
人工智能聊天机器人在解释磁共振成像报告中的应用:比较研究
作者:Liao, Yonghong
介绍
临床肿瘤学中磁共振成像(MRI)的广泛采用强调了其在肿瘤诊断中的关键作用1,,,,2,,,,3。MRI扫描完成后,放射科医生根据图像准备了详细的报告。该报告概述了正常的解剖结构和异常病变信号,提供了初步诊断4。这些报告对于诊断肿瘤和指导治疗策略至关重要,因为它们详细介绍了肿瘤的位置,大小,边缘,血管分布以及与相邻结构的关系5。但是,这些报告中的医疗术语可能会对非医学专业人员构成挑战。尽管可以访问电子成像报告,但它们的复杂内容仍然是试图了解自己健康状况的患者的重大障碍6。结果,大多数患者需要与医生进行额外的咨询来解释其MRI报告,这可能会导致等待时间长时间进行咨询,并可能延迟诊断和治疗。这种情况不仅增加了门诊医师的工作量,而且增加了整体医疗保健负担7。
人工智能(AI)的最新突破导致了大型语言模型(LLMS)的发展,使用大量数据开发了复杂的自然语言处理系统8。这些聊天机器人在LLM的推动下体现了由Chatgpt举例说明的生成AI应用程序,该应用程序能够根据用户输入以对话方式产生响应9。在2022年11月发布的两个月内,Chatgpt超过了1000万用户10。与ChatGpt这样的模型积极互动的能力使LLM在包括药物在内的各个领域具有吸引力的工具11。鉴于它们能够处理复杂的概念并应对各种要求和问题(提示),LLM可以潜在地参与医学的各个领域。12,,,,13。最初的猜想提出了该技术在临床决策支持系统中的潜在应用。但是,先前的研究表明,LLM目前不成熟,容易出错,并且在其输出中表现出不稳定的能力,这大大限制了其在临床工作流程中的利用率14,,,,15。尽管如此,一些研究表明,在交互式对话中,AI聊天机器人的表现值得称赞。已经观察到这些聊天机器人根据输入内容具有非凡的临床决策支持能力16,,,,17。值得注意的是,一些研究表明,聊天机器人可以准确地响应社交媒体平台上提出的临床查询,通常表现出比医师的反应更大的同理心18,,,,19。然而,在临床环境中聊天机器人的潜力仍然在很大程度上尚未开发。在这项研究中,我们探讨了聊天机器人解释对没有医学背景的患者的MRI报告的能力,并确定与疾病管理有关的关键要素。
方法
数据收集
我们从2019年1月1日至2024年12月31日在三个位置进行了扫描的6,174例肿瘤患者的MRI报告。这些报告的长度和复杂性各不相同,是由专门从事多种解剖系统(包括但不限于神经,消化和尿液系统)的放射学家撰写的。每份报告都详细介绍了扫描区域的正常解剖结构,观察到的异常病变信号,并提供了简短的初步诊断。两位独立审阅者分析了原始MRI报告以及相应的扫描,以将发现分类为良性,非典型或恶性类别(表 1)。在分歧的情况下,第三位肿瘤科医生做出了最终决定。为了保留数据的真实性,没有对原始报告的内容进行更改。此外,所有可识别的信息,例如患者的详细信息,检查日期,注册号和医师名称,都匿名为保护患者的机密性。
研究设计
这项研究利用了两个聊天机器人:GPT O1-Preview(由OpenAI开发),以下称为聊天机器人1,DeepSeek-R1(由DeepSeek开发),指定为Chatbot 2。在2025年2月1日至3月31日的研究期间。在此期间,在此期间,这些型号与特定的查询有关。为了标准化可读性比较,所有原始的MRI报告和提交的查询均专门用英语。聊天机器人的任务是依次回答四个问题:首先,以没有医疗背景的患者可以理解的方式来解释报告;其次,将病变归类为良性,非典型或恶性;第三,以评估手术干预的必要性;第四,根据报告的内容推荐一个治疗计划(表 2)。为了最大程度地减少偏见,为分析的每个报告启动了一个新的聊天课程。记录了聊天机器人对每个提示的响应。
在这项研究中,对原始MRI报告和聊天机器人产生的解释报告的可读性评估都是使用可用的在线工具进行的https://www.webfx.com/tools/read-able/。主要计算了三个广泛认可的可读性指数:Flesch-Kincaid Reading Ease(FRE)得分,Flesch-Kincaid等级水平(FKGL)和Gunning FOG得分(GFS)。可读性评估是在研究期间完成的,该研究期限为2025年2月1日至3月31日。随后,聊天机器人提供的答复接受了医疗审查。聊天机器人生成的每个响应线程均由两位医学审查员独立评估。在分歧的情况下,咨询了第三名肿瘤科医生来裁定差异。
