
编码为AI进度的中心和通往一般代理的路径
作者:Nathan Lambert
编码由于其用例的广度,可以说是大多数人可以与之接触的边境模型的最后一个可延续的持续进度的一般域。这是一个大胆的主张,因此,让我们考虑Frontier模型话语中涵盖的其他一些关键能力:
聊天模型撰写的散文质量已经升级糊状。
数学有令人难以置信的结果,但很少有人直接从更好的理论数学中获得。
尽管如此,编码还是模型已经非常有用的领域,并且它们继续始终如一地堆叠有意义的改进。在过去的几年中,每天在附带项目中与AI一起工作,作为AI研究人员,很容易将这些编码能力视为理所当然,因为其中某些形式已经存在了很长时间。我们将一个错误刺入chatgpt,它可以解决它,或者自动完成可以通过整个样板进行标签。
这些用例听起来很良性,并且由于能力急剧攀升,因此在描述中没有发生任何变化。在1000多行代码中刺入GPT-5-Pro或Gemini Deep Thind Think认为是一种非常公平的策略。他们有时确实可以解决队友或我被困数小时至几天的问题。我们正在通过此摘要的功能列表进行进展:
功能完成:〜2021,原始github副驾驶(codex)
脚本:〜2022,chatgpt
建造小型项目:〜2025,CLI代理商
建造复杂的生产代码库,〜2027(估计,将因代码库而异)
编码也许是AI使用的唯一领域,我感到这种缓慢而逐渐改进。自GPT-4以来,聊天质量已经足够好了,搜索出现了,从那以后一直非常出色Openai的O3。在所有这些更令人兴奋的时刻,AIS编码能力刚刚逐渐逐渐改善。
现在,我们中的许多人开始通过这些新的命令行代码代理学习一种与AI合作的新方法。这是过去几年中AI编码能力的最大增长。问题在于,大多数人都习惯与AI合作的领域中的增加不是,因此采用进度要慢得多。新应用程序迅速建立用户,现有的分销网络几乎不适用。
与他们合作的最佳方法 - 我将分享更多有关我稍后在本文中已经构建的内容的示例 - 无论是新的定制网站还是一个脚本,都可以构建迷你项目。这些是企业家和研究人员的绝妙工具,他们需要一种方法来快速充实一个想法。现在可以在几个小时内尝试几天到几周的事情。在此,查看需要完成的代码的实际数量肯定是在下降。作为通过代理商进行的一项活动,编码的进入壁垒完全落在了相同的形式,即编码重新创建欢乐的行为。
我认为很多人都想念这些代理商的原因是,使用代理商的方法与模型所达到的令人难以置信的评估突破的营销截然不同。超人编码公告与使用代理商进行迷你项目之间的差距显然很大。使用代理商的最佳方法仍然是平凡的,需要仔细范围范围。
