。 4和5在第一个和第二个方案中表明出色的性能,并在第三种情况下使用预训练的PubMed和PMC Word嵌入模型在第三种情况下可接受性能。
药物SA可以洞悉药物和治疗过程的有效性。但是,检测和预测患者对药物的情感非常复杂32,但是这样做,我们可以确定有关药物,它们的不可靠性及其有效性的看法;因此,它可以用于临床决策12。
透明度是在临床实践中开发AI模型的主要问题之一,大多数AI模型被认为是黑匣子,在该黑匣子中,决策的逻辑不容易理解和遵循,尤其是对于临床医生而言。61。为了解决这个问题,我们使用了专门设计的石灰技术来解释复杂的机器学习模型,这是通过围绕每个预测的本地近似其决策过程来解释复杂的。石灰通过扰动输入数据(药物评论中的单词)来起作用,并观察这些扰动如何影响模型的预测。这种方法使我们能够识别每个预测最有影响力的特征(单词)。
如图所示。 6,7和8和无花果。附录A中的S1-S6应用石灰来解释表现最佳模型做出的预测。对于每个实例,Lime生成了一个局部替代模型,该模型近似于特定预测附近的黑框模型的决策边界。通过计算每个单词对情感分类和费率评分的重要性,我们可以确定对模型输出产生最大影响的单词。对模型决策的分步解释有助于揭示情感预测背后的理由,从而使它们更加透明。
石灰的输出突出显示了最有影响力的词,并根据这些单词的加权概率的总和为每个类别提供了置信度得分。这种透明度水平使临床医生能够更好地了解模型预测背后的推理,从而增加了在临床工作流中采用AI驱动工具的可信度和潜力。通过对如何进行情感分析的明确解释,临床医生可以更自信地使用这些模型,最终有助于更明智的患者护理决策。
这项研究旨在通过专注于患者药物评论的SA来扩展以前的工作,该评论提出了需要专业模型的独特挑战32。与以前的研究中提出的模型相比6,8,15,16,17 号,18,19,24,25,28,29,30,31,32,35,37,39,无论是用于非药物和药物评论的数据集,以及表所示 11,DL_ENS模型的性能优于传统的DL和ML模型。ENS学习可以减轻错误,减少过度拟合,并通过利用不同模型的优势来提高准确性和鲁棒性63,64。此外,按照研究的建议,通过捕获大型数据集的语义和句法含义,预先训练的单词嵌入增强了模型性能和普遍性65。
在先前的研究中没有ENS模型和使用预训练的单词嵌入6,8,15,16,17 号,18,19,24,25,28,29,30,31,32,35,37,39以及在本研究的其他建议模型中,与最佳建议模型相比,性能较低。在这项研究中,DL_ENS模型与预训练的单词嵌入(来自PubMed和PMC)相结合,利用了DL模型,ENS学习和预训练的单词嵌入的优势,在所有情况下都显示出有希望的结果。
与以前的研究相比,这项研究的一些原因导致了这项研究的改进:(1)对数据集进行了全面的预处理,以防止模型预测中的错误和偏见;(2)部署了一种系统的方法来找到最佳的超参数;(3)SA中推荐的DL_ENS模型63与临床领域中的预训练单词嵌入一起使用。因此,在这项研究中,由于它们与临床结构较强的相关性,因此选择了PubMed和PMC作为预训练的单词嵌入。这些嵌入在广泛的生物医学语料库中进行了培训,使它们可以捕获医疗术语和医疗保健特定的语言模式。此选择增强了模型在药物评论中理解和处理情感的能力,从而确保了医疗保健环境中更准确和上下文相关的预测。
