


每两年将晶体管数量增加一倍,因此将晶体管的价格降低了一半,因为您可以在给定区域进行两倍的计算,并在CMOS CHIP时代驾驶它。
但是,摩尔的法律数学也意味着其他。鉴于每次功率预算略高,您可以每年提高设备的性能40%。对于计算发动机,这意味着每年的升级不仅可以跟上大多数公司的交易和分析工作量的增长。对于那些需要更多的人来说,有对称的多处理(SMP),然后是非统一的内存访问(NUMA)群集以使多个设备看起来像一个大型设备 - 我们称之为规模。
随着Web 2.0 Internet ERA确实在1990年代末开始,即使使用SMP或NUMA,这台机器也是如此,这种所谓的规模扩大了共享的内存方法以增加计算是不够的。(Interestingly and coincidentally, this was also when the exotic federated NUMA configurations in supercomputing, which today we could easily build with off-the-shelf PCI-Express switches, also ran out of gas for traditional HPC simulation and modeling workloads, but at a much higher scale that was too costly for enterprises and the webscale companies like Google that had not yet warped into hyperscale. And so in both cases, scaling out across distributed computing很快就有数百至数千个节点的群集成为获得机器同时完成更多工作或在更少的时间内完成相同工作的唯一途径。
在这一点上,网络确实确实成为计算机。从那以后,该网络一直是瓶颈,现在是Genai时代的巨大瓶颈,在该GPU中,GPU的价格为30,000美元或40,000美元或50,000美元,可能是其计算能力的25%至35%,因为他们等着在AI培训的每一个迭代培训运行中等待与所有其他GPU交换数据。
我们是Google AI和基础设施副总裁兼总经理Amin Vahdat,在本周的Hot Interconnects 32会议上,称为第五个分布式计算时期的第五个时代,Genai工作负载所需的绩效巨大的飞跃意味着计算行业必须再次重新启动网络网络,并且可以重新启动网络,并且可以很好地重新启动网络,并且可以重新启动网络,并且可以重新启动网络,并且必须再次重新启动网络,并且必须重新启动网络,并且必须再次重新启动网络,并且必须再次重新启动网络。网和作品。
