
在过去的两年中,将生成性AI注入了技术巨人的血液以及现在各种规模和条纹的企业中,迫使IT供应商,从硬件制造商到组件提供商到企业应用程序开发人员,以快速重新打造其路线图,以解决这些新兴技术提出的特定要求和机会。
这包括一个数据存储系统制造商,他们已经解决了HPC中心和其他组织进行计算的可伸缩性挑战。但是,根据纯存储技术副总裁查德·肯尼(Chadd Kenney)表示,这些存储系统包括平行文件系统和分解存储 - 不一定会转化为AI环境的需求。
借助AI,工作负载比传统的应用程序更不可预测,它们很复杂,它们是多模式的 - 咀嚼和输出文本,图像和视频 - 肯尼告诉下一个平台。对于那些现有的工作负载,性能和可伸缩性在那里,但它们在包括数千至成千上万昂贵的GPU通过这些应用程序中的环境环境中不错。组织正在告诉纯存储,他们完全能够充分利用它们所拥有的所有GPU,并且基本上以一致的方式读写和写作的能力 - 由于他们认为是存储瓶颈而遭受的可伸缩性。
他说,随着这些模型正在发展并且它们变得越来越多模式,它不再仅仅是基于文本的,''他说。既然这些系统必须处理所有这些不同类型的媒体,这与传统的HPC工作量有很大不同。尽管这些类型的工作负载存在差异,但它们的处理方式往往相对一致。
从需要多种不同的命名空间或新型产品的新产品类型的产品中,所有这些产品都促成了高成本和低ROI的需求。
对于纯存储,在特定的市场领域中,大部分痛苦都受到了。肯尼说,数百个组织正在使用其扩展的闪光灯存储平台用于企业工作量。同样,纯存储宣布了使用元平台的设计胜利这是第一个与超级标准的人,并在超高端给公司立足,在该组织中,组织在其系统中运行成千上万的GPU,并且需要保持其喂养。
但这是在市场的中间的客户 - 那些在数以万计的gpus中运行的人,他们希望从存储阵列中1 tb/sec到50 tb/sec的性能,而肯尼(Kenney”
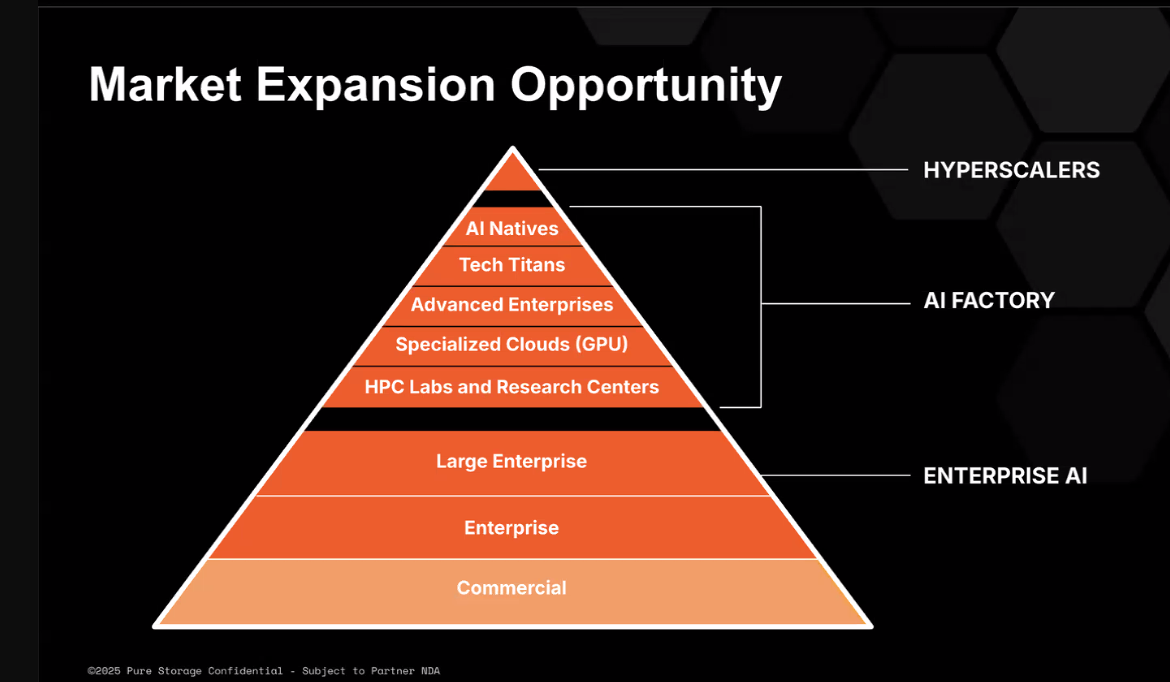
肯尼解释说:`当今购买大部分GPU的人都在大规模培训。”我们想知道这些客户的要求。我们知道企业要求是什么。每秒的Terabyte将为您带来大多数客户,因为他们仍处于早期实验阶段。对于我们在那里看到的大多数企业,通常不到一千千套。高度标准在超高端。他们想要每秒以上的50保持trabytes,并且正在建造完全不同的建筑。在超大型设计的胜利中,我们从他们那里学到了很多东西,这使我们开始对产品的思考与以前的看法有所不同。”
这种思维导致了本周的Pure s Flastblade的介绍// EXA,这是一个在Flashblade基础架构上构建的存储平台,重点是高分子,以及在HPC和AI工作量中发现的大量元数据,并且是造成大量存储瓶颈的原因。Flashblade // EXA通过独立缩放数据和元数据来解决该问题。

当尝试解决元数据挑战时,纯存储有两个概念。一个是平行文件系统,用于HPC,适合可扩展性和性能,但在升级厚客户端和管理系统方面复杂。另一个是分类,它也预先提前了当前的AI时代,并带有自己的性能瓶颈,尤其是在写作周围,元数据和数据摄入量都在同一层次上进行。
纯储存工程师知道,元数据在Flashblade中得到了高度优化,但是供应商希望为数据节点提供无尽的规模,易于使用传统协议的采用,并且网络让企业轻松地将其带入其环境。
他说,我们使用Flashblade作为元数据核心构建了此Flashblade // EXA体系结构,然后利用数据节点来实现超扩展性,并允许您灵活地朝任何想要的方向增强。”如果您确实需要,则可以有十个数据节点和一大堆元数据,如果您有很小的小文件。您可以拥有许多数据节点,只有一个元数据节点。对此规模模型没有任何限制。现在,该平台变成了Flashblade的扩展。

高度分类和并行的体系结构将消除多模式的性能影响,并从他添加的单个命名空间中以10 TB/SEC读取性能开始。此外,组织将能够使用一些现成的技术 - 它与其他存储者的数据节点兼容,而Flashblade则将用于元数据以及纯存储自己的技术。
肯尼说:``我们要将这些数据节点脱离了架子,因为从一开始,当我们开始与他们谈论潜在地实现这一目标时,客户要求这一点。”肯尼说。他们想立即利用现有的投资。
该计划旨在提供在其DirectFlash模块(DFM)上构建的数据节点,从75 TB和150 TB及以后的300 TB开始,该数据节点将在2U模型中提供1.8 pb和7.2 pb。

纯净的本月开始让客户开始测试该平台,大约有十二个概念证明,并计划在夏季将其提供。最初,该系统将支持PNF供访问权限,并计划不久之后提供S3,以及DFM数据节点,NVIDIA认证以及与纯的融合存储与代码服务。

注册我们的新闻通讯
直接从我们到您的收件箱中,介绍了一周的亮点,分析和故事,两者之间一无所有。
立即订阅