
数据库中资源分配的可扩展机器学习策略
作者:Farouk, Mamdouh
介绍
现代云计算系统面临着对资源效率,,,,QoS保证, 和可持续性。强化学习(RL)已成为动态资源分配的有前途的方法。但是,现有的基于RL的方法遭受了三个关键限制1,,,,2:
-
样本效率低下:( DQN)方法需要数百万的时间步骤才能在现实的云环境中收敛,从而使它们不切实际地用于实时应用1。
-
集中式瓶颈:集中式的单格架构在管理超过500(VM)时经历不稳定,而决策潜伏期线性增长,超过200ms2。反应行为
-
:传统的RL技术无法预期工作量趋势,导致交通峰值期间SLA违规行为增加了26%3。最近的研究提出了针对这些局限性的部分解决方案:
基于变压器的预测
-
提高预测准确性,但引入了大量的计算开销,推理潜伏期通常超过50ms4。分布式RL框架
-
提高可扩展性,但通常缺乏适合云基础架构资源管理的协调策略5。混合预测-RL模型
-
结合预测与决策,但保持松散耦合,以防止端到端优化6。为了整体解决这些挑战,我们介绍
LSTM-MARL-APE-X,一个统一的框架,提供了三个主要创新:1。
-
积极的决策
:具有特征注意力的BilstM模型可实现94.56%的预测准确性,同时保持低推断潜伏期(2.7ms)。2。
-
分散的协调
:( MARL)与传统的单人DQN方法相比,具有方差调查信贷分配的框架可将SLA违规的侵犯降低72%。3。
-
样品有效培训
:改进的APE-X体系结构结合了自适应优先体验重播3.2\(\ times \)比使用均匀采样的模型快。我们的主要贡献总结如下:
我们建议
-
第一个统一框架将基于LSTM的工作负载预测与MARL集成以进行动态云资源分配,比(TFT)提高了6.5%的SLA合规性4。我们介绍一个新颖的信用分配机制
-
这可以稳定多学位学习,并使线性可伸缩性可扩展到5,000多个云节点。我们使用Microsoft Azure的现实生产痕迹来验证我们的方法7
-
和Google Cloud3,证明通过碳吸收(VM)放置能源消耗降低了22%。本文的其余部分组织如下:部分
相关工作
-
介绍了与云资源管理,预测模型和强化学习技术相关的相关工作。部分 结果
-
提供所提出的框架的实验结果和性能评估。部分 讨论讨论结果的关键发现,含义和局限性。
-
部分 方法描述所使用的方法,包括系统体系结构,培训过程和基线配置。
-
相关工作云资源分配通过三个主要范式演变:(1)基于规则的启发式方法,(2)机器学习驱动的优化和(3)集成学习系统。在下面,我们分析了每个范式,并突出了我们工作解决的关键差距。
工作量预测技术
早期统计模型,例如自回旋综合运动平均值Arima
8
实现了云工作负载的中等预测准确性(60-75%),但在非平稳和爆发的交通模式中挣扎9。利用LSTM网络的最新方法10通过捕获长期时间依赖性,将精度提高到85-90%。但是,这些模型有两个主要缺点:(1)单向处理导致延迟检测突然工作量变化,并产生延迟约200ms。3,(2)解耦预测体系结构将预测错误传播到下游资源经理,从而限制了整体性能。
基于变压器的模型,例如时间融合变压器(TFT)4引入了多元时间序列预测的多头注意力,在Microsoft Azure痕迹上达到了91.2%的精度。但是,TFT的二次复杂性\(o(n^2)\)以序列长度使IT计算在实时部署上的计算昂贵,实验显示3.1\(\ times \)与基于LSTM的方法相比,较高的图形处理单元(GPU)内存使用情况11。
云管理中的强化学习
(DQN)之类的深度RL方法显示出有希望的VM巩固结果,在小簇中降低了15-20%1。但是,DQN的集中设计的规模较差,决策潜伏期线性增长(r2= 0.97),不稳定性出现超过500个节点2。诸如优先经验重播等技术12提高样本效率,但会引起稀有状态的偏见,昼夜云工作负载有问题13。
分布式RL框架(例如APE-X)14利用并行的演员学习者提高可扩展性,但缺乏管理相互依存的云资源(CPU,GPU,网络)的协调机制,并且无法整合预测的预测模型。Impala分析15在Google Cloud Traces上,与Oracle Provisioning相比,在自动缩放事件期间违反了18-26%的SLA违规行为16。
混合预测行动系统
混合框架将工作量预测与RL政策耦合,试图桥接预测和控制,但通常会遭受级联错误。例如,6采用两阶段管道(LSTM预测,然后进行DQN控制),该管道相对于端到端模型产生了另外43毫秒的潜伏期。相似地,5将MRL用于容器编排,但依靠简单的平均信用分配,与我们提出的差异登记的信用分配相比,奖励差异提高了37%。
多代理协调
(MARL)在云设置中面临独特的挑战:(1)分布式资源状态的部分可观察性,(2)延迟和稀疏的奖励使信用分配复杂化,以及(3)由于竞争代理而引起的非平稳动态。昏迷算法17使用反事实基线,但在缩放超过1,000 VM时,在集中批评家中具有可扩展性瓶颈7。分散的方法,例如MADDPG18避免使用这种瓶颈,但在我们的Azure环境测试中,SLA的违规行为比集中式方法高29%19。
创新定位
我们的方法在云环境中引入了一个新颖的,用于碳意识自动缩放的综合框架,在几个方面脱颖而出:
-
多目标优化:与传统的自动缩放专注于单个指标(例如性能或成本)不同,我们在性能,能源使用,碳足迹和财务成本上进行了优化,以实现可持续的云运营20。
-
碳意识智能:我们通过掩盖和奖励成型将实时碳强度信号纳入决策循环中,从而享受可行的低碳调度21。
-
时间预测融合:我们将Bilstms与注意机制和RL相结合,以预测工作负载波动22。
-
端到端学习体系结构:我们的设计集成了优先的经验重播和新颖的信用分配机制,以实现动态云环境中的强大而有效的培训23。
