
图片:您的团队刚刚收到了10,000个客户反馈响应。传统方法?数周的手动分析。但是,如果AI不仅可以分析此反馈,还可以验证自己的工作,该怎么办?欢迎来到世界大语言模型(LLM)使用亚马逊基岩。
随着越来越多的组织拥抱生成的AI,特别是针对各种应用程序的LLM,已经出现了一个新的挑战:确保这些AI模型的输出与人类的观点保持一致,并且与业务环境相关。大型数据集的手动分析可能是耗时,资源大量的,因此不切实际。例如,根据评论长度,复杂性和研究人员分析,手动审查2,000条评论可能需要80多个小时。LLM提供了一种可扩展的方法,可作为定性文本注释者,摘要,甚至评估来自其他AI系统的文本输出的法官。
This prompts the question, “But how can we deploy such LLM-as-a-judge systems effectively and then use other LLMs to evaluate performance?â€
在这篇文章中,我们强调了如何在亚马逊基岩指示LLM模型创建文本响应的主题摘要(例如向客户的开放调查问题),然后使用多个LLM模型作为陪审团来审查这些LLM生成的摘要,并分配评分以判断摘要标题和摘要描述之间的内容对齐。此设置通常称为LLM陪审团系统。将LLM陪审团视为AI法官的小组,每个人都带来了自己的观点来评估内容。多个模型不依赖单个模型的潜在偏见观点,而是共同提供了更加平衡的评估。
问题:分析文本反馈
您的组织会收到成千上万的客户反馈响应。根据您收到的自由文本评论的数量,对响应的传统手册分析可能会艰苦而大量的资源花费数天或几周。替代性自然语言处理技术虽然可能更快,但还需要大量的数据清理和编码知识来有效地分析数据。预先训练的LLM提供了一种有希望的,相对低的代码解决方案,用于快速从基于文本的数据中生成主题摘要,因为这些模型已被证明可以扩展数据分析并减少手动审核时间。但是,当依靠单个预训练的LLM进行分析和评估时,就会出现对偏见的担忧,例如模型幻觉(即产生不准确的信息)或确认偏差(即有利于预期的结果)。如果没有交叉验证机制,例如将多个模型的输出或基准测试与经过人工评估的数据进行比较,未检查错误的风险会增加。使用多个预训练的LLM可以通过提供强大而全面的分析来解决这一问题,甚至允许实现人类的监督,并在单模评估中提高可靠性。使用LLMS作为陪审团的概念是指部署多个生成AI模型来独立评估或验证彼此的输出。
解决方案:在亚马逊基岩上的法官时部署LLM
您可以使用亚马逊基岩比较各种边界基础模型(FMS),例如人类的Claude 3十四行诗,,,,亚马逊诺瓦专业人士, 和Meta的Llama 3。统一亚马逊网络服务(AWS)环境和标准化的API调用简化了用于主题分析和判断模型输出的多个模型。亚马逊基岩还通过统一的安全性和合规性控制系统以及所有模型的模型部署环境来解决运营需求。
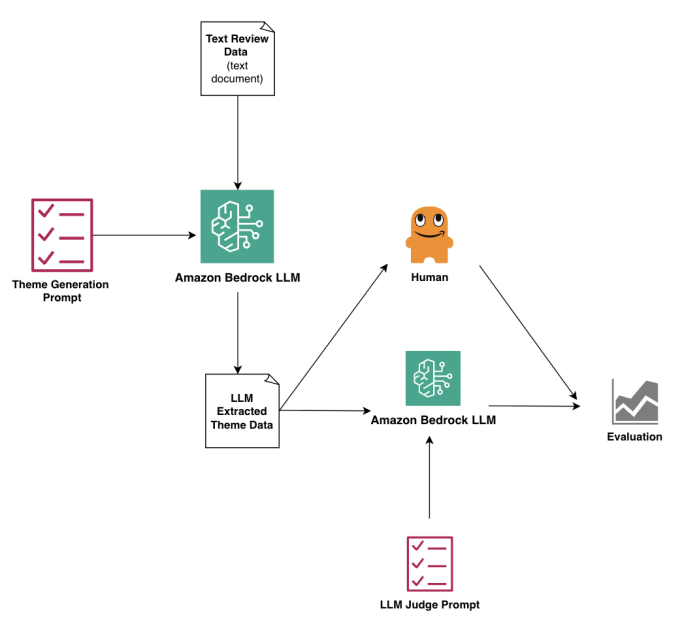
