
每天,组织都会处理数百万个文件,包括发票,合同,保险索赔,医疗记录和财务报表。尽管这些文件扮演着重要角色,但估计为80%它们所包含的数据是无组织的,并且在很大程度上未开发,隐藏了有价值的见解,可以改变业务成果。尽管技术取得了进步,但许多组织仍依靠手动数据输入,花费无数小时从PDF中提取信息,扫描的图像和表格。这种手动方法是耗时,容易出错,并阻止组织扩展其运营并迅速响应业务需求。
尽管生成的AI使构建概念验证文档处理解决方案变得更加容易,但是从概念到生产的旅程仍然充满了挑战。当组织发现其原型时,他们通常会发现自己从头开始重建,无法处理生产量,缺乏适当的错误处理,不符合成本效率或无法满足企业的安全性和合规性要求。每天在生产环境中处理数千份文档时,在演示中起作用的内容通常会崩溃。
在这篇文章中,我们介绍了我们的开源Genai IDP加速器我们用来帮助各个行业客户解决其文档处理挑战的测试解决方案。自动化文档处理工作流程准确地从文档中提取结构化信息,从而减少手动工作。我们将向您展示这种现成的解决方案如何在几天而不是几个月内使用AWS上的生成AI来帮助您构建这些工作流程。
了解智能文档处理
智能文档处理(IDP)包括用于从各种文档类型中提取和处理数据的技术和技术。常见的IDP任务包括:
- OCR(光学特征识别)将扫描的文档和图像转换为可读的文本
- 文档分类•自动识别文档类型(例如发票,合同或表格)
- 数据提取从非结构化文档中获取结构化信息
- 评估评估提取数据的质量和信心
- 摘要�创建文档内容的简明摘要
- 评估根据预期的结果来衡量准确性和性能
这些能力在整个行业之间至关重要。在金融服务中,组织使用IDP处理贷款申请,从银行对帐单中提取数据并验证保险索赔。医疗保健提供者依靠IDP从病历,过程保险表中提取患者信息,并有效地处理实验室结果。制造业和物流公司使用IDP处理发票和采购订单,提取运输信息并处理质量证书。政府机构使用IDP处理公民申请,从税收表中提取数据,管理许可证和许可证以及执行监管合规性。