在我们了解从其网络中分布式计算需求的第五个时代之前,以下是vahdat的时期:
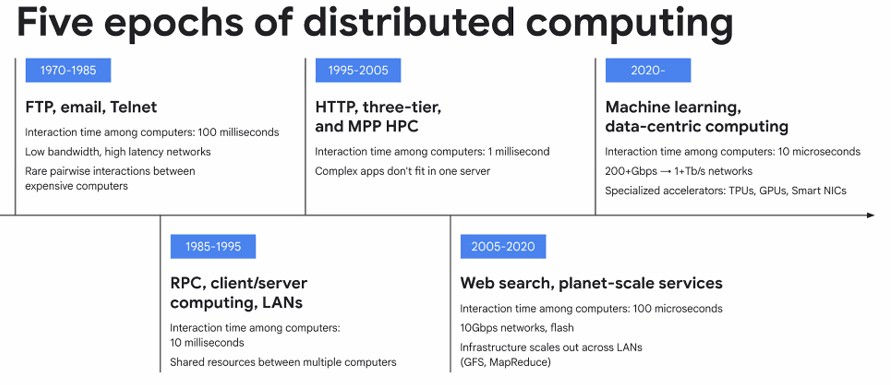
You will note in the table above that with each new epoch in compute, the interaction time between the computers used to run applications went down by an order of magnitude, and that is from 100 milliseconds in the FTP/Email/Telnet era that ended in the mid-1980s to the 10 microseconds in the current machine learning/data-centric computing era, as Vahdat calls it and what we might simplify as “data intelligence.â€
随着更加宽敞的计算和存储进入市场,使用网络并更难推动计算和存储能力,并更难推动它。
Vahdat在他的主题演讲中说:`从2000年到2020年,通过整个社区中的巨大工作,我们到达了一个地方,我们的固定成本效率提高了约1,000倍。”这意味着,让我们说,大约2020年,您可以拥有1,000倍的计算能力,或者与2000年相同的价格的存储容量是1,000倍。我们可以想象的是,又可以想象的事情又发生了巨大变化。这为AI代树立了阶段。我的意思是,我们可以在一个足够的数据和足够的计算能力的地方结束,我们可以想象只需定期运行大规模计算,用于培训或服务这些新一代的模型。因此,需求不断增长,因此,尽管我们花了20年的时间来提高效率的最后1,000倍,但我们将不得不更快地提供接下来的1,000倍。我认为这将是我们工作的关键。
这是加速计算的时代,诗意的是,对计算的需求速度正在加速。
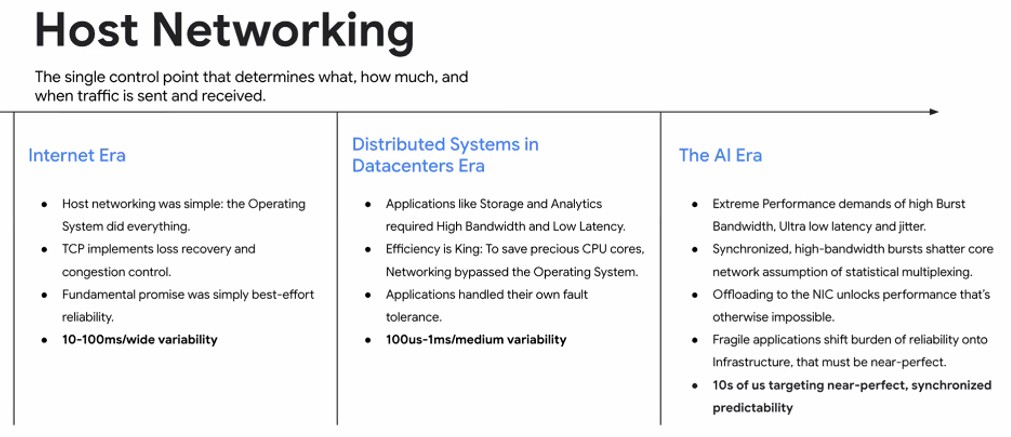
VAHDAT解释说,我们在上一个时期看到的是快速增长,但实际上,在过去的几年中,我们已经看到了几乎无界的计算需求需求增长了10倍,” Vahdat解释说。
随着对计算的需求,对网络的需求还包括相应的需求。