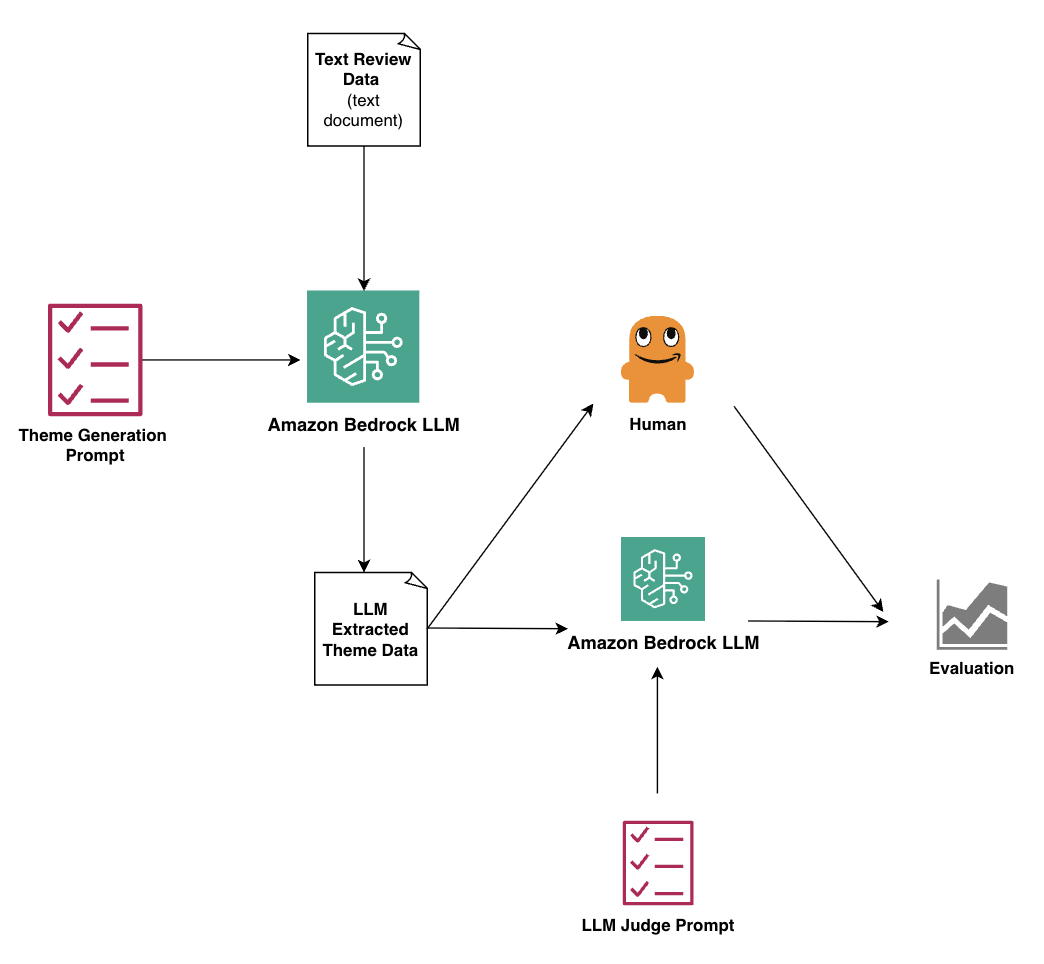
我们提出的工作流程如下图所示,包括以下步骤:
- 预处理的原始数据是在.txt文件中准备的,并将其上传到亚马逊基岩中。设计和测试主题发电提示,然后运行数据和提示亚马逊射手制片厂使用预先训练的LLM。
- LLM生成的摘要将转换为.txt文件,并将汇总数据上传到SageMaker Studio。
- 接下来,制定和测试了LLM-AS-A-A-A-A-A-A-A-Gudge提示,并使用不同的预训练的LLM在Sagemaker Studio中运行摘要数据和提示。
- 然后,将人为法官分数与模型性能进行统计比较。我们使用百分比协议,科恩·卡帕(Cohen s Kappa),,,,Krippendorff的Alpha, 和斯皮尔曼的Rho。
先决条件
要完成这些步骤,您需要拥有以下先决条件:
- 一个AWS帐户,可访问:
- 亚马逊基岩查看亚马逊基岩入门。
- 亚马逊sagemaker AI查看Amazon Sagemaker AI入门
- 亚马逊简单存储服务(亚马逊S3)查看Amazon S3入门
- Python和Jupyter笔记本的基本理解
- 预处理文本数据进行分析
实施详细信息
在本节中,我们将带您完成分步实现。
通过下载自己尝试一下Github的Jupyter笔记本。
- 创建一个Sagemaker笔记本实例要运行分析,然后初始化Amazon Bedrock并在Amazon S3上配置输入和输出文件位置。保存您喜欢在S3存储桶中作为.txt文件分析的文本反馈。使用以下代码:
导入boto3进口JSON#初始化我们与AWS服务的连接BedRock = boto3.client('Bedrock')s3_client = boto3.client('s3')#配置我们将存储我们的证据(数据)的位置bucket ='my-example-name'raw_input ='feffback_dummy_data.txt'output_themes ='feffback_analyzed.txt'- 在亚马逊基岩中使用Amazon Nova Pro来生成基于LLM的主题摘要,以进行您要分析的反馈。根据您的用例,您可以使用亚马逊基岩提供的任何或多种型号进行此步骤。此处提供的提示也是通用的,需要为您的特定用例调整以提供数据的LLM模型,以实现适当的主题分类:
def Analyze_comment(评论):提示= f“”“”您必须仅使用有效的JSON对象响应。分析此客户评论:“ {comment}”用这种确切的JSON结构做出回应:{{“ main_theme”:“这里的主题”,“ sub_theme”:“此处的子主题”,“理由”:“这里的理由”}}}”“”#通过基岩调用预训练的模型响应= bedrock_runtime.invoke_model(ModelID =#选择模型去这里身体= json.dumps({{“提示”:提示,“ max_tokens”:1000,“温度”:0.1})))返回parse_response(响应)- 现在,您可以使用多个LLM作为陪审团来评估LLM在上一步中生成的主题。