例如,昨天,2025年9月17日,OpenAI宣布那GPT-5作为模型系统的一部分获得的分数高于任何人(和Google的双子座思考)ICPC世界决赛``世界各地的顶级大学团队解决复杂算法问题。
我们与一系列通用推理模型竞争。我们没有专门为ICPC培训任何模型。我们同时拥有GPT-5和实验推理模型生成解决方案,以及选择要提交的解决方案的实验推理模型。GPT-5正确回答了11,最后(也是最困难的问题)通过实验推理模型解决了。
这些竞赛通常会被强调,因为它们重新有限的时间,因此该系统必须在固定时间内与人类相同的时间做出响应,但是GPT-5或其他模型的计算量可能远远高于任何用户访问。这主要表明可以从模型中提取进一步的能力,而这种能力可以从模型中提取,但是大多数人在被一般人群使用时受到脚手架和产品的限制。
真正的故事是,这些模型正在为越来越多的人提供越来越多的价值。
对于AI的追随者而言,使用AI模型编码是最简单的感觉。现在,模型非常擅长聊天,需要非常专业的任务来测试模型的一般知识,否则许多收益都在获取正确的答案方面。快点比gpt-5思想的曲折路径。
我不是专家软件工程师,模型之间的巨大差异以及各个模型和系统正在做出的改进,这是非常明显的。
我多次说过,克劳德代码(或现在的法典)比光标代理好得多,光标代理远比Github Copilot好得多。Github Copilot感觉到方向盘醉酒。光标通常在仍然很聪明的同时感到有些分心,但是Claude Code和Codex似乎在主题上,并且能够在手头问题上测试模型的智能。是的,即使是最好的代理商也经常在复杂的代码库中足够好,但是它消除了在聊天窗口中来回走动的必要性,以查看模型是否可以为您达到难题的末尾。这些CLI代理可以运行测试,解决GIT问题,运行本地工具等。范围正在不断增长。
对于Claude Code vs codex CLI的细微差别,答案很昂贵。最好的是Claude Code强迫Claude Opus 4.1,但是Codex不远,并且以一个便宜得多的入口点(每月20美元)的价格出现。Codex还具有诸如Web搜索之类的不错的功能,但是在我的使用方面,它并不是一个主要的区别。1新的工作流程是在无法解决当前问题的情况下切换到另一个代理,并让它用新鲜的眼睛看到存储库,就像您将问题粘贴到另一个聊天机器人上一样。
代理商只有一个标签,就像竞争对手进行聊天一样。
在上面的克劳德(Claude),光标和副驾驶的比较中,关键的组成部分是所有这些试剂都可以通过相同的克劳德4十四行诗模型进行测试。与我所说的那样宽阔的差距,强调了编码代理中的许多收益仅在产品实施中。第二个版本对我来说有点令人尴尬,但是在尝试新的GPT-5-Codex模型时,我没有更新OpenAi Codex代码,这导致了通过更改它立即增加性能。在AI的最前沿具有一个域名,这是一种新现象能力在模型的软件脚手架的情况下,人们感到非常强烈。产品和提示比以往任何时候都重要,这种感觉将扩展到更多的域。