计算需求的10倍增加每年Vahdat说,在Genai时代,在Genai时代很艰难,因为即使您可以通过结合较大的芯片(或芯片络合物)的组合并降低数值精度,但您仍然需要再构成3.3倍到5倍才能达到10倍,以及在分布式的计算机中,您仍然需要再构成3.3倍至5倍。
这就是为什么我们看到少数AI模型建造者拥有具有100,000或200,000个端点的系统,并且很多人在谈论明年或两年中有100万个XPU的集群。这不是容量集群,要从HPC空间借用一个术语,这意味着一台具有成千上万个工作负载的机器以共同的方式安排在机器上,但是功能集群这旨在在整个计算机上运行一个工作负载。因为它必须。
对人类知识的总和进行分配和切片,并创建了一个巨大的知识图,以将查询倒入中,以强迫基于该知识的统计意义的响应,这是一项巨大的工作。
好消息是,即使AI的工作负载也可以预测。查看此图表,该图表显示了训练双子座模型时的爆发流量,查看超过30秒,5秒和100毫秒间隔的交通率:
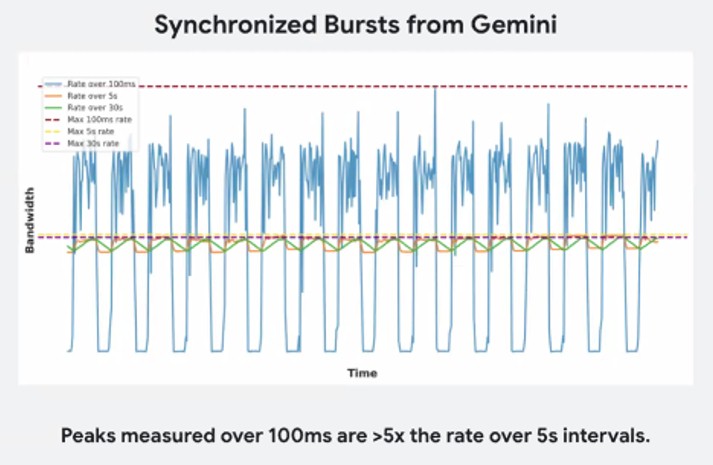
在5秒的时间尺度上,主机网络上的带宽波动看起来像是波涛汹涌的波浪,但没有太大的戏剧性,在30秒的时间范围内,看起来一切都很光滑,容易。但这不是对正在发生的事情的准确表征。看看100毫秒蓝线的野外挥杆。加速器只是坐在那里等待很多时间,然后像疯狂的其他时候一样吸收数据。
但是再看一下可预测性。如果可以定期预测某件事,那么它可以进行管理,更重要的是计划。这是第五个时代网络的秘密,实际上是Ultra Ethernet联盟正在努力提供以太网网络的AI/HPC变体的一件事。
VAHDAT说,越来越多地拥有整个网络,数万个服务器,也许一次专门用于一次运行一个应用程序,并且从计算到通信的阶段非常鲜明。”没有统计多路复用器。有一个应用程序,并且一个应用程序紧密同步。换句话说,该计算通常需要全部沟通,我们在可能的10,000多个服务器之间进行了交流,这意味着交流是非常同步的,打破了我们多年来所拥有的一些基本假设。”
这是AI工作负载及其网络的新假设,因为Vahdat在他的演讲中列出了这些假设:
- 同步的,周期性的线路速率在持续数十秒钟的毫秒粒度上爆发
- 延迟敏感(记忆障碍)和带宽密集型
- 可预测性:对于同步工作负载,最差的案例(100Th百分比)延迟不仅会影响性能决定它工作负载期望接近无毛的基础架构(任何崩溃都可以阻止整个工作运行)单个租户工作量和同步高速爆发,跨工作负载的统计多路复用没有任何好处,因为只有一个
- 加速器的效率至关重要,网络是系统范围性能,可预测性和可靠性的最关键的推动力
- Vahdat说,这个未来的网络必须提供巨大的爆发带宽,低潜伏期,超低抖动和无瑕的可靠性。
- 轻松的毛茸茸,对吗?