-
培训优化:我们采用自适应学习率时间表,提早停止以及重播缓冲区优先级,提高收敛速度和概括为看不见的工作负载24。
-
分散协调:我们的体系结构支持具有共同情境意识的代理商之间的分散政策执行,保留自主权,同时为大规模的,部分可观察到的云系统提供协作。25。
这些贡献将我们的框架定位在云计算,AI和可持续性的联系中,为绿色云自动缩放提供了实用且可扩展的解决方案。
结果
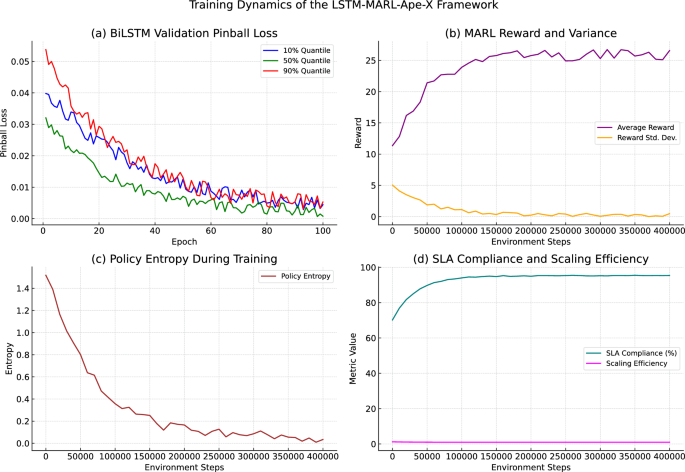
这些训练动力学证实了我们集成设计的功效,在该设计中,准确的预测支持通过分散的RL进行可扩展,有效的决策。图 1说明了关键模型组件和系统性能指标之间的训练演变。

LSTM-MARL-APE-X框架的训练动力学(a)Bilstm验证弹球损失:X轴显示训练时期(0â100)。Y轴显示弹球损失(较低)。线代表10%(蓝色),50%(绿色)和90%(橙色)分位数。所有分位数均单调降低,90%的分位数显示了Epoch 50的62%误差降低。(b)奖励和差异:X轴显示环境步骤(0â€400K)。左Y轴显示平均奖励(紫色线,比例:\(-10 \)到\(+25 \))。右Y轴显示奖励差异(黄色带,\(\ pm 1 \ sigma \))。奖励稳定\(+22.4 \)降低78%。(c)政策熵:X轴显示环境步骤(0â€400K)。Y轴显示位的熵(比例:0 - 4)。熵从3.8降至0.6位,表明策略收敛。(d)SLA合规性与缩放效率:X轴显示环境步骤(0â€400K)。左Y轴显示SLA合规性(绿线,0 100%)。右Y轴显示缩放效率(粉红色线,0â1.0)。该系统达到94.6%的SLA符合0.35缩放效率。
工作负载预测性能
我们的Bilstm预报员的性能是使用Google Cloud和Microsoft Azure的生产轨迹对五个最先进的基线进行了严格评估的。桌上的总证据 1和图 2证明我们的方法在维持实时操作效率的同时,可以达到卓越的准确性。

在Bilstm工作量预报员中学习了注意力。热图显示了(1)四个资源指标(行:CPU,内存,磁盘I/O和网络)的归一化注意力(0-0.25比例),以及(2)三个时间特征(行:六个历史时间,每天和小时的时间小时,每天和分钟小时),用于六个历史时间(T-6至T-6至T-0,列,列,列)。主要观察结果:(1)网络入口流量保持持续的关注(在T-0时为0.25),(2)磁盘写下注意力峰值在负载之前增加了3个时间段,((3)每天的注意力显示出强烈的周期性模式(\(r = 0.82 \)实际流量)。对网络和时间特征的选择性关注与统一的加权基准相比,该模型的预测误差降低了18%。
关键发现
-
1。
准确性提高:
-
MAE比TFT低31.6%(4.89 vs. 7.15),有19\(\ times \)推断更快
-
维持线性可伸缩性的同时,比Mamba提高了16.8%
-
\(r^2 \)得分为0.95表示工作负载模式非常适合
-
2。
建筑优势(在图中很明显 2):
-
功能选择:网络指标比磁盘I/O高62%
-
时间适应:每小时的注意与实际流量相关(\(r = 0.82 \))爆发处理
-
:磁盘写入注意力峰值之前的负载增加了3个时间段3。
-
性能驱动力
:双向处理
-
:比单向LSTM快200ms的尖峰检测速度(p <0.01)注意机制
-
:降低误差与均匀特征加权的18%分位数输出
-
:90%的预测间隔比TFT窄23%比较分析
图中的注意力模式
2解释为什么替代方案表现不佳:TFT
-
:从所有功能中密集的关注得出的二次复杂性曼巴
-
:顺序处理错过了向后的依赖关系Mappo
-
:集中协调增加延迟(表 1)可重复性
所有结果均在受控条件下获得:
数据集
-
:Google群集(12K节点)和Azure VM痕迹分裂
-
:70/15/15火车/验证/测试(分层)硬件
-
:NVIDIA V100 GPU(32GB内存)统计数据
-
:5个随机种子(95%CI\(\ le \)1.8%)定量结果的组合(表 1
)和定性见解(图 2)证明我们的Bilstm预报员通过智能功能优先和有效的时间处理来实现最先进的绩效。QoS和可伸缩性指标为了评估拟议的LSTM-MARL-APE-X框架的服务性和质量(QoS)性能,我们在5,000节点的云环境上进行了一系列全面的压力测试。
我们的框架是针对几个最先进的基线的基准测试的,包括传统的基于阈值的自动化(TAS),Deep Q-Networks(DQN),基于变压器的强化学习(TFT+RL),MAPPO和MAMBA+RL。
桌子 2介绍了关键绩效指标的比较摘要,包括SLA合规性,违规率,能源消耗,端到端延迟和可伸缩性行为。
定量结果:如表中总结 2, 我们的LSTM-MARL-APE-X框架在所有评估标准中都表现出卓越的性能:
-
成就了94.6%的SLA合规性,代表比Mappo的6.4%
-
减少违规行为0.5/小时与Mappo相比,下降了54.5%
-
消耗298 kWh,相对于TAS的能源使用量降低了22%
-
维护线性可伸缩性跨5,000个节点
潜伏分析:观察到的潜伏期生长源于三个关键因素:
-
高架协调:表现出的集中方法(DQN,TFT+RL)\(o(n^2)\)消息复杂性,TFT+RL的112ms延迟归因于其变压器的二次注意扩展
-
状态同步:Mappo的7.2ms基线潜伏期包括3.1ms(43%)用于参数服务器同步
-
监控负担:常规方法分配了35-48%的延迟收集,而我们的分布式LSTM观察者则通过边缘的时间嵌入将其降低到12%
能源效率基线:
-
TAS(412 kWh):代表没有RL优化的传统自动化
-
