

介绍OpenZL:开源格式感知压缩框架
- 是一个新的开源数据压缩框架,为结构化数据提供无损压缩。OpenZL旨在提供特定于格式的压缩机的性能,并易于维护单个可执行的二进制。
- 您可以从今天开始访问我们的OpenZL
- 快速启动指南和一个 OpenZL GitHub存储库。了解更多有关
- 这张白皮书中的OpenZL背后的理论。今天,我们很高兴宣布公开发布
OpenZL,一个新的数据压缩框架。OpenZL为结构化数据提供无损压缩,性能与专用压缩机相当。它通过将可配置的变换序列应用于输入来实现这一目标,从而揭示了数据中的隐藏顺序,然后更容易被压缩。尽管为每种文件类型应用不同的转换排列,但所有OpenZL文件都可以使用相同的Universal OpenZL解压缩器进行解压缩。
十年的课程
什么时候Zstandard宣布,它具有一个简单的音调:它承诺具有先验默认值相同或更好的压缩率,但以数据中心工作负载所需的速度提高了。通过将强力熵编码与充分利用现代CPU功能的设计配对,Zstandard提供了实质性的改进,证明其在数据中心中的存在是合理的。
但是,尽管随着时间的流逝得到了改进,但仍保留在Zstandard框架内,可减少回报。因此,我们开始寻找数据压缩的下一个巨大飞跃。
在此任务中,一种模式不断重复:在结构化数据上使用通用方法在表上压缩增益。数据不仅是字节汤。它可以是柱状,编码枚举,仅限于特定范围,也可以携带高度重复的字段。更重要的是,它具有可预测的形状。倾斜到该结构的定制压缩机可以以比例和速度击败通用工具。但是,每个定制方案都意味着另一个压缩机和解压缩器来创建,运输,审核,补丁和信任。