这个第五个时期网络有很多秘密 - 放心,Google可能不会贡献其硬件设计和协议规范以打开计算及其软件向Linux基金会开放,但是重要的是Google的萤火虫网络时钟同步,迅速的拥塞控制,较好的型号和固定网络,并构成了越来越多的网络,并构成了越来越多的网络,并构成了越来越多的固定网络(该网络),该网络既有越来越多的编码)。
在AI系统中。
在所有这些中,萤火虫可能是最重要的,洞察力是,如果您可以安排流动的各个方面,那么有一个可预测的网络负载,甚至可以改变一个变化,然后您可以管理所有这些流,永远不要首先造成拥塞。为此,事实证明,您需要一个时钟来同步网络上数据的舞蹈,该网络的循环速度比网络的延迟更快。(显然,即使按照这种调度,网络上仍然存在一些拥塞,或者Google也不需要Firefly网络时钟和流量调度。)
这个新的数据中心节拍器将在9月初在葡萄牙的Sigcomm 2025会议上揭示萤火虫:数据中心的可扩展,超准确的时钟同步。自2010年左右以来,Google在数据中心的全球分布式数据库进行测试时,在数据中心有原子钟,该数据库在其全球跨度巨像文件系统上运行。那时和现在使用萤火虫,必要的云是必要的,因为正如Vahdat在Hoti 2025上的介绍所说的那样,您不能安排时间不花时间。”萤火虫实际上是整个数据中心的所有事物的节拍器,提供了sub-10 nansecond clockond clockend clockennnchnynncynigized Fablic,可以使整个Shebang整个Shebang。
通过定时和安排每件小事,该网络从随机延迟的来源转换为确定性,可靠的结构,如演示文稿中详细介绍的Vahdat。每个数据传输都是编排的,并且由于全能的通信模式是如此规则(如上所述),所以这听起来并不那么荒谬。该网络从充满反应的数据包到一个积极的,完美地安排的网络。
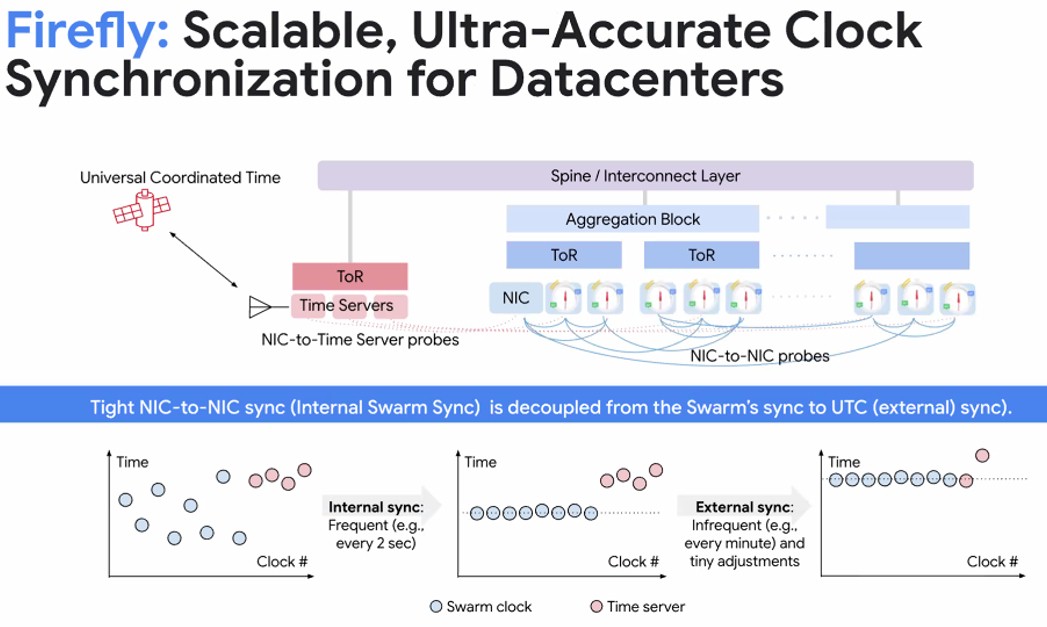
Firefly can synchronize network interface cards (NICs), which do all of the heavy lifting in the network of the future rather than burden host systems and switches, in under 10 nanoseconds and can synchronize a NIC to a Universal Time Clock (UTC) in under 1 millisecond, and this, says Vahdat, allows for the scheduling of AI collective operations in tens of nanoseconds.在这个世界中,基于类似的东西,在高端以太网开关内的港口需要数百个纳秒秒才能希望Broadcom的Tomahawk Ultra -StrataxGC开关ASIC对于早期的战斧而言,还有更多。
除了使AI培训更好地工作(并且我们也认为AI推断)之外,使用萤火虫同步和网络调度的方法意味着,XPU的空闲时间将是一个已知,可预测的和较低的数量,而不是其他可能的情况,这又意味着每年在全球销售的数百亿美元的gpu系统都可以在全球范围内销售更多的数据。
Google开发的迅速拥塞控制比Firefly更古老,这就是为什么它存在的原因。这种拥堵控制方法在Sigcomm 2020中揭示了Swift:延迟对数据中心中的拥塞控制简单有效。斯威夫特(Swift)对NIC和主机服务器进行了运行,基本上说``持有一秒钟,这是以太网不喜欢做的事情来打击网络拥塞。(也许应该被称为“ waitaminit”?)
