
检索卫生保健生成人工智能的生成生成
作者:Liu, Nan
生成人工智能(AI)最近在包括GPT在内的各个领域引起了广泛的关注
1,,,,2和骆驼3,,,,4文本生成系列,dall-e5用于图像生成以及Sora6用于视频生成。在卫生保健系统中,生成AI对咨询,诊断,治疗,管理和教育的应用有望7,,,,8。此外,生成AI的利用可以提高患者的卫生服务质量,同时减轻临床医生的工作量8,,,,9,,,,10。尽管如此,要确认生成AI模型的固有局限性至关重要,这些局限性包括对训练数据的偏见的敏感性11
,缺乏透明度,产生错误的内容的潜力以及保持最新知识的难度7。例如,大型语言模型(LLM)被证明通过采用过时的基于种族的方程来估计肾功能来产生偏见的响应12。在产生图像的过程中,已经观察到与性别,肤色和地质文化因素有关的偏见13。同样,对于诸如问答回答之类的下游任务,LLM生成的内容通常是不一致的,并且缺乏验证的证据14。此外,由于它们的静态知识和无法访问外部数据,生成的AI模型无法为医生提供最新的临床建议或为患者提供有效的个性化健康管理15。在应对这些挑战时,探索了检索功能的一代(RAG)作为潜在的解决方案16
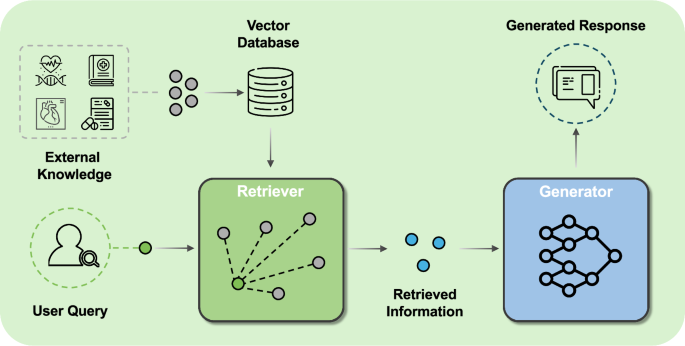
,,,,17。通过为模型提供外部检索数据,RAG可以提高生成内容的可靠性。一个典型的抹布框架由三个部分组成(图。1):索引,检索和世代。在索引阶段,外部数据分为块,编码为向量,并存储在矢量数据库中。在检索阶段,将用户查询编码为向量表示,然后通过查询和矢量数据库中的信息之间的相似性计算来检索最相关的信息。检索技术不仅限于密集的检索,还包括稀疏和混合检索方法,可以采用先进的重读方法来提高检索内容的相关性。在生成阶段,用户的查询和检索到的相关信息均由模型引起生成内容。与特定任务的模型微调相比,抹布通常在计算上更有效,并且已被证明可以提高知识密集型任务的准确性18,为模型更新提供更灵活的范式,并与其他AI技术集成。

首先将外部数据编码为向量并存储在向量数据库中(其中向量是高维空间中各种数据的数学表示)。在检索阶段,当收到用户查询时,回猎犬从矢量数据库中搜索最相关的信息。在生成阶段,用户的查询和检索到的信息都用于提示模型生成内容。
从这个角度来看,我们在生成AI的背景下讨论了抹布的作用,尤其是其在医疗保健中的可能应用。我们从三个方面进行了RAG的可能贡献:公平,可靠性和个性化(图。2)。此外,我们探讨了在医疗应用方案中抹布的局限性,强调需要进一步研究以了解其在卫生系统中的实施影响19。

生成的AI具有偏见的繁殖,缺乏透明度,信息不正确和静态知识等局限性,这阻碍了其在医疗保健中的进一步应用。检索声明的一代具有减轻这些问题并从公平,可靠性和个性化的角度推动医疗创新的潜力。
在生成AI应用中促进健康平等
减少偏差
生成AI模型产生的内容可能会持续培训数据中固有的偏见,这些偏见反映在包括人口特征,政治意识形态和性取向的各个方面12,,,,13,,,,20。这种偏见不仅可以导致不公平的诊断和治疗,而且会加剧特定人群的健康不平等。
RAG能够从外部知识来源获取信息,包括医学文献,临床指南和病例报告,以优化生成AI模型的输出17。通过检索特定于某些亚群的信息,该模型可以从多个角度分析患者的状况,从而有可能降低生成内容中所含偏见的风险。例如,当针对不同的性别群体时,抹布可以检索有关其特定生理模式,常见疾病光谱,临床表现以及临床实践的相关建议的研究结果21,,,,22,,,,23。同样,对于不同的族裔,RAG可以访问涉及其遗传,环境和生活方式因素的研究报告,以了解疾病发病率和独特症状表现的差异24。此外,对于其他特定的亚群(例如不同的年龄段,社会经济地位等),RAG可以检索量身定制的医学证据,以帮助全面了解其独特的健康需求25。尽管在确保访问代表性不足的群体的高质量数据方面仍然存在挑战,但RAG提供了缓解这些问题的可能解决方案。
减轻差异
健康差异在获得医疗资源和卫生服务方面给边缘化群体带来了其他挑战,有可能阻碍公平的成就。尽管生成的AI模型经过广泛的数据培训,但预训练数据本身在代表不同的组方面表现出不平衡。例如,GPT-3的前训练前训练语料库的92.64%来自英语,导致使用其他语言的社区覆盖有限1。这种偏斜可能使得满足代表性不足的群体的医疗需求具有挑战性。
