
对于巴塞罗那最近的一个期刊俱乐部,我们读到了刚刚发表的文章在实验心理学杂志:综述(杰普:G)。这篇论文探讨了使用 gen-AI 对创造力的影响。该论文提出了一个倒U:人工智能使用程度适中的人最具创造力。
该论文共有三项研究。研究 1 和 2 是实验。这篇文章是关于研究 3 的,它被描述为“实地研究”。我认为该研究中的 U 形是虚假的。
这是一个让您知道我们现在正在交叉上市的好地方子栈
研究3。
研究 3 涉及在 CloudResearch(在线参与者池)上进行的两轮调查。在第一波中,“创意工作者”样本按照 7 分制对他们在工作中使用人工智能的程度进行评分。在一周后进行的第二阶段,每个工人的主管(!)用九个项目的量表评估员工的创造力。
在一项被描述为“预先注册”的分析中[1],论文报告了二次回归的结果,其中因变量是主管的创造力评级,关键预测变量是员工自我报告的人工智能使用情况及其平方项。两者都很重要。报纸上这样说“表示非对称倒U形关系”(第 9 页),然后显示图 6。
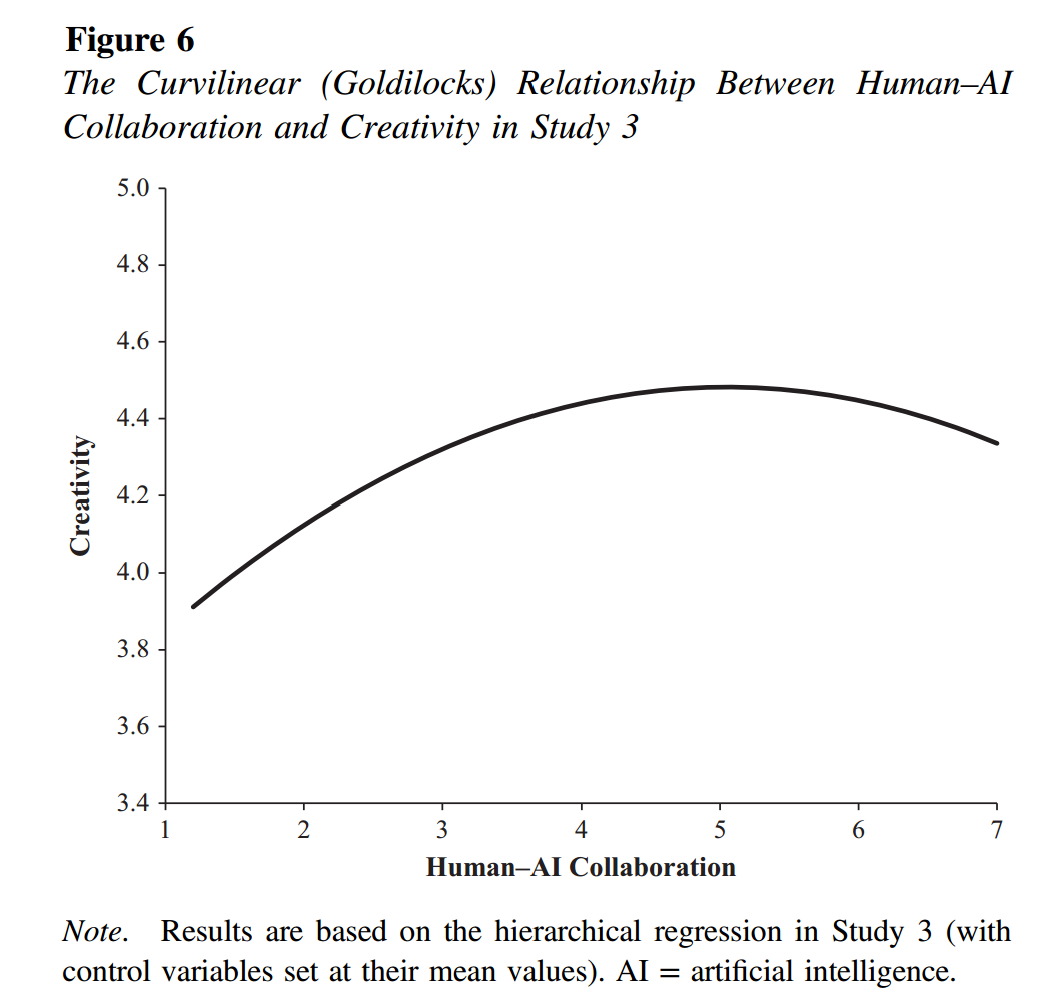
图1.JEP:G 论文中图 6 的转载
该论文称该图意味着“创造力最大值达到4.5。过了这一步,创造力就会下降。”
然而,这一推论并没有得到数据的证实。
问题在于两种不同类型的误差:抽样误差和规格误差。
抽样误差
仅仅因为二次项很重要,并不意味着U型是重要的。阐明这一点的最简洁方法是使用图表,我只是将置信带添加到图 6 中(我分析了发布的数据来计算该带)。