这为什么即使使用相同模型值得居住,这些性能差异也是如此。Claude团队在一般软件工程和产品设计方面的不可能好得多,而人类在从模型中提取最大的内部内部经验。当前模型的转变是关于如何采用一组用于问答和其他单流文本任务并分解问题的模型。在我的下一代推理模型的分类学,我称这种能力抽象。
只需将模型稍微转移到该任务的需要就解释了Openai的最新专业模型,GPT-5-Codex。GPT-5主要是关于平衡Openai的书籍与用户群以聊天格式接近1B活动用户的发行版。GPT-5是一项不同工作的磨练工具。评估分数是轻微地比这款新的GPT-5-Codex的一般推理模型要好,但是主要收益在于行为在编码任务方面的不同程度。
GPT 5-Codex适应了它花费了多少时间根据任务的复杂性进行动态思考。该模型结合了编码代理的两个基本技能:与交互式会话中的开发人员配对,并在更长的任务上持续独立执行。这意味着Codex在小的,定义明确的请求或与之聊天时会感到更挑剔。在测试过程中,我们已经看到GPT 5-Codex一次独立地工作了7个小时以上的工作,完成了大型,复杂的任务,迭代其实施,修复了测试失败,并最终实现了成功的实施。
它们包括了这个令人困惑的情节,以展示这种动态。当我更新Codex软件和Codex模型时,我当然会感受到这些更改。
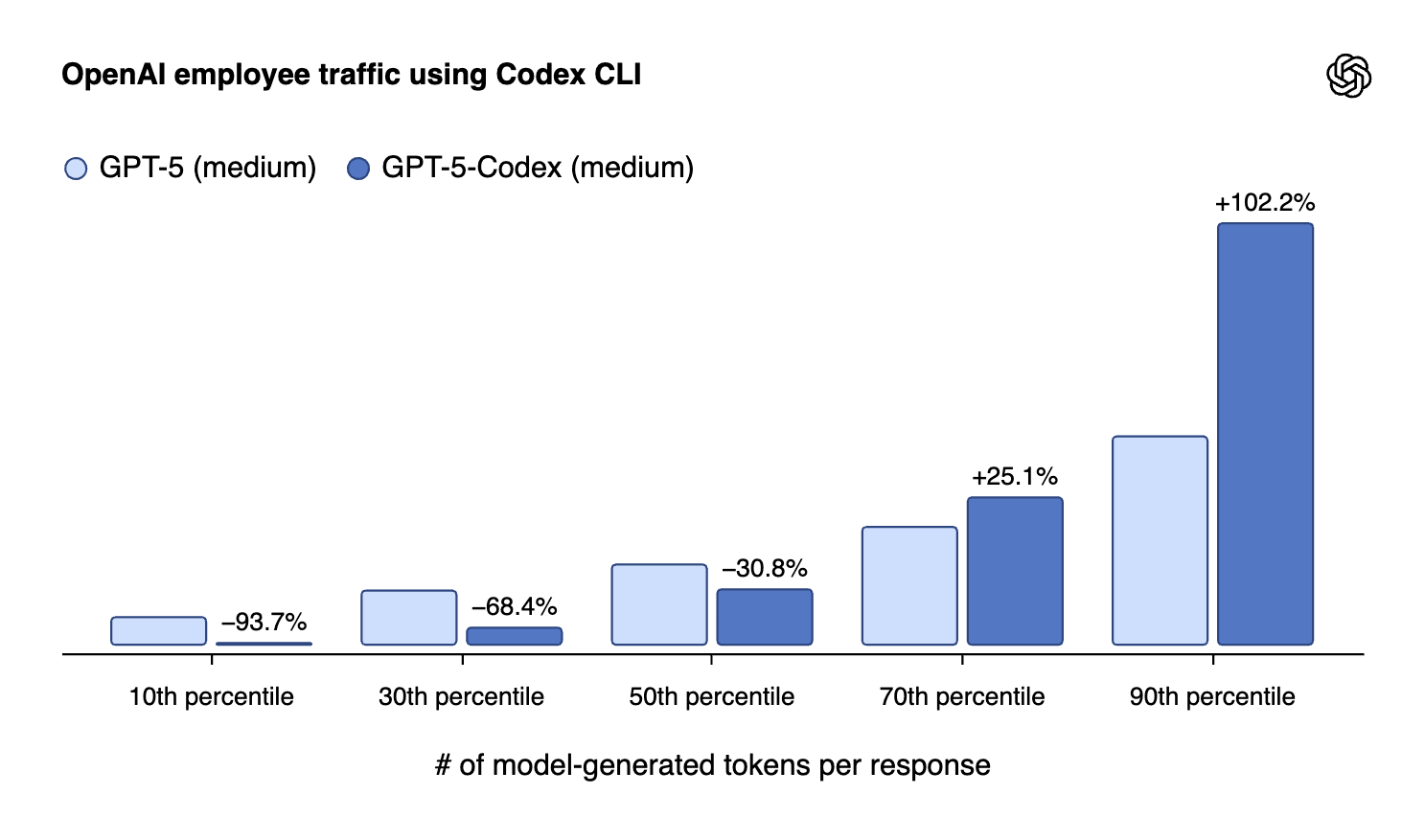
这代表了我在分类法校准中提出的另一个关键问题,即不会过度思考。
拥有专业模型和用例的专业产品可能会使人们认为自己正在缩小以取得进展,但是在Openai的情况下,他们的双手在财务上是紧密的,以支持主要的ChatGpt应用程序。克劳德已经完全致力于代码。这是由于空间可以扩展到的大小。
这些编码代理肯定会被视为所做的不仅仅是编写代码。是的,他们的主要能力将是编写代码本身并执行代码,但是启用是一种与计算机合作的全新方法。
在我的帖子中关于持续学习的反对德瓦克什,我提出了一种观点,即将为您的所有数字工作环境提供代理商,以便成为24/7的研究或社论助理。我开始将其用于互连,在那里我将代理商给我的所有文章,元数据,访谈和细节,因此我可以要求他们提供有关以后帖子的相关参考和上下文。这是一个非常不足的烤制,并且是一个项目,可以在我的40万个写作代币上有效地搜索,但是我促使它几次看到了这篇文章的任何有趣的参考,这给了我一些有用的东西!