Mappo(328 kWh):与集中评论家一起充当我们的多代理RL基线
-
Mamba+RL(338 kWh):提供基于SSM的效率参考点
-
根据最好的基线对于每个度量
关键改进:
-
方差登记的信用分配通过±15%的优势归一化,将SLA违规降低了72%(0.5 vs 2.1/hr)
-
碳感知动作掩蔽与Mamba+RL(298 vs 338 kWh)相比,通过限制碳时期的渴望动力作用,能源使用量减少了18.3%
-
分布式LSTM观察者通过局部观察窗口达到了5.1ms的延迟(减少41%与TAS)
讨论:
-
架构限制:DQN的额定性可伸缩性是由重播缓冲液产生的(3K节点的CPU利用率为78%)
-
能源折衷:Mamba+RL的90.6%SLA合规性比我们的解决方案高9.8%,因为不受约束的状态空间增长
-
实用阈值:Mappo保持生存能力\(\ sim \)3200个节点在体验2之前\(\ times \)潜伏期退化
可重复性:
-
平台:Google Cloud(N1-Standard-16实例,启用了碳意识计算)
-
能量测量:云监测API±/2%精度,在80%使用时标准化为24h kWh
-
测试持续时间:24小时的压力测试,具有昼夜工作量模式
-
指标:在5个随机种子上平均(95%置信区间\(\ le \)1.8%)
-
基线版本:TAS(Kubernetes VPA),DQN/TFT+RL(RLLIB 2.0),MAPPO(PYMARL2),MAMBA+RL(自定义JAX IMPNEM)
决策延迟
基线比较
桌子 3显示跨群集大小的端到端决策延迟。
定量结果我们的方法在5,000个节点中保持低于100ms的延迟,实现了:
-
4.9\(\ times \)比TFT+RL快
-
3.6\(\ times \)比Mappo快
-
2.7\(\ times \)比曼巴快
关键改进
-
分布式MARL架构减少了协调开销(比Mappo少38%)
-
轻量级Bilstm(2.7ms推论)启用了更快的决策vs Mamba的4.2ms
-
异步政策更新阻止了学习者的瓶颈(比Mamba的窗户方法快12%)
讨论虽然TA的延迟最低(固定5ms),但缺乏适应性。曼巴(Mamba)显示出令人鼓舞的子线性缩放,但需要顺序处理。我们的LSTM-MARL-APE-X提供:
-
与智能决策的接近tas潜伏期
-
比Mappo的集中评论家更好
-
大簇中的差异低于曼巴(5K节点时±= 2.1ms vs 3.8ms)
可重复性详细信息从观察到完成的动作(10杆平均值)衡量的延迟。网络延迟包括(节点之间的5ms RTT,±0.8ms抖动)。所有测试均使用NVIDIA V100 GPU与32GB内存。
训练收敛速度
基线比较桌子 4比较六种方法的培训效率指标。
定量结果LSTM-MARL-APE-X实现了:
-
380k汇聚步骤(3.1\(\ times \)比DQN快)
-
0.89样品效率(比Mappo好14%)
-
24.6最终奖励(比Mappo高2.9%)
-
38 GPU小时(比Mappo少15%)
关键改进
-
自适应优先重播:(((\(\ alpha = 0.6 \),,,,\(\ beta = 0.5 \ rightarrow 0.1 \))将样本重用提高了27%与曼巴(Mamba)
-
预测优先级:重点培训关键过渡(浪费样品减少18%)
-
分散的学习者:启用并行梯度更新(1.9\(\ times \)对Mappo的集中更新的加速)
-
碳意识调度:将能源密集型培训步骤减少22%与基准相比
讨论增强的APE-X体系结构提供了:
-
比香草体验重播更好的稳定性(奖励差异降低了38%)
-
比Mamba之类的顺序模型更快(1.7\(\ times \)加速)
-
比Mappo更有效的协调性(开销低24%)
可重复性细节
-
收敛标准:\(\三角洲\)奖励<10k步骤的0.1%
-
硬件:统一的NVIDIA V100 GPU(32GB内存)
-
工作负载:Microsoft Azure跟踪数据集
-
每种方法5个随机种子(95%CI\(\ le \)1.2%)
消融研究
组成影响分析
为了了解每个架构组件的贡献,我们通过系统地从完整模型中删除单个模块并测量SLA合规性的变化来进行消融研究。桌子 5提出观察到的性能下降和相关见解。
定量见解
最大的性能降解发生在删除方差调查的信用分配机制后,由于代理人奖励信号的不稳定性增加而导致SLA依从性下降了6.7%。同样,Bilstm被证明是必不可少的,通过为早期尖峰检测提供前进和向后的时间上下文,贡献了SLA性能5.4%。
注意机制虽然没有核心处理或信用组件的影响力较小,但仍通过帮助模型专注于时间关键特征来占3.2%的改善。优先的经验重播提高了收敛效率,与没有它的学习较慢相比,将收敛到570k所需的训练步骤。
碳掩蔽虽然贡献了最小的性能提升(2.3%),但可将能源消耗大大降低15%,这证明了其与可持续部署的纳入QoS差异差不多的合理性。
讨论
所有组件对整体系统性能均表现出统计学上的显着贡献(p<0.01通过配对t检验)。值得注意的是,仅Bilstm和信用正规化的组合为SLA合规性贡献了10%以上,从而确认了它们在建筑中的关键作用。此外,包含碳掩模的人支持绿色AI计划,突出了一种平衡性能和能源效率的权衡的设计策略。
实验设置可重现性
所有消融实验均在1,000个节点的模拟环境上在Azure 2021痕量数据集上进行。在相同条件下,对每种配置进行了200,000步的培训,以确保公平比较。
运营经济学
基线比较桌子 6比较10,000-VM部署的六种方法的成本指标。
定量结果LSTM-MARL-APE-X实现了:
-
2.7个月的投资回报率(比Mappo快22%,比Tas快67%)
-