图2.添加置信带
用于重现此图和其他图的 R 代码和数据:https://researchbox.org/5159
估计函数存在很多不确定性,而且这种关联是单调的,对于所有级别的人工智能使用来说,更多的人工智能使用与更多的创造力相关,这一点远没有被数据拒绝。
规格错误
论文中的图 6 和我喷绘的置信带假设人工智能参与和创造力之间的真实关联可以通过二次函数完美地捕捉到。也就是说,它估计二次回归并按面值获取结果估计。
在两篇博文和一篇发表的论文中,我解释了为什么这种方法无效,并建议改为依靠“两线”程序来测试 U 形。
1.飘香[27]三十多岁的人正在萎缩以及其他U型挑战
2.飘香[62]两条线:U 型关系的第一个有效测试
3.西蒙森 (2018)。两条线:用二次回归对 U 形关系进行无效测试的有效替代方法。AMPPS, 1(4), 538-555
通过两条线测试,这个 U 形并不显着(p= .81)。见下图,用(开源)生成在线应用程序
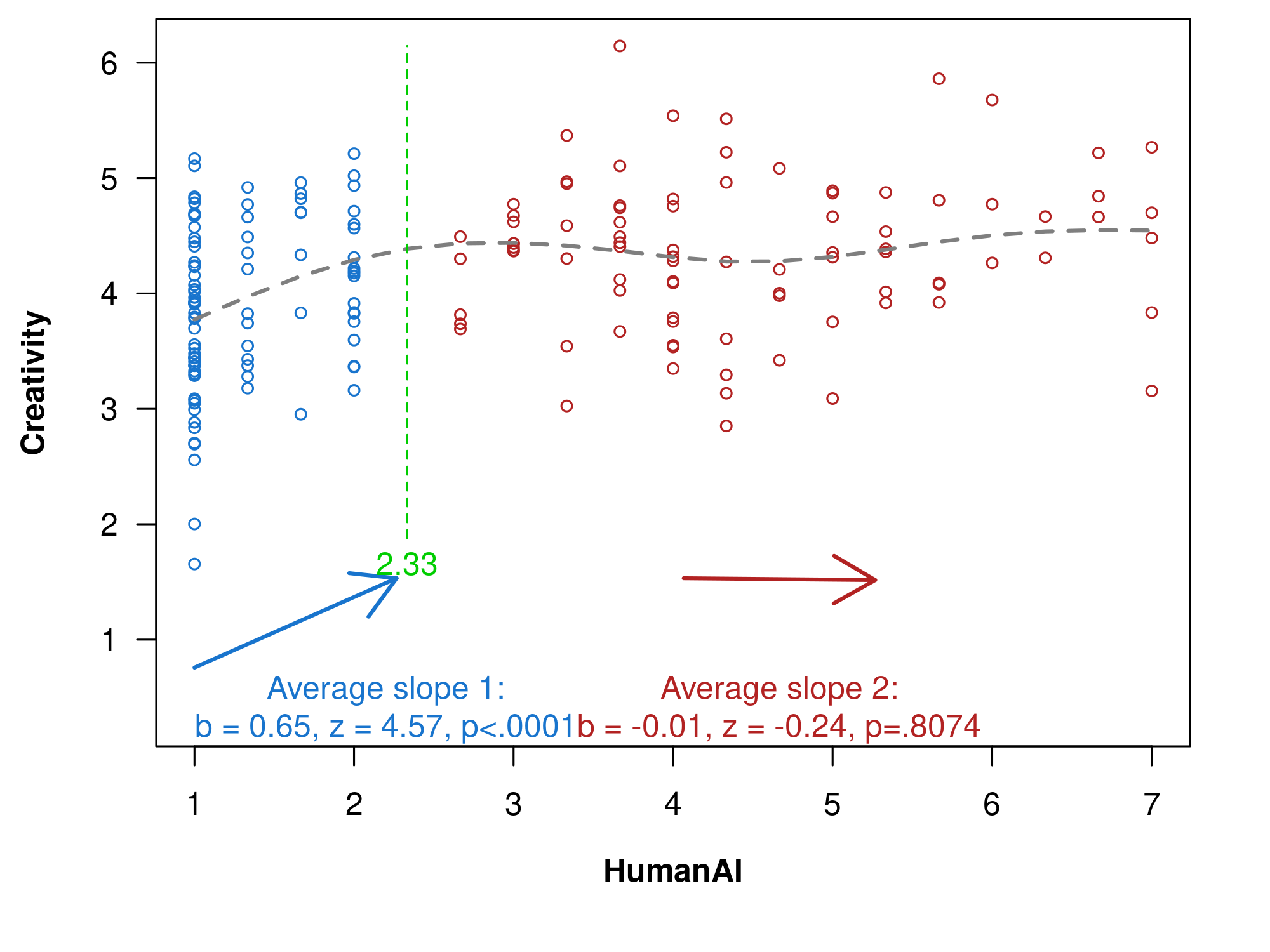
图 3.两线测试的结果。
(虚线基于 GAM;使用“Robin Hood”过程设置断点)
使用双线检验代替二次回归的呼吁已经足够成功;我不会在这里重复两行论证[2]。
我会改为新的对二次方错误之处的直觉。
有问题的二次方程的新直觉:这里的效果基于那里的数据
让我们从应该开始的地方开始,绘制基础数据的分布。