这引用了我罗斯·泰勒(Ross Taylor)采访被发现共鸣7月使用编码代理:
我对Claude代码的主要担忧是……人们混淆了代理商,使您更有生产力,而不是阻止您付出心理努力。因此,有时候我会有一天的Claude代码,我觉得自己很少的精神努力,这感觉很棒。然后,代理商倾向于挣扎并进入这些怪异的线路搜索末日循环。
对于非常复杂的生产代码库来说,这种情绪仍然是正确的,但是末日循环的可能性正在下降。同时,快乐和精神上的轻松仍然适用。
最近,我与Claude Code或Openai的Codex CLI混合构建的一些示例包括:
原始的HTML我的RLHF书的网站为了比较SFT与RLHF训练的模型的响应(以及对RLHF书籍本身的改进)。
制作存储库使用互连的所有帖子和内容,因此我可以在写作时使用编码代理作为编辑助手。
改进原子项目网站。
将我的个人网站从WebFlow的系统中删除(这是研究生院期间注册的错误),包括CMS条目和其他详细页面。
我日常工作培训模型中的其他小脚本和工具。
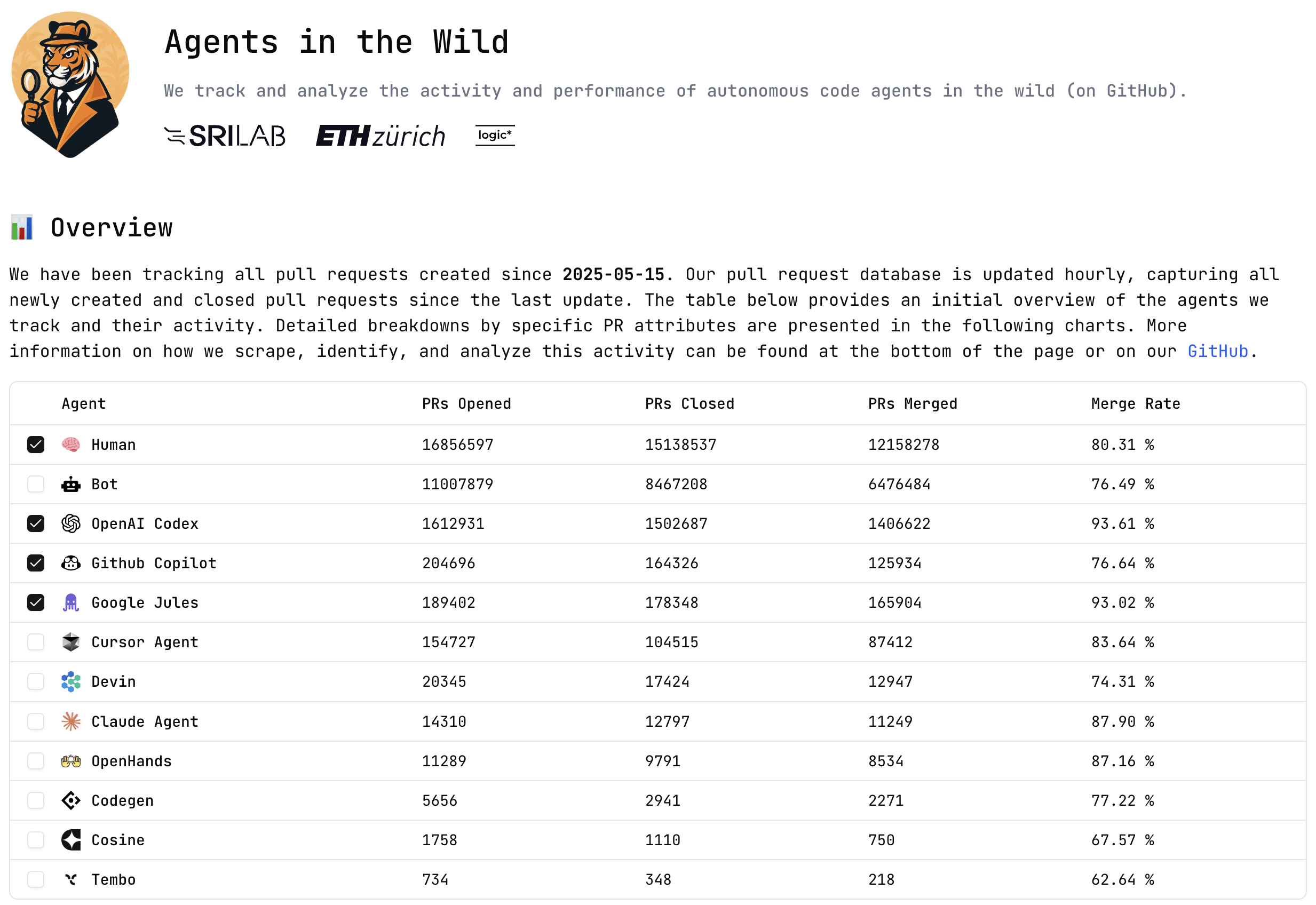
这不仅是我用这些广泛的建设。有多个致力于跟踪这些模型的公共贡献的开源项目 -Prarena和野外的特工。
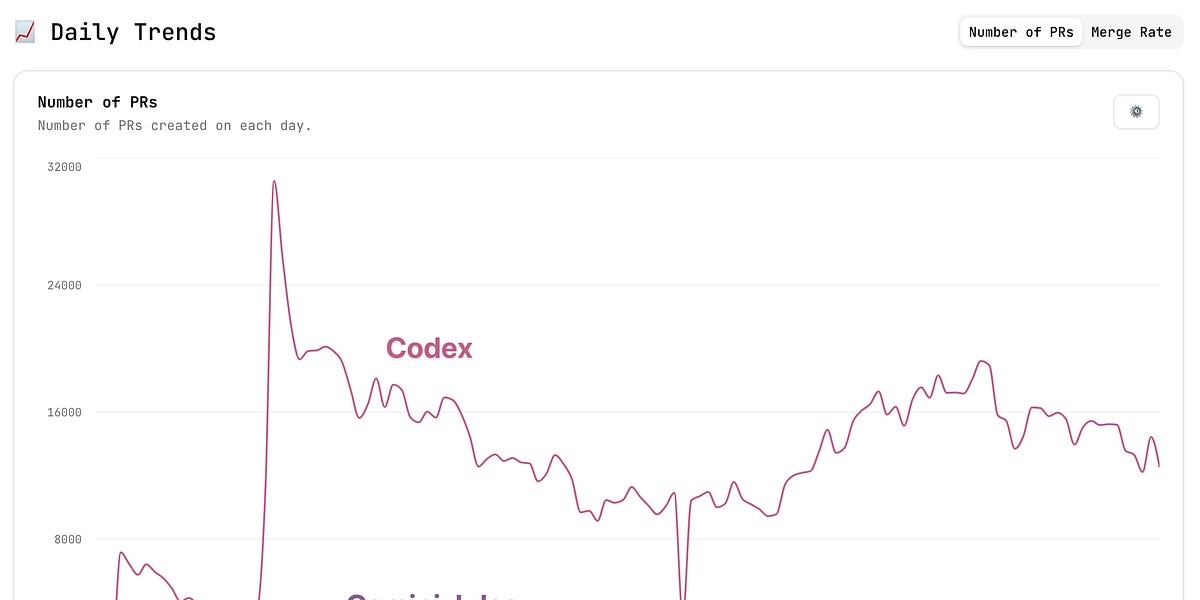
Prarena的仪表板显示,超过100万个PR从Codex Web代理商中合并,使许多竞争对手相形见war。即使Codex的Web App版本远离当今CLI代理的时代精神,这是OpenAI可以使用分配的力量。
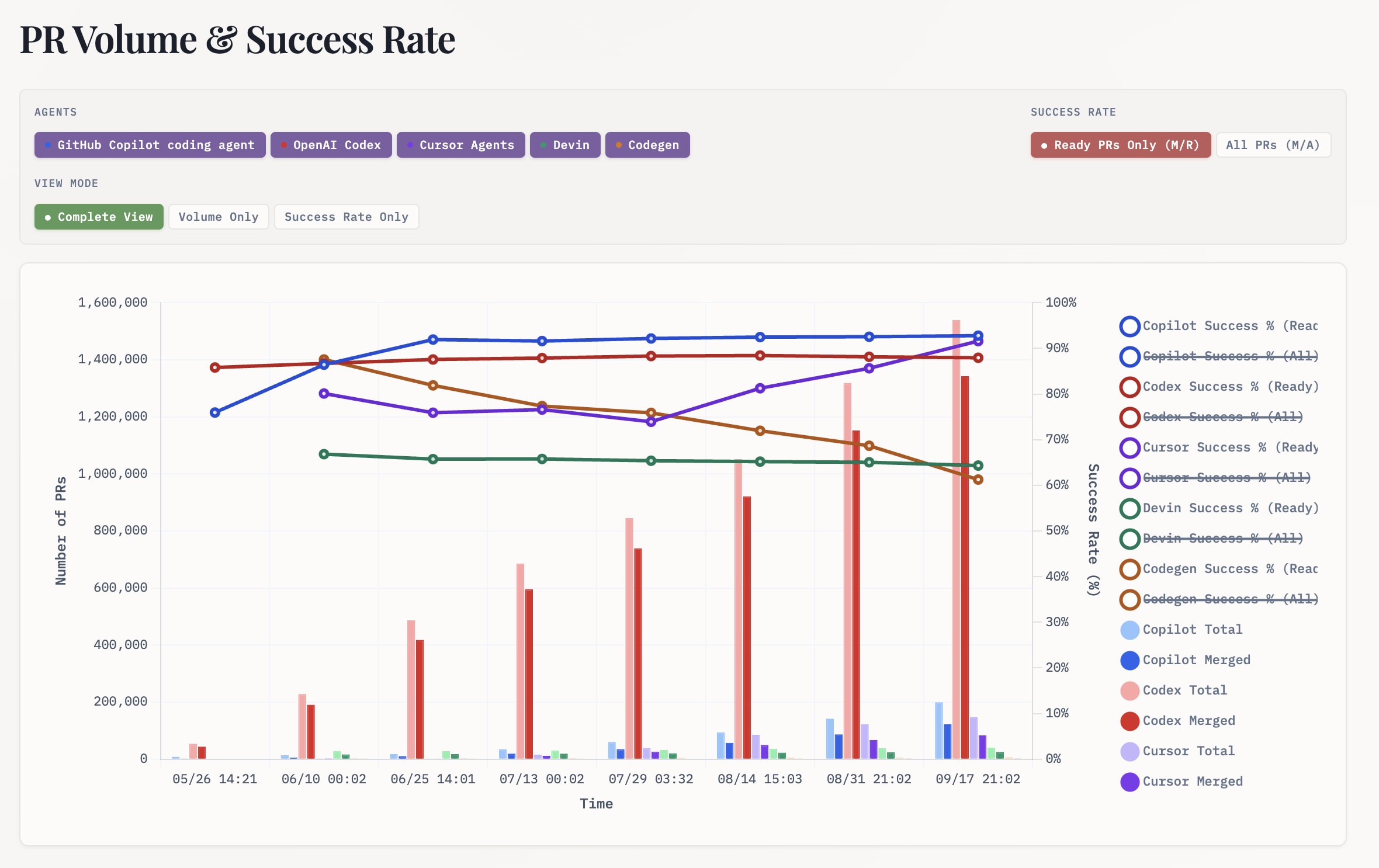