收集特定于这些代表性不足的人群并将其纳入抹布系统的数据具有减轻医疗保健差异的潜力。具体而言,在低资源区域中,抹布系统可能会利用将当地医学研究文献,临床准则和实践经验整合的知识,以向当地居民提供更相关的诊断和治疗建议26。尽管某些区域指南可能不会数字化,但音频和图像识别技术可以将此信息转换为数字格式,从而创建特定于区域的上下文数据库27。同样,通过开发高质量的多语言医学知识库,RAG可以在跨语言信息检索和知识整合中发挥重要作用,并有可能消除因语言差异而带来的障碍。但是,值得注意的是,即使是目前最先进的LLM,也仅支持有限数量的主流语言,这限制了抹布在多语言环境中的有效性,尤其是在低资源设置中处理语言时28。此外,RAG系统能够检索预收集的材料并以各种格式(例如文本,图像和视频)展示它们,以促进患者的教育。这种方式可以向具有多种教育和文化背景的患者解释复杂的医疗概念29。
生成可靠的内容
减轻错误
卫生保健中生成AI模型的一个重大挑战是它们产生不正确或不忠信息的潜力7,,,,8。尽管已经在大量医学数据(例如Med-palm2和Med-Gemini)上进行了预先培训的特定模型,但无法避免幻觉的现象29,,,,30。此问题非常敏感,因为与疾病诊断,治疗计划或药物指导有关的任何虚假信息都可能对患者造成严重伤害31。
例如,用药错误是医疗错误的主要类别,每年导致许多患者死亡32,,,,33。在将处方说明转换为标准格式的阶段,药房技术人员可能会错误记录剂量,频率或给药途径32。此外,当患者将药物从原包装转移到其他容器时,药剂师很难识别药物,这可能导致遗漏错误33。鉴于电子健康记录建议和警报通常不精确,并且传统的自然语言处理方法需要广泛的人类注释,因此生成的AI提供了有吸引力的解决方案。但是,生成的AI模型有时也会产生不正确的药物信息,从而进一步危害。破布可能有助于解决其中一些问题。通过搜索各种药物信息,RAG可以在数据输入阶段自动解析处方并生成更准确的药物指导,从而减少信息传输引起的医疗错误。此外,在药物识别过程中,多模式抹布系统具有识别药物的外观特征,例如颜色,形状和烙印。通过将这些特征与数据库信息匹配,抹布系统可以生成可靠的药物信息以作为药剂师的参考,从而提高药物识别的效率。但是,至关重要的是要强调,这些应用程序仍处于开发的早期阶段,并且需要在实施之前进行彻底验证。
透明度提高
生成AI模型的黑盒性质使得很难解释如何得出特定的诊断或治疗建议。这种缺乏透明度不仅破坏了医生和患者在产生的内容中的信任,而且更重要的是,它可能构成严重的医疗风险和道德问题。尽管一些研究试图通过诸如思想链之类的方法来增强模型推理能力和透明度34,多代理讨论35和事后归因36,医疗应用程序仍然存在限制37。
相比之下,RAG能够从外部知识库中检索可追溯的医学事实,从而促进了更透明的内容的产生。但是,此过程仍然需要手动验证38。在协助临床决策时,RAG可以提供诊断所基于的信息来源,包括临床准则,医学证据和临床病例。通过将查询分类为简单的事实搜索或多步推理过程,RAG可以进一步阐明不同类型的信息如何促进给定建议,从而提高其决策的透明度。此外,一些研究还利用了外部医学知识图(例如统一的医学语言系统)或自我构造的知识图来增强模型的诊断能力14,,,,39。基于给定的查询,抹布系统首先识别知识图中的相关节点,例如疾病,症状或药物,然后检索直接关系和连接这些节点的多跳路路径。这个过程使抹布系统可以有效提取结构化的,相关的知识并利用其提供明确的诊断解释14。
个性化医疗服务
健康管理
破布还显示了个性化医疗保健管理的潜力。生成的AI模型缺乏合并个人信息的能力,因此难以提供有效的健康服务8。例如,他们可能不知道用户的过敏并推荐过敏性食物。相比之下,抹布系统可以整合个人的健康数据和生活方式习惯,以建立全面的个人资料,这可能可以实现更自定义的健康指导。
对于患者,通过连接他们的病历和临床数据,同时允许实时更新,抹布系统具有提供更精确的健康管理指导的能力。例如,对于需要长期服用多种药物的慢性病患者,该系统可以根据医生处方生成药物提醒,以确保患者正确及时服用药物,从而改善药物依从性。对于公众来说,抹布系统可以分析个人健康数据,生活方式,环境因素和遗传信息(如果是单个用户的访问权限),以识别潜在的健康风险。通过这种方式,抹布系统提供了个性化的健康建议,包括饮食,运动和压力管理,有效地促进了预防疾病。例如,对于患有心脏病遗传风险高的个体,该系统可以建议特定的饮食计划和适当的运动方案,以降低最终患上疾病的风险。
精密医学
Precision Medicine旨在根据患者的遗传特征,环境影响,生活方式和其他个体因素来调整治疗策略,从而最大程度地提高医疗效率和患者益处40。尽管当前的生成AI模型表现出了协助临床决策的潜力35,,,,41,他们仍然面临精密医学的挑战42,由于他们难以利用高度个性化的患者数据来提供精确的治疗建议。