在我们的示例中,我们使用Amazon Nova Pro和Anthropic的Claude 3.5十四行诗模型来分析每个反馈的主题并提供对齐得分。在这里,我们的对齐得分在1 -3的范围内,其中1表示主题的一致性较差,其中主题捕获了主要要点,2表示部分对齐,其中主题捕获了一些但并非全部关键点,而3表示主题准确捕获主要点:
def evaluate_alignment_nova(评论,主题,子主题,理由):Judge_prompt = f“”“速率主题对齐(1-3):评论:“ {评论}”主要主题:{主题}子主题:{subtheme}理由:{理性}”“”#在附带的笔记本中完成代码- 当您获得LLM的对齐分数时,在这里如何实施以下协议指标来比较和对比分数。在这里,如果您获得了人类法官的评分,则可以快速将其添加为另一组分数,以发现人类评分(黄金标准)与模型的近对齐程度:
def calculate_agreement_metrics(ratings_df):返回 {“百分比协议”:calculate_percentage_agreement(ratings_df),'Cohens Kappa':calculate_pairwise_cohens_kappa(ratings_df),'krippendorffs alpha':calculate_krippendorffs_alpha(ratings_df),'Spearmans rho':calculate_spearmans_rho(ratings_df)}我们使用以下流行协议指标来比较模型和模型之间的一致性和性能:
- 百分比协议百分比协议告诉我们,有两个评分者提供了相同事物的相同评分(例如1â5),例如两个人提供电影的5星级等级。他们同意的次数越多,越好。这表示是通过将总协议除以评级总数和乘以100的总协议来评估和计算得出的案件总数的百分比。
- 科恩·卡帕(Cohen s Kappa)Cohen的Kappa本质上是百分比协议的更明智的版本。就像当两个人猜测他们的5个同事中有多少人每天都会在办公室里穿蓝色时。有时,两个人都偶然地猜测相同的数字(例如1â5)。科恩(Cohen)的卡帕(Kappa)考虑了两个人的同意,除了任何幸运的猜测之外。系数范围从1到+1,其中1代表完美的一致性,0代表相当于机会的一致性,负值表示一致性少于机会。
- 斯皮尔曼的Rho斯皮尔曼(Spearman)的Rho就像数字的友谊仪。它显示了两组数字相处或一起移动的程度。如果一组数字上升,另一组也增加了,则它们具有积极的关系。如果一个人在另一个倒下时上升,他们会有负相关关系。系数范围从1到+1,值接近±1表示相关性更强。
