
我们最新的小型模型 Claude Haiku 4.5 现已向所有用户推出。
最近在边境的东西现在更便宜、更快。五个月前,Claude Sonnet 4 是最先进的型号。如今,Claude Haiku 4.5 为您提供了类似水平的编码性能,但成本却只有三分之一,速度却是原来的两倍多。
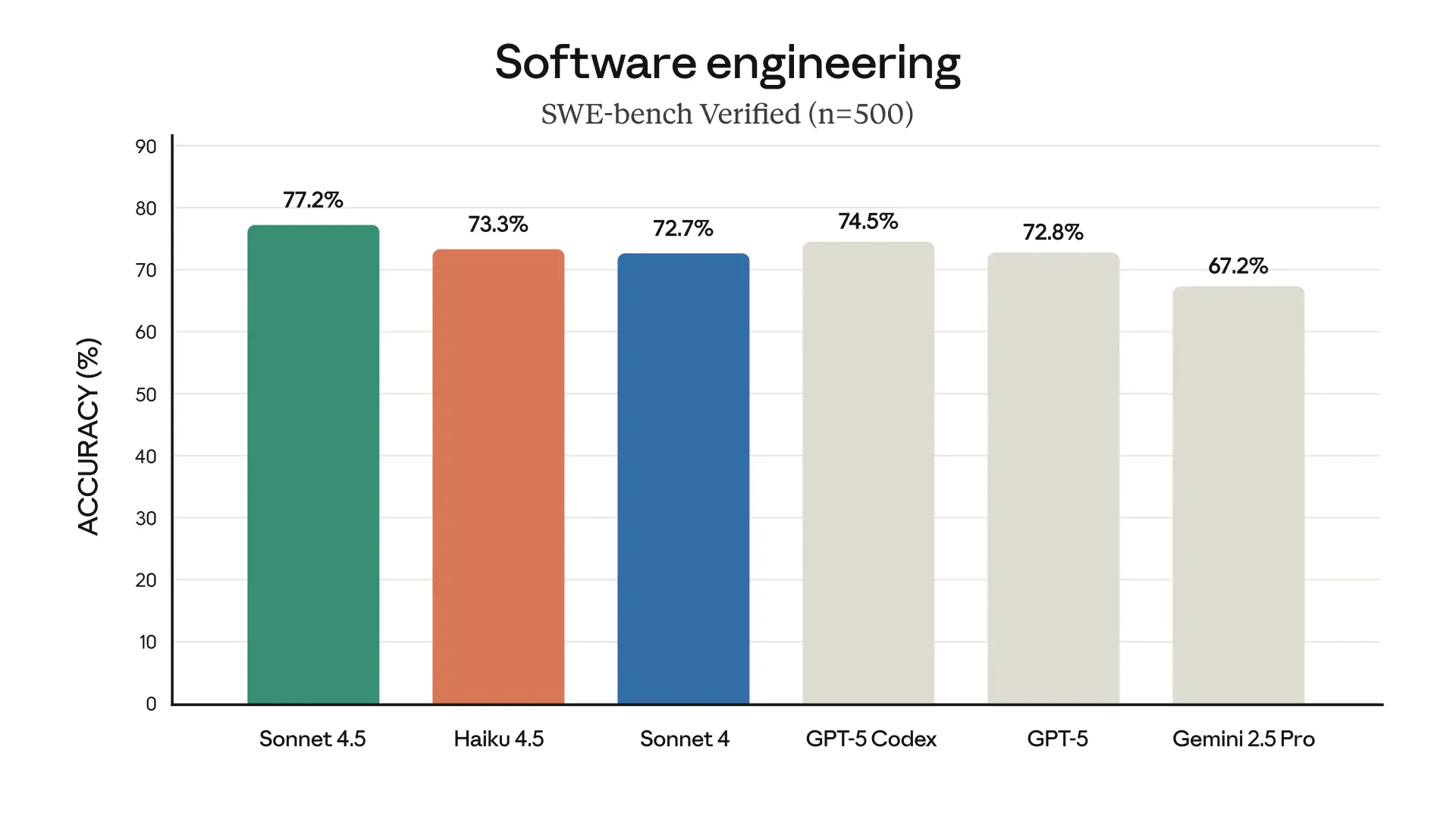
Claude Haiku 4.5 在某些任务(例如使用计算机)上甚至超过了 Claude Sonnet 4。这些进步使应用程序像克劳德·铬比以往更快、更有用。
依靠 AI 执行实时、低延迟任务(例如聊天助理、客户服务代理或结对编程)的用户将欣赏 Haiku 4.5 的高智能和卓越速度的结合。Claude Code 的用户会发现 Haiku 4.5 使编码体验(从多代理项目到快速原型设计)的响应速度明显加快。
克劳德十四行诗 4.5,发布两周前,仍然是我们的前沿模型和世界上最好的编码模型。当用户想要接近前沿的性能和更高的成本效率时,Claude Haiku 4.5 为他们提供了一个新的选择。它还开辟了一起使用我们的模型的新方法。例如,Sonnet 4.5 可以将一个复杂的问题分解为多步骤计划,然后编排多个 Haiku 4.5 组成的团队并行完成子任务。
克劳德俳句 4.5 现已随处可用。如果您是开发人员,只需通过 Claude API 使用 claude-haiku-4-5 即可。目前定价为每百万输入和输出代币 1/5 美元。
基准测试
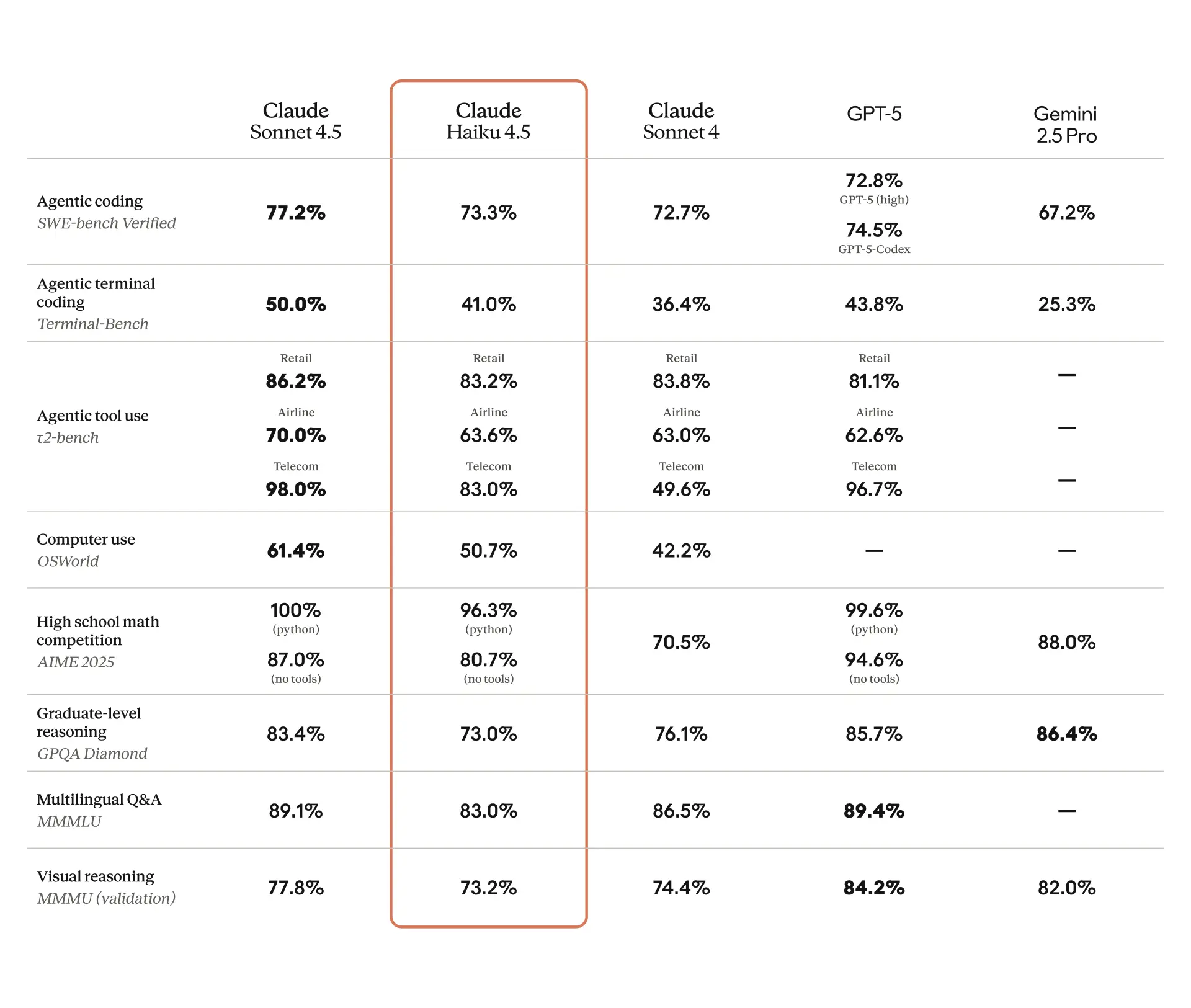
![]()
—
