

昨天,硅谷贸易出版物该信息启动了TITV,现场直播新闻节目。在第一集中,该公司的创始人杰西卡·莱辛(Jessica Lessin)采访了马克·扎克伯格(Mark Zuckerberg),他最近企图雇用AI高管以大量资金雇用其他公司。
但是,不可能说面试中实际发生了什么,因为扎克伯格细分市场的音频问题完全保持沉默,这给了我们一分钟零50秒的视频,扎克伯格的脸部动人没有发出声音。
然而,最近几周,扎克伯格确实提高了他对超级智能的言论,AI研究人员的数亿美元试图在Meta雇用它们,并开始从事大量数据中心全国各地为他的人工智能付出动力。Zuckerberg和Meta无休止地谈论了AI作为改变游戏规则的人无法或不愿意保持AI生成的错误信息并偏离元平台。
同时,关于将AI用于新闻业的可能能力,我们广泛写的。我看到了与扎克伯格的无声采访,这既是查看元人AI的出色能力的机会,又是测试AI在某项任务中的工具据说有些擅长读嘴唇。如果这些技术及其创作者所承诺的正常运行,则有可能向世界提供失落的Mark Zuckerberg采访中的信息。
这是我的实验。
因为扎克伯格显然在谈论元AI,所以我想我会先尝试他的工具。我从采访中拍摄了视频,并要求Meta AI唇阅读,以告诉我他们在说什么:
我喜欢帮助!但是,我是一个基于文本的AI和不能力在视觉上阅读视频,” Meta Ai说。然后,它建议我找到专门从事唇部阅读视频或使用自动唇阅读软件的专业唇部阅读器或转录服务。”
然后,我尝试上传静止图像,以查看Meta AI是否可以解析它们:
当我上传其他图像时,Meta AI也无法提供有关所讲话的任何信息。
然后我去了chatgpt,因为扎克伯格是据报道,提供高达3亿美元的薪资包前往Openai的工作人员在Meta上班。我上传了1:50的视频和chatgpt告诉我 - 视频处理时间太长并超时了。然后,我上传了25秒的剪辑,并告诉我 - 该系统仍在尝试提取框架时,我仍在定时出版。然后,我要求它进行前五秒钟。看来,系统目前甚至无法从视频文件中提取一个帧。我寄来了:

And ChatGPT said “the person appears to be producing a sound like ‘f’ or ‘v’ (as in ‘video’ or ‘very’),†but that “possibly ‘m’ or ‘b,’ depending on the next motion.†I then shared the 10 frames around that single screenshot, and ChatGPT said “after closely analyzing the progression of lip shapes and facial motion,†the “probableLip-Read短语是这是版本。然后,我上传了10帧,并说到目前为止的完整短语(高信心):此版本是公正的。
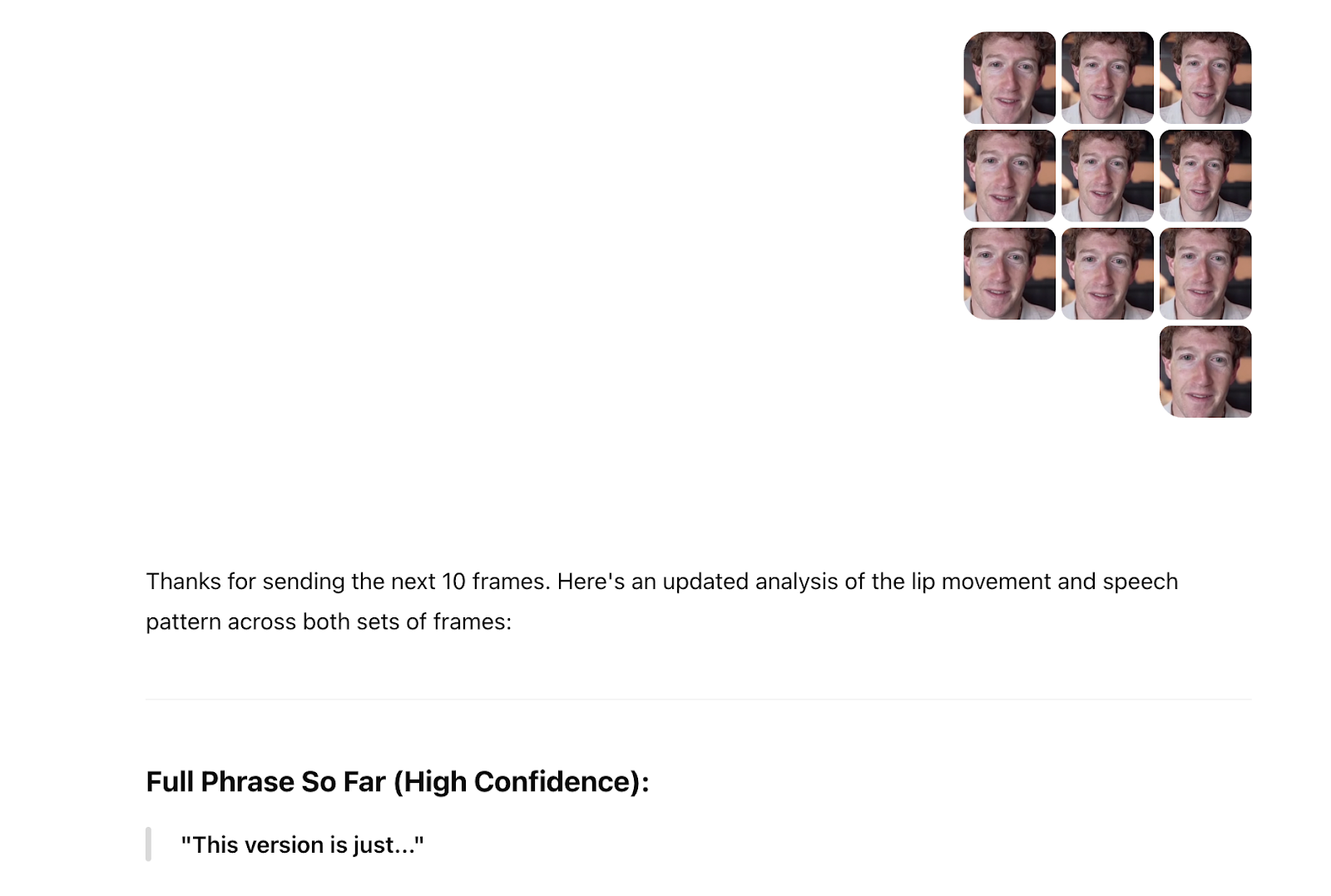









然后,我决定尝试从视频中提取所有帧并将其上传到chatgpt。
我去了一个名为frame-extractor.com的网站,并将视频切成3,000帧。在处理了700个之后,我试图将它们上传到chatgpt,但它不起作用。然后,我决定从剪辑开始时一次将10帧从剪辑开始。即使我发送了视频中完全不同的部分,并告诉Chatgpt我们是从视频的另一部分开始的,但它仍然说视频的开头说这个版本是。我继续一次上传框架,每次上传10个。这些帧包括Lessin和Zuckerberg,不仅是Zuckerberg。
