
智能文档处理(IDP)是一项技术,可以自动化从广泛文档中提取,分析和解释关键信息的提取,分析和解释。通过使用高级机器学习(ML)和自然语言处理算法,IDP解决方案可以从非结构化文本中有效提取和处理结构化数据,从而简化以文档为中心的工作流程。
当使用生成AI功能增强时,IDP使组织能够通过高级理解,结构化数据提取和自动分类来转换文档工作流程。生成的AI驱动IDP解决方案可以更好地处理传统ML模型以前从未见过的各种文档。该技术组合在多个行业中都具有影响力,包括子女抚养服务,保险,医疗保健,金融服务和公共部门。传统的手动处理会产生瓶颈并增加错误风险,但是通过实施这些高级解决方案,组织可以显着提高其文档工作流程效率和信息检索功能。AI增强的IDP解决方案改善了服务交付,同时减轻了各种文档处理方案的管理负担。
这种文档处理方法可提供可扩展,高效和高价值的文档处理,从而提高了生产率,降低成本和增强的决策。拥有生成AI增强IDP力量的企业可以从提高效率,增强的客户体验和加速增长中受益。
在博客文章中使用亚马逊基岩的可扩展智能文档处理,我们演示了如何使用拟人化基础模型构建可扩展的IDP管道亚马逊基岩。尽管这种方法表现出色,但引入亚马逊基岩数据自动化为IDP解决方案带来了新的效率和灵活性。这篇文章探讨了亚马逊基岩数据自动化如何增强文档处理功能并简化自动化之旅。
亚马逊基岩数据自动化的好处
亚马逊基础数据自动化引入了几个功能,可显着提高IDP解决方案的可伸缩性和准确性:
- 置信度得分和边界数据数据 亚马逊基础数据自动化提供了置信分数和边界数据,从而增强了数据的解释性和透明度。借助这些功能,您可以评估提取信息的可靠性,从而导致更明智的决策。例如,较低的置信度得分可以表明需要进行额外的人类审查或对特定数据字段的验证。
