

Understanding Aggregate Trends for Apple Intelligence Using Differential Privacy
At Apple, we believe privacy is a fundamental human right. And we believe in giving our users a great experience while protecting their privacy. For years, weâve used techniques like differential privacy as part of our opt-in device analytics program. This lets us gain insights into how our products are used, so we can improve them, while protecting user privacy by preventing Apple from seeing individual-level data from those users.
This same need to understand usage while protecting privacy is also present in Apple Intelligence. One of our principles is that Apple does not use our users' private personal data or user interactions when training our foundation models, and, for content publicly available on the internet, we apply filters to remove personally identifiable information like social security and credit card numbers. In this post, weâll share how weâre developing new techniques that enable Apple to discover usage trends and aggregated insights to improve features powered by Apple Intelligence, without revealing individual behavior or unique content to Apple.
Improving Genmoji
One area where weâve been applying our work on differential privacy with Apple Intelligence is Genmoji. For users who opt in to share Device Analytics with Apple, we use differentially private methods to identify popular prompts and prompt patterns, while providing a mathematical guarantee that unique or rare prompts arenât discovered and that specific prompts cannot be linked to individual users.
Knowing popular prompts is important because it helps Apple evaluate changes and improvements to our models based on the types of prompts that are most representative of real user engagement. For example, understanding how our models perform when a user requests Genmoji that contain multiple entities (like âdinosaur in a cowboy hatâ) helps us improve the responses to those kinds of requests.
This approach works by randomly polling participating devices for whether theyâve seen a particular fragment, and devices respond anonymously with a noisy signal. By noisy, we mean that devices may provide the true signal of whether a fragment was seen or a randomly selected signal for an alternative fragment or no matches at all. By calibrating how often devices send randomly selected responses, we ensure that hundreds of people using the same term are needed before the word can be discoverable. As a result, Apple only sees commonly used prompts, cannot see the signal associated with any particular device, and does not recover any unique prompts. Furthermore, the signal Apple receives from the device is not associated with an IP address or any ID that could be linked to an Apple Account. This prevents Apple from being able to associate the signal to any particular device.
Apple currently uses differential privacy to improve Genmoji, and in upcoming releases we will also use this approach, with the same privacy protections, for Image Playground, Image Wand, Memories Creation and Writing Tools in Apple Intelligence, as well as in Visual Intelligence.
Improving Text Generation with Synthetic Data
For Apple Intelligence features like summarization or writing tools that operate on longer sentences or entire email messages, the methods we use to understand trends in short prompts like Genmoji arenât effective, so we need a new method to understand trends while upholding our privacy standards, which means not collecting any individual userâs content. To address this challenge, we can expand on recent research to create useful synthetic data that is representative of aggregate trends in real user data, without collecting any actual emails or text from devices.
Synthetic data are created to mimic the format and important properties of user data, but do not contain any actual user generated content. When creating synthetic data, our goal is to produce synthetic sentences or emails that are similar enough in topic or style to the real thing to help improve our models for summarization, but without Apple collecting emails from the device. One way to create a synthetic email message is to use a large language model (LLM).
Creating a single synthetic email on one specific topic is just the first step. To improve our models we need to generate a set of many emails that cover topics that are most common in messages. To curate a representative set of synthetic emails, we start by creating a large set of synthetic messages on a variety of topics. For example, we might create a synthetic message, âWould you like to play tennis tomorrow at 11:30AM?â This is done without any knowledge of individual user emails. We then derive a representation, called an embedding, of each synthetic message that captures some of the key dimensions of the message like language, topic, and length. These embeddings are then sent to a small number of user devices that have opted in to Device Analytics.
Participating devices then select a small sample of recent user emails and compute their embeddings. Each device then decides which of the synthetic embeddings is closest to these samples. Using differential privacy, Apple can then learn the most-frequently selected synthetic embeddings across all devices, without learning which synthetic embedding was selected on any given device. These most-frequently selected synthetic embeddings can then be used to generate training or testing data, or we can run additional curation steps to further refine the dataset. For example, if the message about playing tennis is one of the top embeddings, a similar message replacing âtennisâ with âsoccerâ or another sport could be generated and added to the set for the next round of curation (see Figure 1). This process allows us to improve the topics and language of our synthetic emails, which helps us train our models to create better text outputs in features like email summaries, while protecting privacy.