解释性报告的医学综述,即对第一个问题的回答,将发现分为四个不同的级别:正确,部分正确,部分不正确且不正确。正确指示原始报告中的所有内容均准确包含而没有错误。``部分正确'是指不影响患者管理的细节的遗漏,例如未能描述硫和回合的正常变化。部分不正确的错误包括略微影响患者管理的错误,例如描述肿瘤大小或形状的少量不准确性,而这些肿瘤大小或形状不足以改变诊断或治疗建议。不正确表示严重影响患者管理的错误,例如错误描述的肿瘤位置。
第二个和第三个问题旨在分别分别确定肿瘤的性质并分别确定手术干预的必要性。对于这些分类任务,将结果评估为正确或不正确的结果。此外,审稿人还采用了李克特量表来评估治疗建议的质量以及聊天机器人在响应过程中所证明的同理心,从1(非常差)到5(优秀)。
道德考虑
中国医学科学院北京联合医学院医院的学术伦理审查委员会为这项横断面研究提供了伦理审查的豁免(豁免号SZ-3192)。在这项研究中使用的所有数据都被取消识别,以确保人类受试者的隐私和机密性。中国医学科学院北京联合医学院医院的机构审查委员会放弃了对原始知情同意书的要求,并允许未经其他同意进行二级分析。这项研究遵守了赫尔辛基宣言的原则,并遵循了加强流行病学观察性研究报告的指南(Strobe)。
统计分析
弗里德曼测试被用来比较原始报告与两个聊天机器人生成的解释性报告之间的可读性差异。Wilcoxon签名的秩检验用于比较两个聊天机器人生成的报告中的可读性,治疗建议的质量和同理心。此外,还采用卡方检验来评估两个聊天机器人之间医学审查表现的差异。所有统计分析均使用SPSS软件(26.0版,IBM)进行,两尾p值小于0.05被认为具有统计学意义。
结果
可读性分析
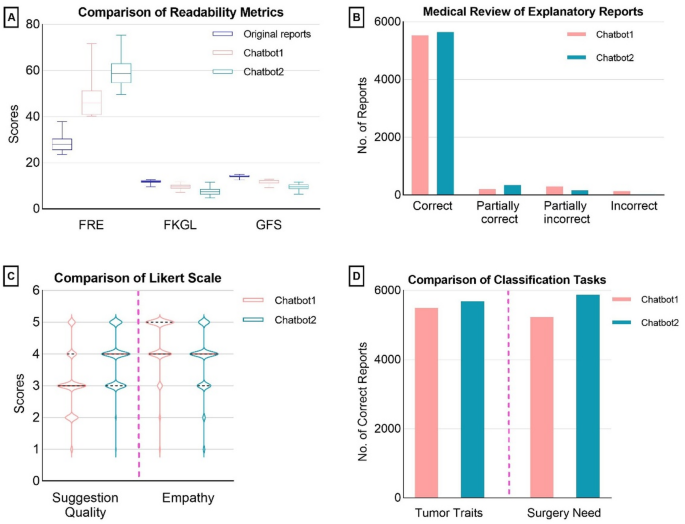
原始报告与聊天机器人1和聊天机器人2生成的报告之间的可读性改善是显而易见的,并使用Friedman测试确定了显着差异(p<<0.001)。聊天机器人生成的报告显示,FRE得分增强,FKGL和GFS分数降低,表明可读性增强和更简单的文本复杂性。表格中概述了详细的指标,包括复杂的单词百分比和平均单词计数 3。使用Wilcoxon签名的两个聊天机器人之间的进一步比较,发现可读性指标的统计学上显着差异(p<<0.001),确认聊天机器人2在简化文本中优于聊天机器人1。表3原始报告和解释性报告的可读性评估。
对ChatBot1和ChatBot2产生的解释报告进行了全面分析。
在医疗审查任务中,聊天机器人的表现优于聊天机器人1,尤其是其准确性和大幅下降的错误,包括分类和幻觉,其中仅显示26(0.42%)不正确,而11(0.18%)的幻觉实例,相比134(2.17%)(2.17%)不正确(1.73%)(1.73%)(1.73%)(1.73%)(1.73%)。两家聊天机器人均经过评估了他们在医疗分类任务方面的熟练程度,尤其是诊断肿瘤的性质并评估手术的必要性,并在表中列出了数据 4。此外,ChatBot2在医疗问题分类中更加遵守单词响应要求,成功地满足了6029年的报告(97.65%),明显超过了ChatBot1,仅在4724个报告中遵守了chatbot1(76.51%)。表4两个聊天机器人之间的医学评论比较。
相比之下,尽管ChatBot1的报告较短,但由于其回应的同理心更高表达而闻名。补充表1提供两个聊天机器人的比较响应示例。这种不同的性能突出了聊天机器人处理医疗审查任务的各种优势。(图 1)

原始报告和解释性报告的可读性和解释性报告的医学评估的比较。((一个)比较原始报告与聊天机器人生成的报告之间的可读性。指标包括Flesch Reading Ease(FRE),Fleschâkincaid等级(FKGL)和Gunning Fog得分(GFS)。((b)在两个不同的聊天机器人产生的解释性报告中对医疗准确性的比较分析。((c)李克特量表评估比较了两个聊天机器人的治疗建议和移情水平的质量。((d)比较医疗分类任务中两个聊天机器人的表现。
错误和幻觉
常见错误主要包括误解医学术语和错误地解释非标准符号。例如,两种聊天机器人偶尔会误诊肿瘤是在处理诸如异构增强或入侵之类的术语时,因此会增加解释性错误的风险。此外,在评估手术的必要性时,ChatBot1有时会忽略肿瘤的大小,从而导致评估不准确。幻觉通常表现为对因果关系的错误引入,在这些因果关系中,不存在并涉及过度解释陌生的术语或不当结合无关的信息,从而造成误解。这些问题突出了聊天机器人在管理复杂医学文本中的局限性。
讨论
据我们所知,这是探索生成AI聊天机器人在解释MRI报告中使用的首次横断面研究,旨在增强患者对放射学发现的理解,简化咨询过程并减少门诊工作。Ayers等人的开创性研究。强调了聊天机器人在医疗保健中的潜力,记录了他们在在线论坛上回应非正式患者查询的用途18。值得注意的是,与某些医师反应相比,这些聊天机器人的反应被发现具有可接受的质量,并且表现出更大的同理心。此外,其他研究还研究了聊天机器人在解决医师查询和支持临床决策方面的能力,结果不同20。