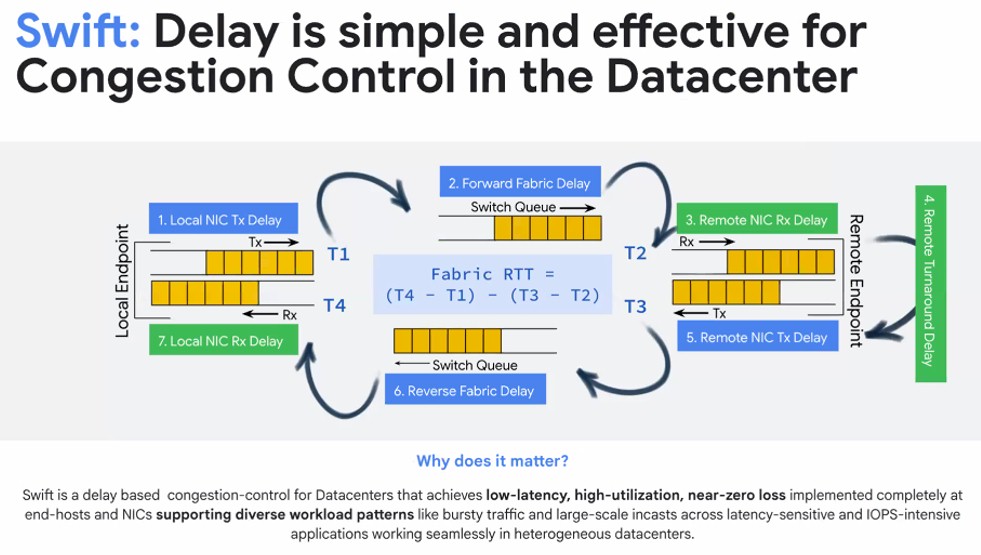
Vahdat在他的演讲中解释说,Swift所做的事情是维护有关网络周围排队和主机排队的所有信息的细粒度信息,并调整网络上的数据发送率,以达到网络中低级排队的目标水平。这样做的净效应是,运行迅速拥塞控制的以太网网络可以处理AI和HPC全能通信和大规模的直肠等爆发流量,并且仍以低潜伏期,高网络利用率和接近零数据包的丢失,仍然传递数据。
这就是猎鹰协议以及Google和英特尔称之为智能处理单元或IPU的内容,以及我们大多数人称之为数据处理单元或DPU的内容。
Google一直在投资协议,以优化数据包装并在各种网络上传递的方式。我们告诉你Aquila协议及其非常特定的小群集用例例如,早在2022年10月。有一个名为Snap的更广泛使用的主机网络系统,由Google在2019年揭示SNAP:一种托管网络的微粒方法,概述了一个由Linux衍生的网络操作系统,其中用户空间中编码了模块;这些模块之一是Pony Express,这是一种数据平面发动机,用于SNAP,即运输层,包括流量控制,拥塞控制和其他功能。据我们所知,自2016年左右以来,Snap和Pony Express已在Google的主机网络中部署。
最近,随着切换到智能DPU与Intel结合开发的智能DPU(尤其是我们在这里谈论的埃文斯山),Google为该设备开发了一个新的传输层,该设备是第五个时期网络的另一个元素。

Vahdat解释说,将Falcon视为可靠且低延迟的NIC运输的硬件实施,并且在这些极端性能水平,低尾部潜伏期,大规模的应用带宽范围内越来越多地进行。”
猎鹰和相关技术是由Google在超级标准元平台和Microsoft以及NVIDIA的帮助下开发的,因为与vender conseernet contimented Ethernet相比,RDMA比vahdat更适合利基用例,而Vahdat则是独立的。我们对猎鹰一无所知,但一篇论文叫猎鹰:可靠的低潜伏期硬件运输下个月还将在Sigcomm 2025中发布,我们将留意它。