

DeepSeek再次罢工:其新的开源AI模型是否击败了Dall-E 3? - 解密
作者:Decrypt / Jose Antonio Lanz
中国AI实验室DeepSeek最近对行业发展成本进行了颠覆,该实验室发布了一个新的开源多模式AI模型系列,据报道,在关键基准上,OpenAi的Dall-e 3都超过了OpenAI的DALL-E 3。
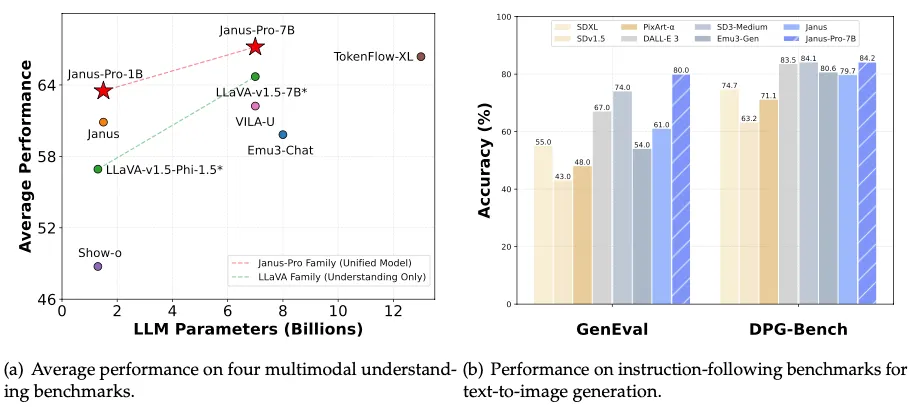
称为Janus Pro该模型范围从10亿到70亿参数(接近SD 3.5L的大小),可立即在机器学习和数据科学中心上下载拥抱面。
最大的版本Janus Pro 7b不仅击败了Openai的Dall-E 3,还击败了其他领先模型,例如Pixart-Alpha,Emu3-Gen和SDXL,在行业基准测试基准Geneval和DPG基础上。共享由deepseek ai。
它的发布就在DeepSeek成为头条新闻之后的几天R1语言模型,它与GPT-4的功能相匹配,而开发的成本仅为500万美元引发激烈的辩论关于AI行业的当前状态。
这家中国初创公司的产品还引发了整个部门的担忧,它可能会颠覆现有企业并击败主要芯片制造商NVIDIA的增长轨迹,该芯片制造商NVIDIA遭受了最大的单日市值损失在周一的历史上。
DeepSeek的Janus Pro模型使用了该公司所谓的“新型自回归框架”,该框架将视觉编码分解为单独的路径,同时维护单个统一的变压器体系结构。
该设计使模型可以分析图像并以768x768分辨率生成图像。
DeepSeek在其中声称:“ Janus Pro超过了以前的统一模型,匹配或超过了特定于任务模型的性能。”发布文档。“ Janus Pro的简单性,高灵活性和有效性使其成为下一代统一多模型模型的强大候选人。”
与DeepSeek R1不同,该公司没有在模型上发布完整的白皮书,但确实发布了技术文档,并且 使该模型可以立即免费下载``继续其开源版本的做法与美国科技巨头的封闭,专有方法形成鲜明对比。
那么,我们的判决是什么?好吧,该模型具有高度的用途。
但是,不希望它取代您喜欢的任何最专业的车型。它可以生成文本,分析图像并生成照片,但是当对着仅能做得很好的模型固定时,充其量是在标准杆上。
测试模型
请注意,没有立即使用传统的UI来运行它的舒适,A1111,Focus和Draw Things现在与之不兼容。这意味着在本地运行该模型并需要在终端中浏览文本命令是不切实际的。
但是,一些Hugginface用户创建了尝试模型的空间。DeepSeek的官方空间不可用,所以我们建议使用Neurosenko尝试Janus 7B的空间。
注意您的工作,因为某些标题可能会误导。 例如, 由AP123运行的空间说它运行了Janus Pro 7B,但运行Janus Pro 1.5B,最终可能会让您失去大量的空闲时间测试模型并获得不良结果。相信我们:我们知道这是因为它发生在我们身上。
视觉理解
该模型擅长视觉理解,并且可以准确地描述照片中的元素。
它显示出良好的空间意识和不同对象之间的关系。
它也比LLAVA最流行的开源视觉模型更准确,能够提供更准确的场景描述并根据视觉提示与用户互动。
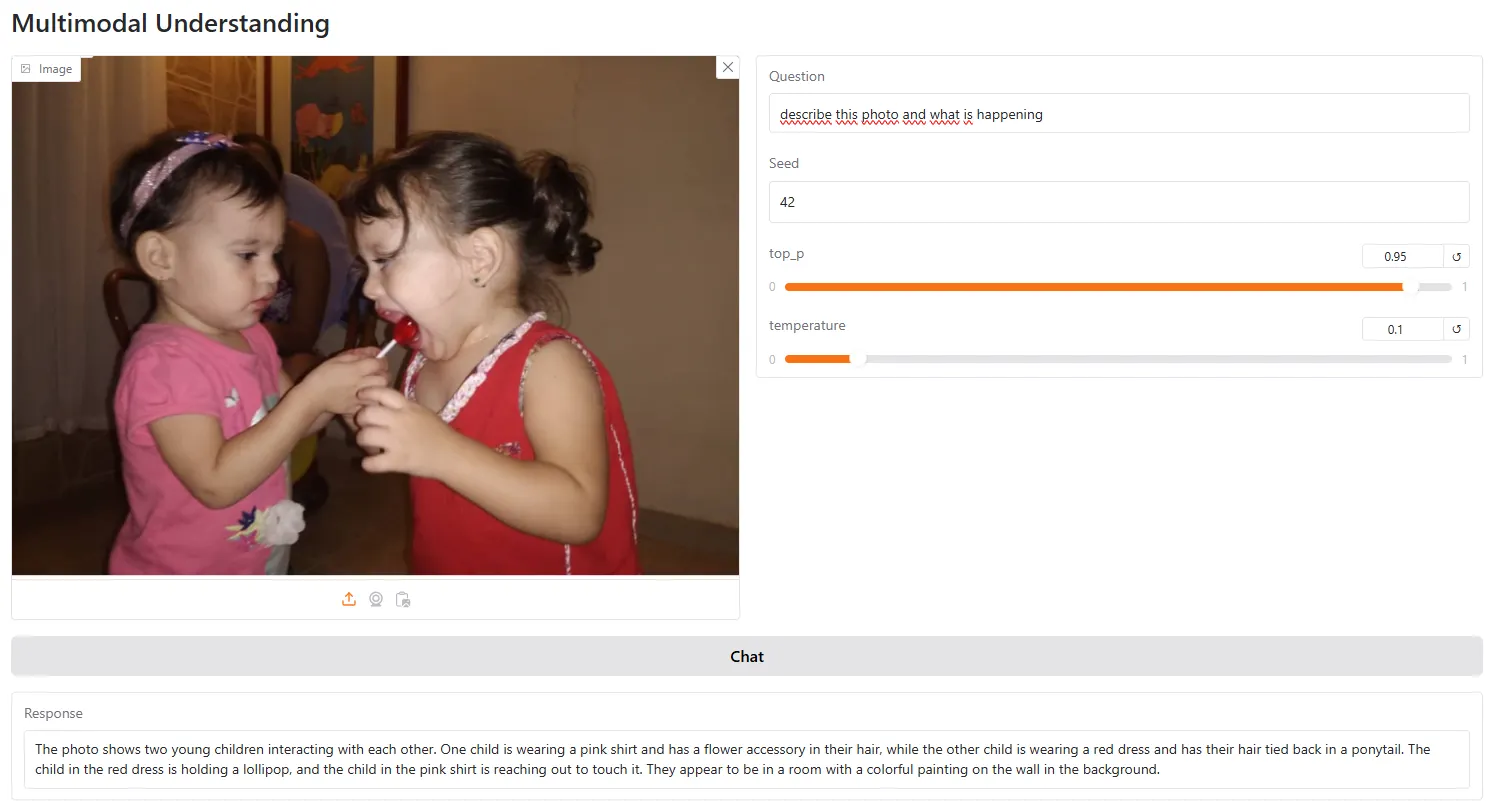
但是,它仍然不比GPT视觉好,尤其是对于需要逻辑或某些分析的任务,超出了照片中明显显示的内容。例如,我们要求该模型分析这张照片并解释其信息