图 4.关键预测变量的分布
我们看到 38% 的数据的 AI 值在 [1 和 2) 之间。
相比之下,不到 10% 的数据位于 [6 & 7] 之间。
这意味着(二次)回归在拟合这些数据时,将比 [6 和 7] 更多地关注值 [1 和 2)。好的。这足够直观了。接下来的事情就不那么直观了。
当二次回归产生倒 U 时,负斜率对于值 [6 和 7],这并不是因为它正在检测消极的 坡度在那个范围内,相反,这是因为它正在检测非常积极斜率在a不同范围,[1&2)。
回归实际上是向后弯曲以适应 1 和 2 之间的陡峭曲线,然后在 2 和 5 之间变平。它在 [5 和 7] 之间的范围内弯曲,但只是为了适应曲线在较低值处的平坦化。
更一般和更精确地,曲线任何部分的形状不必是局部数据的充分或可解释的总结。
二次回归的衷心声明
在一次与二次回归的独家对话中,它与我分享了这样的说法:
二次回归的陈述
听着,我的工作是全面了解数据。如果你给我的数据中很多观测值都有陡峭的斜率,我不能不注意它,所以我会这样做;我会给你一个陡坡回来,没问题。然后我什至可以使附近数据的曲线变得平坦。但我不能提供一个平台期,不能提供曲线保持平坦。最终我必须当我远离这个平坦部分时,变为负值;我会生产一个U吗?是的。我在乎吗?不,我没有得到报酬形状对。我付钱去得到接近数据。一个虚假的 U 会得到一些错误的数据点,但作为回报,我得到了更多正确的数据点,所以我会努力去做,我会减少损失。U 是“你的问题”;我看不到形状。如果你关心形状,那就大错特错了。我应该看看其他人,你应该看看其他工具。
我将再展示两张图,以便为这一点提供一些直观的认识。
没有低值,就没有高值反转。
首先,让我们重新运行论文中的二次回归,但排除那些在 [1 和 2) 之间的低值观测值。如果虚假 U 形是由它们引起的,我们可能会预期 U 形会消失,而且确实如此。这突出表明,当二次函数报告 5 和 7 之间的负斜率时,它并不是根据 5 和 7 之间的数据执行此操作,该数据仍然存在,而是根据 1 和 2 之间的数据执行此操作。

图 5.观测数据的二次回归拟合值和置信带,下降陡峭部分
通过更改“此处”的数据来生成“此处”的 U 形
对于最终的数字,我采用了真实的 AI 值,但生成了一个假的因变量,这样我就可以控制真实的函数形式。我生成了三个函数。这三个都是单调的,更多的人工智能总是会产生更多的创造力,但我改变了[1和2]之间函数的不成比例的陡峭程度。从陡峭,到更陡,再到最陡。[1 &2] 范围内的最陡函数会产生高 AI 值的虚假 U 形。
仅仅陡峭的函数则不然。
图 6.的

消极的二次方的斜率可能是由陡峭的积极的数据中的斜率很远用于重现此图和其他图的 R 代码和数据:https://researchbox.org/5159
反馈政策我们的政策是在发布之前联系我们所报道作品的作者以获得反馈。
我第一次联系作者是在两周前。
我们有过一次亲切的以及建设性的交流,他澄清了一些我认为 JEP:G 的同行评审员应该确保包含在论文中的细节(即样本是如何构建的以及响应率是多少)。作者对我试图纳入的措辞提供了反馈。他指出,他的分析(用于测试 U 形的二次回归)是他所在领域的主流,并提到了一位有影响力的研究人员 2013 年发表的一篇论文,该论文发表在心理科学,他用它作为基准(哈特姆)。
![]()
脚注。
- 预登记
预注册中的分析(https://aspredicted.org/DC2_WKN) 并不表明哪些协变量将包含在回归中。它还没有指定如何解释二次回归。上面写着:
该论文确实在补充中报告了替代规范的结果,正文指出,当排除所有协变量时,人工智能的二次效应并不显着(p= .14,第 3302 页)。 样本量也有点奇怪。论文中报告的样本量 N=188 对,为更大比 AsPredicted 预注册 (N=150) 中的结果要好,但论文对它太小表示歉意。

没有报告预期或观察到的回报/完成率。我向作者询问,他表示有250名工人提供了信息,后来他得到了188名主管的答复,“他们可以与这些工人匹配”。他还解释说“虽然出于实际考虑,样本量达到了预先注册的目标,但仍然没有达到审查过程中要求功效分析指定的更大目标”。
[Ø©]
- 两条线足够成功
我的偶然观察是,顶级心理学期刊上的大多数论文在测试 U 形时都使用两线测试。他们确实继续报告大部分二次结果,并使用两条线作为稳健性检查。但我还没有进行系统的照明审查来验证这一偶然的观察。[Ø©]