看起来Falcon将实施迅速的基于延迟的拥塞控制。目标是使猎鹰运输提供10倍的每秒运营,以1/10的Th尾部潜伏期,看来Vahdat炫耀的早期测试发生了这种情况:实现猎鹰硬件运输层的第一个硬件是与英特尔(Intel)一起设计的Evans E2100 Mount E2100,它具有16个ARM Neoverse N1内核和48 GB的内存,其中有两个100 GB/sec端口。

Google获得的公司具有专门的硬件,可用于公司的本土 - 仙女座外面网络虚拟化堆栈,
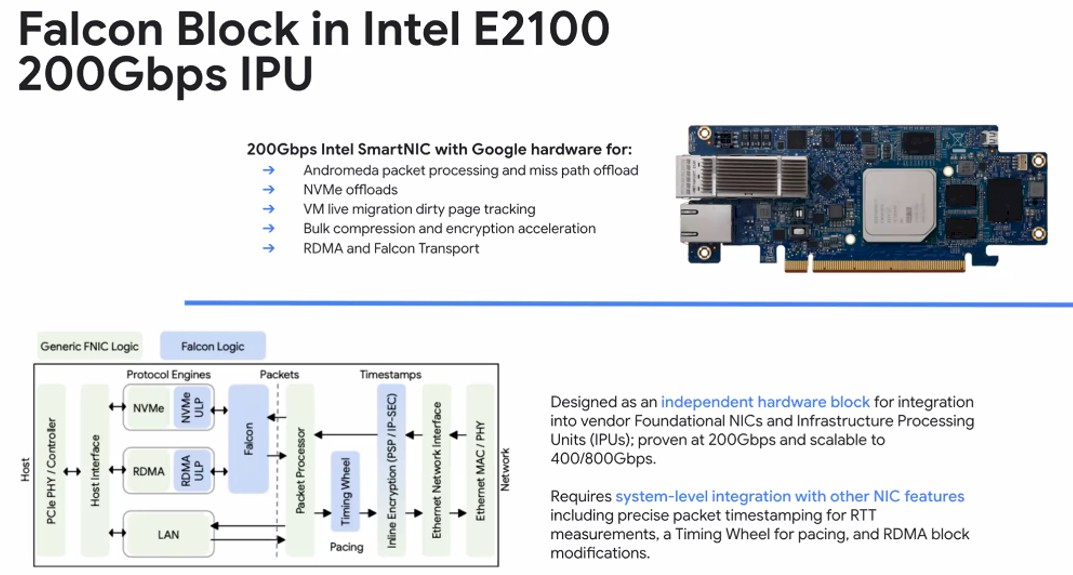
我们告诉大家回到2017年11月和当年晚些时。NIC还运行了Google的RDMA实施,并具有电路以帮助VM实时迁移,NVM-Express-Express Flash虚拟化以及飞行中数据的压缩和加密。Vahdat暗示,Evans的版本具有400 GB/sec和800 GB/sec的带宽(可能是在两端口和单端口版本的Google需求中)都在路上。
据我们所知,这是英特尔做得正确的事情,并导致了DPU,希望它可以将其出售到主流中。
对于Google而言,猎鹰的运输意味着其NIC的中位和尾部潜伏期都接近理想的吞吐量,并且Goodput在最大链路速度下饱和。随着队列对的增加,它的延迟与NVIDIA CONNECTX-7的潜伏期大致相同,但约3.000至4,000 QP的延迟,CX-7潜伏期尖峰的速度仅为Mount Evans设备的3倍。
这使Straggler的发现是Vahdat在Hoti 2025年谈到的第五个网络时期的最后一部分。
Vahdat说:“我们具有强大的机制,不仅能够检测到艰苦的失败,而且还可以发生挑战性的软失败或可能发生的散乱者。”说节点降低,或者该网络链接下降。也许只是缓慢的 - 它可能要慢2倍,无论出于何种原因,它可能比其他人慢4倍。也许您有一些错误率上升,也许您有一些PCI-Express问题。有一百件事可能会出错,实际上不会造成严重的失败。您如何将其定位,检测到它,从本质上删除该元素或从网络中进行修复,非常非常快速?