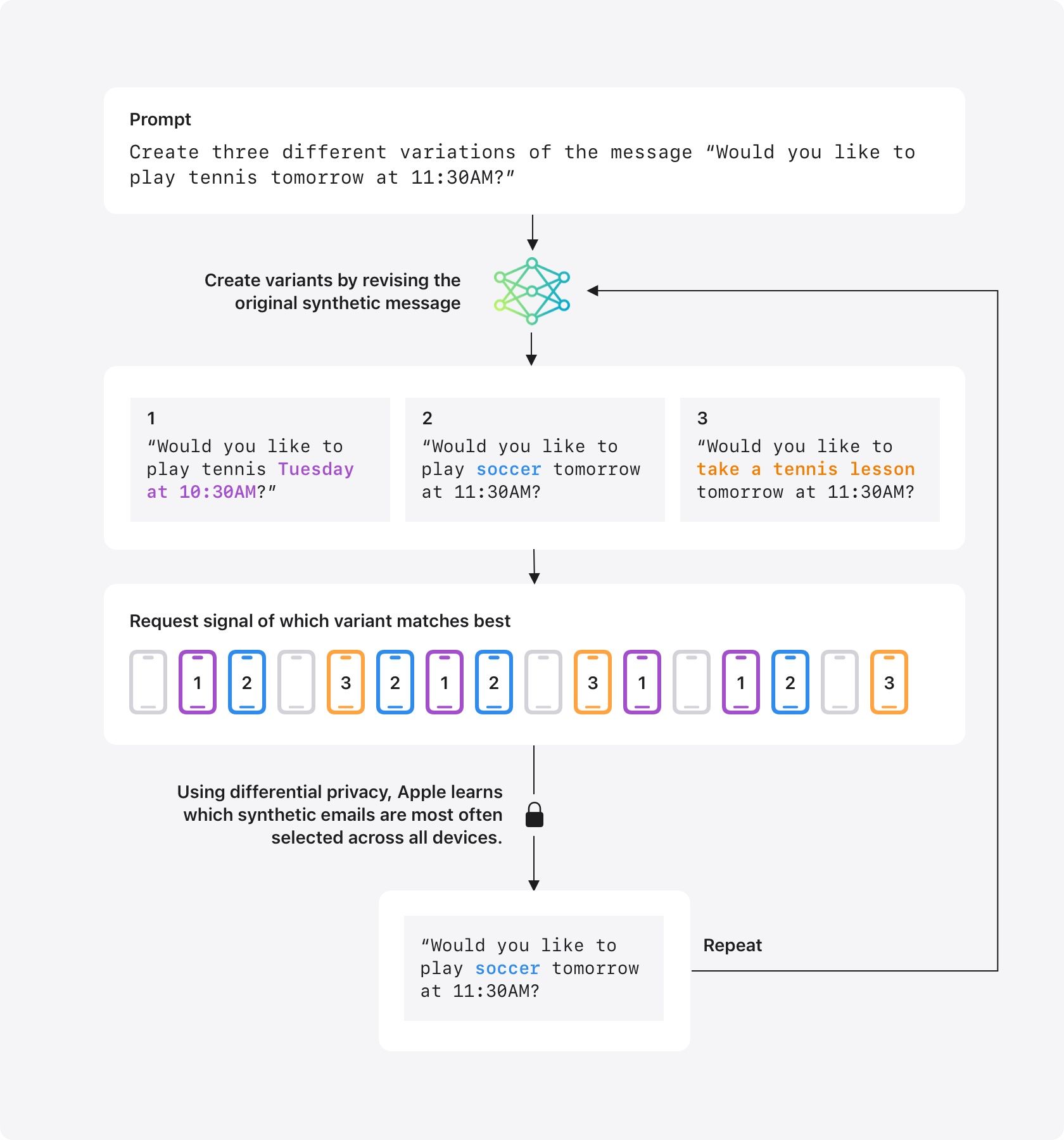
The core privacy protections we apply when creating synthetic data to improve text generation are very similar to the protections used for Genmoji. Only users who have opted-in to send Device Analytics information to Apple participate. The contents of the sampled emails never leave the device and are never shared with Apple. A participating device will send only a signal indicating which of the variants is closest to the sampled data on the device, and Apple learns which selected synthetic emails are most often selected across all devices, not which embedding was selected by any individual device. The same systems used in Genmoji are used here to determine the appropriate amount of noise and share only aggregated statistics to Apple. As a result of these protections, Apple can construct synthetic data that is reflective of aggregate trends, without ever collecting or reading any user email content. This synthetic data can then be used to test the quality of our models on more representative data and identify areas of improvement for features like summarization.
We use synthetic data to improve text generation in email in beta software releases as described above. We will soon begin using synthetic data with users who opt in to Device Analytics to improve email summaries.
Conclusion
Building on our many years of experience using techniques like differential privacy, as well as new techniques like synthetic data generation, we are able to improve Apple Intelligence features while protecting user privacy for users who opt in to the device analytics program. These techniques allow Apple to understand overall trends, without learning information about any individual, like what prompts they use or the content of their emails. As we continue to advance the state of the art in machine learning and AI to enhance our product experiences, we remain committed to developing and implementing cutting-edge techniques to protect user privacy.
Related readings and updates.
At Apple, we believe privacy is a fundamental human right. Our work to protect user privacy is informed by a set of privacy principles, and one of those principles is to prioritize using on-device processing. By performing computations locally on a userâs device, we help minimize the amount of data that is shared with Apple or other entities. Of course, a user may request on-device experiences powered by machine learning (ML) that can be enrichedâ¦
At the 2024 Worldwide Developers Conference, we introduced Apple Intelligence, a personal intelligence system integrated deeply into iOSÂ 18, iPadOSÂ 18, and macOSÂ Sequoia.
Apple Intelligence is comprised of multiple highly-capable generative models that are specialized for our usersâ everyday tasks, and can adapt on the fly for their current activity. The foundation models built into Apple Intelligence have been fine-tuned for user experiences such as writing and refining text, prioritizing and summarizing notifications, creating playful images for conversations with family and friends, and taking in-app actions to simplify interactions across apps.