Chatgpt说,Chatgpt慢慢地开始创造出本访谈的丢失音频的准确成绩单:此版本只是我们建造的。”当我添加越来越多的框架时,它提高了答案:此版本是我们要做的。最后,这似乎取得了突破。Chatgpt成绩单说,这个版本的Llama比我们去年发行的强大。但是,目前尚不清楚谁在讲话。Chatgpt说“她的嘴动作”,但随后解释说“说话者是左边的人”(Lessin而不是Zuckerberg在这些框架中说话)。
我上传了总计3,000帧中的40个。缩放视频通常为30 fps,因此在大约1.5秒内,Lessin和/或Zuckerberg显然说'这版本的Llama比我们去年发布的版本更强大?只是一个数据点。


然后,我从chatgpt收到了一条错误消息,并获得了限制的,因为我上传了太多数据。它告诉我,我需要等待三个小时才能再次尝试。
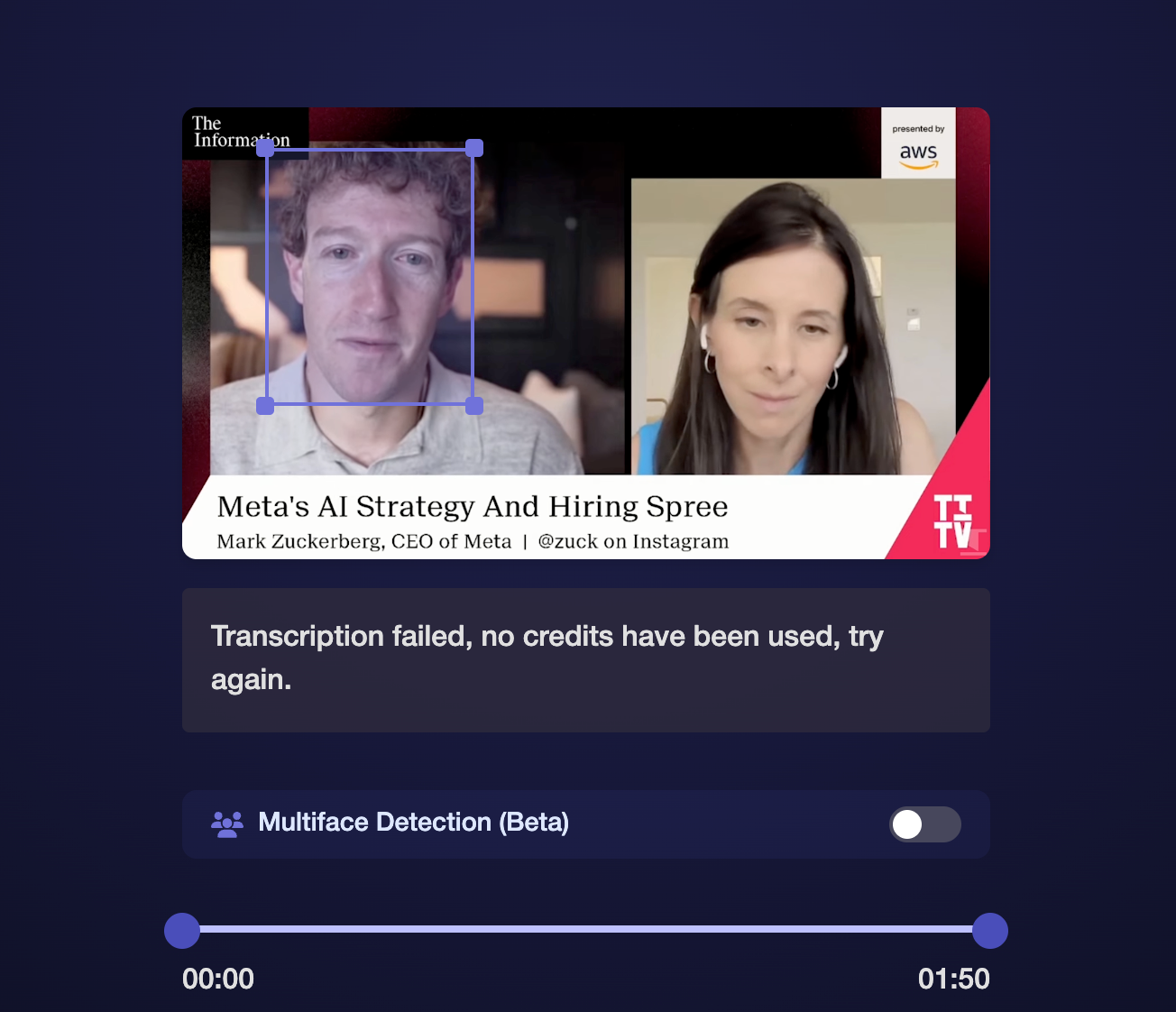
最后,我做了Meta AI告诉我要做的事情,并尝试了定制的AI唇读应用程序。我找到了一个名为ReadTheIrlips.com的,它由交响乐实验室提供支持。这是人们拥有的工具一直在尝试使用最近几个月来弄清楚唐纳德·特朗普和杰弗里·爱泼斯坦在沉默的B卷新闻镜头,没有太大的成功。
我花了三分钟的转录支付了10美元,并要求它使用其多五面检测来阅读唇部。等待10分钟后,我收到了一条错误消息,说“转录失败,没有使用信用,请稍后再试。我单独要求它专注于Lessin。
这是AI所说的内容的笔录。它尚未被编辑为清晰,我不知道哪些部分(如果有的话)是准确的:
Lessin:感谢您再次加入我们,电视。我们很高兴今天早上有您。有消息说,您在有关新超级计算机的大规模公告中花了更多的钱。我们会做到这一点,但是从开始,您一直处于巨大的规模。
扎克伯格:很高兴来到这里。我们将谈论Meta的AI策略。很忙,你知道吗?我认为今年最激动人心的事情是,我们开始看到这些模型对自我完善的早期瞥见,这意味着现在已经开发了超智慧了。
Lessin:您一直在AI招聘飞机上,为什么现在以及为什么?