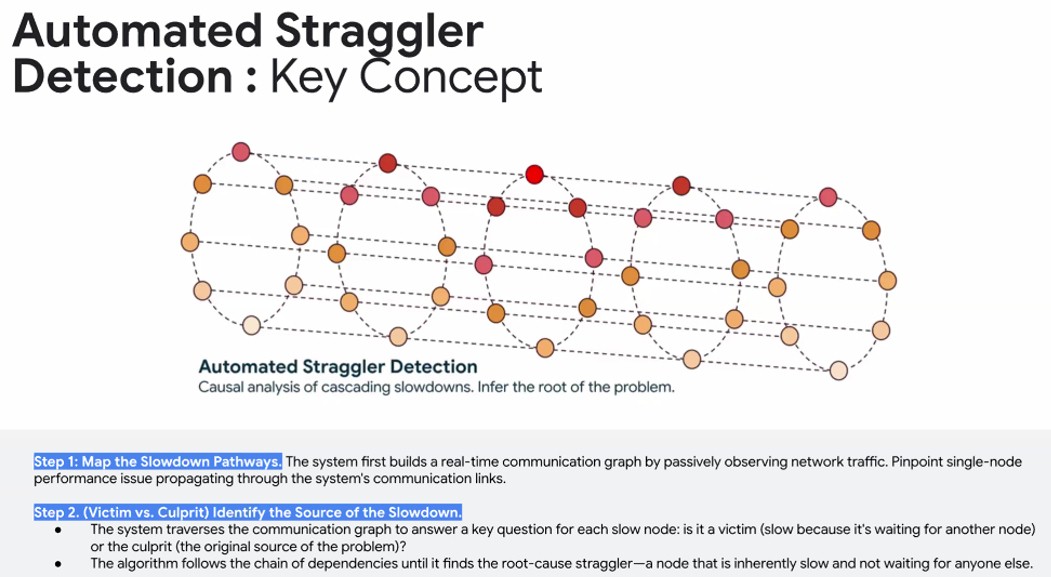
这不是微不足道的。但是请记住,在AI工作负载中,就像HPC工作负载一样,当一个节点降低时,整个训练运行或模拟停止或移动速度也很慢,以至于可能也可能。(这就是为什么AI和HPC工作负载同样重要的检查点计算同样重要的原因。)
Vahdat详细详细介绍了Straggler检测的时间,但说该系统为在其数据中心中的群集中找到故障而提出了一个过程,这可能需要花费数天的时间手动调试,从Google最聪明的人进行了自动化的三角体的最低点。我们很想知道该系统中已将AI系统延续的系统部署了多少。要点是,Google从网络中的所有NIC,开关和主机中都采取了遥测,并创建了所有这些设备的实时实时通信图,并且当出现故障时,找到了所有受害者,并发现了如何从图形上从图形上进行上游的所有受害者,以快速找到错误的culprit设备,这些设备是错误的和引起问题。它通过找到根本原因straggler而做到这一点,该节点很慢,并且没有等待任何其他节点。
在那里你有。或者,更确切地说,您不拥有它,直到所有这些想法都是由超太以太网联盟,开放式计算项目等实施的。

注册我们的新闻通讯
直接从我们到您的收件箱中,介绍了一周的亮点,分析和故事,两者之间一无所有。
立即订阅