IDP的生成AI革命
传统的IDP解决方案依赖于基于模板的提取,正则表达式和经典的机器学习(ML)模型。尽管功能很强,但这些方法需要广泛的设置,在文档变化方面挣扎,并且在复杂文档上的准确性有限。
大语言模型(LLM)和生成AI的出现从根本上改变了IDP功能。现代AI模型可以理解文档上下文,处理没有模板的变化,在复杂提取上实现近乎人类的准确性,并适应具有最小示例的新文档类型。从基于规则的处理到基于智能的处理的这种转变意味着组织现在可以高精度处理不同的文档类型,从而大大减少了实施的时间和成本。
Genai IDP加速器
我们很高兴分享Genai IDP加速器一种开源解决方案,该解决方案通过大大减少手动努力并提高准确性来改变组织如何处理文档处理。这个无服务器的基础提供了使用的处理模式亚马逊基岩数据自动化对于富含现成的文档处理功能,高精度,易用性和直接的每页价格,亚马逊基岩需要自定义逻辑的复杂文档的最新基础模型(FMS)和其他AWS AI服务为企业提供灵活,可扩展的起点,以构建根据其特定需求量身定制的文档自动化。
以下是解决方案中的简短演示,在这种情况下,展示了默认的亚马逊基础数据自动化处理模式。
现实世界的影响
Genai IDP加速器已经在为各个行业的组织转换文档处理。
竞争:大规模改变营销情报
竞争性营销情报的领导者竞争面临着面临的巨大挑战:每天处理35,000次45,000个营销活动,同时保持了15年的4500万个活动的可搜索档案。
使用Genai IDP加速器,竞争者实现了以下内容:
- 各种营销材料的分类和提取精度为85%
- 提高可伸缩性处理35,000 45,000个每日活动
- 去除关键瓶颈,促进业务增长
- 从初始概念起的短短8周内生产部署
理光:扩展文档处理
文档管理方面的全球领导者里科(Ricoh)实施了Genai IDP加速器,以为其客户转换医疗保健文档处理。他们每月处理超过10,000个医疗保健文件,并有可能扩展到70,000,他们需要一种可以以高准确性处理复杂医疗文档的解决方案。