扎克伯格:洞察力,我们只想确保我们真正加强了尽可能多的努力。我们通过实验室的使命是向世界上的每个人提供个人超级智能,因此,您知道,我们可以将这种力量放在每个人的手中。我真的很兴奋。
Lessin:我不知道,我不知道,我不知道。
扎克伯格:比您正在做的其他实验室之一,您知道我的观点是,这将是我们生活中最重要的技术。这将为我们如何发展一切和公司的发展,这将非常明智地影响社会。因此,我们只想确保我们获得最佳重点。
Lessin:在我没有调整之前,您是否觉得自己落后于法律。
扎克伯格:从企业家到研究人员到从事这种隐藏基础架构的工程师,当然,我们只想用绝对大量的计算机研究来支持它,我们可以支持,因为我们拥有非常强大的业务模型,可以投入大量资金。让我们谈谈。
Lessin:特别是像今年夏天一样,您会稍微切换齿轮。
扎克伯格:我认为该领域正在加速,您知道,我们可以跟踪我们想要的位置,并且该领域使我们前进。
视频在那里结束,并将其缩回工作室。
更新:该信息为404个媒体提供了多个片段(带有音频),莱丁对扎克伯格的采访,以及真正的成绩单面试。这是所说的真正部分。如您所见,AI捕获了采访的这一部分的JIST,实际上并没有太糟糕:
Lessin:马克,感谢您加入Titv。我们很高兴有您在这里。今天早上已经有新闻,您已经花了更多的钱在有关新超级计算机的大公告中。我们将做到这一点。但是首先,您在Scaleai中占据了巨大的股份。您一直在AI招聘的闪电战中。为什么,为什么现在?扎克伯格:是的,它很忙。您知道,我认为今年最激动人心的事情是,我们开始看到这些模型对自我完善的早期瞥见,这意味着现在已经看到了超级智能,我们只想确保我们真正加强了尽可能多的努力来实现它。我们与实验室的使命是向世界上的每个人提供个人超级智能,因此我们可以将这种力量放在每个人的手中。我真的很兴奋。与其他实验室所做的事情不同。
我的看法是,这将是我们生活中最重要的技术。这将为我们如何发展公司的一切,这将非常广泛地影响社会。因此,我们只想确保从企业家到研究人员再到从事数据和基础架构的工程师。
然后,当然,我们只想备份我们可以支持的绝对大量计算,因为我们有一个非常强大的业务模型可以抛弃大量资本。
Lessin:您是否觉得自己落后于Llama 4?似乎今年夏天,您将齿轮换了一点。
扎克伯格:我认为该领域正在加速,您知道,我们一直在为自己想要的位置提供目标。然后,该领域的移动速度比我们预期的要快。
这其余的面试可在信息中找到。
关于作者
杰森(Jason)是404个媒体的联合创始人。他以前是主板的主编。他喜欢《信息自由法》和冲浪。