OpenZL是我们对格式特异性压缩机性能与单个可执行二进制的维护简单性之间的紧张关系的答案。
显式结构
通用压缩机依赖于一种尺寸适合所有处理策略,或者花很多周期猜测要使用哪种技术。OpenZL通过使结构为显式输入参数来保存这些周期。然后,压缩可以集中在编码之前表面图案的一系列可逆步骤。
作为用户,您为OpenZL提供了数据形状(通过预设或薄格式描述)。然后,培训师是一个离线优化组件,构建了一个有效的压缩配置,可以重新雇用用于类似数据。在编码过程中,该配置将分解成嵌入框架中的具体解码食谱。通用解码器将直接执行该食谱,而无需任何带外信息。
使用OpenZL的示例压缩
例如,让我们压缩sao,这是西里西亚压缩语料库。该文件遵循定义明确的格式每个记录都有一系列记录,每个记录都描述了一颗星星。将此信息提供给OpenZL足以使其比无限损耗的压缩机具有优势,仅看到字节。
使用Clang-17对M1 CPU进行比较
| 压缩机 | ZSTD -3 | XZ -9 | OpenZL |
| 压缩大小 | 5,531,935bâ | 4,414,351 b | 3,516,649 b |
| 压缩比 | x1.31 | x1.64 | X2.06 |
| 压缩速度 | 220 MB/s | 3.5 MB/s | 340 MB/s |
| 减压速度 | 850 MB/s | 45 MB/s | 1200 MB/s |
至关重要的是,OpenZL产生较高的压缩比同时保留甚至提高速度,这对于数据中心处理管道至关重要。
为了进行说明,使用以下简单图来实现此结果:
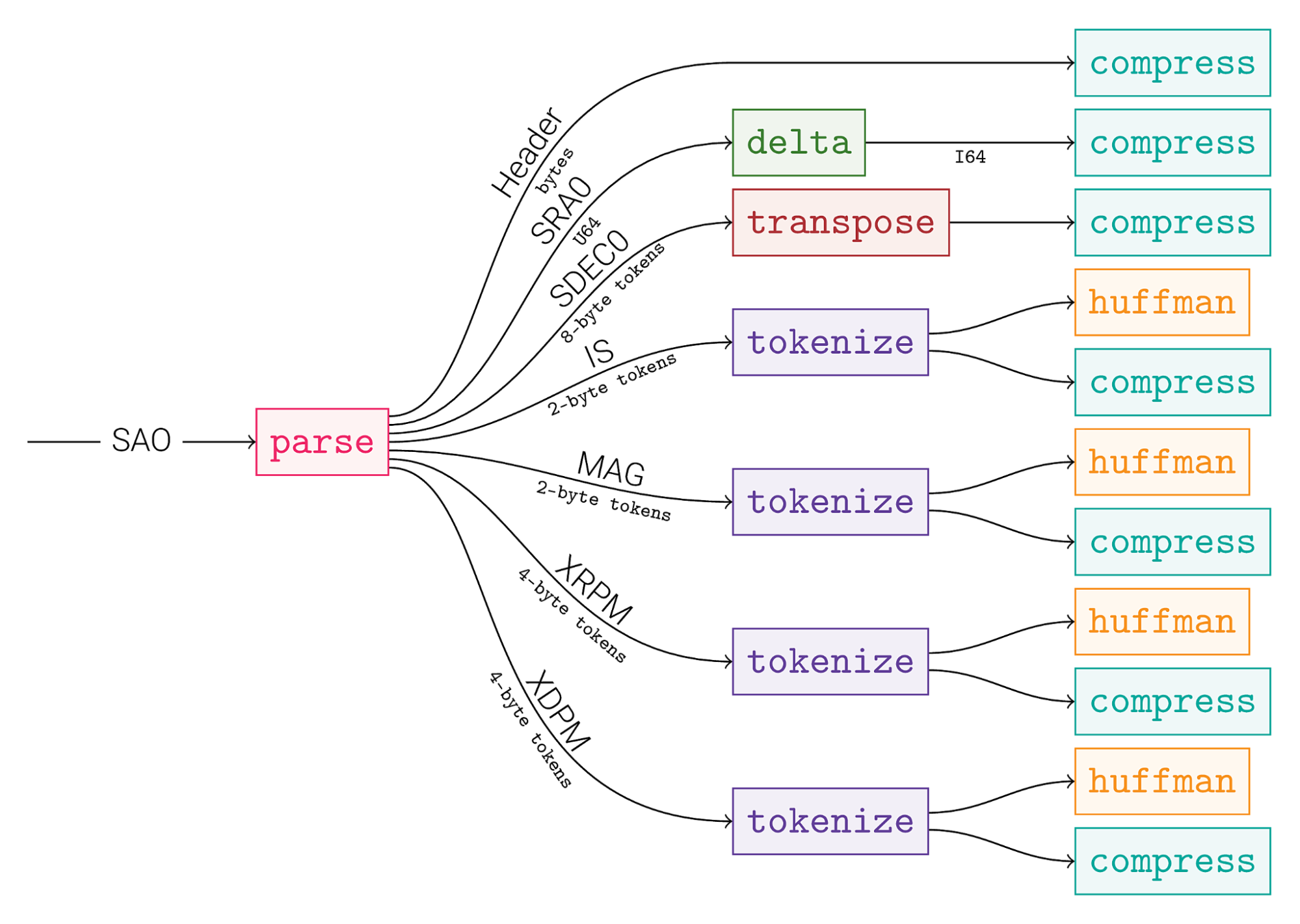
简短的解释
那么在此示例中发生了什么?