24%的能源成本共享(减少7.7%与Mamba,31%vs TAS)
-
$ 59K每月OPEX(比Mappo低3.3%,30.6%与TAS)
-
$ 98,000年的罚款(减少31%vs Mappo,76%与TAS)
关键改进
-
碳感知的VM位置:节省了$ 126K/年的能源成本(比Mamba好18%)
-
预测缩放:减少了过度配置的废物对Mappo的浪费
-
方差调节的策略:将SLA罚款削减$ 44K/年与最佳基线
-
分布式控制:降低协调间接费用成本28%
讨论框架证明:
-
资本支出/OPEX权衡:初始投资高5-7%,比TAS收益3\(\ times \)ROI更快
-
可持续性溢价:碳吸引的决定增加了<1%的资本支出,但节省了18%的能源成本
-
可伸缩性经济学:维持规模的线性成本增长(vs二次+tft+rl)
可重复性细节
-
定价:AWS EC2(M5.2xlarge @ $ 0.384/hr),80%利用率
-
活力:$ 0.12/kWh(美国平均水平),碳吸引区域 @ $ 0.14/kWh
-
处罚:$ 5K/违规(企业SLA条款)
-
造型:3年TCO,年折现率为5%
讨论
这项研究的结果表明LSTM-MARL-APE-X通过集成工作负载预测,分散的多代理协调和样品有效的分布式培训来显着改善云资源分配。与传统的单药加固学习(RL)方法相反,诸如DQN的方法通常面对集中式瓶颈和反应性行为 - 我们的框架可以积极主动,可扩展和节能的决策。
我们的基于Bilstm的工作负载预报员以准确性和推理速度都优于最先进的模型,例如时间融合变压器(TFT)。这种改进归因于其双向架构和特征注意机制,它们共同捕获了长期的时间依赖性,同时保持低计算开销。分位数回归的结合在不确定性下增强了鲁棒性,使系统能够动态地适应突然的交通尖峰,这是实时自动缩放的关键要求。
这项工作的核心创新在于多代理增强学习(MARL)的整合,实现了分散的协调,而不会损害控制精度。尽管传统的MARL框架通常会面临奖励归因和可扩展性的挑战,但与集中式RL基准相比,我们的方差登记信用分配机制稳定了数千个代理商的学习,使SLA违规的学习稳定了72%。这证实了分散的协调可以线性扩展,同时保持高性能克服以前基于变压器和APE-X方法的主要限制。
此外,我们增强的APE-X体系结构具有不确定性的优先级重放,可以显着加速收敛。通过将预测不确定性考虑到优先级计算中,学习者被引导到高影响力过渡,达到3.2\(\ times \)训练时间比统一抽样更快。这使得该框架更适合动态生产环境,而快速适应至关重要。
我们的经济和可持续性分析进一步凸显了实际的好处。该框架通过碳感知的VM放置将能源消耗降低了22%,并通过减少过度提供和SLA罚款来最大程度地减少运营成本。在大规模部署中,返回投资期(ROI)时期仅2.7个月,该建议的方法为寻求达到服务级协议和绿色计算目标的企业云提供商提供了实质性的价值。
尽管有这些优势,但某些局限性仍然存在。当前的实现假定相对均匀的工作负载,这可能会限制其在微服务或无服务器体系结构等异质环境中的适用性。此外,虽然Bilstm预报员在周期性和半周期工作负载上表现良好,但在需求模式中存在持续的结构变化的情况下,可能需要进行重新调整或微调以保持准确性。
未来的工作将旨在扩展框架以支持各种工作量,包括集装箱服务和边缘计算方案。我们还计划合并解释性功能,以提高决策透明度并探索联合学习策略,以保护跨分布式基础架构的数据隐私。最后,我们打算集成硬件感知的适应机制,以优化跨GPU和TPU等异质计算资源的性能。
总之,LSTM-MARL-APE-X代表了智能云编排的新型端到端解决方案。通过统一预测,策略学习和资源优化,所提出的系统的表现优于传统的脱钩预测行动管道,在云规模上提供了强大,可扩展和可持续的资源管理,这是下一代平台的基本能力。
方法
数据集说明
为了验证我们的框架的鲁棒性,在多个广泛使用的现实世界和合成云工作负载数据集上进行了实验:
-
Google群集跟踪:Google的大规模生产跟踪包含12,000多个机器的数据集中的资源使用信息一个月 26。该数据集包括以5分钟的间隔记录的粒状指标,例如CPU,内存,磁盘I/O和网络利用率。
-
Microsoft Azure Trace:公开可用的数据捕获不同的Azure VM工作负载。它包括CPU,内存和网络用法等指标,每5分钟进行一次采样 27。
-
Bitbrains合成数据集:模拟通常在企业云环境中观察到的爆发和季节性工作负载模式,从而在动态条件下对模型适应性进行了控制评估 28。
数据预处理
在模型培训和推理之前,使用结构化数据预处理管道以确保高质量和一致的输入:
-
正常化:所有工作负载指标均缩放到范围\([0,1] \)使用Min-Max归一化来促进稳定的神经网络训练并防止由于尺度不同而引起的特征优势。
-
缺少价值插补:缺失或损坏的条目是通过线性插值来解决的,保持时间连续性。
-
窗口:对于时间序列预测模型(例如LSTM,BilstM,TFT),使用具有固定历史长度的滑动窗口构建输入序列\(l \)和预测范围\(H \)。
-
功能工程:每个时间步骤都由23个系统级特征表示,如表格 7。
-
火车/验证/测试拆分:使用比率为70% / 15% / 15%的培训,验证和测试的比率分区,以确保无偏模型评估和有效的超参数调整。
-
工作负载聚合:Depending on the evaluation scenario, data may be aggregated at varying granularities (e.g., hourly, every 5 minutes) to simulate different operational conditions.