这些模型的开发,例如拟议的DL_ENS模型,可以作为健康和药物系统中临床医生和患者的辅助工具,以预测用过的药物的情绪。最初,我们根据患者情绪数据集开发了几种模型,该模型来自Drugs.com网站,该网站适用于美国的患者。本研究中提出的最佳模型也可以在其他国家 /地区的数据集上进行测试和重新训练,以提高其有效性。该模型可以与用于注册和管理患者药物的软件系统一起作为插入工具集成。分析收集的情感可以帮助临床医生开处方更合适的药物,具有更少的副作用。这种整合意味着患者和临床医生不需要详细了解该模型,因为它可以无缝地纳入其常规软件应用程序中。此外,这项研究的发现和详细实施可以指导AI医学应用专家的更先进和全面的模型的开发。最后,在临床环境中集成DL_ENS模型会提出重要的道德考虑,尤其是在使用患者生成的数据进行模型培训和部署方面。重要的是要注意,本研究中使用的数据集不包含患者信息,因为所有记录都已匿名化以确保隐私和机密性。患者同意和透明度是这种方法的基本原则,因为该分析中没有可识别的数据。此外,由于该模型已整合到临床决策中,因此至关重要的是要摆脱可能影响治疗结果的偏见,尤其是对于代表性不足的患者群体而言。为了解决任何道德问题,必须连续监测模型的现实世界绩效,以确保它为患者的最大利益提供服务。
但是,我们的研究有一些局限性。首先,在本研究中提出的所有情况下,由于数据集的不同类别的评论数量不平衡,因此考虑类别的实例的数量并不相同。其次,由于资源有限,我们无法开发更多的模型。此外,没有其他类似于使用的数据集(具有大量样本)来验证开发模型的普遍性。最后,DL_ENS模型有其自身的局限性,例如更高的计算成本和实时部署的潜在挑战,这可能会影响其在临床环境中的实际应用。这些因素可能需要进一步优化,以平衡医疗环境中实际使用的效率。
结论
在这项研究中,提出的DL_ENS模型是PubMed和PMC预先训练的单词嵌入在所有实施场景中的最佳结果,获得了最佳结果。此外,我们的发现表明,临床领域中的预训练的单词嵌入对模型的性能而不是通用域中的预训练的单词嵌入。此外,我们开发的模型的性能比以前在Drugs.com数据集的SA研究更好。我们的研究还通过利用石灰技术来考虑结果的解释性和解释性。该技术可以帮助临床医生看到决策背后的逻辑并增加对结果的信任。结果,该技术还可以增加使用我们最佳模型作为实际实践中的临床决策支持系统的机会。
这项研究的技术可以提高透明度并促进我们的DL_ENS模型作为临床决策支持工具的整合,可以将其作为现有医疗保健系统的插件添加。这种整合将使临床医生能够利用患者评论中的情感见解来帮助选择药物选择,治疗计划和患者咨询。该模型可以通过为患者满意度和副作用提供可行的见解,最终改善患者的结果,从而有助于更具个性化和有效的护理策略。
将来,我们计划开发更多的模型,以提高SA在预测患者情感方面的准确性。此外,我们打算通过整合文本和语音数据进行情感分析,测试此类模型在临床实践中的性能,以探索多模式的方法。通过结合不同形式的沟通,可以增强模型的鲁棒性和适用性,可以在现实世界中的医疗环境中提高对患者情感的更全面的了解。
数据可用性
在当前研究中分析的数据集可在https://archive.ics.uci.edu/dataset/462的“药物评论数据集(Drugs.com)”中公开获得。
参考
Cambria,E.,Wang,H。&White,B。嘉宾社论:大型社交数据分析。知识。基于系统。 69,1 2(2014)。
Budennyy,S.,Kazakov,A.,Kovtun,E。&Zhukov,L。新药和股市:用于预测药物市场对临床试验公告的反应的机器学习框架。科学。代表。 13,12817(2023)。
Grassi,M.,Cambria,E.,Hussain,A。&Piazza,F。Sentic Web:一种用于管理社交媒体情感信息的新范式。认知计算。 3,480 A489(2011)。
Chintalapudi,N.,Battineni,G.,Canio,M。D.,Sagaro,G。G.&Amenta,F。有关Seafarers医疗文件的情感分析的文本挖掘。国际。J. 通知。管理。数据洞察。1,100005(2021)。谷歌学术
一个 Blanco,A.,Casillas,A.,Pã©Rez,A。&De Diaz,A。多标签临床文档分类:标签密度的影响。
