

研究人员发现,人工智能驱动的搜索引擎依赖于“不太受欢迎”的资源
好的,但是哪一个更好呢?
当然,这些差异并不一定意味着人工智能生成的结果“更糟”。研究人员发现,基于 GPT 的搜索更有可能引用企业实体和百科全书等来源来获取信息,而几乎从不引用社交媒体网站。
基于LLM的分析工具发现人工智能驱动的搜索结果也往往涵盖与传统前 10 个链接相似数量的可识别“概念”,这表明结果的细节、多样性和新颖性水平相似。与此同时,研究人员发现,“生成引擎倾向于压缩信息,有时会忽略传统搜索保留的次要或模糊的方面。”对于更模糊的搜索词(例如不同人共享的名字)尤其如此,研究人员发现,“有机搜索结果提供了更好的覆盖范围”。
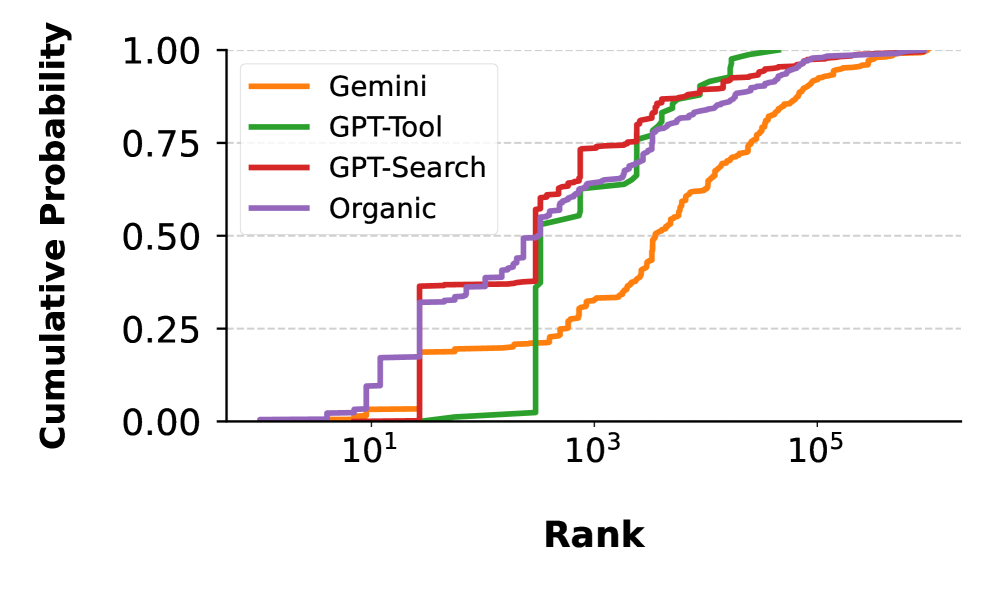
尤其是 Google Gemini 搜索更有可能引用低受欢迎度的域名。尤其是 Google Gemini 搜索更有可能引用低受欢迎度的域名。
对于带有搜索工具的 GPT-4o 来说尤其如此,它通常不引用任何网络资源,只是根据其训练提供直接响应。
但这种对预先训练数据的依赖可能会成为搜索及时信息的限制。对于从 Google 9 月 15 日趋势查询列表中提取的搜索词,研究人员发现带有搜索工具的 GPT-4o 经常会回复类似“您能否提供更多信息”的消息,而不是实际在网络上搜索最新信息。
虽然研究人员没有确定基于人工智能的搜索引擎总体上比传统搜索引擎链接“更好”还是“更差”,但他们确实敦促未来研究“新的评估方法,共同考虑生成搜索系统中的来源多样性、概念覆盖范围和综合行为”。
关于《研究人员发现,人工智能驱动的搜索引擎依赖于“不太受欢迎”的资源》的评论
暂无评论
发表评论
摘要
研究人员发现,基于 GPT 的模型由人工智能生成的搜索结果往往更频繁地引用企业实体和百科全书,但很少引用社交媒体。人工智能驱动的搜索涵盖与传统前 10 个链接类似数量的概念,但可能会省略次要或模糊的方面,特别是对于有机搜索提供更好覆盖范围的模糊搜索词。研究发现 Google Gemini 更频繁地引用低受欢迎度的域名。人工智能引擎可以将预先训练的内部知识与网络数据集成起来,这在某些情况下比传统搜索有优势,但在寻求及时信息时却受到限制。该研究并没有明确地将基于人工智能的搜索标记为更好或更差,但表明需要考虑源多样性和合成行为的新评估方法。