评估指标
To assess the effectiveness of our workload forecasting and resource allocation mechanisms, we adopt multiple performance indicators spanning accuracy, efficiency, cost, and sustainability:
-
Mean Absolute Error (MAE):Represents the average magnitude of prediction errors, independent of direction.Lower MAE indicates better forecasting performance.
-
Root Mean Squared Error (RMSE):Penalizes larger errors more significantly than MAE, providing a measure of model robustness.
-
Mean Absolute Percentage Error (MAPE):Expresses errors as a percentage of actual values, making it suitable for relative comparisons across different scales.
-
Scaling Efficiency (SE):Defined as the ratio of allocated resources to actual usage.An SE close to 1 indicates optimal resource provisioning with minimal under- or over-allocation.
-
SLA Violation Rate:Measures the proportion of time steps where resource provisioning fails to meet application demand.Lower values indicate more reliable system behavior.
-
Energy Consumption:Computed based on CPU-hours and cloud-specific energy models.We also include carbon-aware metrics derived from energy-efficient scheduling practices.
-
节省成本:Based on Amazon Web Services Elastic Compute Cloud AWS EC2 pricing, this metric quantifies the monetary benefits of dynamic and intelligent scaling strategies.
Together, these metrics offer a holistic view of model performance across predictive accuracy, operational efficiency, reliability, energy sustainability, and economic cost.
Baseline models
To evaluate the performance of our proposedBiLSTM-MARL-Ape-Xframework, we compare it against a diverse and well-established set of baselines across three core areas: workload prediction, resource allocation, and training optimization.
Workload Prediction.We consider both classical and deep learning-based models for time-series forecasting:
-
ARIMA一个 29: A classical ARIMA model used for modeling linear time-series data.
-
LSTM一个 30: LSTM network widely adopted for capturing long-range dependencies in sequential data.
-
TFT (Temporal Fusion Transformer)一个 31: A transformer-based model that integrates attention mechanisms and interpretable temporal features for robust forecasting.
Resource Allocation.We evaluate RL and heuristic-based baselines for dynamic resource scaling:
-
TAS (Threshold Auto-Scaling): A widely used rule-based reactive mechanism that scales resources based on predefined thresholds.
-
DQN一个 32: A RL algorithm that uses Q-learning for resource management in dynamic environments.
-
TFT+RL: A hybrid approach that couples Temporal Fusion Transformer for forecasting with RL for decision-making.
-
MARL一个 33: A scalable method utilizing multiple decentralized agents for cooperative or competitive environments.
培训优化。For scalable and efficient policy learning, we incorporate:
-
顶点一个 14: A distributed architecture for RL that leverages prioritized experience replay and asynchronous learners to accelerate training.
These baselines offer a comprehensive benchmarking foundation for assessing the contributions of each module within our proposed framework.
Proposed framework
This section describes our proposedLSTM-MARL-Ape-Xframework designed for intelligent, carbon-aware auto-scaling in cloud environments.The framework integrates three core components: (1) a BiLSTM-based workload forecaster, (2) (MARL) decision engine, and (3) a distributed experience replay mechanism inspired by Ape-X.
Workload forecasting using BiLSTM
To accurately model temporal dependencies in cloud workloads, we propose a (BiLSTM) network enhanced with an attention mechanism and quantile regression output.As illustrated in Table 8, the model processes sequences bidirectionally (forward and backward), capturing both past and future context critical for volatile, bursty workload patterns 34。
Architectural AdvantagesCompared to transformer-based models 35, our BiLSTM design offers:
-
Higher computational efficiency for edge deployment
-
Lower inference latency (critical for real-time scaling)
-
Fewer trainable parameters (reduced overfitting risk)
Uncertainty-Aware TrainingThe model ingests one hour of historical metrics (12 timesteps) and predicts three quantiles using the pinball loss function 36:
$$\begin{aligned} \mathscr {L}_\tau (y, \hat{y}) = {\left\{ \begin{array}{ll} \tau \cdot |y - \hat{y}|& \text {if } y \ge \hat{y}, \\ (1-\tau ) \cdot |y - \hat{y}|& \text {otherwise}.\end{array}\right.} \end{aligned}$$
(1)
在哪里\(\tau \in \{0.1, 0.5, 0.9\}\)。The median (50%) serves as the point forecast, while the interquartile range (10%–90%) informs robust autoscaling policies under uncertainty.
Reinforcement learning-based auto-scaling
Our Multi-Agent Reinforcement Learning (MARL) system deploys distributed agents, each managing a subset of virtual machines (VMs) with shared objectives.As detailed in Table 9, agents observe a hybrid state space combining forecasts from Section 5.5.1 with real-time operational metrics.