这带有方法论的著名星号,可以解释类似仪表板中的许多差距:
一些代理喜欢法典私下迭代并直接创建现成的PR,导致很少的草稿,但合并费率很高。其他人喜欢副驾驶和代码根首先创建PRS草案,鼓励公众迭代,然后将其标记为审查。
以下统计数据重点仅准备PR为了公平地比较不同工作流程中的代理商,无论它们是公开迭代(使用草稿)还是私人迭代,都可以衡量每个代理商生成可合并代码的能力。
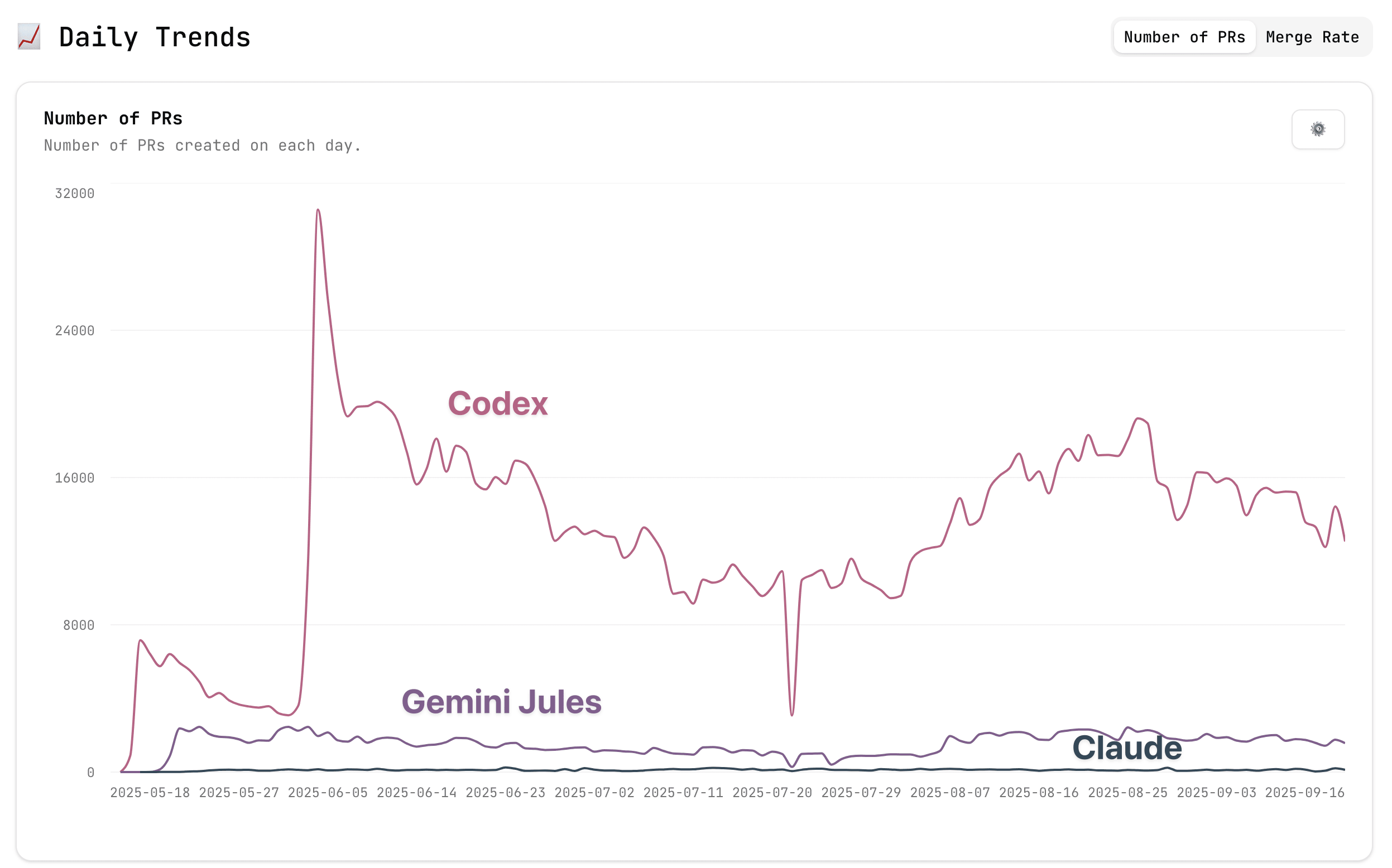
另一个仪表板是野外的特工,表明Openai的编码剂只是人类落后于人类的一个数量级,而PRS中的其他自动化则只是一个数量级。
将此视为相对于双子座或克劳德(Claude)的视角:
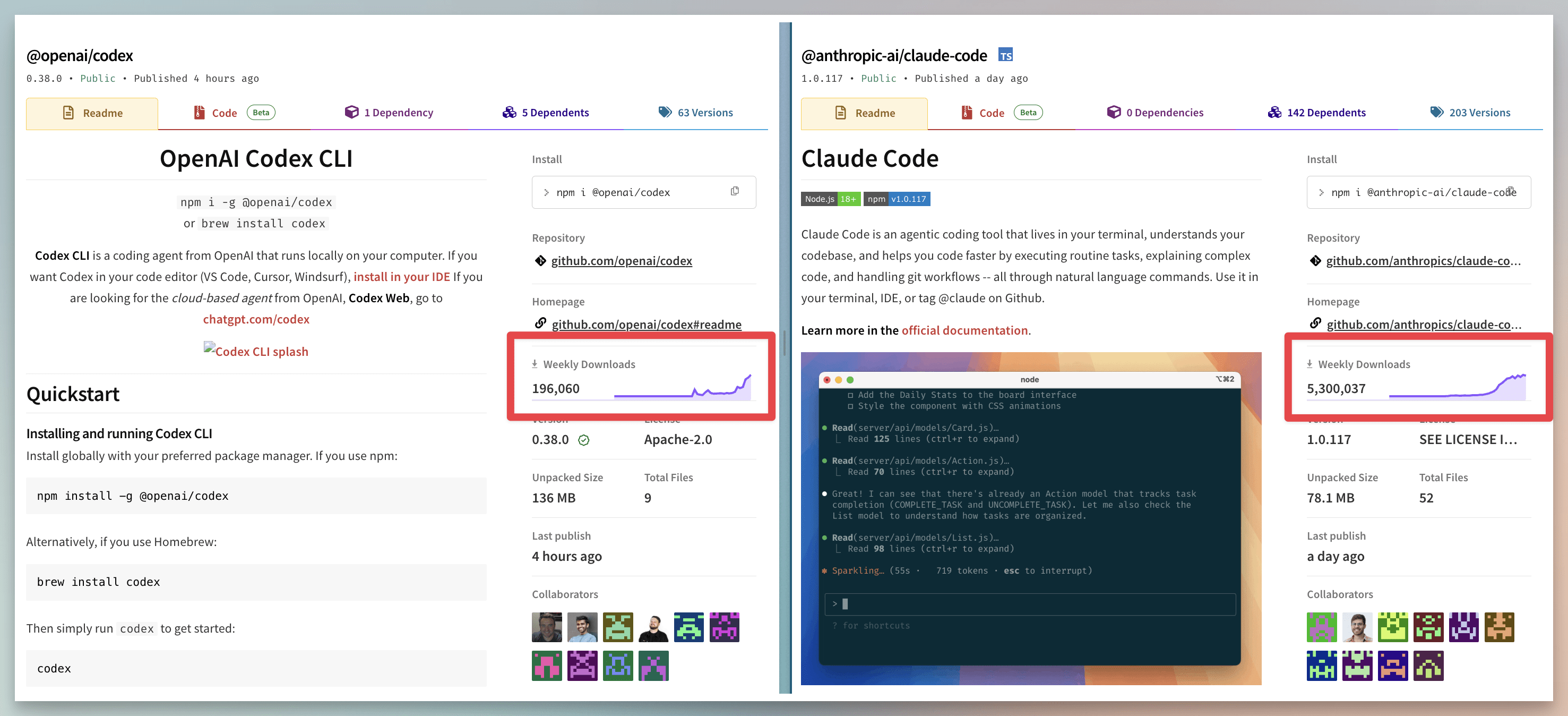