克劳德俳句 4.5 达到了我们认为不可能的最佳点:近乎前沿的编码质量以及惊人的速度和成本效率。在 Augment 的代理编码评估中,它达到了 Sonnet 4.5 90% 的性能,可以匹配更大的模型。我们很高兴向我们的用户提供它。
![]()
—
Claude Haiku 4.5 是代理编码的一次飞跃,特别是对于子代理编排和计算机使用任务。这种响应能力让 Warp 中的人工智能辅助开发感觉是即时的。
![]()
—
从历史上看,模型为了质量而牺牲了速度和成本。Claude Haiku 4.5 模糊了这种权衡的界限:这是一种快速前沿模型,可保持成本效益并表明此类模型的发展方向。
![]()
—
Claude Haiku 4.5 在不牺牲速度的情况下提供智能,使我们能够构建利用深度推理和实时响应能力的人工智能应用程序。
![]()
—
克劳德俳句 4.5 非常强大 –就在六个月前,这种性能水平还是最先进的根据我们的内部基准。现在,它的运行速度比 Sonnet 4.5 快 4-5 倍,而成本仅为 Sonnet 4.5 的一小部分,从而解锁了一组全新的用例。
![]()
—
速度是在反馈循环中运行的人工智能代理的新领域。Haiku 4.5 证明你可以兼具智力和快速输出。它能够可靠地处理复杂的工作流程,实时自我纠正,并保持动力而无延迟开销。对于大多数开发任务来说,这是理想的性能平衡。
![]()
—
克劳德俳句 4.5在幻灯片文本生成的指令跟踪方面优于我们当前的模型,准确率达到 65%,而我们的高级模型为 44%,这彻底改变了我们的单位经济效益。
![]()
—