- Krippendorff的AlphaKrippendorff的Alpha是一种测试,用于确定所有评估者对某事的同意。想象一下,有两个人在餐厅品尝不同的食物,并以1的比例对食物进行评分。Krippendorff的Alpha提供了一个分数,即使他们没有品尝餐厅里的每道菜,两人也对他们的食物评级达成了多少同意。α系数范围从0到1,其中值接近1表示评估者之间的一致性更高。通常,高于0.80的alpha表示强有力的一致性,α在0.67至0.80之间表示可接受的协议,而α低于0.67表示较低的协议。如果以这样的理由计算出(1、2和3)是有序的,那么Krippendorff的Alpha不仅认为一致,而且考虑分歧的幅度。与Kappa相比,它受到边际分布的影响较小,并在排名(序数)时提供了更细微的评估。也就是说,尽管百分比一致性和Kappa平等地对待所有分歧,但Alpha认识到次要的差异(例如,与2相比1)和主要分歧(例如,与3)之间的差异。
成功!如果您跟进,现在您已成功部署了多个LLM,以判断LLM的主题分析输出。
其他考虑因素
为了在运行此解决方案时帮助管理成本,请考虑以下选项:
- 使用Sagemaker托管现场实例
- 用大型数据集实施批处理处理亚马逊基岩批次推理
- 缓存中间结果Amazon S3
对于敏感数据,请考虑以下选项:
- 在所有S3存储桶中启用静止加密
- 使用AWS身份和访问管理(IAM)的角色,最低要求的权限
- 实施亚马逊虚拟私人云(Amazon VPC)增强安全性的端点
结果
在这篇文章中,我们演示了如何使用Amazon Bedrock无缝使用多个LLM来生成和判断定性数据的主题摘要,例如客户反馈。我们还展示了如何比较来自调查响应数据的基于文本的摘要的人类评估者评分与来自人类claude 3 Sonnet,Amazon Nova Pro和Meta s llama 3的评级的评级。最近发表的研究,亚马逊科学家表明,LLMS显示出高达91%的模型一致性,而人与模型的一致性高达79%。我们的发现表明,尽管LLM可以大规模提供可靠的主题评估,但人类的监督对于确定LLM可能会错过的微妙的上下文差异仍然至关重要。
最好的部分?通过Amazon Bedrock模型托管,您可以在所有模型中使用相同的预处理数据比较各种模型,因此您可以选择最适合您的上下文和需求的模型。
结论
随着组织转向生成AI来分析非结构化数据,本文提供了有关使用多个LLMS验证LLM生成分析的价值的洞察力。LLM-AS-A-Audge模型的强劲表现为大规模扩展文本数据分析的机会开放,亚马逊基地可以帮助组织与组织互动并使用多个模型使用LLM-AS-A-A-a-a-gudge框架。
关于作者
 Sreyoshi Bhaduri博士是亚马逊的高级研究科学家。目前,她率先在规模上应用生成AI来解决复杂的供应链物流和运营挑战。她的专业知识跨越了弗吉尼亚理工大学的博士学位以及MILA负责AI的专业培训,应用了统计数据和自然语言处理。Sreyoshi致力于使用AWS技术弥补理论研究和实际应用之间的差距,并弥合理论研究的差距和民主化。