- 快速发展的蓝图Amazon Bedrock数据自动化提供了预构建的蓝图,可简化文档处理管道的创建,从而帮助您快速开发和部署解决方案。亚马逊基岩数据自动化提供了灵活的输出配置,以满足各种文档处理要求。对于简单的提取用例(OCR和布局)或文档中文本的线性化输出,您可以使用标准输出。对于定制的输出,您可以从头开始设计独特的提取模式,或者将目录中的预配置蓝图作为起点。您可以根据您的特定文档类型和业务需求来自定义蓝图,以获取更具针对性和准确的信息检索。
- 自动分类支持亚马逊基础数据自动化将文档拆分并匹配到适当的蓝图,从而导致精确的文档分类。这种聪明的路由减轻了对手动文档进行分类的需求,大大减少了人类干预和加速处理时间。
- 正常化亚马逊基岩数据自动化通过其全面的归一化框架解决了常见的IDP挑战,该框架可以处理关键的归一化(将各种现场标签映射到标准化名称)和值归一化(将提取的数据转换为一致的格式,单位和数据类型)。这种归一化方法有助于减少数据处理的复杂性,因此组织可以自动将原始文档提取到标准化数据中,以使其与现有系统和工作流程更加平稳地集成。
- 转型Amazon Bedrock数据自动化转换功能通过自动将组合信息(例如地址或名称)自动分配为离散的,有意义的组件,将复杂的文档字段转换为结构化的,可用于业务的数据。此能力简化了组织如何处理各种文档格式,帮助团队定义了与其现有数据库模式和业务应用程序相匹配的自定义数据类型和现场关系。
- 验证Amazon Bedrock数据自动化通过使用提取数据的自动验证规则,支持数字范围,日期格式,字符串模式和跨场检查来增强文档处理精度。此验证框架可帮助组织自动确定数据质量问题,在需要时触发人类评论,并确保提取的信息在进入下游系统之前符合特定的业务规则和合规性要求。
解决方案概述
下图显示了使用Amazon Bedrock数据自动化以及AWS步骤功能和亚马逊增强了AI(Amazon A2I)为文档处理工作负载提供了具有成本效益的缩放,以提供不同尺寸的工作负载。