专家系统。应用。 138,112835(2019)。
Basiri,M。E.,Abdar,M.,Cifci,M。A.,Nemati,S。&Acharya,U。R.使用深层和机器学习技术的融合来对药物评论进行情感分类的新方法。知识。基于系统。 198,105949(2020)。
Hiremath,B。N.和Patil,M。M.使用自然语言处理增强临床决策支持系统中优化的个性化治疗。j国王沙特大学。 - 计算科学。34,2840 2848(2022)。谷歌学术
一个 Colã³n-Ruiz,C.,Segura-Bedmar,I。&Martãnez,P。anâlisisde Sentimiento en el Dominio Salud:Analizando comentarios sobrefãrmacos。
Procesamiento del。Lenguaje Nat。 63,15 22(2019)。
谷歌学术一个
Sutphin,C.,Lee,K.,Yepes,A.J.,Uzuner,â。&McInnes,B。T.使用FDA药物标签中的理性分配的不良药物事件检测。J.生物医学。信息。 110,103552(2020)。
Snyder,C。F.等。信息学在促进以患者为中心的护理中的作用。癌症 J。 17 号,211 218(2011)。
刘,Z.等人。通过复发神经网络从临床文本中识别实体识别。BMC 医学。信息。决定。麦 17 号,(2017)。
Denecke,K。&Deng,Y。医疗环境中的情感分析:新的机会和挑战。阿蒂夫。英特尔。医学。 64,17â27(2015)。
坎布里亚(E.IEEE 英特尔。系统。 32,74 -80(2017)。
陈,J.等人。一个分类的特征表示三向决策模型,用于情感分析。应用。英特尔。 52,7995 - 8007(2022)。
Wu,D.C.,Zhong,S.,Qiu,R。T. R.&Wu,J。客户评论只是评论吗?使用情感分析的酒店预测。旅游经济。 28,795â816(2022)。
Sarsam,S.M.,Al-Samarraie,H.,Alzahrani,A.I.,Alnumay,W。&Smith A.P.一种基于词典的方法,用于在Twitter上检测与自杀相关的消息。生物医学。信号。过程。控制。65,102355(2021)。文章
一个 谷歌学术一个 Gao,Z.,Li,Z.,Luo,J。&Li,X。基于CNN+Bigru的简短文本基于方面的情感分析。应用科学
12,(2022)。 Yu,W。,Cui,F。&Hou,Z。公共卫生危机中消费者对酒店的需求的发展:在线评论中挖掘的意见。电流。
发出旅游业。26,1974年(2023年)。文章一个
503,173 - 188(2022)。 文章一个
谷歌学术一个 Al-Smadi,M.,Hammad,M.M。,Al-Zboon,S.A.,Al-Tawalbeh,S。&Cambria,E。带有基于阿拉伯方面的情感分析的多语言通用句子编码器。知识。
基于系统。261 ,107540(2023)。文章
一个 谷歌学术一个 Singh,C.,Imam,T.,Wibowo,S。&Grandhi,S。一种深度学习方法,用于COVID-19评论的情感分析。应用。
科学。(巴塞尔)。12,3709(2022)。文章
一个 中科院一个 谷歌学术一个 Marcec,R。&Likic,R。使用Twitter对阿斯利康/牛津,辉瑞/Biontech和Moderna Covid-19疫苗进行情感分析。研究生。
医学。J。 98,544 -550(2022)。
Chinnasamy,P。等。COVID-19-twitter上使用公众意见分析疫苗情感分析。马特。今天。64,448 A451(2022)。中科院
一个 谷歌学术一个 Tang,J。E。等。患者如何在线审查脊柱外科医生?