我们首先将标头与其余部分分开,这是一大桌结构。然后将每个字段提取到自己的流中:结构的数组成为数组的结构。此后,我们期望每个流都包含相同类型和语义含义的均匀数据。现在,我们可以专注于为每个策略找到最佳的压缩策略。
- SRA0是X轴上的位置。由于表的生成方式,索引为大多分类,邀请使用三角洲减少代表的值范围。这使生成的流更容易压缩。
- SDEC0是Y轴上的位置。它的分类不如X轴,但我们至少可以利用它在最小值和最大值之间的界限。这使得较高的字节更可预测,可以利用它转置手术。
- 其他字段(是,,,,杂志,,,,XRPM,,,,XDPM)共享一个共同的特性:它们的基数远低于其数量,并且连续2个值之间没有关系。这使它们成为一个很好的目标令牌,将将流转换为字典和索引列表。
- 由此产生的词典和索引列表非常不同。它们从完全不同的压缩策略中受益。因此,它们被发送到专用处理图。
该图超出了这些步骤。但是在某个时候,我们也可以停止做出决定。主要工作是将数据分组为均匀的流。之后,可以指望OpenZL照顾其余的。
为了进一步发展,我们想生成针对每个流的专门调整的压缩策略。这是离线教练舞台发挥作用
自动生成压缩机
可以完全控制压缩过程,但也不需要。更快的策略是仅描述您的数据并让系统学习压缩配置。