抹布可能会为推进精密医学提供独特的优势。通过检索患者的复杂临床和分子数据,抹布系统使医生有能力制定针对每个患者量身定制的更准确和个性化的治疗计划43。例如,生成的AI模型通常向表现出相似体征和症状的癌症患者提供类似的一般临床建议。但是,实际上,由于其生物标志物的差异(例如,DNA,RNA,蛋白质,代谢物,宿主细胞和微生物组),这些患者通常具有不同的疾病进展和预后。44。尽管收集和保护此类敏感数据仍然是一个挑战,但RAG可以更好地利用此信息进行精确医学实践。具体而言,抹布系统可能能够全面分析患者的生物标志物,将其分类为更颗粒状的亚组,并根据既定的临床指南向医师推荐适当的个性化治疗计划。
讨论
RAG可以使生成AI更好地整合到卫生系统中,并在咨询,诊断,治疗,管理和教育中带来更多创新的应用。尽管抹布系统在医疗保健中有潜力,但它们也面临着重大局限性。首先,外部知识的检索可能会引入其他偏见,因为这些来源本身可能包含偏见。其次,由于缺乏有关代表性不足的群体的足够高质量的信息,在这种情况下,抹布系统可能会降低,而生成的内容更多地依赖于模型本身的知识。结果,少数群体不太可能从现有的抹布系统中受益。第三,尽管抹布系统可以通过提供证据来提高透明度,但确定响应的哪些部分是从没有人类检查的情况下从哪些部分中检索到的知识的。同时,尽管有效的实施仍然具有挑战性45。第四,RAG系统面临某些隐私风险,因为可以通过设计的提示提取检索数据库中存储的敏感信息。实施适当的隐私保护机制对于减轻生成内容中信息泄漏的风险至关重要,尤其是在处理敏感医疗信息时46。因此,我们建议临床医生,研究人员,利益相关者和监管机构之间进行多学科的合作,以探讨如何更公平,可靠,有效地使用破布以改善医疗保健中的现有实践。这种合作应着重于应对实际挑战,包括确保与EHR系统的互操作性,建立临床医生信任,并为医疗保健专业人员提供足够的培训,以充分利用破布的潜力47。
数据可用性
在当前研究中没有生成或分析数据集。
参考
Brown,T。等。语言模型是很少的学习者。ADV。神经信息。过程。系统。 33,1877年(2020年)。
Openai等。GPT-4技术报告。https://doi.org/10.48550/arxiv.2303.08774(2023)。
Touvron,H。等。骆驼:开放有效的基础语言模型。https://doi.org/10.48550/arxiv.2302.13971(2023)。
Touvron,H。等。骆驼2:开放基础和微调聊天模型。https://doi.org/10.48550/arxiv.2307.09288(2023)。
https://openai.com/index/sora/。Thirunavukarasu,A。J.等。医学中的大型语言模型。
纳特。医学 29,1930年(2023年)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Yang,R。等。医疗保健中的大型语言模型:开发,应用和挑战。医疗科学 2,255 263(2023)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Roberts,K。减轻临床医生文件负担的大型语言模型。纳特。医学 30,942â943(2024)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Chen,S。等。使用大型语言模型响应患者信息的效果。柳叶刀数字。健康 6,E379 e381(2024)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Chen,S。等。交叉护理:评估对语言模型偏见的预培训数据的医疗保健意义。预印本arxiv。 https://doi.org/10.48550/arxiv.2405.05506(2024)。
Omiye,J。A.,Lester,J。C.,Spichak,S.,Rotemberg,V。&Daneshjou,R。大语言模型传播基于种族的药物。NPJ数字。医学 6,1 - 4(2023)。
文章一个 Google Scholar一个
Wan,Y。等。文本到图像生成中偏见的调查:定义,评估和缓解措施。预印本arxiv。 https://doi.org/10.48550/arxiv.2404.01030(2024)。
Yang,R。等。KG秩:通过知识图和排名技术增强医学质量检查的大型语言模型。第23届生物医学自然语言处理研讨会论文集155â166(计算语言学协会,美国宾夕法尼亚州斯特劳兹堡,2024年)。
