

Legal AI Benchmarking: Evaluating Long Context Performance for LLMs - Thomson Reuters Institute
The Importance of Long Context
In the legal profession, many daily tasks revolve around document analysis—reviewing contracts, transcripts, and other legal documents. As the leading AI legal assistant, CoCounsel’s ability to automate document-centric tasks is one of its core legal capabilities. Users can upload documents, and CoCounsel can automatically perform various tasks on these documents, saving lawyers valuable time.
Legal documents are often extensive. Deposition transcripts can easily exceed a hundred pages, and merger and acquisition agreements can be similarly lengthy. Additionally, some tasks require the simultaneous analysis of multiple documents, such as comparing contracts or testimonies. To perform these legal tasks effectively, solutions must handle long documents without losing track of critical information.
When GPT-4 was first released in 2023, it featured a context window of 8K tokens, equivalent to approximately 6,000 words or 20 pages of text. To process documents longer than this, it was necessary to split them into smaller chunks, process each chunk individually, and synthesize the final answer. Today, most major LLMs have context windows ranging from 128K to over 1M tokens. However, the ability to fit 1M tokens into an input window does not guarantee effective performance with that much text. Often, the more text included, the higher the risk of missing important details. To ensure CoCounsel’s effectiveness with long documents, we’ve developed rigorous testing protocols to measure long context effectiveness.
Why a Multi-LLM Strategy—and Trusted Testing Ground—Matter
At Thomson Reuters, we don’t believe in putting all our bets on a single model. The idea that one LLM can outperform across every task—especially in high-stakes professional domains—is a myth. That’s why we’ve built a multi-LLM strategy into the core of our AI infrastructure. It’s not a fallback. It’s one of our competitive advantages.
Some models reason better. Others handle long documents more reliably. Some follow instructions more precisely. The only way to know what’s best for any given task is to test them—relentlessly. And that’s exactly what we do.
Because of our rigor and persistence in this space, Thomson Reuters is a trusted, early tester and collaborator for leading AI labs. When major providers want to understand how their newest models perform in high-stakes, real-world scenarios, they turn to us. Why? Because we’re uniquely positioned to pressure-test these models against the complexity, precision, and accountability that professionals demand — and few others can match.
- Our legal, tax, and compliance workflows are complex, unforgiving, and grounded in real-world stakes
- Our proprietary content—including Westlaw and Reuters News—gives us gold-standard input data for model evaluation
- Our SME-authored benchmarks and skill-specific test suites reflect how professionals actually work—not how a model demo looks on paper
When OpenAI was looking to train and validate a custom model built on o1-mini, Thomson Reuters was among the first. And when the next generation of long-context models hits the market, we are routinely early testers.
A multi-model strategy only works if you know which model to trust—and when. Benchmarking is how we turn optionality into precision.
This disciplined, iterative approach isn’t just the best way to stay competitive—it’s the only way in a space that’s evolving daily. The technology is changing fast. New models are launching, improving, and shifting the landscape every week. Our ability to rapidly test and integrate the best model for the job—at any moment—isn’t just a technical strategy. It’s a business advantage.
And all of this isn’t just about immediate performance gains. It’s about building the foundation for truly agentic AI—the kind of intelligent assistant that can plan, reason, adapt, and act across professional workflows with precision and trust. That future won’t be built on rigid stacks or static decisions. It will be built by those who can move with the market, test with integrity, and deliver products that perform in the real world.
RAG vs. Long Context
In developing CoCounsel’s capabilities, a significant question was whether and how to utilize retrieval-augmented generation (RAG). A common pattern in RAG applications is to split documents into passages (e.g., sentences or paragraphs) and store them in a search index. When a user requests information from the application, the top N search results are retrieved and fed to the LLM in order to ground the response.
RAG is effective when searching through a vast collection of documents (such as all case law) or when looking for simple factoid questions easily found within a document (e.g., specific names or topics). However, some complex queries require a more sophisticated discovery process and more context from the underlying documents. For instance, the query “Did the defendant contradict himself in his testimony?” requires comparing each statement in the testimony against all others; a semantic retrieval using that query would likely only return passages explicitly discussing contradictory testimony.
In our internal testing (more on this later), we found that inputting the full document text into the LLM’s input window (and chunking extremely long documents when necessary) generally outperformed RAG for most of our document-based skills. This finding is supported by studies in the literature1,2. Consequently, in CoCounsel 2.0 we leverage long context LLMs to the greatest extent possible to ensure all relevant context is passed to the LLM. At the same time, RAG is reserved for skills that require searching through a repository of content.
Comparing the Current Long-Context Models + testing GPT-4.1
As discussed in our previous post, before deploying an LLM into production, we conduct multiple stages of testing, each more rigorous than the last, to ensure peak performance.
Our initial benchmarks measure LLM performance across key capabilities critical to our skills. We use over 20,000 test samples from open and private benchmarks covering legal reasoning, contract understanding, hallucinations, instruction following, and long context capability. These tests have easily gradable answers (e.g., multiple-choice questions), allowing for full automation and easy evaluation of new LLM releases.
For our long context benchmarks, we use tests from LOFT3, which measures the ability to answer questions from Wikipedia passages, and NovelQA4, which assesses the ability to answer questions from English novels. Both tests accommodate up to 1M input tokens and measure key long context capabilities critical to our skills, such as multihop reasoning (synthesizing information from multiple locations in the input text) and multitarget reasoning (locating and returning multiple pieces of information). These capabilities are essential for applications like interpreting contracts or regulations, where the definition of a term in one part of the text determines how another part is interpreted or applied.