描述输入:与简单数据说明语言(SDDL),您可以绘制字节映射到字段,列,枚举,嵌套记录。SDDL仅用于解析;它只是告诉OpenZL您的数据形状。另外,您可以使用一种受支持的语言直接编写自己的解析器函数,并向OpenZL注册以委派逻辑。
学习配置:从预设,解析器函数或SDDL描述开始培训师对变换选择和参数进行预算搜索以产生计划。它可以提供一套全套的速度/比率权衡,或直接针对符合某些速度约束的最佳配置。在内部,它使用群集查找器(对表现相似的组字段)和图形资源管理器(尝试候选子图并保持得分)。
在Encode-time上解析:在压缩时,编码器将计划变成混凝土食谱 -解决图。如果计划具有控制点,它将选择适合数据并记录该选择到框架的分支。
不协调的解码:每个框架块都带有自己的解决图。单个解码器检查它,执行限制并按顺序运行步骤。当计划改善时,您只需发布新计划,就不需要新的解压缩器。旧数据一直在解码;新数据得到改善的收益。
在实践中,循环很简单:描述(SDDL)train(制作计划)压缩(带有分辨率图的发射帧) - 与相同二进制的任何地方解码。
拥抱变化:重新训练和机上控制
在现实世界中,数据在结构和内容上都不断发展。为一个版本的模式构建的压缩机将有较短的一生。
值得庆幸的是,有了压缩计划提供的灵活性,我们可以迅速对数据更改做出反应。在Meta,这是托管压缩,最初创建的是为了自动化字典压缩,并在较早的博客中介绍关于我们如何通过zstandard改善压缩。一个