柯克(H.纳特。马赫。Intell。 6,383 392(2024)。
文章一个 Google Scholar一个
Gilbert,S.,Kather,J。N.&Hogan,A。增强非障碍的大语言模型作为医疗信息策展人。NPJ数字。医学 7,1 -5(2024)。
文章一个 Google Scholar一个
Zakka,C。等。临床医学的年鉴检索语言模型。nejm ai。 https://doi.org/10.1056/aioa2300068(2024)。
O. Ovadia,M.比较LLM中的知识注入。预印本arxiv。 https://doi.org/10.48550/arxiv.2312.05934(2023)。
Yang,R。等。从全球角度来看,启用AI的临床研究中的差异。NPJ数字。医学 7,209(2024)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Ayoub,N。F。等。大语言模型中的固有偏见:随机抽样分析。梅奥临床。Proc。数字。健康 2,191(2024)。
Haupt,S.,Carcel,C。&Norton,R。研究中的性别和性别是一种公共卫生风险。自然。 https://doi.org/10.1038/d41586-024-01372-2(2024)。
Narasimhan,M。等。妇女健康和福祉的自我保健干预措施。纳特。医学 30,660â669(2024)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Vieira Machado,C.,Araripe Ferreira,C。&de Souza Mendes Gomes,M。A.在科学和健康劳动力中促进性别平等对于改善妇女的健康至关重要。纳特。医学 30,937年939(2024)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
雷贝克(T.纳特。医学 28,890 A 893(2022)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Lewis,C。V.,Huebner,J.,Hripcsak,G。&Sabatello,M。我们所有人的盲人和聋人参与者的代表性不足。纳特。医学 29,2742 2747(2023)。
文章一个 Google Scholar一个
Ferber,D。等。GPT-4用于信息检索和比较医学肿瘤学指南。nejm ai。 https://doi.org/10.1056/AICS2300235(2024)。
Acosta,J。N.,Falcone,G。J.,Rajpurkar,P。&Topol,E。J.多模式生物医学AI。纳特。医学 28,1773年1784年(2022)。
文章一个 CAS一个 PubMed一个 Google Scholar一个
Llama 3.2:通过开放的,可自定义的模型彻底改变了Edge AI和视野。meta ai。 https://ai.meta.com/blog/llama-3-2-connect-2024-vision-vision-dedge-mobile-devices/。Saab,K。等。
双子座模型在医学中的能力。预印本arxiv。 https://doi.org/10.48550/arxiv.2404.18416。(2024)。
Singhal,K。等。使用大语言模型回答专家级的医学问题。预印本arxiv。 https://doi.org/10.48550/arxiv.2305.09617(2023)。
Yang,R。等。ASCLE python自然语言处理工具包用于医学文本生成:开发和评估研究。J. Med。Internet Res。 26,E60601(2024)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Pais,C。等。大型语言模型,用于预防在线药房中的药物方向错误。纳特。医学 30,1574年1582(2024)。
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Larios Delgado,N。等。快速准确的药物识别。NPJ数字。医学 2,1页(2019年)。
文章一个 Google Scholar一个