聊天机器人的部署以从RAW MRI报告中产生可理解的报告具有巨大的潜力,可以为数百万患者提供快速准确的医疗支持21。我们的研究发现表明,聊天机器人可以将原始MRI报告(通常是医学术语载有)转换为可理解且高度准确的文档。与通常需要至少11年级教育水平来理解的在线医学教育材料不同,聊天机器人生成的报告简化了对个人健康状况的理解22,,,,23,,,,24。传统上,医生向患者传达MRI结果,使他们获得医疗决策所需的知识25。将AI聊天机器人整合到临床实践中可以弥合医生与患者之间的医学知识差距,从而促进主动参与并可能改善疾病的结果26。此外,聊天机器人可以通过向患者传达报告结果,减少与后续约会相关的焦虑,并经常为社会经济上的弱势群体提供免费或低成本的医疗支持,这些人群往往较差,聊天机器人可以减轻医生的工作量,从而减少与后续预约有关的焦虑。27,,,,28。这些解释性报告还可以作为医学生和初级医生的教育辅助工具,增强他们的学习经验并促进对医学成像发现的更全面的了解。
聊天机器人在医学分类任务中表现出了显着的精度,尤其是在区分肿瘤的特征方面。他们对开放式问题的回答不仅保持准确性,而且还表现出更高的同理心,尤其是与某些临床从业人员的回答相比。此外,这项技术为初级临床医生提供了其他医疗建议,从而增强了他们的决策能力。它还通过有效识别肿瘤类型并优先考虑紧急情况,从而提高了临床工作流程的效率29。
虽然聊天机器人在分类肿瘤的性质和最初评估手术的需求方面表现出高度的准确性,但在提供特定的治疗建议时,它们的反应可能是冗长的,并且可能与核心问题有所不同。尽管这些详细的答案可能对患者表示同情,但它们也可能导致医疗专业人员的满意度下降。聊天机器人通常包括非医疗免责声明,并始终建议患者寻求专业的医疗建议。这强调了他们在医疗保健中作为辅助工具的作用,并强调了他们无法取代医生的临床决策。
潜在的语言偏见值得考虑。尽管所有投入均以英语为标准化,但由于其发育起源,DeepSeek-R1的培训语料库为中国医疗词典中的富裕基础奠定了基础。这种多语言体系结构可以部分解释其在复杂术语(例如,异质增强)和解剖学关系的上下文解释中的语义解析中的出色表现。未来的研究应通过平行翻译实验明确测试语言对效应,以消除语言一致性对性能的影响。
在临床环境中,生成聊天机器人反应的不准确性可能会对患者的诊断和治疗产生严重的影响。将这些聊天机器人部署在医学中的主要挑战与准确性,可靠性和幻觉的发生有关30。尽管已经提出了一些补救策略,但他们尚未实现令人满意的结果。微调涉及对模型的额外培训31。进一步的研究表明,更广泛的微调可以显着提高这些聊天机器人的准确性并降低幻觉的发生率32。因此,未来的研究应着重于完善聊天机器人通过靶向微调来解释肿瘤MRI报告的能力。
在临床环境中部署聊天机器人时,关注患者的隐私,道德和法律考虑至关重要。必须避免在与聊天机器人互动期间输入可识别信息,因为可能从培训和输入查询中使用的数据中识别出患者。关于责任,有人建议使用这些工具的临床医生或研究人员应对33。此外,由于没有医疗背景的患者无法判断聊天机器人反应的准确性,因此必须对临床医生进行医学审查以确保其准确性。
这项研究不可避免地面临某些局限性。首先,MRI报告专门来自肿瘤患者,这些患者本质上具有更独特的特征。这种特异性可能会限制聊天机器人对肿瘤以外的条件的适用性,从而有可能降低我们发现的普遍性。其次,聊天机器人以概率为基础运行,这意味着问题的表述和顺序可以影响其答复。即使按照相同顺序提出相同的问题,响应的细微差异仍然会发生。
结论
这项研究证实了AI聊天机器人解释肿瘤患者的MRI报告,识别关键管理特征并建议治疗的潜力。但是,将它们整合到临床实践中需要严格验证其反应,并仔细考虑隐私和道德标准。
数据可用性
当前研究期间和/或分析期间生成的数据集可从相应的作者根据合理的要求获得。
参考
Turkbey,B。等。多参数前列腺磁共振成像在评估前列腺癌中。Cancer J. Clin。 66(4),326 - 336。https://doi.org/10.3322/caac.21333(2016)。
文章一个 Google Scholar一个
Daniel,A。H.,Alnawaz,R。&Brian,D。R.扩散磁共振成像:肿瘤学治疗反应的生物标志物。J. Clin。Oncol。 25(26)。https://doi.org/10.1200/jco.2007.11.9610(2007)。
Nola,H。动态对比增强的磁共振成像作为成像生物标志物。J. Clin。Oncol。 24(20)。https://doi.org/10.1200/jco.2006.06.8080(2006)。