OpenZL提供了一个培训过程,该过程根据提供的数据样本更新压缩计划,以维持或改善压缩性能。现在,具有托管压缩的协同作用很明显:每个注册的用例都经过监视,采样,定期训练,并在证明有益的情况下会收到新的配置。减压侧继续解码旧数据和新数据,没有任何更改。
运行时改编:压缩配置可以包括控制点在压缩时间(例如,字符串重复统计,运行长度,直方图偏斜,三角洲差异)读取轻巧的统计信息,然后选择计划中最佳分支机构。可以使用许多技术,教科书分类器符合条件。控制点处理爆发,离群值和季节性转移而没有蛮力探索:勘探是有限的,以保持速度期望。然后将所需的分支记录到框架中,而解码器只是执行记录的路径。
这给出了两全其美的最好的:在压缩时间的动态行为,以处理变化和异常,而无需将压缩变成无界的搜索问题,并且将零复杂性添加到解码器中。
通用解码器的优势
OpenZL能够压缩大量的数据格式,并且可以通过单个解压缩器二进制进行解压缩。即使压缩配置更改,解码器也不会。这听起来像是运营的细节,但对于OpenZl的部署成功至关重要。
- 一个经过审核的表面:安全性和正确性评论集中于具有一致不变,模糊和硬化的单个二进制文件;没有各种各样的工具可以散开。
- 机队范围的改进:解码器更新(安全性或性能 - SIMD内核,内存界限,调度)都会使每个压缩文件,甚至是更改更改的文件。
- 操作清晰度:跨数据集相同的二进制,相同的CLI,相同的指标和仪表板;设计和推出的设计很顺利。