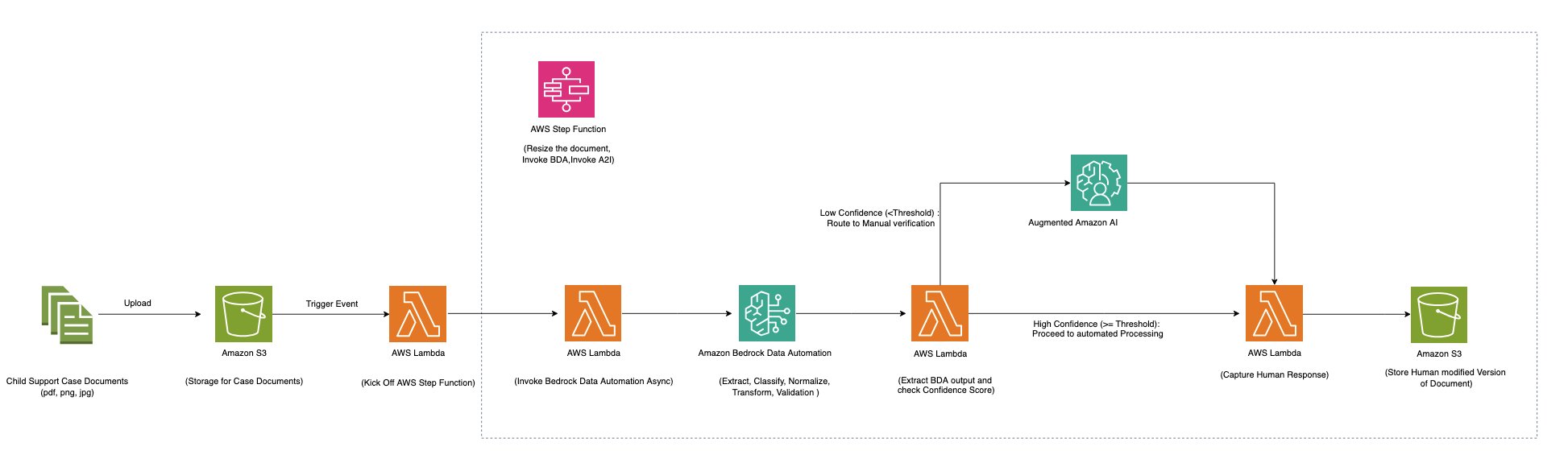
步骤功能工作流程使用Amazon Bedrock数据自动化处理多种文档类型,包括乘法PDF和图像。它在单个项目中使用各种亚马逊基岩数据自动化蓝图(标准和自定义)来处理多种文档类型,例如免疫文档,运输税证书,儿童支持服务注册表格和驾驶执照。
Workflow通过以下步骤处理包含单个文档或多个文档的文件(PDF,JPG,PNG,TIFF,DOC,DOCX):
- 对于多页文档,沿逻辑文档边界拆分
- 将每个文档与适当的蓝图匹配
- 应用蓝图的特定提取说明来从每个文档中检索信息
- 根据蓝图中指定的指令对提取的数据进行归一化,转换和验证
步骤功能地图状态用于处理每个文档。如果文件达到置信度阈值,则将输出发送到亚马逊简单存储服务(亚马逊S3)桶。如果任何提取的数据均低于置信度阈值,则该文档将发送到Amazon A2I进行人类审查。审阅者使用Amazon A2I UI,其中包括所选字段的边界框突出显示来验证提取结果。当人类评论完成后,回调任务令牌用于恢复状态机,并通过人工评估的输出发送到S3存储桶。
将此解决方案部署到AWS帐户,遵循随附的步骤GitHub存储库。
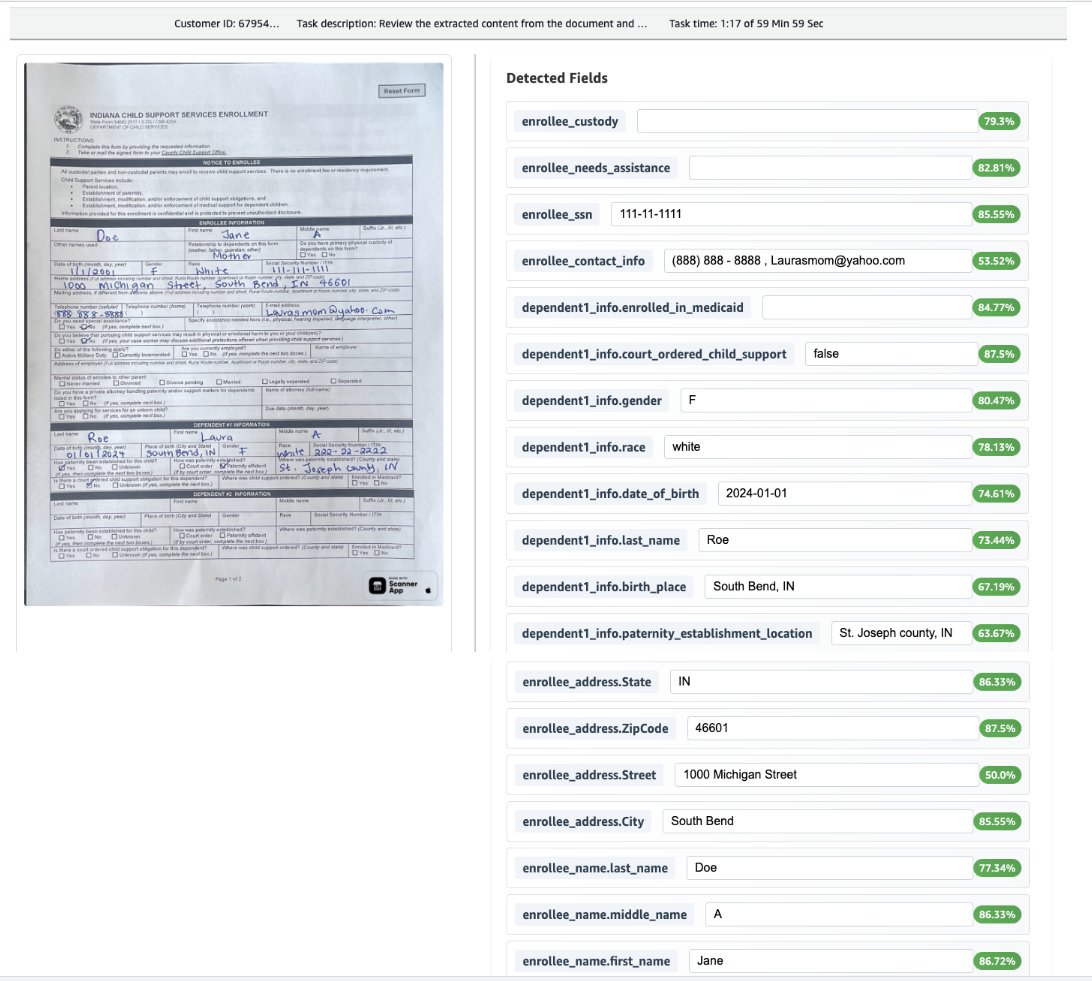
在以下各节中,我们使用儿童支持注册表格审查了使用此解决方案部署的特定亚马逊基础数据自动化功能。
自动分类
在实施中,我们为创建的每个自定义蓝图定义了文档类名称,如以下屏幕截图所示。当处理多种文档类型(例如驾驶执照和子女抚养注册表格)时,系统会根据内容分析自动应用适当的蓝图,确保为每种文档类型使用正确的提取逻辑。

数据归一化