结果自言自语:
- 每年通过自动化每年超过1,900个人小时的储蓄潜力
- 达到提取准确性,以帮助最大程度地减少处理错误的经济损失
- 自动申诉与上诉分类
- 创建了可在多个医疗保健客户中部署的可重复使用的框架
- 与人类的审查集成了需要专家验证的案件
- 杠杆模块化体系结构与现有系统集成,启用自定义文档分割和大规模文档处理
解决方案概述
Genai IDP加速器是一种模块化的,无服务器的解决方案,它会自动将非结构化文档转换为结构化的可操作数据。它完全基于AWS服务,提供企业级的可扩展性,安全性和成本效益,同时需要最少的设置和维护。其配置驱动的设计可帮助团队快速适应其特定文档类型的提示,提取模板和验证规则,而无需触摸基础基础架构。
该解决方案遵循一个模块化管道,该管道在从OCR到分类,再提取,评估,汇总和以评估结尾的每个阶段丰富文档。
您可以独立部署和自定义每个步骤,因此可以在保持集成工作流的好处的同时为特定用例进行优化。
下图说明了解决方案体系结构,显示了默认基础数据自动化工作流程(模式1)。
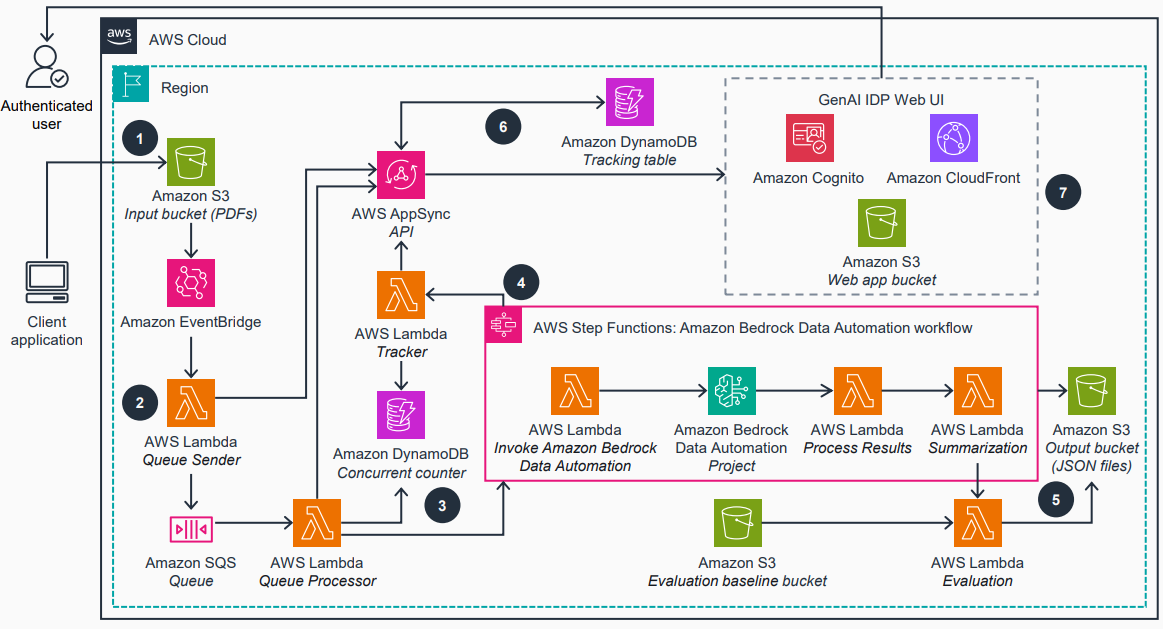
参考Github仓库有关其他详细信息和处理模式。
解决方案的一些关键特征包括:
- 无服务器体系结构建立在AWS Lambda,,,,AWS步骤功能,以及其他无服务器的技术,用于排队,并发管理和重试,以提供自动缩放和每次使用的定价,用于生产工作负载
- 生成AI驱动的文档数据包分割和分类智能文件分类使用亚马逊基岩数据自动化或亚马逊基岩多模式FMS,包括对多文件包和数据包拆分的支持
- 高级AI密钥信息提取关键信息萃取使用亚马逊基岩数据自动化或亚马逊基岩多模式FMS
- 多个处理模式'从针对具有不同可配置性,成本和准确性要求的不同工作负载进行优化的预制模式中选择,或使用其他模式扩展解决方案:
我们希望添加更多模式选项来满足其他现实世界文档处理需求,并利用不断改善的最先进功能:
- 几乎没有学习通过提供分类和提取的准确性几个示例指导AI模型
- 信心评估AI驱动的质量保证评估提取场置信度,用于指示人类审查的文件
- 人类在环(HITL)评论用于集成的工作流程人类评论使用低信心提取亚马逊萨吉人增强了AI(Amazon A2i),目前可用于模式1,并支持模式2和3即将推出
- Web用户界面响应式Web UI用于监视文档处理,查看结果和管理配置
- 知识库集成查询处理的文档通过自然语言通过亚马逊基石知识基地
- 内置评估框架评价并提高基线数据的准确性
- 分析和报告数据库集中分析数据库用于跟踪处理指标,准确性趋势和跨文档工作流程的成本优化,并使用亚马逊雅典娜
- 无代码配置通过自定义文档类型,提取字段和处理逻辑配置,在Web UI中可编辑
- 开发人员友好的Python包对于想要直接实验,优化或集成IDP功能的数据科学和工程团队,解决方案的核心逻辑可通过IDP_COMMON PYTHON软件包
先决条件
在部署解决方案之前,请确保您拥有一个具有管理员权限的AWS帐户,并在Amazon Bedrock上使用Amazon和Anthropic Models。有关更多详细信息,请参阅访问亚马逊基岩基金会模型。
部署Genai IDP加速器
要部署Genai IDP加速器,您可以使用提供的AWS云形式模板。有关更多详细信息,请参阅快速启动选项在GitHub仓库上。高级步骤如下:
- 登录到您的AWS帐户。
- 选择启动堆栈对于您首选的AWS地区:地区
| 启动堆栈 | 美国东部(N.弗吉尼亚州) |
|---|---|
| 美国西部(俄勒冈州) | |
| 输入您的电子邮件地址,然后选择您的处理模式(默认为模式1,使用Amazon BedRock Data Automation)。 |
- 对所有其他配置参数使用默认值。
- 部署堆栈。
- 堆栈大约需要15分钟的时间来部署资源。
部署后,您将收到带有Web界面登录凭据的电子邮件。
过程文档
部署解决方案后,您可以开始处理文档:
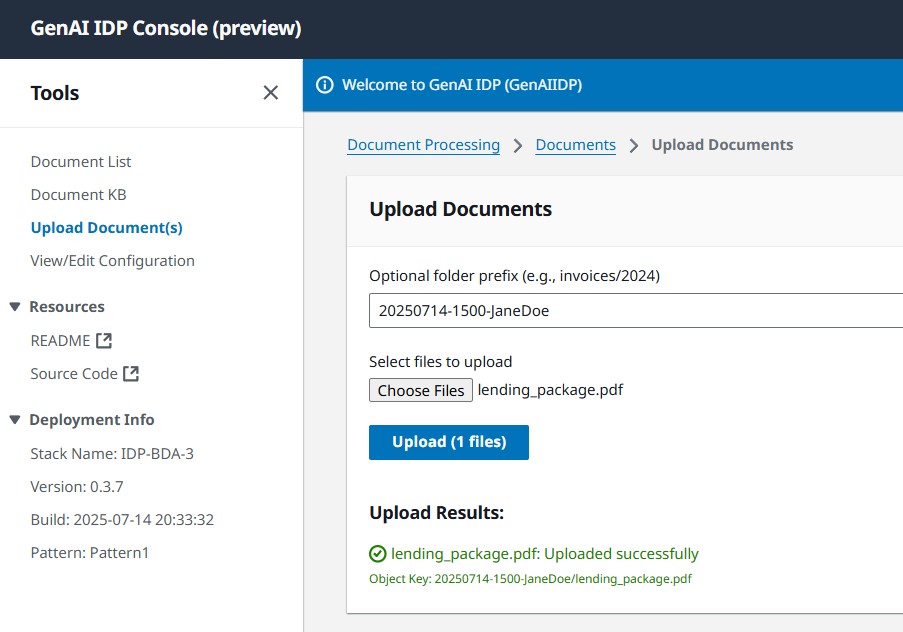
- 使用Web界面上传示例文档(您可以使用提供的示例:lending_package.pdf)。
在生产中,您通常会自动将文档直接加载到亚马逊简单存储服务(Amazon S3)输入存储桶,自动触发处理。要了解更多,请参阅没有UI的测试。
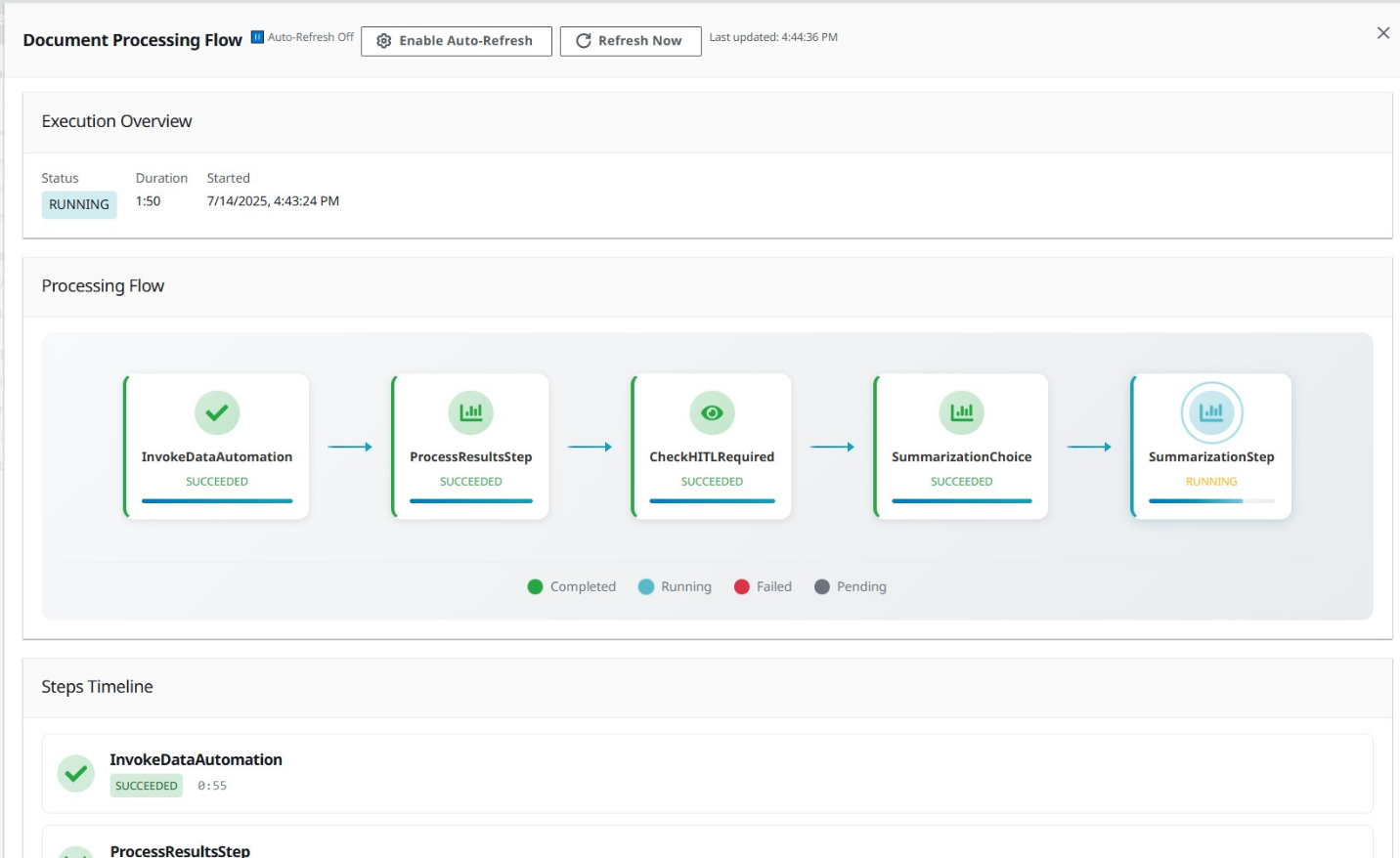
- 从文档列表中选择您的文档,然后选择查看处理流观察您的文档流过管道。
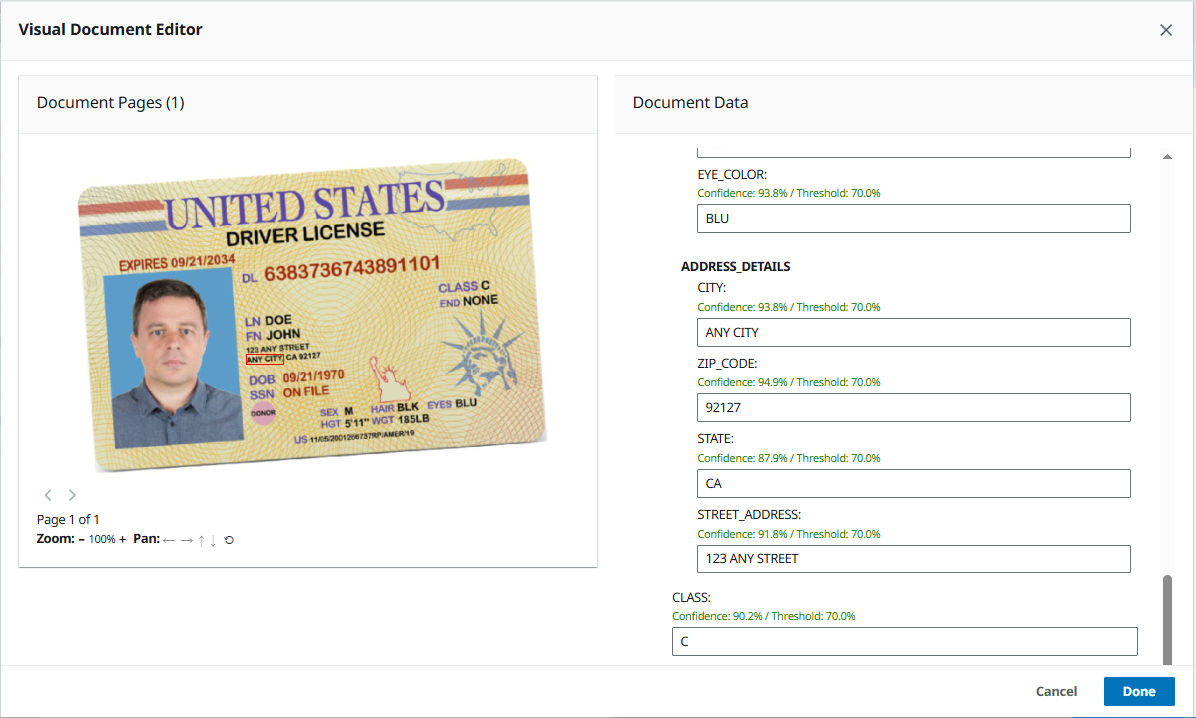
- 以置信度评分检查提取的数据。
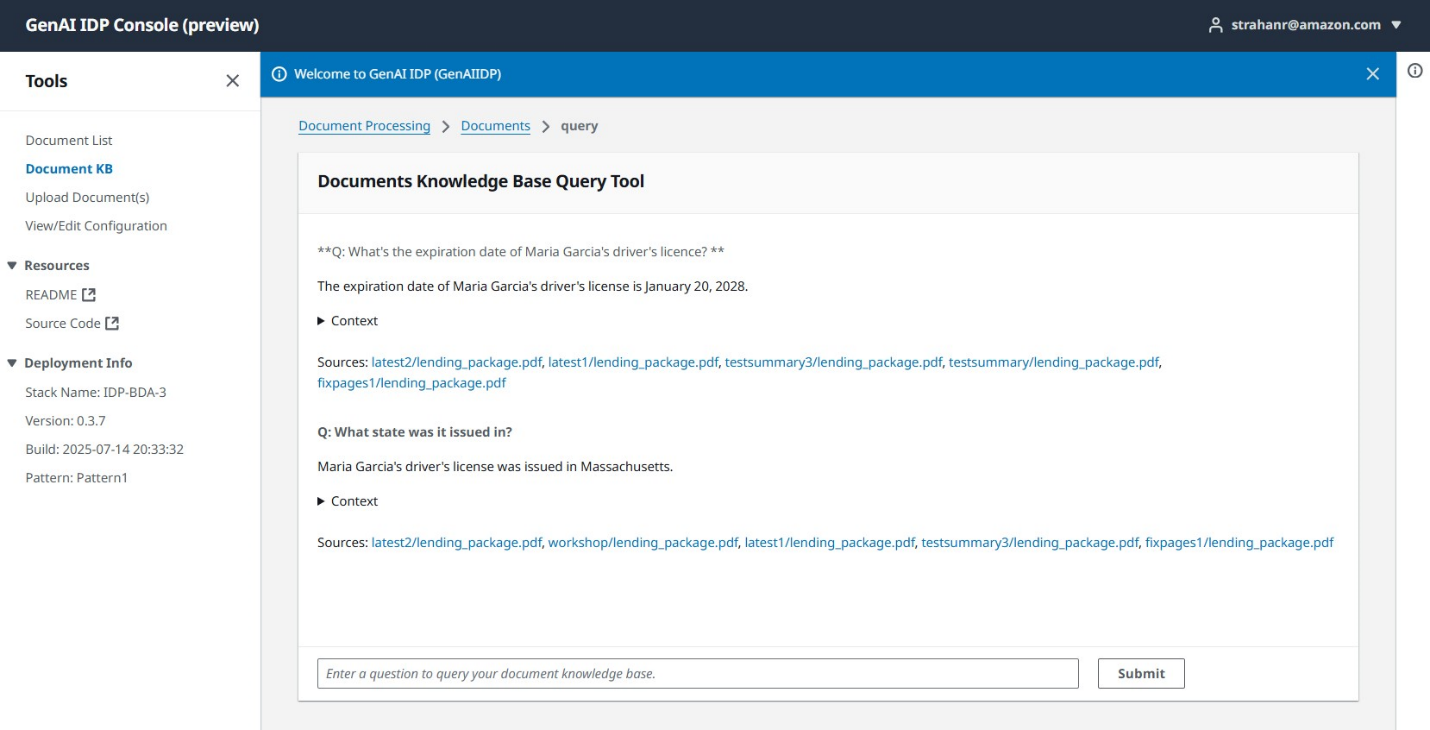
- 使用知识库功能来询问有关处理内容的问题。
替代部署方法
你可以从源代码构建解决方案如果您需要将解决方案部署到其他区域或构建和部署代码更改。
我们希望增加对AWS云开发套件(AWS CDK)和Terraform部署。跟随GitHub存储库有关更新或联系AWS专业服务用于实施帮助。
更新现有的Genai IDP加速器堆栈
您可以将现有的Genai IDP加速器堆栈更新为最新版本。有关更多详细信息,请参阅更新现有的堆栈。
清理
完成实验后,使用AWS云形式控制台清理资源,以删除部署的IDP堆栈。
结论
在这篇文章中,我们讨论了Genai IDP加速器,这是一种新的文档处理方法,将生成AI的力量与AWS的可靠性和规模相结合。您可以比传统方法处理数百万甚至数百万个文档,以更快,更具成本效益。
参观GitHub存储库用于详细的指南和示例,然后选择手表要了解新的版本和功能。AWS专业服务和AWS合作伙伴可用于实施。您还可以加入GitHub社区,以贡献改进并分享您的经验。
关于作者
 鲍勃·斯特拉汉(Bob Strahan)是AWS生成AI创新中心的主要解决方案建筑师。
鲍勃·斯特拉汉(Bob Strahan)是AWS生成AI创新中心的主要解决方案建筑师。