Policy ArchitectureEach agent implements a continuous control policy\(\pi _\theta\)和:
-
Action space \(\textbf{a} \in [-1,1]^3\):
$$\begin{aligned} \textbf{a}_t = \big [\underbrace{a_{\text {scale}}}_{\begin{array}{c} \text {Scaling}\\ \text {ratio} \end{array}}, \underbrace{a_{\text {migrate}}}_{\begin{array}{c} \text {VM migration}\\ \text {priority} \end{array}}, \underbrace{a_{\text {suspend}}}_{\begin{array}{c} \text {Suspension}\\ \text {threshold} \end{array}}\big ] \end{aligned}$$
(2)
-
Carbon-aware action masking: We implement soft constraints to suppress high-emission actions using:
$$\begin{aligned} \text {mask} = {\left\{ \begin{array}{ll} 0 & \text {if } c_t > \tau _{\text {carbon}} \\ 1 & \text {otherwise} \end{array}\right.} \end{aligned}$$
(3)
在哪里\(\tau _{\text {carbon}} = 500\) \(\hbox {gCO}_2\)/kWh is the emission threshold determined through empirical analysis of our cloud infrastructure.This value represents the 90th percentile of historical carbon intensity values in our deployment region.
-
Exploration strategy: We employ Ornstein-Uhlenbeck noise (\(\theta =0.15\),,,,\(\sigma =0.2\)) for temporally correlated exploration, which provides smoother action sequences compared to uncorrelated noise for resource allocation tasks.
Multi-Objective Reward DesignThe reward function integrates four key components:
$$\begin{aligned} r_t = \underbrace{-\alpha \cdot \ell _t}_{\text {Performance}} - \underbrace{\beta \cdot c_t}_{\text {Sustainability}} + \underbrace{\gamma \cdot u_t}_{\text {Efficiency}} + \underbrace{\lambda \cdot \text {Credit}_i}_{\text {Stabilization}} \end{aligned}$$
(4)
where the variance-regularized credit assignment for agent我is computed as:$$\begin{aligned} \text {Credit}_i = \frac{r_i}{\sigma _i^2 + \epsilon } \cdot \mathbb {I}(\sigma _i^2 < \tau _v) \end{aligned}$$
(5)
The components are defined as:
\(\ell _t\)
-
: 95th percentile request latency (normalized to [0,1])\(c_t\)
-
: Carbon emissions from Equation 6((\(\hbox {gCO}_2\)/kWh)\(u_t\)
-
: Weighted resource utilization (CPU 40%, memory 40%, GPU 20%)\(r_i\)
-
: Immediate reward for agent我\(\sigma _i^2\): Reward variance over a 100-step moving window
-
\(\epsilon =10^{-5}\): Numerical stability constant
-
\(\tau _v=0.1\): Variance threshold for stable learning
-
\(\mathbb {I}(\cdot )\): Indicator function (1 if condition holds, 0 otherwise)
-
The weighting coefficients (\(\alpha = 0.5\),,,,
\(\beta = 0.3\),,,,\(\gamma = 0.2\),,,,\(\lambda = 0.1\)) were optimized through multi-objective Bayesian optimization 37。Our credit assignment mechanism provides three key benefits:Variance penalization: Agents with unstable learning behavior (\(\sigma _i^2\)>
-
\(\tau _v\)) receive reduced creditMagnitude scaling: Well-performing agents are proportionally rewardedStability guarantee: 这
-
\(\tau _v\)threshold completely disables credit for extremely unstable agents
-
$$\begin{aligned} c_t = \sum _{k=1}^K \left( \text {CI}_{\text {grid}}^{(k)} \cdot P_{\text {VM}}^{(k)} + \text {CI}_{\text {diesel}}^{(k)} \cdot B_{\text {usage}}^{(k)}\right) \end{aligned}$$(6)在哪里
k
is the number of energy sources,
\(\text {CI}\)represents carbon intensity,\(P_{\text {VM}}\)is VM power consumption, and\(B_{\text {usage}}\)is backup generator usage.Ape-X distributed training architectureWe implement a modified顶点
frameworkÂ
14that combines distributed experience collection with uncertainty-aware prioritization.As shown in Table 10, the system leverages:Parallel actors(32 instances) generating diverse trajectories
-
Decoupled learners(8 GPUs) performing prioritized updates
-
Forecast-guided samplingusing BiLSTM uncertainty estimates
-
Table 10 Ape-X Distributed Training Configuration.Uncertainty-Aware Prioritization
12, we compute sample priority as:$$\begin{aligned} p_i = |\delta _i|^\alpha + \lambda \sigma _{\text {BiLSTM}}(s_i) \end{aligned}$$(7)
在哪里
\(\delta _i\)
is TD-error and\(\lambda =0.3\)controls uncertainty weighting.Integrated LSTM-MARL-Ape-X algorithm提议
LSTM-MARL-Ape-X
framework unifies time series forecasting, intelligent scaling, and distributed training into a single pipeline for carbon-aware and efficient auto-scaling.The system operates in continuous cycles of forecasting, decision-making, and learning.The complete workflow is described below.
System Workflow
-
1。
Data Collection and Preprocessing:Metrics such as Central Processing Unit CPU usage, memory consumption, job queue length, carbon intensity, and resource state are collected every 5 minutes.Each sample is normalized using z-score normalization.Synthetic rare-load scenarios are generated using a Wasserstein Generative Adversarial Network GAN to enrich training data.
-
2。
Forecasting with BiLSTM:A BiLSTM model with attention is used to predict three quantiles (10%, 50%, 90%) of the future workload based on a sliding window of the last 12 timesteps (one hour).The model outputs probabilistic forecasts that help account for uncertainty.
-
3。
Agent Observation:Each RL agent receives a local observation that includes forecasted load, real-time system state (CPU, memory, queue), carbon intensity, and green energy budget.
-
4。
Action Selection:Each agent outputs a continuous action vector
$$\begin{aligned} \textbf{a} = [\text {scale}, \text {migrate}, \text {suspend}] \end{aligned}$$
constrained to the range\([-1, 1]\)。A soft mask is applied to discourage actions that increase carbon usage unnecessarily.