- 连续培训:有了一个解码器和许多压缩计划,我们可以在系统实时改进。离线训练计划,在小切片上尝试一下,然后像任何其他配置更改一样将其推出。向后兼容性是内置的 - 旧帧仍在解码,而新帧变得更好。
换句话说,可以在不破坏生态系统的情况下提供特定于领域的压缩。
带有OpenZL的结果
当OpenZL能够理解和解析文件格式时,它可以提供大量改进的压缩比,同时仍提供快速的压缩和减压速度。但是,这不是神奇的子弹。当OpenZl不了解输入文件格式时,它就落后于ZSTD。
OpenZL通过其离线训练功能,还能够在压缩比,压缩速度和减压速度的权衡空间中提供广泛的配置。与传统压缩机通过设置压缩级别提供配置的传统压缩机不同,OpenZL通过序列化压缩机图提供配置。这允许选择各种权衡的灵活性。
这些结果基于我们VE的数据集为我们的白皮书开发。之所以选择数据集,是因为它们是高度结构化的,并且以OpenZL支持的格式。下面的每个数字都是由OpenZL存储库中的脚本因此它们可以复制,并且我们的运行中的输入数据和日志已上传到Github。
请注意,一条线连接的数据点是帕累托最佳的。所有此类点都具有同一数据集中没有意义的属性,可以在两个指标中击败它们。
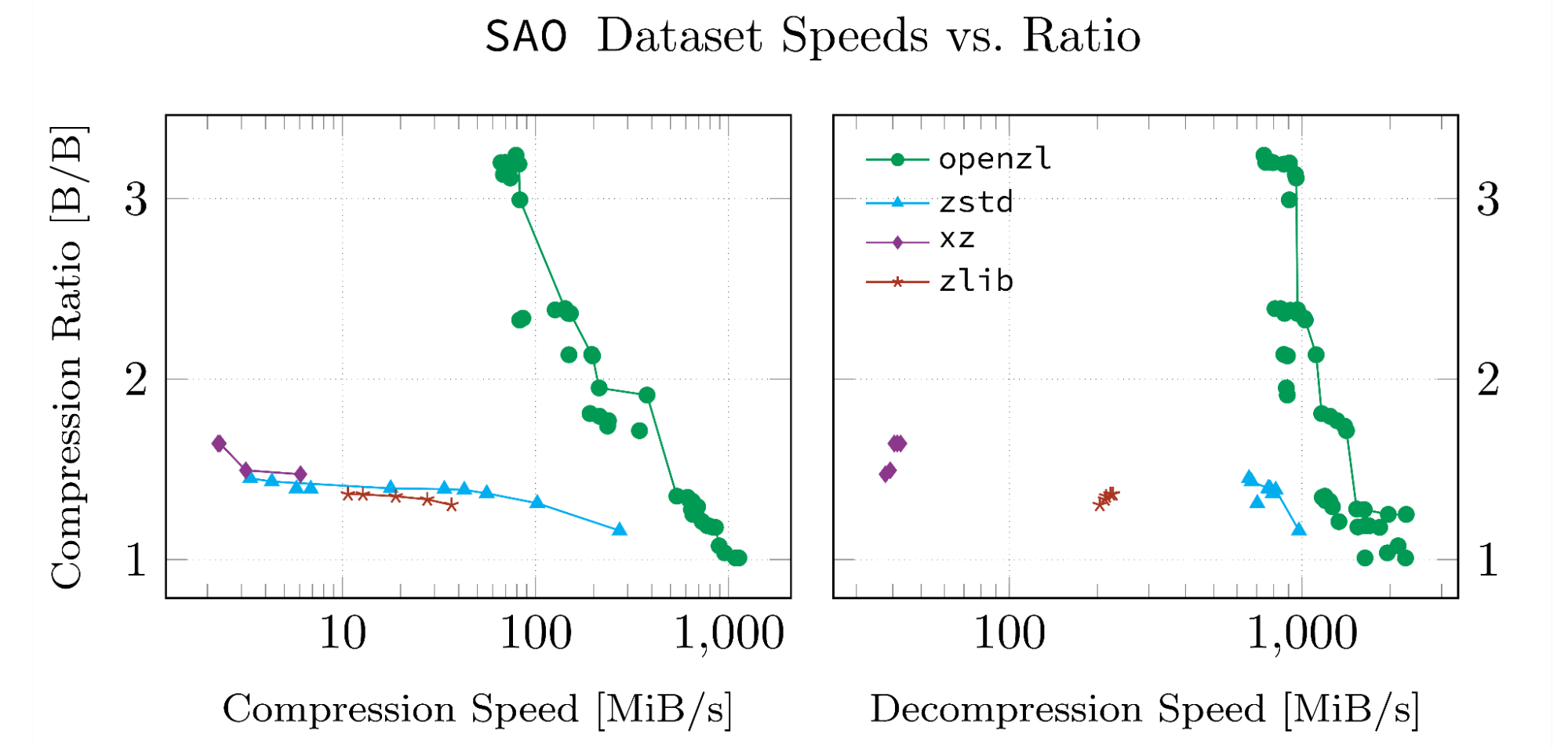
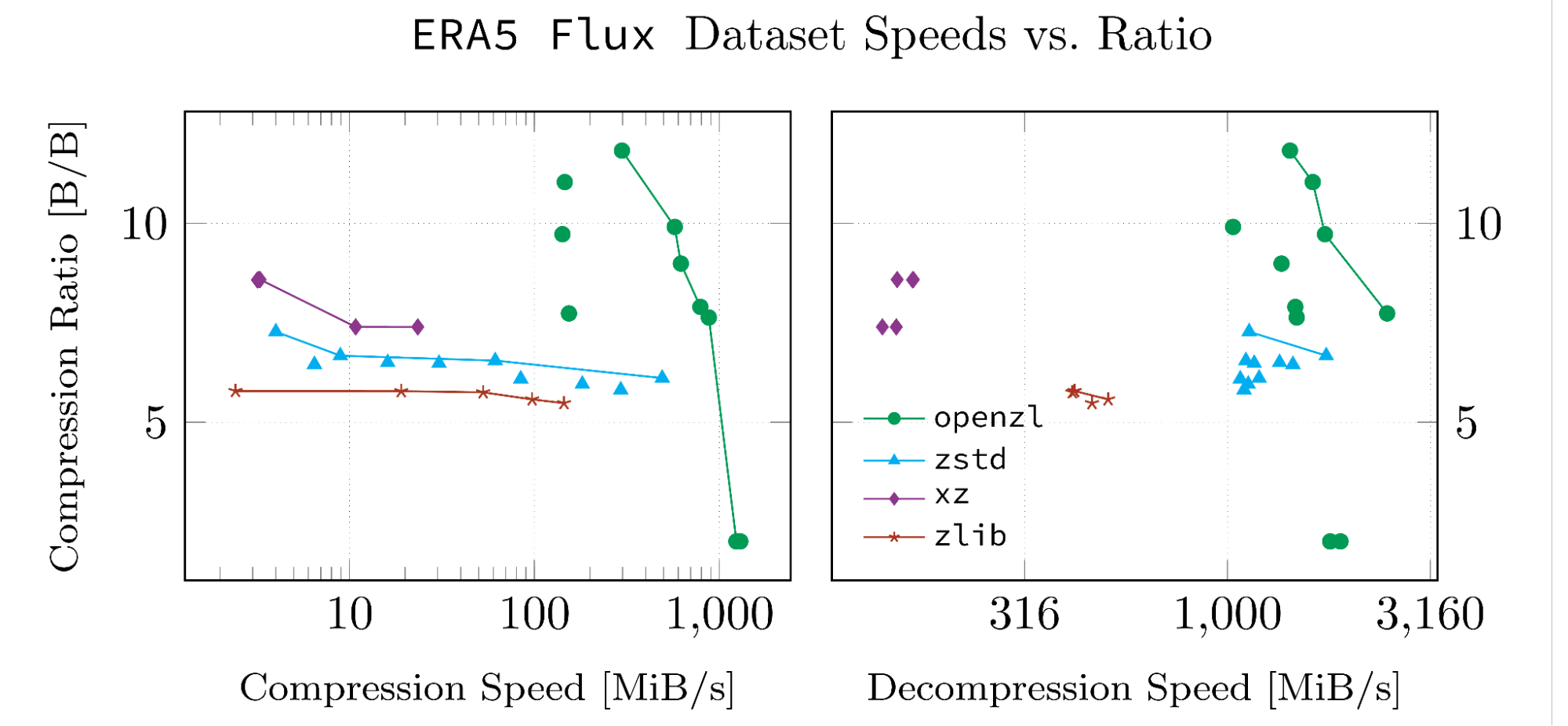