该模型回答说,图像似乎是一部幽默的卡通,描绘了一个女人在舔着男孩的长长的红色舌头的末端。”
它结束了分析,说“图像的整体语气似乎都很轻松又好玩,可能暗示了女人正在从事调皮或戏弄的行为的情况。

在这些情况下,除了简单的描述之外,需要一些推理,大多数情况下,该模型会失败。
另一方面,例如,chatgpt实际上理解了图像背后的含义:这个比喻表明,母亲的态度,言语或价值观直接影响了孩子的行为,尤其是以负面的方式,例如欺凌或歧视,我们可以补充说,它得出的结论。

自己的联盟
图像生成看起来强大且相对准确,尽管确实需要仔细提示才能取得良好的结果。
DeepSeek声称Janus Pro击败了SD 1.5,SDXL和Pixart Alpha,但重要的是要强调,这必须是与基础非微调模型进行比较。
换句话说,公平的比较是在当前可用的最糟糕的版本之间,因为可以说,当有数百种的微调能够达到可以与即使是最新的 -诸如通量或稳定扩散3.5的模型。
因此,几代人在质量方面一点也不令人印象深刻,但它们似乎比SD1.5或SDXL发射时使用的要好。
例如,这里是Janus和SDXL生成的图像的面对面比较:可爱又可爱的婴儿狐狸,棕色大眼睛,背景中的秋叶迷人,不朽,蓬松,闪亮的鬃毛,花瓣,童话,高度详细,近视,逼真的,电影,自然色彩。

Janus在理解核心概念时击败了SDXL:它可以产生婴儿狐狸而不是成熟的狐狸,就像SDXL的情况下一样。
它还更好地了解了影子主义风格,并且还存在其他元素(蓬松,电影)。
也就是说,尽管不遵守提示,但SDXL还是产生了酥脆的图像。整体质量更好,眼睛是现实的,细节更容易发现。
在其他几代人中,这种模式是一致的:良好的迅速理解但执行不佳,考虑到当前最新的图像发生器的良好状态的模糊图像感觉过时。
但是,重要的是要注意,Janus是一种能够生成文本对话,分析图像和生成图像的多模式LLM。Flux,SDXL和其他模型不是为这些任务构建的。
因此,与在一项特定任务上脱颖而出相比,Janus的核心更具用途不错。
作为开源的,Janus作为生成AI爱好者的领导者的未来将取决于一系列寻求改善这些观点的更新。
编辑乔什·奎特纳(Josh Quittner)和塞巴斯蒂安·辛克莱(Sebastian Sinclair)
通常聪明的新闻通讯
Gen叙述的每周AI旅程,Gen是一种生成的AI模型。