Mostafa,E。等。开发基于磁共振成像报告的自然语言处理算法,用于检测脊柱转移。N.脊柱学科。J. 19,100513。https://doi.org/10.1016/j.xnsj.2024.100513(2024)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Thurston,D。等。复杂脊柱病理学中磁共振成像和Spect-CT成像的比较:Spect-CT是否提供了磁共振成像的其他诊断信息?地球。脊柱。 14(7),1997年,2003年https://doi.org/10.1177/21925682231163812(2024)。
Lyles,C。R。等。使用电子健康记录门户来改善患者参与:研究优先事项和最佳实践。安。实习生。医学 172(11供应),S123 s29。https://doi.org/10.7326/m19-0876(2020)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Wan,M。M.,Cristall,N。D.&Cooke,L。J.神经病学家对姑息治疗的态度和看法:一项定性研究。神经。临床实践。 14(5),E200322。https://doi.org/10.1212/cpj.0000000000200322(2024)。
文章一个 PubMed一个 Google Scholar一个
Thirunavukarasu,A。J.等。医学中的大型语言模型。纳特。医学 29(8),1930年。https://doi.org/10.1038/s41591-023-02448-8(2023)。
文章一个 PubMed一个 Google Scholar一个
Sarangi,P。K.&Mondal,H。大语言模型产生的响应取决于提示的结构。印度J. Radiol。成像。34(3),574 - 575。https://doi.org/10.1055/s-0044-1782165(2024)。文章
一个 PubMed一个 PubMed Central一个 Google Scholar一个 Shah,N。H.,Entwistle,D。&Pfeffer,M。A.在医学中创建和采用大型语言模型。贾马
330(9),866 869。 https://doi.org/10.1001/jama.2023.14217(2023)。文章一个
PubMed一个 Google Scholar一个 Clusmann,J。等。大型语言模型在医学中的未来景观。
社区。医学(Lond)。3(1),141。https://doi.org/10.1038/s43856-023-00370-1(2023)。文章
一个 PubMed一个 Google Scholar一个 Singhal,K。等。大型语言模型编码临床知识。
自然。620(7972),172 - 180。https://doi.org/10.1038/s41586-023-06291-2(2023)。文章一个
广告一个 PubMed一个 PubMed Central一个 Google Scholar一个 功夫,T。H。等。Chatgpt在USMLE上的表现:使用大语言模型进行AI辅助医学教育的潜力。
PLOS数字。健康。2(2),E0000198。https://doi.org/10.1371/journal.pdig.0000198(2023)。文章
一个 PubMed一个 PubMed Central一个 Google Scholar一个 Chen,S。等。使用人工智能聊天机器人用于癌症治疗信息。
贾马·恩科尔(Jama Oncol)。9 (10),1459年1462年。https://doi.org/10.1001/jamaoncol.2023.2954(2023)。文章
一个 PubMed一个 PubMed Central一个 Google Scholar一个 Caranfa,J。T.,Bommakanti,N。K.,Young,B。K.&Zhao,P。Y.来自人工智能聊天机器人的玻璃体视网膜疾病信息的准确性。JAMA OPHTHALMOL。
141(9),906 - 907。 https://doi.org/10.1001/jamaophthalmol.2023.3314(2023)。文章一个
PubMed一个 PubMed Central一个 Google Scholar一个 Chen,D。等。医师和人工智能聊天机器人对社交媒体对癌症问题的回答。