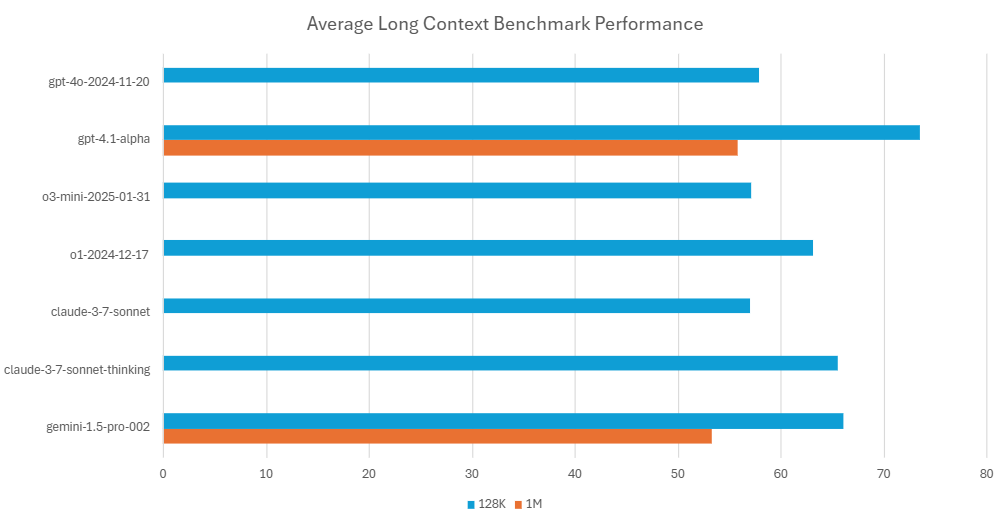
We track and evaluate all major LLM releases, both open and closed source, to ensure we are using the latest and most advanced models, such as the newly updated GPT-4.1 model with its much-improved long context capabilities.
Skill-Specific Benchmarks
The top-performing LLMs from our initial benchmarks are tested on our actual skills. This stage involves iteratively developing (sometimes very complex) prompt flows specific to each skill to ensure the LLM consistently generates accurate and comprehensive responses required for legal work.
Once a skill flow is fully developed, it undergoes evaluation using LLM-as-a-judge against attorney-authored criteria. For each skill, our team of attorney subject matter experts (SMEs) has generated hundreds of tests representing real use cases. Each test includes a user query (e.g., “What was the basis of Panda’s argument for why they believed they were entitled to an insurance payout?”), one or more source documents (e.g., a complaint and demand for jury trial), and an ideal minimum viable answer capturing the key data elements necessary for the answer to be useful in a legal context. Our SMEs and engineers collaborate to create grading prompts so that an LLM judge can score skill outputs against the ideal answers written by our SMEs. This is an iterative process, where LLM-as-a-judge scores are manually reviewed, grading prompts are adjusted, and ideal answers are refined until the LLM-as-a-judge scores align with our SME scores. More details on our skill-specific benchmarks are discussed in our previous post.
Our test samples are carefully curated by our SMEs to be representative of the use cases of our users, including context length. For each skill, we have test samples utilizing one or more source documents with a total input length of up to 1M tokens. Additionally, we have constructed specialized long context test sets where all test samples use one or more source documents totaling 100K–1M tokens in length. These long context tests are crucial because we have found that the effective context windows of LLMs, where they perform accurately and reliably, are often much smaller than their available context window.
In our testing, we have observed that the more complex and challenging a skill, the smaller an LLM’s effective context window for that skill. For more straightforward skills, where we search a document for one or a few data elements, most LLMs can accurately generate answers at input lengths up to several hundred thousand tokens. However, for more complex tasks, where many different data elements must be tracked and returned, LLMs may struggle with recall to a greater degree. Therefore, even with long context models, we still split documents into smaller chunks to ensure important information isn’t missed.
When you look at the advertised context window for leading models today, don’t be fooled into thinking this is a solved problem. It is exactly the kind of complex, reasoning-heavy real-world problem where that effective context window shrinks. Our challenge to the model builders: keep stretching and stress-testing that boundary!
Final Manual Review
All new LLMs undergo rigorous manual review by our attorney SMEs before deployment. Our SMEs can capture nuanced details missed by automated graders and provide feedback to our engineers for improvement. These SMEs further provide the final check to verify that the new LLM flow performs better than the previously deployed solution and meets the exacting standards for reliability and accuracy in legal use.
Looking Ahead: From Benchmarks to Agents
Our long-context benchmarking work is more than just performance testing — it’s a blueprint for what comes next. We’re not just optimizing for prompt-and-response AI. We’re laying the technical foundation for truly agentic systems: AI that can not only read and reason, but plan, execute, and adapt across complex legal workflows.
Imagine an AI assistant that doesn’t just answer a question, but knows when to dig deeper, when to ask for clarification, and how to take the next step — whether that’s reviewing a deposition, cross-referencing contracts, or preparing a case summary. That’s where we’re headed.
This next chapter requires everything we’ve built so far: long-context capabilities, multi-model orchestration, SME-driven evaluation, and deep integration into the professional’s real-world tasks. We’re closer than you think.
Stay tuned — more on that soon.
——-
- Li, Xinze, et al. “Long Context vs. RAG for LLMs: An Evaluation and Revisits.” arXiv preprint arXiv:2501.01880 (2024).
- Li, Zhuowan, et al. “Retrieval augmented generation or long-context llms? a comprehensive study and hybrid approach.” Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2024.
- Lee, Jinhyuk, et al. “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?.” arXiv preprint arXiv:2406.13121 (2024).
- Wang, Cunxiang, et al. “Novelqa: Benchmarking question answering on documents exceeding 200k tokens.” arXiv preprint arXiv:2403.12766 (2024).