Liâ©Vin,V.,Hother,C。E.,Motzfeldt,A。G.&Winther,O。大语言模型是否可以理解有关医疗问题的原因?图案 5,100943(2024)。
Ke,Y。H。等。通过大型语言模型:模拟研究来减轻临床决策中的认知偏见。J Med Internet Res 26,E59439(2024)。
Krishna,S。等。关于语言模型的事后解释可以改善语言模型。ADV。神经信息。过程。系统。 36,65468 65483(2023)。
Zhao,H。等。大型语言模型的解释性:调查。ACM Trans。Intell。系统。技术。 15,1 38(2024)。
Kresevic,S。等。大型语言模型对肝临床准则进行优化:基于增强生成的框架。NPJ数字。医学 7,1 9(2024)。
文章一个 Google Scholar一个
Wu,J.,Zhu,J。&Qi,Y。医学图:通过图检索 - 杰出的一代迈向安全的医学大语言模型。预印本arxiv。 https://doi.org/10.48550/arxiv.2408.04187(2024)。
Kânig,I。R.,Fuchs,O.,Hansen,G.,Von Mutius,E。&Kopp,M。V.什么是精密医学?欧元。呼吸。j。50,1700391(2017)。Liu,S。等。
使用AI生成的建议从Chatppt提出的建议来优化临床决策支持。J. Am。医学通知。联合。 30,1237年1245(2023)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Truhn,D.,Eckardt,J.-N.,Ferber,D。&Kather,J。N.大型语言模型和多模式基础模型的精确肿瘤学模型。NPJ Precis。Oncol。 8,1 - 4(2024)。
Benary,M。等。利用大型语言模型在个性化肿瘤学中进行决策支持。JAMA NetW。打开 6,E2343689 e2343689(2023)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Vargas,A。J.&Harris,C。C. Precision Medicial时代的生物标志物发育:肺癌作为案例研究。纳特。癌症牧师 16,525 - 537(2016)。
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Yang,R。等。图形:具有全球视角的知识图构造的抹布框架。预印本arxiv。 https://doi.org/10.48550/arxiv.2410.17600(2024)。
Zeng,S。等。好与坏:探索检索授权一代(RAG)中的隐私问题。预印本arxiv。 https://doi.org/10.48550/arxiv.2402.16893(2024)。
Ning,Y。等。卫生保健中的生成人工智能和道德考虑:范围审查和道德清单。柳叶刀数字。健康。 https://doi.org/10.1016/s2589-7500(24)00143-2(2024)。
致谢
这项工作得到了新加坡卫生部资助的杜克 - 纳斯签名研究计划的支持。在本材料中表达的任何意见,发现和结论或建议都是作者的意见,也不反映卫生部的观点。
道德声明
竞争利益
作者没有宣称没有竞争利益。
附加信息
出版商的注释关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
权利和权限
开放访问本文均根据创意共享归因4.0国际许可,允许以任何媒介或格式使用,共享,适应,分发和复制,只要您适当归功于原始作者和来源链接到Creative Commons许可证,并指示是否进行了更改。本文中的图像或其他第三方材料包含在文章的创意共享许可证中,除非在材料的信用额度中另有说明。如果文章的创意共享许可中未包含材料,并且您的预期用途不得由法定法规允许或超过允许的用途,则需要直接从版权所有者那里获得许可。要查看此许可证的副本,请访问http://creativecommons.org/licenses/4.0/。重印和权限
引用本文

Yang,R.,Ning,Y.,Keppo,E。
等。检索卫生保健生成人工智能的生成生成。NPJ健康系统。2 ,2(2025)。https://doi.org/10.1038/S44401-024-00004-1
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s44401-024-00004-1