贾马·恩科尔(Jama Oncol)。10 (7),956 - 960。https://doi.org/10.1001/jamaoncol.2024.0836(2024)。文章
一个 PubMed一个 PubMed Central一个 Google Scholar一个 Ali,S。R.,Dobbs,T。D.,Hutchings,H。A.&Whitaker,I。S.使用Chatgpt撰写患者诊所信件。柳叶刀数字。
健康。5(4),E179 e81。https://doi.org/10.1016/s2589-7500(23)00048-1(2023)。文章一个
PubMed一个 Google Scholar一个 Ayers,J。W。等。将医师和人工智能的聊天机器人与发布到公共社交媒体论坛的患者问题进行比较。
JAMA实习生。医学 183(6),589 596。https://doi.org/10.1001/jamainternmed.2023.1838(2023)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
伯恩斯坦,I。A。等。眼科医生和大语言模型聊天机器人对在线患者眼保健问题的回答的比较。JAMA NetW。打开。 6(8),E2330320。https://doi.org/10.1001/jamanetworkopen.2023.30320(2023)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Goodman,R。S.等。聊天机器人对医师问题的回答的准确性和可靠性。JAMA NetW。打开。 6(10),E2336483。https://doi.org/10.1001/jamanetworkopen.2023.36483(2023)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Sarangi,P。K.等。评估Chatgpt在简化医疗保健专业人员和患者的放射学报告方面的水平。肉质 15(12),E50881。https://doi.org/10.7759/cureus.50881(2023)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Miles,R。C。等。与需要手术的乳房病变有关的在线患者教育材料的可读性。放射学 291(1),112 - 118。https://doi.org/10.1148/radiol.2019182082(2019)。
文章一个 PubMed一个 Google Scholar一个
Haygood,T。M.患者素养和获取放射学信息。放射学。291(1),119 - 120。https://doi.org/10.1148/radiol.2019190007(2019)。
Rancher,C。E。等。揭示神经影像学的偶然发现:对健康素养挑战的定性主题分析。BMC Med。伦理。17(1),58。https://doi.org/10.1186/s12910-016-0141-1(2016)。文章
一个 PubMed一个 PubMed Central一个 Google Scholar一个 Natalie,J-W。,Glyn,E。&Adrian,E。知识不是患者的力量:系统的审查和主题综合患者报告的障碍和促进者共享决策。病人教育。
国家。94 (3)。https://doi.org/10.1016/j.pec.2013.10.031(2013)。Tasha,M。H.等。
关于患者报告的健康结果和医疗保健利用的共同决策协会。是。J. Surg。 216(1)。https://doi.org/10.1016/j.amjsurg.2018.01.011(2018)。
Zhan,Z。等。患者在理解实验室测试结果时面临的挑战和需求:混合方法研究。J. Med。Internet Res。 22(12)。https://doi.org/10.2196/18725(2020)。
Stormacq,C.,van den broucke,S。&Wosinski,J。健康素养是否调解了社会经济地位与健康差异之间的关系?综合评论。健康促进。int。 34(5),e1âe17。https://doi.org/10.1093/heapro/day062(2019)。
文章一个 PubMed一个 Google Scholar一个
博斯卡丁(C.学院。医学 99(1),22 27。https://doi.org/10.1097/acm.0000000000005439(2024)。
文章一个 PubMed一个 Google Scholar一个