 乔·金是AWS生成AI创新中心的高级数据科学家。
乔·金是AWS生成AI创新中心的高级数据科学家。
 Mofijul Islam是AWS生成AI创新中心的应用科学家。
Mofijul Islam是AWS生成AI创新中心的应用科学家。
 Vincil Bishop是AWS生成AI创新中心的高级深度学习建筑师。
Vincil Bishop是AWS生成AI创新中心的高级深度学习建筑师。
 大卫·卡莱科(David Kaleko)是AWS生成AI创新中心的高级应用科学家。
大卫·卡莱科(David Kaleko)是AWS生成AI创新中心的高级应用科学家。
 Rafal Pawlaszek是AWS Generative AI创新中心的高级云应用架构师。
Rafal Pawlaszek是AWS Generative AI创新中心的高级云应用架构师。
 斯宾塞·罗莫(Spencer Romo)是AWS生成AI创新中心的高级数据科学家。
斯宾塞·罗莫(Spencer Romo)是AWS生成AI创新中心的高级数据科学家。
 Vamsi Thilak Gudi是AWS世界广泛公共部门团队的解决方案建筑师。
Vamsi Thilak Gudi是AWS世界广泛公共部门团队的解决方案建筑师。
致谢
We would like to thank Abhi Sharma, Akhil Nooney, Aleksei Iancheruk, Ava Kong, Boyi Xie, Diego Socolinsky, Guillermo Tantachuco, Ilya Marmur, Jared Kramer, Jason Zhang, Jordan Ratner, Mariano Bellagamba, Mark Aiyer, Niharika Jain, Nimish Radia, Shean Sager,Sirajus Salekin,Yingwei Yu以及我们不断扩展的社区中的许多其他人,始终是他们坚定不移的愿景,热情,贡献和指导。