我们使用数据归一化来确保下游系统接收均匀格式的数据。我们使用两个显式提取(对于文档中可见的清晰明说的信息)和隐式提取(对于需要转换的信息)。例如,如以下屏幕截图所示,出生日期标准化为yyyy-mm-dd格式。

同样,社会安全号码的格式将其更改为XXX-XX-XXXX。
数据转换
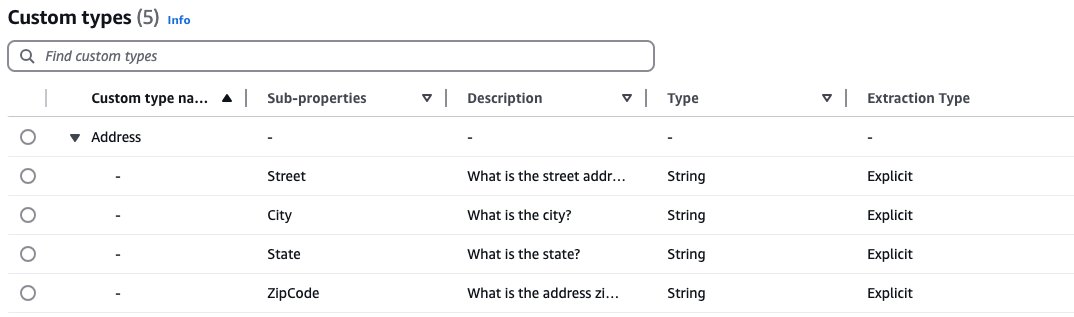
对于儿童支持注册应用程序,我们实施了自定义数据转换,以使提取的数据与特定要求一致。一个示例是我们用于地址的自定义数据类型,该数据类型将单线地址分解为结构化字段(街道,城市,州,Zipcode)。这些结构化字段在注册表格(雇主地址,家庭地址,其他父母地址)的不同地址字段中重复使用,从而与现有系统进行一致的格式和直接集成。
数据验证
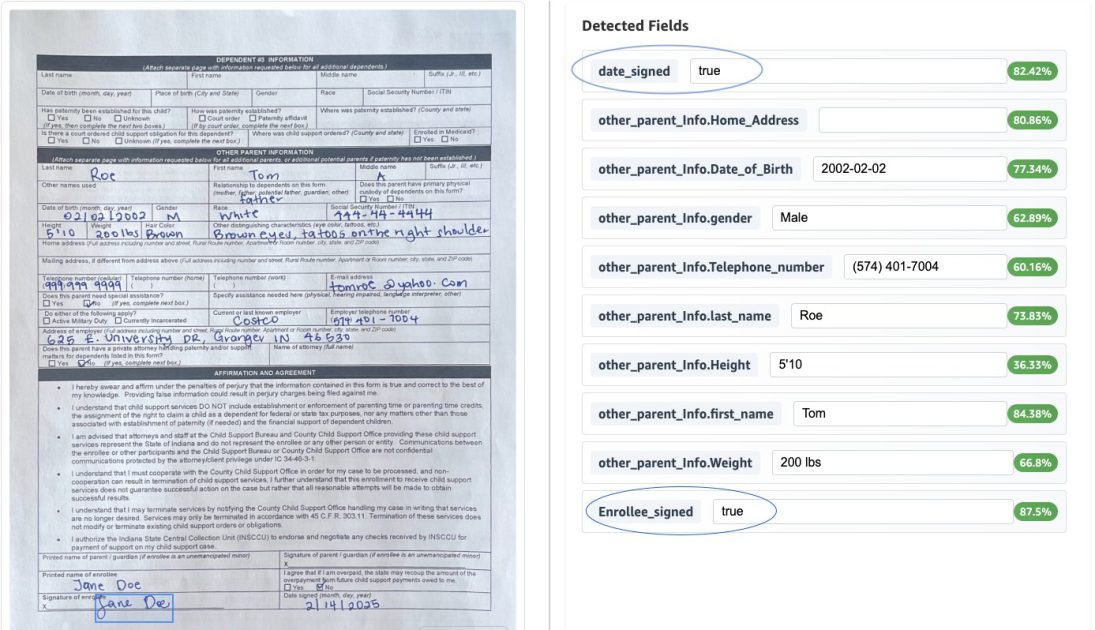
我们的实施包括维持数据准确性和合规性的验证规则。对于我们的示例用例,我们实现了两个验证:1。验证注册人的签名和2。

以下屏幕截图显示了应用于文档的上述验证规则的结果。
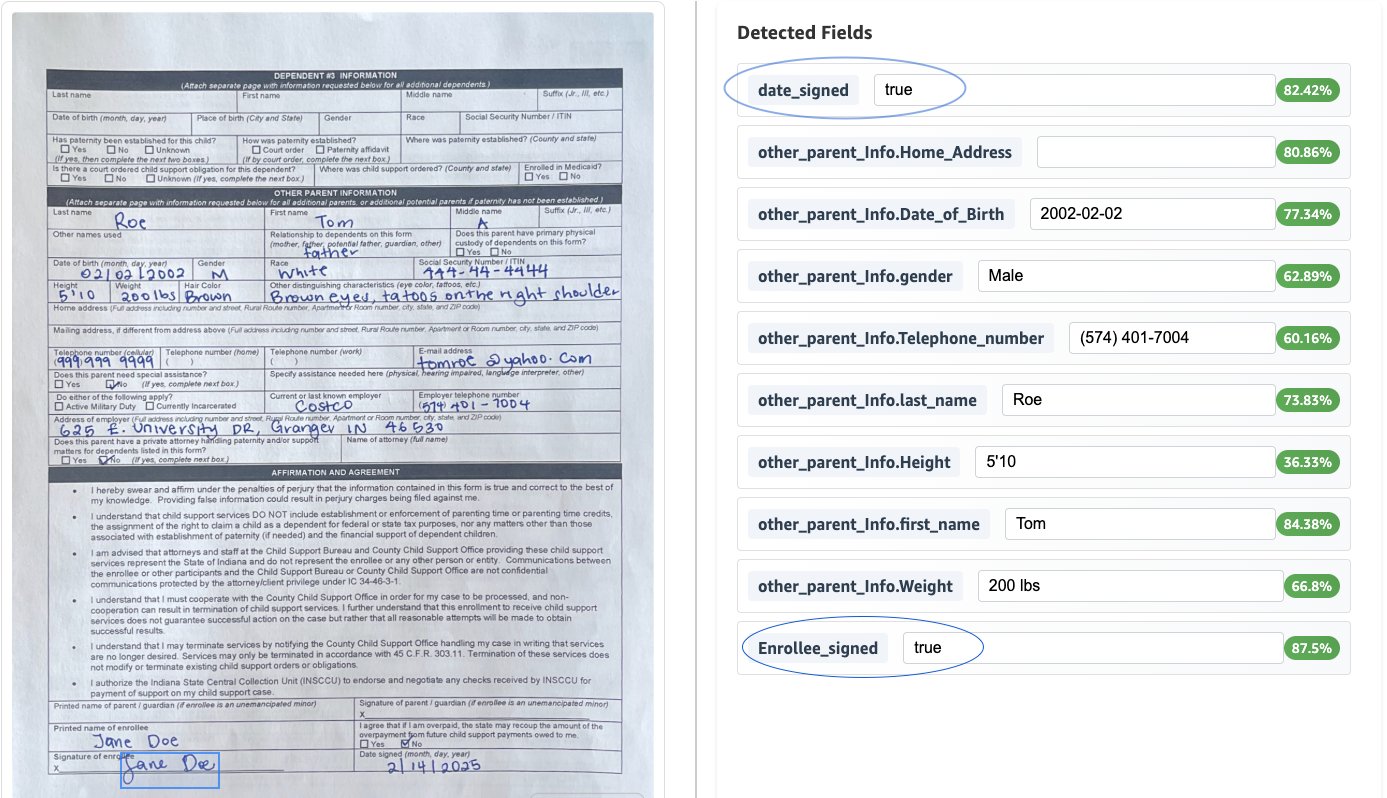
人类在环境验证
以下屏幕截图说明了提取过程,其中包括置信度评分,并与人类的过程集成在一起。它还显示了适用于出生日期的归一化。
结论
亚马逊基石数据自动化通过引入信心评分,边界数据,自动分类和通过蓝图快速开发来显着提高IDP。在这篇文章中,我们演示了如何利用其高级功能来进行数据归一化,转换和验证。通过升级到亚马逊基石数据自动化,组织可以大大减少开发时间,提高数据质量,并创建与人类审查过程集成的更强大,可扩展的IDP解决方案。
跟随AWS机器学习博客要了解Amazon基岩的新功能和用例。
关于作者