Alonso,I。,Oronoz,M。&Agerri,R。Medexpqa:大型语言模型的多语言基准测试以进行医学问题回答。艺术品。Intell。医学 155,102938。https://doi.org/10.1016/j.artmed.2024.102938(2024)。
文章一个 PubMed一个 Google Scholar一个
Moor,M。等。通才医学人工智能的基础模型。自然 616(7956),259 265。https://doi.org/10.1038/s41586-023-05881-4(2023)。
文章一个 广告一个 PubMed一个 Google Scholar一个
Wankmã¼ller,S。在检索相关文档进行分析的背景下,分类问题的方法的比较。J. Comput。Soc。科学。 6(1),91 - 163。https://doi.org/10.1007/s42001-022-00191-7(2023)。
文章一个 PubMed一个 Google Scholar一个
Zhavoronkov,A。在生物医学中使用AI生成的含量的谨慎。纳特。医学 29(3),532。https://doi.org/10.1038/d41591-023-00014-W(2023)。
文章一个 PubMed一个 Google Scholar一个
致谢
作者承认以下财政支持:国家科学技术主要项目(2022ZD0116002);CAMS医学科学创新基金(2023-I2M-C&T-B-008)。
资金
作者承认以下财政支持:国家科学技术主要项目(2022ZD0116002);CAMS医学科学创新基金(2023-I2M-C&T-B-008)。
道德声明
同意出版
所有参与的作者都同意出版这项工作。
竞争利益
作者没有宣称没有竞争利益。
道德批准和知情同意
中国医学科学院北京联合医学院医院的学术伦理审查委员会为这项横断面研究提供了伦理审查的豁免(豁免号SZ-3192)。在这项研究中使用的所有数据都被取消识别,以确保人类受试者的隐私和机密性。The Institutional Review Board of Peking Union Medical College Hospital, Chinese Academy of Medical Sciences waived the requirement for the original informed consent and permitted secondary analysis without additional consent.The study adhered to the principles of the Declaration of Helsinki and followed the guidelines of the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE).
附加信息
Publisher’s note
关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
补充信息
以下是电子补充材料的链接。
权利和权限
开放访问本文在Creative Commons Attribution-Noncormercial-Noderivatives 4.0国际许可下获得许可,该许可允许任何非商业用途,共享,分发和复制以任何媒介或格式的形式,只要您提供适当的原始作者和来源的信用,请符合原始作者和来源,并提供了与Creative Commons的链接,并指示您是否修改了许可的材料。您没有根据本许可证的许可来共享本文或部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.To view a copy of this licence, visithttp://creativecommons.org/licenses/by-nc-nd/4.0/。重印和权限
引用本文

Bai, X., Feng, M., Ma, W.
等。Application of artificial intelligence chatbots in interpreting magnetic resonance imaging reports: a comparative study.Sci代表15 , 31266 (2025).https://doi.org/10.1038/s41598-025-17355-w
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41598-025-17355-w