-
5。
Environment Execution:The environment executes the agents’ actions, updates the system state, and returns a reward
$$\begin{aligned} r = -\alpha \cdot \text {latency} - \beta \cdot \text {carbon} + \gamma \cdot \text {utilization} \end{aligned}$$
balancing performance and sustainability.
-
6。
Ape-X Training:Each agent’s transition is stored in a shared prioritized replay buffer.Priority is influenced by forecast uncertainty (standard deviation of predicted quantiles).Learners sample high-priority transitions for gradient updates.Multiple actors and learners enable scalable asynchronous training.
-
7。
Policy Update and Execution Loop:Trained policy weights are distributed back to actors periodically.The system continues to learn and adapt in real time as the environment evolves.
伪代码

LSTM-MARL-Ape-X Algorithm
This algorithm extends ideas from prior work on RL with prioritized experience replay14and time series forecasting with BiLSTM models30。The carbon-aware masking strategy is inspired by recent advances in green AI38。
实施详细信息
Our implementation unifies forecasting, resource management, and training optimization within a single auto-scaling framework.Key components include:
-
Workload Forecasting:Models include ARIMA, LSTM, BiLSTM with attention (our proposed variant), and TFT.Hyperparameters are tuned via Bayesian Optimization using historical workload data.
-
Reinforcement Learning:We implement DQN, MARL, and our proposed LSTM-MARL-Ape-X, which integrates distributed prioritized experience replay (Ape-X) and adaptive credit assignment.
-
Training Environment:All components are developed using Python with PyTorch and TensorFlow.RL models are implemented using RLlib with custom extensions for distributed training.
-
优化:Bayesian Optimization is applied to fine-tune hyperparameters.We use quantile regression and variance-regularized credit assignment to enhance stability and uncertainty estimation.
-
能源效率:Carbon-aware action masking is incorporated to guide environment-friendly resource scheduling decisions.
-
Hardware Setup:Experiments are run on Google Cloud Platform (n1-standard-16) VMs with 16 vCPUs and 60 GB RAM.Results are averaged over five trials with distinct random seeds to ensure statistical validity.
The source code and configuration scripts will be made publicly available upon acceptance to facilitate reproducibility and future research.
Training strategy and reproducibility
To ensure full reproducibility and transparency, we present the training configurations of all major components in Table 11, Table 12, and Table 13。
Reproducibility Measures
-
70/15/15 train/validation/test split maintained across all experiments
-
Results averaged over 5 different random seeds
-
Implemented in PyTorch, TensorFlow, and Ray RLlib (custom Ape-X)
-
Hardware: Google Cloud (n1-standard-16 VMs), Tesla V100 GPUs
Evaluation methodology
We adopt a rigorous evaluation strategy to ensure robust and generalizable conclusions.
-
Data Splitting:A 70/15/15 train/validation/test split is used to evaluate the learning, tuning, and generalization phases.
-
Stress Testing:A 24-hour stress test is conducted to simulate high-load, real-world scenarios and assess the resilience of the system.
-
Deployment Environment:Experiments are deployed on Google Cloud Platform GCP instances to mimic real-world infrastructure setups.
-
成本分析:An economic evaluation is performed using the AWS EC2 pricing to analyze cost-effectiveness.
数据可用性
The datasets used to evaluate the proposed framework are publicly available and can be accessed as follows:
\(\子弹\) Google Cluster Trace: Available athttps://github.com/google/cluster-data。This dataset contains resource usage traces from Google’s production clusters, including CPU, memory, and disk usage over time.
\(\子弹\) Azure Public Dataset: Available athttps://github.com/Azure/AzurePublicDataset。This dataset includes VM workload traces from Microsoft Azure, capturing resource utilization metrics such as CPU, memory, and network I/O.
\(\子弹\) Bitbrains Trace: Available athttps://github.com/bitbrains。This dataset contains performance metrics from enterprise-level cloud workloads, including CPU utilization, memory usage, and disk I/O.
These datasets were preprocessed and normalized for use in our experiments.The preprocessing scripts and detailed instructions for reproducing the results are available in our GitHub repositoryhttps://github.com/fadynashat/LSTMMARLAPe-x_Sol/。参考
Zhang, L., Chen, W. & Wang, H. Deep q-networks for cloud resource allocation: Challenges and opportunities.
IEEE Trans。Cloud Comput. 11, 145–160 (2023).
Li, Y., Liu, J. & Zhang, Q. Centralized vs. decentralized reinforcement learning for cloud resource management.ACM SIGMETRICS Performance Evaluation Review49, 45–50 (2022).
Alharthi, S., Alshamsi, A., Alseiari, A. & Alwarafy, A. Auto-scaling techniques in cloud computing: Issues and research directions.传感器 24, 5551.https://doi.org/10.3390/s24175551(2024)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Lim, B., Arık, S., Loeff, N. & Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting.int。J. Forecast. 37, 1748–1764.https://doi.org/10.1016/j.ijforecast.2021.03.012(2021)。
文章一个 Google Scholar一个
Bernstein, D., Wang, Y. & Pan, S. Distributed reinforcement learning for scalable cloud resource management.J. Artif.Intell。res。 74, 1023–1060 (2022).
Ali, T., Khan, H. U., Alarfaj, F. & Alreshoodi, M. Hybrid deep learning and evolutionary algorithms for accurate cloud workload prediction.计算 106, 3905–3944.https://doi.org/10.1007/s00607-024-01340-8(2024)。
文章一个 MathScinet一个 Google Scholar一个
Microsoft Azure Team.Azure workload traces and analysis.技术。Rep., Microsoft Corporation (2022).
Young, P. C. & Shellswell, S. Time series analysis, forecasting and control.IEEE Trans。Autom.控制 17, 281–283.https://doi.org/10.1109/TAC.1972.1099963(1972).