Sreyoshi Bhaduri博士是亚马逊的高级研究科学家。目前,她率先在规模上应用生成AI来解决复杂的供应链物流和运营挑战。她的专业知识跨越了弗吉尼亚理工大学的博士学位以及MILA负责AI的专业培训,应用了统计数据和自然语言处理。Sreyoshi致力于使用AWS技术弥补理论研究和实际应用之间的差距,并弥合理论研究的差距和民主化。
 娜塔莉·佩雷斯(Natalie Perez)博士专门研究使用生成AI来实现客户见解和创新解决方案的变革方法。纳塔莉(Natalie)此前曾在AWS上开创了员工研究,驱动产品和程序化改进的大规模声音。娜塔莉(Natalie)致力于革新组织如何通过策略性地集成生成的AI和人类在环境策略的策略整合来扩展,理解和采取行动,从而推动创新,从而使客户成为产品,计划和服务开发的核心。
娜塔莉·佩雷斯(Natalie Perez)博士专门研究使用生成AI来实现客户见解和创新解决方案的变革方法。纳塔莉(Natalie)此前曾在AWS上开创了员工研究,驱动产品和程序化改进的大规模声音。娜塔莉(Natalie)致力于革新组织如何通过策略性地集成生成的AI和人类在环境策略的策略整合来扩展,理解和采取行动,从而推动创新,从而使客户成为产品,计划和服务开发的核心。
 约翰·基托卡(John Kitaoka)是Amazon Web Services(AWS)的解决方案建筑师,并与政府实体,大学,非营利组织和其他公共部门组织一起设计和扩展AI解决方案。他的工作涵盖了广泛的机器学习(ML)用例,对推理,负责人AI和安全性具有主要兴趣。在业余时间,他喜欢木工和单板滑雪。
约翰·基托卡(John Kitaoka)是Amazon Web Services(AWS)的解决方案建筑师,并与政府实体,大学,非营利组织和其他公共部门组织一起设计和扩展AI解决方案。他的工作涵盖了广泛的机器学习(ML)用例,对推理,负责人AI和安全性具有主要兴趣。在业余时间,他喜欢木工和单板滑雪。
 伊丽莎白(Liz)Conjar博士是亚马逊的首席研究科学家,她在人力资源研究,组织转型和AI/ML的交汇处开创了他的开拓者。她专门研究人员分析,帮助重新想象员工的工作经验,推动高速组织变革,并发展下一代亚马逊领导者。在她的整个职业生涯中,伊丽莎白(Elizabeth)在将复杂的人分析转化为可行的策略方面一直是思想领袖。她的工作着重于通过数据驱动的见解和创新的技术解决方案来优化员工经验并加速组织成功。
伊丽莎白(Liz)Conjar博士是亚马逊的首席研究科学家,她在人力资源研究,组织转型和AI/ML的交汇处开创了他的开拓者。她专门研究人员分析,帮助重新想象员工的工作经验,推动高速组织变革,并发展下一代亚马逊领导者。在她的整个职业生涯中,伊丽莎白(Elizabeth)在将复杂的人分析转化为可行的策略方面一直是思想领袖。她的工作着重于通过数据驱动的见解和创新的技术解决方案来优化员工经验并加速组织成功。