医师评论网站的情感分析书面评论。全球脊柱 J. 13,2107 2114(2023)。
钱德拉(R.公共图书馆一号。16,E0255615(2021)。
祖尔菲克(M. S.阵列(n y)。15,100204(2022)。
Alam,K。N.等。来自Twitter数据的COVID-19疫苗接种反应的基于深度学习的情感分析。计算。数学。医学方法。4321131(2021)。(2021)。
GrâäEr,F.,Kallumadi,S.,Malberg,H。&Zaunseder,S。基于跨域和跨数据学习的药物评论的基于方面的情感分析。在国际数字健康会议论文集(ACM,纽约,纽约,美国,2018年)。(ACM,纽约,纽约,美国,2018年)。(2018)。
Jain,N.,Kumar,A.,Singh,S.,Singh,C。和Tripathi,S。使用深度学习技术的欺骗性评论。在自然语言处理和信息系统79 - 91Springer International Publishing,Cham,(2019年)。
陈,T.等人。使用模糊 - 沟通功能选择的药物评论的情感分类。在。IEEE国际模糊系统会议(Fuzz-ieee)(IEEE,2019年)。(2019)。
Ebrahimi,M.,Yazdavar,A。H.,Salim,N。&Eltyeb,S。在药物评论中识别副作用为隐式词。在线inf。牧师。 40,1018年1032(2016)。
Jimâ©Nez-Zafra,S.M.,Martãn-Valdivia,M.T。&Molina-Gonzãlez,M。D。Ureã±a-a-létapez,L。A.我们如何谈论医生和毒品?在论坛上表达对医疗领域意见的情感分析。阿蒂夫。英特尔。医学。 93,50 -57(2019)。
Youbi,F。&Settouti,N。对药物评论的意见挖掘的机器学习和深度学习框架的分析。计算。J。 65,2470 2483(2022)。
Ru,B.,Li,D.,Hu,Y。&Yao,L。Serendipity-A机器学习应用程序,用于从社交媒体中采矿偶然的药物使用。IEEE 传输。纳米菌。 18,324â334(2019)。
Zhang,M。&Geng,G。使用弱监督的卷积神经网络和复发性神经网络模型的不良药物事件检测。信息(巴塞尔)10,276(2019)。
Colã³n-Ruiz,C。&Segura-Bedmar,I。比较深度学习体系结构,以分析药物审查的情感分析。J.生物医学。信息。 110,103539(2020)。
Han,Y.,Liu,M。&Jing,W。基于双重BIGRU和知识转移的方面级药物评论分析。IEEE 访问。 8,21314 21325(2020)。
Hossain,M。D.,Azam,M。S.,Ali,M。J.&Sabit,H。使用机器学习对药物审查的情感分析的药物评级生成和建议。2020年,计算,通信和电子产品(ETCCE)的新兴技术(IEEE,(2020)。
Liu,S。&Lee,I。用医学情感词典提取特征和用于药物审查的位置编码。健康信息。科学。系统。 7,11(2019)。
Xu,Q。A.,Chang,V。&Jayne,C。基于社交媒体的情感分析的系统评价:新兴趋势和挑战。决定。分析J. 3,100073(2022)。
Cascini,F。等。社交媒体和对COVID-19疫苗接种的态度:对文献的系统评价。电子临床医学 48,101454(2022)。
Zunic,A.,Corcoran,P。&Spasic,I。健康与福祉的情感分析:系统评价。JMIR 医学。信息。 8,E16023(2020)。
Pilipiec,P.,Liwicki,M。&Bota,A。使用机器学习进行药物守护:系统评价。药剂学 14,266(2022)。
El-Kenawy,E。S。M.等。Greylag鹅优化:自然风格的优化算法。专家系统。应用。 238,122147(2024)。
El-Kenawy,E。S。M.等。足球优化算法(FBOA):一种受团队策略动力学启发的新颖元神经。J.阿蒂夫。英特尔。元启发法。8,21 38(2024)。文章
一个 谷歌学术一个 Abdollahzadeh,B。等。PUMA Optimizer(PO):一种新型的元启发式优化算法及其在机器学习中的应用。
集群计算。27 ,5235 - 5283(2024)。文章
一个 谷歌学术一个 Zhang,Y.,Jin,R。&Zhou,Z。H.理解词袋模型:一个统计框架。国际。
J.马赫.学习。塞伯恩。1,43 -52(2010)。文章
一个 谷歌学术一个 Serrano-Guerrero,J.,Bani-Doumi,M.,Romero,F。P.&Olivas,J。A.了解患者对医院的看法:一种用于检测患者意见情绪的深度学习方法。阿蒂夫。