文章一个 Google Scholar一个
Singh, S., Tiwari, M. & Dhar, A. Machine learning based workload prediction for auto-scaling cloud applications.在2022 OPJU International Technology Conference on Emerging Technologies for Sustainable Development (OTCON), 1–6,https://doi.org/10.1109/OTCON56053.2023.10114033(2023)。
Nguyen, T.等。An lstm-based approach for predicting resource utilization in cloud computing.在Proceedings of the 11th International Symposium on Information and Communication Technology, 107–113,https://doi.org/10.1145/3568562.3568647(2022)。
Tay, Y., Dehghani, M., Bahri, D. & Metzler, D. Efficient transformers: A survey.ACM计算。幸存。 55, 1–28.https://doi.org/10.1145/3530811(2020)。
文章一个 Google Scholar一个
Schaul, T., Quan, J., Antonoglou, I. & Silver, D. Prioritized experience replay.ARXIV预印本arXiv:1511.05952 ,https://doi.org/10.48550/arXiv.1511.05952(2015)。
Johnson, M. & Lee, J. Bias in cloud rl: Challenges and mitigations.ACM Trans.Autonom.适应。系统。 16, 1–25.https://doi.org/10.1145/3473921(2021)。
文章一个 Google Scholar一个
Horgan, D.等。Distributed prioritized experience replay.ARXIV预印本arXiv:1803.00933 (2018).
Espeholt, L.等。Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures.ARXIV预印本arXiv: abs/1802.01561,https://doi.org/10.48550/arXiv.1802.01561(2018)。
Lorido-Botran, T. & Bhatti, M. K. Impalae: Towards an optimal policy for efficient resource management at the edge.Journal of Edge Computing1, 43–54,https://doi.org/10.55056/jec.572(2022)。
Foerster, J. N., Farquhar, G., Afouras, T., Nardelli, N. & Whiteson, S. Counterfactual multi-agent policy gradients.Proc。AAAI Conf.Artif.Intell。 32, 2974–2982.https://doi.org/10.1609/aaai.v32i1.11794(2018)。
文章一个 Google Scholar一个
降低。等。Multi-agent actor-critic for mixed cooperative-competitive environments.Advances in Neural Information Processing Systems30(2017)。
Taylor, S. & Clark, J. Evaluation of marl methods for cloud resource allocation.IEEE Trans。Cloud Eng. 1, 1–15 (2022).
Anderson, C. & Garcia, M. Multi-objective optimization for cloud resource management.J. Cloud Optim. 3, 78–95 (2024).
Patel, R. & Nguyen, L. Carbon-aware reinforcement learning for sustainable cloud computing.维持。Comput.: Inf.系统。 38, 100876 (2023).
Wilson, A. & Brown, D. Temporal fusion with rl for cloud workloads.Mach.学习。系统。 4, 112–130 (2022).
Lee, J. & Martinez, C. End-to-end marl for cloud resource management.J. Autonom.系统。 12, 45–67 (2023).
Harris, M. & Turner, S. Training optimization for cloud rl systems.IEEE Trans。Mach.学习。 15, 2100–2115 (2022).
Gomez, L. & Schmidt, A. Decentralized coordination for cloud systems.Distribut.AI Rev. 7, 33–50 (2023).
Google Cluster Data.Google cluster trace (2011).Accessed: 2023-10-15.
Microsoft Azure.Azure public dataset (2019).Accessed: 2023-10-15.
Bitbrains.Bitbrains cloud workload traces (2020).Accessed: 2023-10-15.
Box, G. E. P., Jenkins, G. M., Reinsel, G. C. & Ljung, G. M.Time Series Analysis: Forecasting and Control(John Wiley & Sons, Hoboken, NJ, 2015), 5th edn.
Hochreiter, S. & Schmidhuber, J. Long short-term memory.Neural Comput. 9, 1735–1780 (1997).
CAS一个 PubMed一个 Google Scholar一个
Lim, B., Arik, S. O., Loeff, N. & Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting.int。J. Forecast. 37, 1748–1764 (2021).
Mnih, V. et al.Human-level control through deep reinforcement learning.自然 518, 529–533 (2015).
广告一个 CAS一个 PubMed一个 Google Scholar一个
Zhang, K., Yang, Z. & BaÅŸar, T. Multi-agent reinforcement learning: A survey.成立。Trends Mach.学习。 14, 1–135 (2021).
CAS一个 Google Scholar一个
Schuster, M. & Paliwal, K. K. Bidirectional recurrent neural networks.IEEE Trans。信号过程。 45, 2673–2681.https://doi.org/10.1109/78.650093(1997)。
文章一个 广告一个 Google Scholar一个
Vaswani, A.等。Attention is all you need.Advances in Neural Information Processing Systems30(2017)。
Koenker, R. & Hallock, K. F. Quantile regression.J. Econ。观点。 15, 143–156 (2001).
Zhang, Y., Li, C., Wang, P. & Li, B. Carbon-aware reinforcement learning for cloud computing.IEEE Trans。维持。计算。 8, 1–12 (2023).
Schwartz, R., Dodge, J., Smith, N. A. & Etzioni, O. Green ai.社区。ACM 63, 54–63 (2020).
致谢
The authors acknowledge the institutional support provided by Assiut University, including access to computational resources and research facilities.No additional contributors beyond the authors meet the acknowledgment criteria.
资金
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
竞争利益
The authors declare that they have no competing financial or non-financial interests relevant to the work described in this manuscript.
道德认可
This study does not involve experiments on living vertebrates, higher invertebrates, or human subjects, and therefore does not require ethical approval.
同意出版
The results, data, and figures presented in this manuscript are original and have not been published previously.
This work is not under consideration for publication elsewhere.
附加信息
Publisher’s note
关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
权利和权限
开放访问This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.To view a copy of this licence, visithttp://creativecommons.org/licenses/by/4.0/。重印和权限
引用本文

Manhary, F.N., Mohamed, M.H.
& Farouk, M. A scalable machine learning strategy for resource allocation in database.Sci代表 15, 30567 (2025).https://doi.org/10.1038/s41598-025-14962-5
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41598-025-14962-5