我们的早期测试表明,Claude Haiku 4.5 为 GitHub Copilot 带来了高效的代码生成质量与 Sonnet 4 相当,但速度更快。我们已经将其视为 Copilot 用户的绝佳选择,他们重视人工智能驱动的开发工作流程中的速度和响应能力。
安全评估
我们对 Claude Haiku 4.5 进行了一系列详细的安全性和一致性评估。该模型表现出较低的关注行为率,并且比其前身 Claude Haiku 3.5 更加一致。在我们的自动对齐评估中,Claude Haiku 4.5 还显示出统计上显着低于 Claude Sonnet 4.5 和 Claude Opus 4.1 的总体错位行为率,从而使 Claude Haiku 4.5(按照此指标)成为我们迄今为止最安全的模型。
我们的安全测试还表明,克劳德俳句 4.5 在化学、生物、放射性和核武器 (CBRN) 武器的生产方面仅带来有限的风险。因此,我们根据 AI 安全级别 2 (ASL-2) 标准发布了它,而 Sonnet 4.5 和 Opus 4.1 则采用了限制性更强的 ASL-3 标准。您可以在以下位置阅读模型 ASL-2 分类背后的完整推理,以及我们所有其他安全测试的详细信息:克劳德俳句4.5系统卡。更多信息
Claude Haiku 4.5 现已在 Claude Code 和我们的应用程序上提供。
其效率意味着您可以在使用限制内完成更多任务,同时保持优质的模型性能。
开发人员可以在我们的 API、Amazon Bedrock 和 Google Cloud 的 Vertex AI 上使用 Claude Haiku 4.5,它可以以最经济的价格直接替代 Haiku 3.5 和 Sonnet 4。