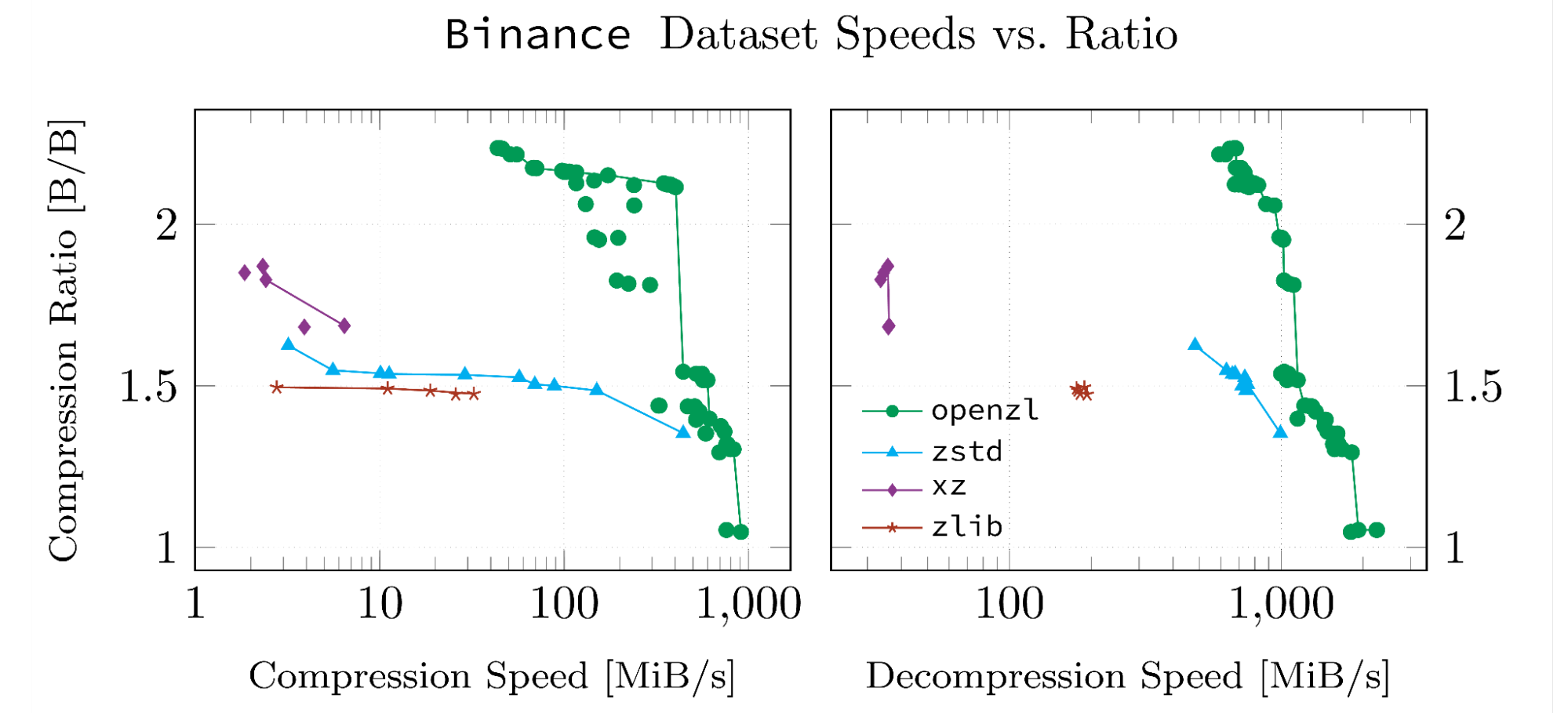
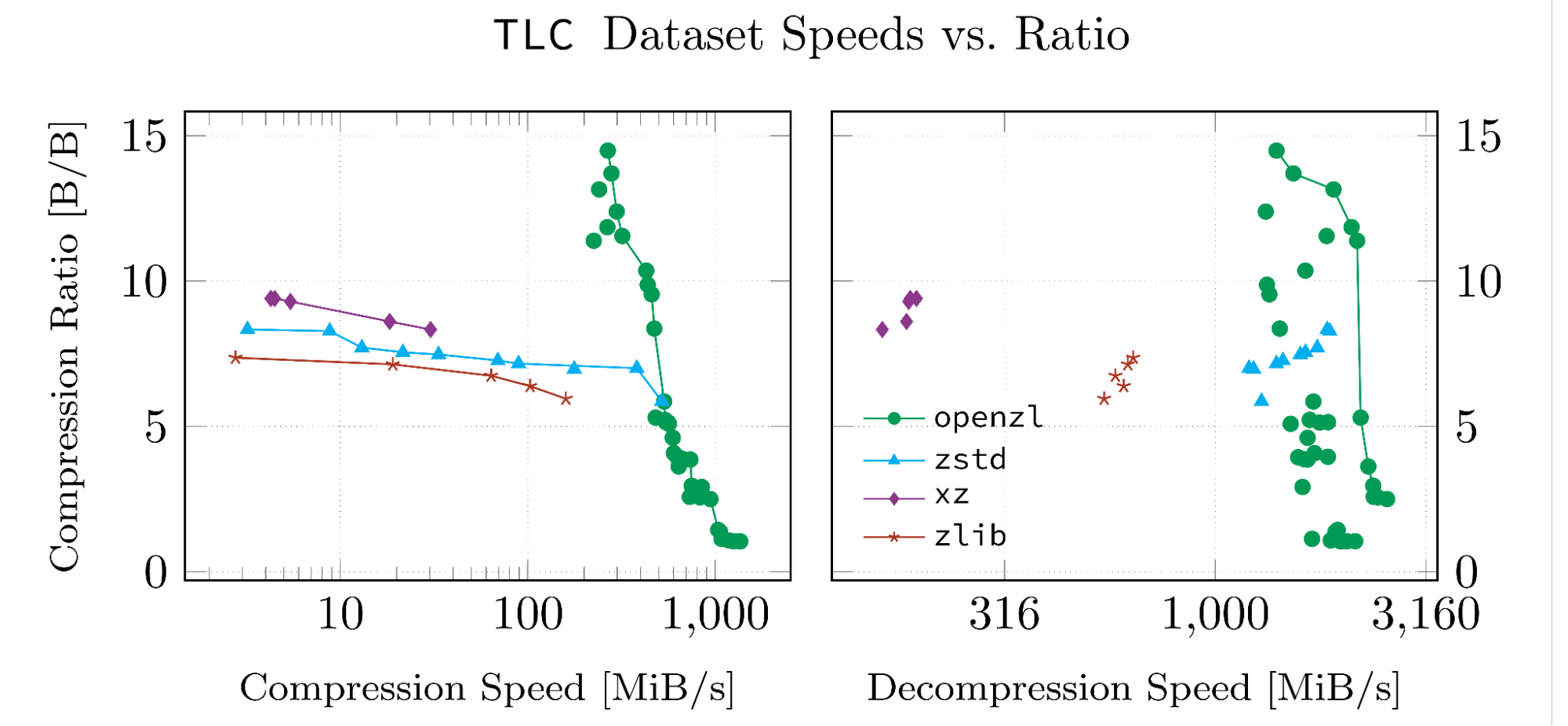
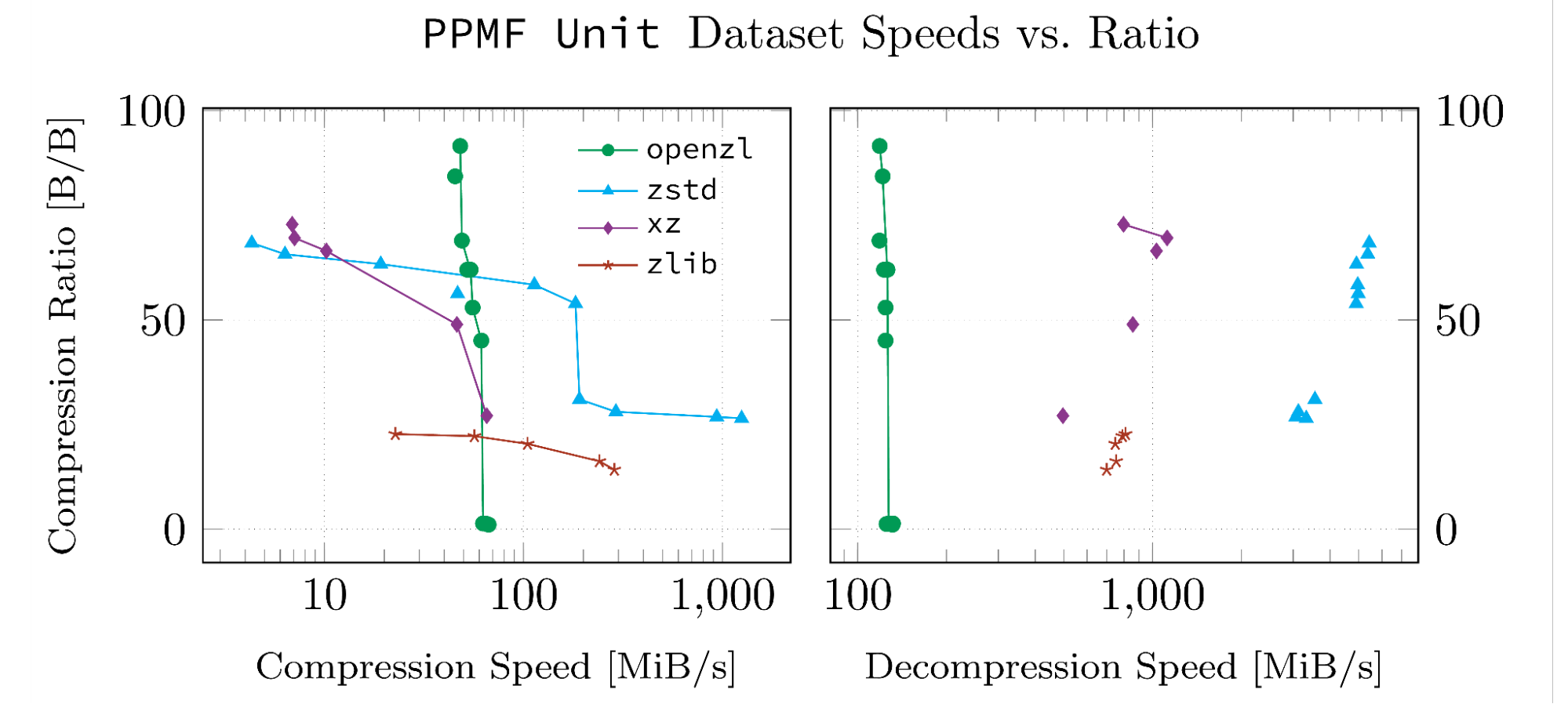
当它没有用
OpenZL依靠某种结构的描述来利用其一组转换。当没有结构时,就没有优势。纯文本文档中通常是这种情况,例如恩威克或者狄更斯。在这些情况下,OpenZL跌回ZSTD,提供基本相同的性能水平。
开始使用OpenZL
OpenZl的编解码器选择非常适合压缩向量,表格或树结构的数据,并且可以预期使用数字,字符串或二进制数据来表现良好。常见的示例包括时间工程数据集,ML张量和数据库表。请记住,我们受信息理论限制的约束,因此输入需要有一些可以发现的顺序。随着时间的流逝,我们计划合并其他编解码器,如下一节所述。
如果您的数据适合上述类别之一,请尝试一下!参观OpenZL网站还有我们的快速启动指南开始。
如果您想潜入代码,请查看 GitHub存储库用于来源,文档和示例。我们欢迎社区的捐款和反馈!
我们要去哪里
设定了OpenZL的一般方向:使揭露结构变得更容易,并使用自动化的压缩计划来利用它的发展数据。