与此的上下文是Claude代码是远的与OpenAi的CLI代理码相比,下载更多,但默认情况下,它并不以相同的巧妙方式使用分支机构中的代理名称。Claude代码在上周在NPM上的Codex下载超过20倍。
尽管有测量的挑战,但很明显,编码剂正在脱颖而出。
上面的法典PR实际上表示Web代理,具有默认的分支名称行为,而不是CLI代理。这表明了OpenAI分布的力量,当成千上万的人首次尝试新工具时,实际上合并了多少PR(超过80%),这令人印象深刻。
Web代理和CLI代理之间的主要区别是降低了交互性。CLI代理商提出计划并寻求反馈,或者让您监视和中断。Web上的codex在一个系统中将其与CLI代理相似,该系统一直运行,直到可以打开PR为止。
随着时间的流逝,编码只会获得更多的异步,如果很快发生,Openai就可以捕获这种过渡。基于上述所有证据,编码模型越来越有能力,转移到该软件的新UX将比人们预期的要快。对完全自主编码的过渡将很快发生在编码模型的类型中,在这种情况下,编码模型在脚本,网站,数据分析等方面都可以正常工作。后来,复杂的生产代码库将在较低级别的堆栈,CLI代理以及其他既可以交互式又最适合吸收内容的事物中效果最好。
在几年之内,这两个趋势将融合自主代理的功能,并且可以通过AI改善最复杂的代码库。然后,一切都可以返回聊天机器人窗口。对于大多数人来说,不必查看代码将是一个可喜的变化。
编码的进度感觉比过去的模型世代之间的紧急能力慢,这使得更容易跟踪。这是由于包含编码的行为的范围有多大,但导致了学习AI模型如何发展和迭代的绝佳领域。在未来几年,Frontier Labs将多次使用该剧本,因为AI模型被教导解决更具挑战性的任务。
发生了一场安静的革命,为了真正理解它,您需要参加。去建立一些东西。