英特尔。医学。 128,102298(2022)。
Pennington,J。,Socher,R。&Manning,C。手套:单词表示的全球向量。在自然语言处理经验方法会议论文集(EMNLP)(美国宾夕法尼亚州斯特劳兹堡计算语言学协会,2014年)。(美国宾夕法尼亚州斯特劳兹堡计算语言学协会,2014年)。(2014)。
Moen,S。P.&Ananiadou,T。S.生物医学文本处理的分销语义资源。在LBM会议论文集39â44(2013)。
Shortliffe,E。H.&SepãºLveda,M。J.人工智能时代的临床决策支持。美国医学会杂志 320,2199 2200(2018)。
Alzubi,J.,Nayyar,A。和Kumar,A。从理论到算法的机器学习:概述。J. Phys。会议。序列。 第1142章,012012(2018)。
Alpaydin,E。机器学习简介(麻省理工学院出版社,2020年)。
Islam,M。S.&Ghani,N。A.使用Bigru-Bilstm的深神经网络进行多级情感分析的新型BigRubilstM模型。在电气工程讲义新加坡新加坡新加坡414Sspringer,(2022年)。
Goodfellow,I.,Bengio,Y。&Courville,A。深度学习(麻省理工学院出版社,2016年)。
Alsulami,B。,Almalawi,A。&Fahad,A。迈向基于半监督方法的有效自动自我增强标记工具,用于入侵检测。应用。科学。(巴塞尔)。12,7189(2022)。文章
一个 中科院一个 谷歌学术一个 佩德雷戈萨,F.等人。Scikit-Learn:Python中的机器学习。
J.马赫.学习。资源。 12,2825 2830(2011)。
Hossin,M。&Sulaiman,M。N.有关数据分类评估评估指标的综述。国际。J.数据最小知识。马纳格。过程5,(2015)。
Babaei Rikan,S。等。使用现代深度学习和机器学习技术对胶质母细胞瘤患者的生存预测。科学。代表。 14,2371(2024)。
Ling,C。X.,Huang,J。,Zhang,H。&AUC比在比较学习算法方面的准确性更好。在人工智能的进步,329â341(Springer 2003)。
Linardatos,P.,Papastefanopoulos,V.,Kotsiantis,S。&Aplable,A。I.对机器学习可解释性方法的回顾。熵(巴塞尔)。23,18(2020)。
Mandrekar,J。N.诊断测试评估中的接收器操作特征曲线。J·索拉克。安科尔。 5,1315年1316年(2010年)。
Kazmaier,J。&van Vuuren,J。H.情感分析中合奏学习的力量。专家系统。应用。 187,115819(2022)。
Baradaran,R。&Amirkhani,H。基于集合学习的方法,用于提高机器阅读理解系统的概括能力。神经计算 第466章,229 - 242(2021)。
Rezaeinia,S.M.,Rahmani,R.,Ghodsi,A。&Veisi,H。基于改进的预训练单词嵌入的情感分析。专家系统。应用。 117,139 - 147(2019)。
资金
这项研究没有任何资金。
道德声明
利益竞争
作者声明没有竞争利益。
道德认可
不适用。
同意发表
不适用。
附加信息
出版商备注
施普林格·自然对于已出版的地图和机构隶属关系中的管辖权主张保持中立。
电子补充材料
以下是电子补充材料的链接。
权利和权限
开放获取本文获得 Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License 的许可,该许可允许以任何媒介或格式进行任何非商业使用、共享、分发和复制,只要您给予原作者适当的署名即可和来源,提供知识共享许可的链接,并指出您是否修改了许可材料。根据本许可,您无权共享源自本文或其部分内容的改编材料。本文中的图像或其他第三方材料包含在文章的知识共享许可中,除非材料的出处中另有说明。如果文章的知识共享许可中未包含材料,并且您的预期用途不受法律法规允许或超出了允许的用途,则您需要直接获得版权所有者的许可。要查看该许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。转载和许可
引用这篇文章

Sorayaie Azar,A.,Babaei Rikan,S.,Naemi,A。
等人。使用人工智能技术来预测患者对药物的情感。科学代表14 ,31928(2024)。https://doi.org/10.1038/s41598-024-83222-9
已收到:
公认:
已发表:
DOI:https://doi.org/10.1038/s41598-024-83222-9