

Gemini 3 Pro 在文档、空间、屏幕和视频理解方面提供最先进的性能。
总体总结
Gemini 3 Pro 是 Google 最强大的多模式模型,可在文档、空间、屏幕和视频理解方面提供最先进的性能。您可以使用它进行复杂的视觉推理、文档处理和理解空间关系。查看开发人员文档或使用 Google AI Studio 中的模型来开始使用。
摘要由 Google AI 生成。生成式人工智能尚处于实验阶段。
听文章
此内容由 Google AI 生成。生成式人工智能尚处于实验阶段
[[持续时间]] 分钟
Gemini 3 Pro 代表了从简单识别到真正的视觉和空间推理的代际飞跃。它是我们有史以来最强大的多模式模型,在文档、空间、屏幕和视频理解方面提供最先进的性能。
该模型在视觉基准(例如用于复杂视觉推理的 MMMU Pro 和 Video MMMU)以及跨文档、空间、屏幕和长视频理解的特定用例基准上创下了新高。

1. 文档理解
现实世界的文档是混乱的、非结构化的并且难以解析——通常充满交错的图像、难以辨认的手写文本、嵌套的表格、复杂的数学符号和非线性布局。Gemini 3 Pro 代表了该领域的重大飞跃,在整个文档处理流程中表现出色 — 从高精度光学字符识别 (OCR) 到复杂的视觉推理。
智能感知
为了真正理解文档,模型必须准确地检测和识别文本、表格、数学公式、图形和图表,无论噪音或格式如何。
一项基本功能是“去渲染”——将可视文档逆向工程回结构化代码(HTML、LaTeX、Markdown)并重新创建它的能力。如下图所示,Gemini 3 展示了跨多种模式的准确感知,包括将 18 世纪的商人日志转换为复杂的表格,或将带有数学注释的原始图像转换为精确的 LaTeX 代码。
示例 1:来自 18 世纪奥尔巴尼商人手册的手写复杂表格
示例 2:从图像重建方程
示例 3:将 Florence Nightingale 的原始极地面积图重建为交互式图表(带有切换开关!)
复杂的推理
用户可以依靠 Gemini 3 跨表格和图表执行复杂的多步骤推理 - 即使在长报告中也是如此。事实上,该模型在 CharXiv Reasoning 基准测试中的表现明显优于人类基线 (80.5%)。
为了说明这一点,想象一下用户正在分析 62 页的美国人口普查局“美国收入:2022” 报告,提示如下: – 比较 2021 年至 2022 年“货币收入”与“税后收入”基尼指数的百分比变化,以及导致税后指标差异的原因,以及就“货币收入”而言,它是否显示最低五分之一的份额上升或下降?
滑动下面的图像即可查看模型的逐步推理。
视觉提取:为了回答基尼指数比较问题,Gemini 在图 3 中找到并交叉引用了有关“货币收入减少 1.2%”和表 B-3 中有关“税后收入增加 3.2%”的信息。
因果逻辑:至关重要的是,Gemini 3 并不仅仅停留在数字上;它将这种差距与文本的政策分析联系起来,正确识别 ARPA 政策的失效和刺激支付的结束是主要原因。
数值比较:为了比较最低分位数的份额上升或下降,Gemini3 查看了表 A-3,比较了 2.9 和 3.0 的数字,并得出结论:“最低五分位数所占家庭总收入的份额正在上升。”
2. 空间理解
Gemini 3 Pro 是我们迄今为止最强的空间理解模型。结合其强大的推理能力,该模型能够理解物理世界。
- 指向能力:Gemini 3 能够通过输出像素精确坐标来指向图像中的特定位置。二维点序列可以串在一起来执行复杂的任务,例如估计人体姿势或反映随时间变化的轨迹。
- 开放词汇参考:Gemini 3 使用开放词汇来识别对象及其意图。最直接的应用是机器人技术:用户可以要求机器人生成基于空间的计划,例如,“鉴于这张凌乱的桌子,想出一个如何对垃圾进行分类的计划。”这也扩展到 AR/XR 设备,用户可以要求人工智能助手“根据用户手册指向螺丝。”
3. 屏幕理解
Gemini 3.0 Pro 的空间理解确实通过其对桌面和移动操作系统屏幕的屏幕理解而闪耀。这种可靠性有助于使计算机使用代理足够强大以自动执行重复任务。UI 理解功能还可以支持 QA 测试、用户引导和 UX 分析等任务。下面的计算机使用演示展示了模型的高精度感知和点击。
4. 视频理解
Gemini 3 Pro 在人工智能理解视频(我们交互的最复杂的数据格式)方面取得了巨大飞跃。它是密集的、动态的、多模式的并且具有丰富的背景。
- 高帧率理解:我们对模型进行了优化,以便在以每秒 >1 帧的速度采样时更能理解快节奏的动作。Gemini 3 Pro 可以快速捕捉细节,这对于分析高尔夫挥杆力学等任务至关重要。
通过以 10 FPS(默认速度的 10 倍)处理视频,Gemini 3 Pro 捕捉每一次挥杆和重量变化,从而深入了解球员的动作。
2、“思考”模式视频推理:我们升级了“思维”模式,超越物体识别,走向真正的视频推理。该模型现在可以更好地追踪一段时间内复杂的因果关系。而不仅仅是识别什么正在发生,它理解为什么它正在发生。
3. 将长视频转化为行动:Gemini 3 Pro 弥合了视频和代码之间的差距。它可以从长格式内容中提取知识,并立即将其转化为功能应用程序或结构化代码。
提示: – 这是我尝试做作业的照片。请检查我的步骤并告诉我哪里出错了。不要用文字解释,而是在图像上直观地显示我。(注意:学生作业以蓝色显示;模型修正以红色显示)。[查看 Google AI Studio 中的提示]

医学和生物医学成像
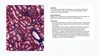
双子座 3 专业版 1 是我们最有能力的医学和生物医学图像理解通用模型,在 MedXpertQA-MM(一项困难的专家级医学推理考试)、VQA-RAD(放射学图像问答)和 MicroVQA(基于显微镜的生物研究的多模态推理基准)等主要公共基准测试中实现了最先进的性能。
输入图像来自微型VQA- 基于显微镜的生物研究的基准
法律和金融
Gemini 3 Pro 增强的文档理解能力可帮助金融和法律专业人士处理高度复杂的工作流程。金融平台可以无缝分析充满图表和表格的密集报告,而法律平台则受益于该模型复杂的文档推理。
6. 媒体分辨率控制
Gemini 3 Pro 通过保留图像的原始长宽比来改进其处理视觉输入的方式。这推动了全面的质量显着提高。
此外,开发人员可以通过新的功能对性能和成本进行精细控制媒体分辨率参数。这允许您调整视觉令牌的使用,以平衡保真度和消耗:
- 高分辨率:最大限度地提高需要精细细节的任务的保真度,例如密集的 OCR 或复杂的文档理解。
- 低分辨率:优化更简单任务的成本和延迟,例如一般场景识别或长上下文任务。
如需具体建议,请参阅我们的Gemini 3.0 文档指南。使用 Gemini 3 Pro 进行构建