 阿卜杜勒·纳瓦兹(Abdul Navaz)是总部位于得克萨斯州达拉斯的亚马逊Web服务(AWS)健康和公共服务团队的高级解决方案建筑师。他拥有超过10年的AWS经验,专注于使用AWS服务的儿童抚养费和儿童福利机构的现代化解决方案。在担任解决方案建筑师的角色之前,Navaz曾是一名高级云支持工程师,专门从事网络解决方案。
阿卜杜勒·纳瓦兹(Abdul Navaz)是总部位于得克萨斯州达拉斯的亚马逊Web服务(AWS)健康和公共服务团队的高级解决方案建筑师。他拥有超过10年的AWS经验,专注于使用AWS服务的儿童抚养费和儿童福利机构的现代化解决方案。在担任解决方案建筑师的角色之前,Navaz曾是一名高级云支持工程师,专门从事网络解决方案。
 Venkata Kampana是亚马逊Web服务(AWS)健康和公共服务团队的高级解决方案建筑师,总部位于加利福尼亚州的萨克拉曼多。在此职位上,他帮助公共部门的客户通过AWS实现了良好的解决方案来实现其任务目标。
Venkata Kampana是亚马逊Web服务(AWS)健康和公共服务团队的高级解决方案建筑师,总部位于加利福尼亚州的萨克拉曼多。在此职位上,他帮助公共部门的客户通过AWS实现了良好的解决方案来实现其任务目标。
 Sanjeev Pulapaka是主要解决方案建筑师和公共部门的AI领导。Sanjeev是一位发表的作者,有几个博客和一本关于生成AI的书。他还是包括RE:Invent和Summit在内的几个活动中的著名演讲者。Sanjeev拥有印度理工学院的工程学士学位,并拥有巴黎圣母院的MBA学位。
Sanjeev Pulapaka是主要解决方案建筑师和公共部门的AI领导。Sanjeev是一位发表的作者,有几个博客和一本关于生成AI的书。他还是包括RE:Invent和Summit在内的几个活动中的著名演讲者。Sanjeev拥有印度理工学院的工程学士学位,并拥有巴黎圣母院的MBA学位。