接下来:我们重新扩展了时间序列和网格形数据的变换库,提高编解码器的性能,并使培训师能够更快地找到更好的压缩计划。我们还在积极努力扩展SDDL,以更灵活地描述嵌套的数据格式。最后,自动化压缩机资源管理器在指定预算内对压缩计划的安全,可测试的更改变得更好。
社区可以提供帮助的地方:如果您的格式或具有明显结构的数据集,请尝试使用OpenZL预先构建计划对其进行压缩。如果有希望,请尝试与培训师一起生成新计划,或者通过我们的文档对其进行自定义以改进它。如果是公众可能想要的格式,请以公关的方式发送给我们。
您也可以为OpenZL核心做出贡献。如果您有用于优化C/C ++的诀窍,请帮助我们加快发动机或添加变换以涵盖新的数据格式。如果您的超级力量是可靠性的,那么该项目肯定会从更多验证规则和资源上限中受益。而且,如果您关心基准测试,请将数据集添加到安全带中,以便其他人可以重现您的结果。
如何参与:在GitHub发行委员会上打开一个问题。如果您有一个用例,您希望OpenZL做得更好,请提供一些小样本,以便我们可以一起分析它们。您也可以为编解码器的优化做出贡献,并提出新的图表,解析器或控制点。所有这些主题不会影响解码器的普遍性。
我们认为OpenZL向数据压缩字段打开了一个新的可能性宇宙,我们很高兴看到开源社区将对它做什么!
要了解有关Meta开源的更多信息,请访问我们网站,订阅我们YouTube频道,或跟随我们Facebook,,,,线程,,,,x,,,,布鲁斯基和LinkedIn。